Definition
A conditional branch instruction is a fundamental control instruction in assembly language that alters the program’s execution flow based on the outcome of a comparison between two values. This type of instruction enables decision-making in assembly programs, allowing the execution to continue along different paths depending on whether a specified condition is met.
In assembly language, conditional branching is typically implemented using instructions such as beq (branch if equal) and bne (branch if not equal). Consider the following MIPS assembly instructions:
beq $s1, $s2, L1 # Branch to L1 if ($s1 == $s2)
bne $s1, $s2, L1 # Branch to L1 if ($s1 != $s2)In these examples, the beq instruction checks whether the values in registers $s1 and $s2 are equal. If they are, execution jumps to the instruction labeled L1. Conversely, the bne instruction causes a branch to L1 if $s1 and $s2 hold different values.
When a branch instruction is executed, two critical concepts determine its behavior:
DEFINITION
- Branch Target Address (BTA): This is the address to which control is transferred if the branch condition is satisfied. The BTA is typically calculated as
PC + 4 + offset, whereoffsetis an immediate value derived from the instruction.- Branch Outcome: This determines whether the branch is taken or not taken . If the condition specified by the branch instruction is met, the branch is considered taken, and execution jumps to the BTA. Otherwise, the branch is not taken , and the execution continues sequentially with the next instruction (
PC + 4).
Branch Execution in a MIPS 5-Stage Pipeline
A classic MIPS processor follows a five-stage pipeline for instruction execution, comprising Instruction Fetch (IF), Instruction Decode (ID), Execute (EX), Memory Access (ME), and Write Back (WB). The execution flow of a branch instruction through these stages is as follows:

- Instruction Fetch (IF): The instruction is fetched from memory, and the Program Counter (PC) is incremented by
to point to the next sequential instruction. - Instruction Decode (ID): The instruction is decoded, and the source registers (e.g.,
$xand$y) are read. - Execution (EX): The two registers are compared using the Arithmetic Logic Unit (ALU) to determine the Branch Outcome (Taken or Not Taken). Simultaneously, the Branch Target Address (BTA) is computed as
PC + 4 + offset. - Memory Access (ME): At this stage, the Branch Outcome is applied to update the Program Counter (PC):
- If the branch is not taken , execution continues at
PC + 4. - If the branch is taken, the PC is updated to the computed BTA.
- If the branch is not taken , execution continues at
- Write Back (WB): Unlike regular arithmetic or load/store instructions, branch instructions do not write results to registers. Instead, the control flow is redirected based on the computed branch decision.
A critical aspect of branch execution in pipelined architectures is that the Branch Outcome and Branch Target Address are determined at the end of the EX stage. However, the PC is only updated at the end of the ME stage. This delay implies that by the time the next instruction is fetched during IF, the processor has not yet confirmed whether the branch will be taken. This delay introduces a control hazard, which can lead to incorrect instruction execution if not properly handled.
Problem of Control Hazards in Pipelining
In a pipelined processor, each clock cycle is used to fetch a new instruction to keep the execution flow continuous. However, a challenge arises when dealing with branch instructions: the decision to change the program counter is not available at the time of instruction fetch. This uncertainty creates what is known as a Control Hazard or Branch Hazard—a situation where the pipeline cannot determine the correct instruction to fetch until the branch condition is fully evaluated.
DEFINITION
Control hazards occur when the pipeline attempts to fetch the next instruction before the outcome of a branch or jump instruction is known. These hazards can lead to incorrect instruction execution, requiring the pipeline to be stalled or flushed, ultimately reducing performance.
Branch instructions, including conditional branches and unconditional jumps, alter the normal sequential flow of execution. Since pipelining relies on fetching instructions in advance, it suffers from performance degradation when control hazards occur, as the processor must wait until the branch decision is resolved before proceeding.
The Impact of Control Hazards on Performance
A straightforward but inefficient solution to control hazards is to stall the pipeline until the branch resolution is complete. In a standard five-stage MIPS pipeline, the branch outcome is determined at the Memory (ME) stage, which means a naive approach would introduce a 3-cycle stall every time a branch instruction is encountered. This significantly reduces the ideal speedup provided by pipelining.
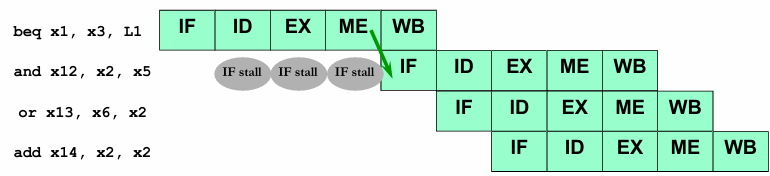
If the branch outcome turns out to be not taken, the delay is unnecessary, wasting valuable execution cycles. Instead of stalling, an alternative approach is to speculatively assume the branch is not taken and continue fetching and executing the next instructions. If this assumption holds, the pipeline proceeds smoothly. However, if the branch is actually taken, the three speculatively fetched instructions must be discarded or flushed before they affect the program state.
To mitigate the cost of control hazards, modern architectures employ various techniques:
-
Branch Prediction
Instead of stalling the pipeline, the processor predicts the branch outcome and speculatively executes instructions accordingly.- If the prediction is correct, execution continues without interruption.
- If incorrect, the mispredicted instructions are flushed, and the correct path is taken.
-
Forwarding and Early Resolution
By resolving the branch earlier in the pipeline—at the Execution (EX) stage instead of the ME stage—the branch outcome and target address become available sooner. This approach reduces the stall penalty from 3 cycles to 2 cycles and improves performance. -
Delayed Branching
Some architectures introduce delayed branch execution, where a few instructions after the branch are always executed regardless of whether the branch is taken. Carefully selecting these instructions (which do not depend on the branch outcome) minimizes wasted cycles.
Early Evaluation of the PC in the ID Stage
To mitigate the performance impact of control hazards, additional hardware resources can be introduced to optimize branch handling.
Hint
Specifically, the pipeline can be enhanced to:
- Compare register values to determine the Branch Outcome (BO).
- Compute the Branch Target Address (BTA) to identify where control should be transferred if the branch is taken.
- Update the PC register to reflect the correct instruction address.
These steps must be executed as early as possible in the pipeline to minimize the number of stalls caused by branch instructions.
In an optimized MIPS pipeline, these three steps (Branch Outcome computation, Branch Target Address computation, and PC update) are anticipated during the Instruction Decode (ID) stage instead of being completed at the Execution (EX) or Memory (ME) stage. By making this modification, the processor can resolve branch decisions earlier in the pipeline. Since both the BO and BTA are known at the end of the ID stage, the pipeline can decide which instruction to fetch with only one stall cycle instead of the standard three-cycle penalty.
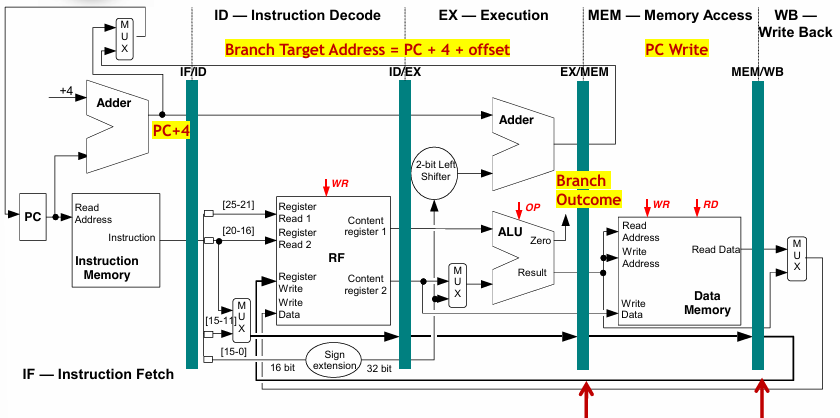
A similar optimization is also present in the RISC-V pipeline, where branches are resolved at the ID stage. This approach significantly improves performance by reducing unnecessary pipeline stalls.
Conservative Approach: Stalling Until Resolution in the ID Stage
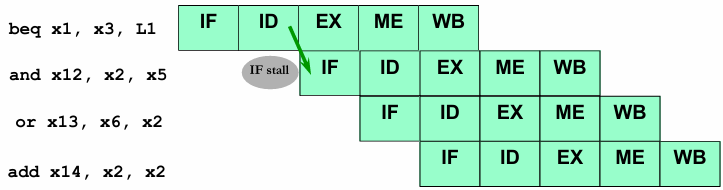
A straightforward approach to handling branches after this optimization is to stall the pipeline until the branch outcome is determined at the end of the ID stage. This method introduces a 1-cycle stall to ensure the correct instruction is fetched, reducing the performance loss associated with each branch instruction.
However, while this conservative approach ensures correctness, it still imposes a stall penalty. A more efficient solution can be explored.
Alternative Approach: Speculative Execution of Sequential Instructions
Instead of stalling, an alternative strategy is to assume that the branch is not taken and continue executing sequential instructions. If this assumption is correct, the pipeline proceeds smoothly without introducing unnecessary stalls.
Warning
However, if the branch is taken, the incorrectly fetched instruction must be flushed before it can write its results, and the correct instruction must be fetched from the Branch Target Address (BTA).

This approach introduces the concept of branch prediction, where the processor speculatively assumes a particular branch outcome and adjusts execution accordingly. Since the branch outcome is resolved at the end of the ID stage, this method incurs a 1-instruction flush penalty when mispredicted, rather than the more costly multi-cycle stall of unoptimized pipelines.
- The branch cannot be assumed as taken immediately because the Branch Target Address is not known at the instruction fetch stage.
- If the branch is actually taken, the processor must:
- Flush one incorrectly fetched instruction before it writes any results.
- Fetch the correct instruction from the Branch Target Address.
- This method ensures that each branch incurs at most a one-cycle penalty, significantly reducing performance degradation compared to traditional stalling techniques.