In modern web and mobile applications, the Database Management System (DBMS) is a critical endpoint. Often, the database exists independently of the applications that use it.
Challenge
Moving data between the relational model of the DBMS and the object model of the application (like Java) can be complex and requires a significant amount of repetitive boilerplate code to convert row data into objects and vice versa.
This fundamental difference between the two models is often called the Object-Relational Impedance Mismatch.
Definition
Object-Relational Mapping (ORM) is a programming technique for bridging the gap between the object-oriented model used in application development and the relational model used in databases. It acts as a mediator that automates the transformation of data between these two models.
The primary challenge, known as impedance mismatch, arises because some concepts in one model have no direct or logical equivalent in the other.
Object-oriented programming (OOP) and relational databases have fundamentally different ways of representing data. The following table summarizes the key differences:
Object-Oriented Model (Java)
Relational Model
Objects, Classes
Tables, Rows
Attributes, Properties
Columns
Identity (Physical Memory Address)
Primary Key
Reference to another entity
Foreign Key
Inheritance/Polymorphism
Not supported
Methods
Stored Procedures, Triggers
Code is portable
Not necessarily portable (vendor-dependent)
Java Persistence API (JPA)
The Java Persistence API (JPA) is a Java specification that provides a standard way to bridge the gap between object-oriented domain models and relational database systems.
Important
JPA provides a POJO (Plain Old Java Object) persistence model for ORM. This means you can use regular Java objects to represent your database entities without them needing to implement special interfaces, a concept known as non-intrusiveness.
JPA was developed as part of JSR-317 and builds upon previous proposals like Java Data Objects (JDO) and Java Database Connectivity (JDBC). It can be used in both Java Enterprise Edition (EE) environments with containers (like EJB) and standalone Java Standard Edition (SE) applications.
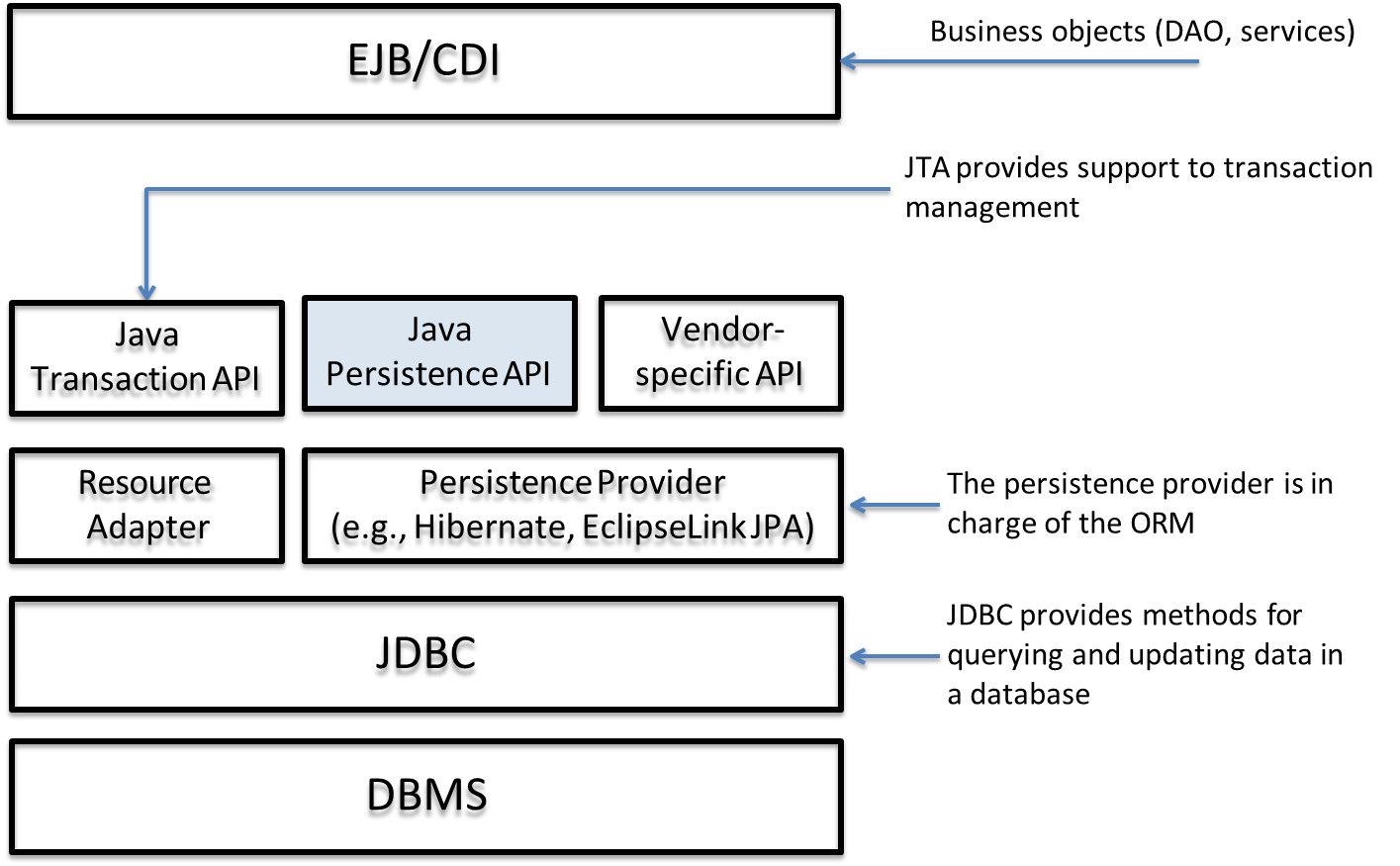
The JPA architecture is layered to abstract the underlying database and persistence provider.
EJB/CDI: The business layer containing Data Access Objects (DAOs) and services.
Java Transaction API (JTA): Provides support for transaction management.
Java Persistence API (JPA): The standard API for persistence.
Persistence Provider: The implementation of the JPA specification (e.g., Hibernate, EclipseLink). This layer is responsible for the actual ORM.
JDBC: The standard Java API for connecting to and interacting with databases.
DBMS: The underlying relational database.
JPA Main Concepts
Core JPA Concepts
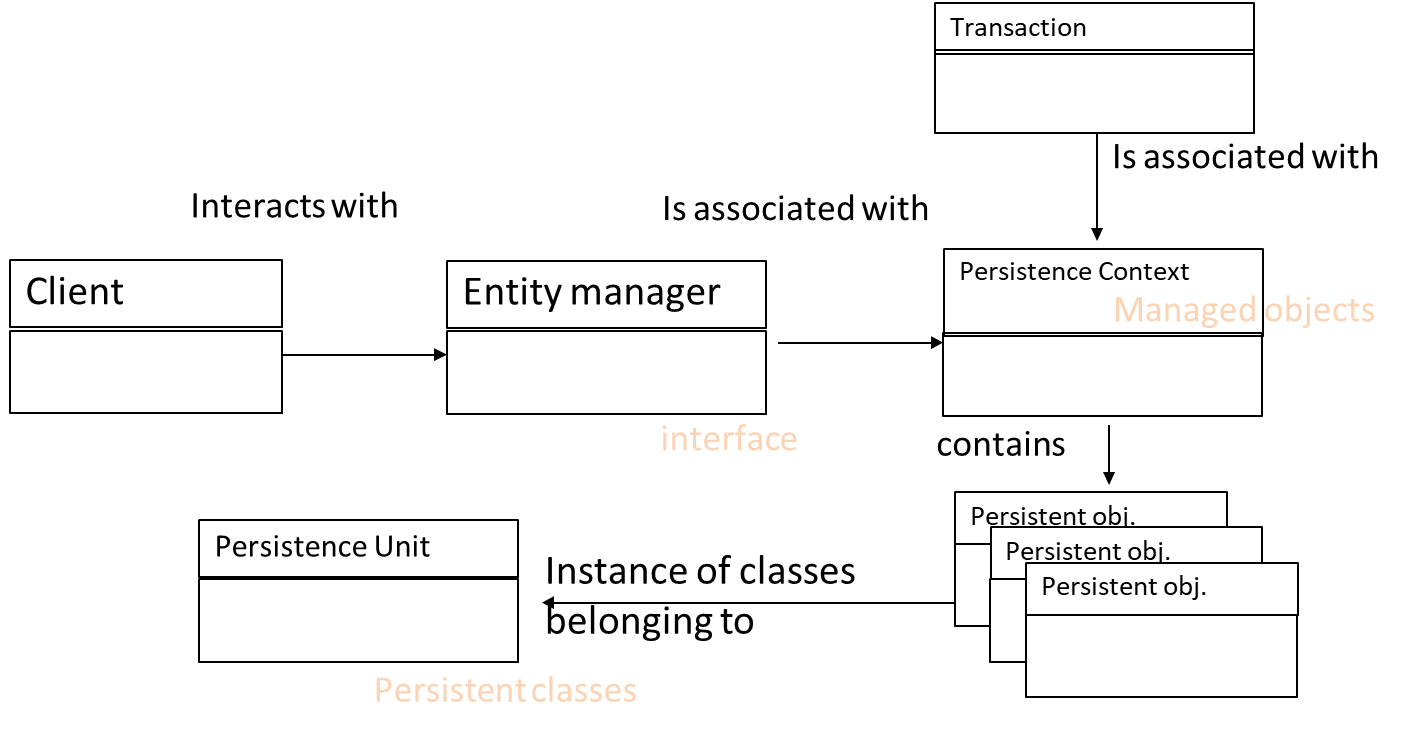
Entity: A JavaBean (POJO) class that represents a collection of persistent objects mapped to a relational table. The class maps to the table schema, and its instances (objects) map to the tuples (rows).
Persistence Unit: The set of all entity classes that are mapped to a single database. This is analogous to a database schema.
Persistence Context: The set of all managed entity instances within a persistence unit. It acts as a cache or a transactional write-behind buffer and is analogous to a database instance.
Managed Entity: An entity instance that is currently part of a persistence context. Any changes to its state are tracked and will be synchronized with the database.
Entity Manager: The primary interface for interacting with the persistence context. It provides methods for creating, reading, updating, and deleting entities.
Client: A component (e.g., an EJB) that interacts with the persistence context indirectly through an EntityManager.
Entities are accessed and managed through the EntityManager interface.
The EntityManager Interface
The EntityManager interface is a central component within the Java Persistence API (JPA), serving as the primary mechanism for interacting with the persistence context.
Definition
The EntityManager exposes a set of core operations that allow developers to perform Create, Read, Update, and Delete (CRUD) operations, thereby bridging the object-oriented domain model of the application with the relational structure of the database.
The fundamental methods of the EntityManager are designed to manage the lifecycle of an entity within the persistence context.
persist(Object entity): Transitions a new, unmanaged entity instance into a managed state, scheduling it for insertion into the database upon the next synchronization.
find(Class<T> entityClass, Object primaryKey): Retrieves an entity from the database using its primary key. The returned instance is immediately placed in a managed state within the persistence context.
remove(Object entity): Schedules an entity for deletion from the database. Once remove is called, the entity instance is no longer managed by the persistence context.
refresh(Object entity): Reloads the entity’s state from the database, overwriting any pending changes in the persistence context and ensuring data consistency.
flush(): Forces the persistence context to write all pending changes, such as insertions, updates, and deletions, to the database immediately. This is particularly useful for ensuring that changes are committed at specific points within a transaction.
Defining Entities
Definition
An entity is a POJO that is associated with a tuple in a database. Its persistent state outlives the application’s execution. An entity class must be explicitly mapped to the database table it represents.
For a class to be a valid entity, it must follow these rules:
It must have a public or protected no-argument constructor.
The class itself must not be final.
No methods or persistent instance variables of the entity class may be final.
If an entity instance needs to be passed by value as a detached object, it must implement the Serializable interface.
An Employee Entity
When defining an entity, you typically use JPA annotations to specify how the class maps to a database table and its columns. The most common annotation is @Entity, which marks the class as a persistent entity.
The primary key of the entity is defined using the @Id annotation. This field uniquely identifies each instance of the entity in the database.
// Java annotations are used to qualify the class as an entity@Entitypublic class Employee { @Id private int id; // attributes private String name; private long salary; // constructor... // getter and setter...}
In a database, every row has a unique identity provided by a primary key. An entity assumes the identity of the data it’s associated with.
Simple Primary Key: A single persistent field represents the identity.
Composite Primary Key: A set of persistent fields represents the identity.
Standard POJOs do not have a durable identity. The concept of a persistent identity is introduced by JPA to bridge this gap.
@Entitypublic class Mission implements Serializable { @Id // @Id indicates this is the primary key (PK) private int id; private String city; // ...}
For entities with a single-field primary key, the @Id annotation is used to mark the field that uniquely identifies each instance. However, when an entity requires a composite primary key—meaning the primary key consists of multiple fields—JPA provides two main approaches: @EmbeddedId and @IdClass.
The @EmbeddedId annotation is used when you define a separate embeddable class that encapsulates all the primary key fields, and this class is then referenced as a single attribute in the entity.
Alternatively, the @IdClass annotation allows you to specify a separate primary key class whose fields correspond to multiple@Id-annotated fields in the entity itself. Both strategies enable JPA to manage entities with composite keys, but they differ in how the key fields are organized and referenced within the entity class.
JPA’s persistence provider can automatically generate unique identifiers for entities. This feature is called identifier generation and is specified using the @GeneratedValue annotation.
@Entitypublic class Mission implements Serializable { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) // The ID is generated by the DB when the tuple is created private int id; // ...}
Applications can choose from four strategies:
Strategy
Description
AUTO
The persistence provider chooses the generation strategy. This is the default.
TABLE
The provider uses a database table to generate identifiers.
SEQUENCE
The provider uses a database sequence for generation. This is used if the underlying DB supports sequences.
IDENTITY
The provider relies on an auto-incrementing identity column in the database.
Mapping Attributes and Tables
By default, an entity class is mapped to a table with the same name, and its fields are mapped to columns with the same names. These defaults can be overridden using annotations.
Custom Table and Column Mapping
In this example, the Book entity is mapped to a table named T_BOOKS, and its attributes are mapped to specific columns. The title attribute is marked as non-nullable, while the coverType and publicationDate attributes are not explicitly mapped to any column.
@Table(name="T_BOOKS"): Maps the entity to the T_BOOKS table.
@Column(name="BOOK_TITLE", nullable=false): Maps the title attribute to the BOOK_TITLE column and specifies that it cannot be null.
@Transient: Indicates that the discount attribute should not be persisted in the database.
@Entity @Table(name="T_BOOKS")public class Book { @Column(name="BOOK_TITLE", nullable=false) private String title; private CoverType coverType; // An enum private Date publicationDate; @Transient private BigDecimal discount;}
Attributes in JPA entities can be further customized using annotations to control how they are mapped to database columns and how they behave at runtime.
Special Types:
Large Objects (LOBs): Attributes that store large binary or character data, such as images or long text, should be annotated with @Lob. This tells JPA to map the field to a database type suitable for large objects, like BLOB or CLOB. By default, LOBs are fetched lazily, but you can override this with the fetch attribute.
Enumerated Types: Java enums are mapped to the database using the @Enumerated annotation. By default, JPA stores the ordinal (integer) value of the enum. However, this can lead to problems if the order of enum constants changes. To store the enum as a string (the name of the constant), use @Enumerated(EnumType.STRING). This approach is safer and more maintainable.
Temporal Types: For attributes of type java.util.Date, java.util.Calendar, or the legacy java.sql date/time types, you must specify the temporal precision using the @Temporal annotation. The options are TemporalType.DATE (date only), TemporalType.TIME (time only), and TemporalType.TIMESTAMP (date and time). This ensures the correct mapping to the corresponding SQL type.
Entities and Relationships
Most entities need to form relationships with other entities. In JPA, a relationship is defined in the sense of the Object Model (i.e., through object references).
Every relationship in the Object Model has four key characteristics:
Directionality: A relationship can be unidirectional (one entity has a reference to the other) or bidirectional (both entities have references to each other). In JPA, all relationships are fundamentally unidirectional; a bidirectional relationship is implemented as a matched pair of unidirectional ones.
Role: In a directional relationship, one entity is the source and the other is the target.
Cardinality: Defines the number of instances on each side of the relationship. The four types are:
@ManyToOne (many source entities, one target entity)
@OneToMany (one source entity, many target entities)
@OneToOne (one source entity, one target entity)
@ManyToMany (many source entities, many target entities)
Bidirectional relationships are just pairs of matched unidirectional mappings with swapped source and target entities. When we have a “to-one” relationship, the source entity has 1 reference to the target entity. In a “to-many” relationship, the source entity has multiple references (a collection) to the target entity.
Ownership: In a relationship, one side is designated as the owner.
The owner is the entity whose table contains the foreign key (join column) that implements the relationship.
Annotations for the physical mapping (like @JoinColumn) are defined on the owning side. In a one-to-many or one-to-one relationship, the owner is the entity that has the foreign key column in its table. In a many-to-many relationship, either entity can be the owner.
The mappedBy Attribute vs. @JoinColumn
These two elements are central to defining relationships but serve opposite purposes.
@JoinColumn: Used on the owning side of a relationship. It specifies the foreign key column in the owner’s table. It essentially says, “I own the join column.”
mappedBy: Used on the inverse (non-owning) side of a bidirectional relationship. It tells JPA that the relationship is already mapped by a field in the other entity. It essentially says, “To find the mapping for this relationship, go to the other side and look at the specified attribute.”
If mappedBy is omitted in a bidirectional @OneToMany or @OneToOne relationship, JPA assumes it’s two separate unidirectional relationships and, by default, might create an unnecessary join table (as it does for many-to-many). The purpose of mappedBy is to instruct JPA not to create a bridge table because the relationship is already being managed by a foreign key on the owning side.
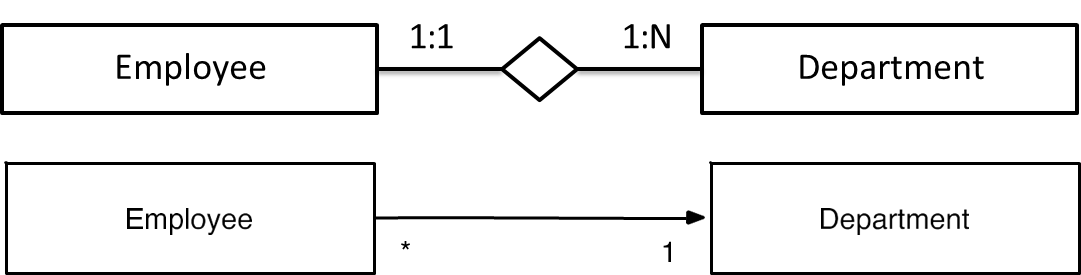
Modeling One-to-Many and Many-to-One Relationships
In object-relational mapping (ORM), a fundamental association is the one-to-many relationship, which links a single instance of one entity to multiple instances of another.
A common example is the relationship between a Department and its Employees.
graph LR;
Department --1:N--> Employee;
Employee --N:1--> Department;
In a relational database, this is implemented by placing a foreign key in the table corresponding to the “many” side of the relationship (e.g., the EMPLOYEE table would contain a dept_fk column referencing the DEPARTMENT table).
When this relationship is mapped bidirectionally in the Java Persistence API (JPA), it allows for navigation from either entity to the other.
The “many” side (e.g., the Employee entity) is designated as the owning side of the relationship. This is because its corresponding database table holds the foreign key that physically establishes the link.
Conversely, the “one” side (e.g., the Department entity) is the inverse side. It contains a collection of the associated entities and is annotated with @OneToMany. Crucially, the mappedBy attribute must be used on the inverse side. This attribute points to the field in the owning entity that manages the relationship (e.g., mappedBy="dept"). This informs the persistence provider that the mapping is defined and controlled by the Employee entity, preventing JPA from erroneously creating a separate join table to manage the association.
@Entitypublic class Department { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; // The owning side of the relationship @OneToMany(mappedBy = "dept") private List<Employee> employees;}@Entitypublic class Employee { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; // The inverse side of the relationship @ManyToOne @JoinColumn(name = "dept_fk") private Department dept;}
Applications do not always require bidirectional navigation. In such scenarios, a unidirectional mapping offers a simpler and more focused domain model.
Definition
A unidirectional many-to-one () relationship is the most direct representation. It involves annotating the reference on the “many” side with @ManyToOne and @JoinColumn. The “one” side remains unaware of this association, containing no reference back to its employees.
This design perfectly mirrors the underlying database structure, where an Employee can be queried to find its Department, but not the other way around without a specific query.
Conversely, a unidirectional one-to-many () relationship presents greater complexity because the entity owning the relationship in the object model (Department, which holds the collection) is not the one whose table contains the foreign key. One approach is to map the collection in the “one” side using @OneToMany and specifying the foreign key column with @JoinColumn(name = "dept_fk").
A more common and often preferred alternative is to omit the collection mapping altogether. Instead, related entities are retrieved on-demand using a query. This approach decouples the entities in the domain model, simplifies persistence management, and can improve performance by avoiding the overhead of managing a collection that may not always be needed.
Modeling One-to-One and Many-to-Many Relationships
A bidirectional one-to-one () relationship associates a single instance of an entity with exactly one instance of another. In JPA, this is modeled using the @OneToOne annotation on both entities. One entity must be designated as the owner of the relationship, meaning its table will contain the foreign key. The @JoinColumn annotation can be used on the owning side to specify this column. If omitted, JPA will derive a default column name by concatenating the name of the relationship attribute with an underscore and the target entity’s primary key name (e.g., a field parkingSpace would default to a join column named parkingSpace_id).
The inverse side must use the mappedBy attribute within its @OneToOne annotation to reference the field on the owning side, ensuring that JPA understands the relationship is managed elsewhere and does not attempt to create a second, redundant foreign key.
// Owning Side: Employee.java@Entitypublic class Employee { @Id private int id; @OneToOne // By default, the join column will be named 'parkingSpace_id' private ParkingSpace parkingSpace; // ...}// Inverse Side: ParkingSpace.java@Entitypublic class ParkingSpace { @Id private int id; @OneToOne(mappedBy="parkingSpace") private Employee employee; // ...}
A many-to-many () relationship, where multiple instances of one entity can be associated with multiple instances of another, is implemented in relational databases via an intermediary join table. This table contains foreign keys referencing the primary keys of the two related entities. JPA abstracts this structure using the @ManyToMany annotation. One entity is chosen as the owning side, which is responsible for defining the join table via the @JoinTable annotation. This annotation specifies the name of the join table, the joinColumns (the foreign key column(s) referencing the owning entity), and the inverseJoinColumns (the foreign key column(s) referencing the other entity).
The inverse side also uses @ManyToMany but must include the mappedBy attribute, pointing to the collection field on the owning entity. This indicates that the lifecycle of the relationship (additions and removals in the join table) is managed by the owning side. If @JoinTable is not explicitly defined, JPA will generate a default table name by combining the names of the owner and inverse entities.
// Owning Side: Employee.java@Entitypublic class Employee { @Id private long id; @ManyToMany @JoinTable( name = "EMP_PROJ", // Name of the join table joinColumns = @JoinColumn(name = "EMP_ID"), // FK to Employee inverseJoinColumns = @JoinColumn(name = "PROJ_ID") // FK to Project ) private Collection<Project> projects; // ...}// Inverse Side: Project.java@Entitypublic class Project { @Id private int id; @ManyToMany(mappedBy = "projects") private Collection<Employee> employees; // ...}
Warning
If you do not specify a @JoinTable, JPA will automatically generate a default join table name using the pattern <Owner>_<Inverse>, where <Owner> is the name of the owning entity and <Inverse> is the name of the inverse (non-owning) entity. For example, in the case above, the default would be Employee_Project.
Advanced Relationship Features
Relationship Fetch Mode
JPA allows you to control when attribute values are loaded from the database using fetch strategies:
Definition
EAGER Fetching:The attribute is loaded immediately when the entity is retrieved.
This is the default for basic types (such as primitives and simple objects), but can be explicitly set using @Basic(fetch = FetchType.EAGER).
LAZY Fetching:The attribute is loaded only when it is accessed for the first time.
This is the default for large objects (@Lob) and collections, but can also be specified for other attributes using @Basic(fetch = FetchType.LAZY). Lazy loading can improve performance by avoiding unnecessary data retrieval, but requires an open persistence context when the attribute is accessed.
@Entitypublic class Mission implements Serializable { @Id @GeneratedValue (strategy = GenerationType.IDENTITY) private int id; private MissionStatus status; @Temporal (TemporalType.DATE) private Date date; /* * By default, LOBs are fetched lazily. However, you can explicitly specify the fetch mode. * This is a good practice for large objects to avoid loading large amounts of data unnecessarily. */ @LOB @Basic (fetch=FetchType.LAZY) private byte [] photo;}
Specifying a LAZY policy is a good practice for large objects (LOBs) to avoid loading large amounts of data unnecessarily.
By default, JPA specifies different fetch modes depending on the type of relationship.
Relationship Type
Default Fetch Mode
@ManyToOne
EAGER
@OneToOne
EAGER
@OneToMany
LAZY
@ManyToMany
LAZY
Important
It is generally recommended to use LAZY loading for all relationships, including single-valued ones, to avoid performance problems such as the ” select” issue (where many unnecessary queries are executed).
You can specify the fetch mode in the annotation, for example: @OneToOne(fetch = FetchType.LAZY).
Note
Lazy loading is a hint to the JPA provider and may not always be honored, especially for basic types or when using certain frameworks. However, eager loading must always be respected.
Lazy loading is typically implemented using proxy objects. When you access a lazy-loaded relationship, JPA fetches the data from the database at that moment. If the persistence context is closed (e.g., after a transaction), accessing a lazy relationship may throw a LazyInitializationException.
Cascading Operations
In the Java Persistence API (JPA), operations performed via the EntityManager, such as persist, merge, or remove, are by default scoped only to the entity instance provided as an argument. Related entities within the object graph are not affected unless explicitly configured otherwise. To automate the propagation of these state transitions to associated entities, JPA provides the cascade attribute on relationship annotations like @ManyToOne or @OneToMany. This attribute allows developers to define which operations on a parent entity should be automatically applied, or cascaded, to its child entities.
The available cascade types, defined in the CascadeType enumeration, cover the full lifecycle of an entity.
Cascade Type
Description
CascadeType.PERSIST
When the parent entity is persisted, the related entities are also persisted.
CascadeType.MERGE
When the parent entity is merged, the related entities are also merged.
CascadeType.REMOVE
When the parent entity is removed, the related entities are also removed.
CascadeType.REFRESH
When the parent entity is refreshed, the related entities are also refreshed.
CascadeType.DETACH
When the parent entity is detached, the related entities are also detached.
CascadeType.ALL
Applies all of the above cascade types.
Cascading a persist operation
Without cascading, you must persist both the parent and the child entities separately:
em.persist(address);em.persist(employee);
With cascade = CascadeType.PERSIST, persisting the parent automatically persists the child:
@Entitypublic class Employee { @ManyToOne(cascade = CascadeType.PERSIST) Address address; //...}// Now this is sufficient:em.persist(employee); // The associated address will also be // persisted
By default, JPA does not cascade any operations. You must explicitly specify the cascade type. Use REMOVE with caution, as it can result in multiple delete statements and potential performance issues.
Orphan Removal
Distinct from cascading is the concept of orphan removal, a mechanism specifically designed for tightly coupled parent-child relationships where the child entity’s existence is wholly dependent on the parent. This is enabled by setting the orphanRemoval = true flag on a @OneToOne or @OneToMany association.
When this is active, the persistence provider monitors the relationship for “orphaned” entities.
Definition
An entity becomes an orphan when it is disassociated from its parent—for example, when it is removed from the parent’s collection or when the parent’s reference to it is set to null.
Upon detecting an orphan, the EntityManager will automatically schedule it for removal from the database during the next flush or commit. This is particularly useful in aggregate-style relationships, such as an Order and its OrderLine items, where an OrderLine has no logical meaning outside the context of its Order.
The distinction between cascade = CascadeType.REMOVE and orphanRemoval = true is fundamental to correct lifecycle management.
CascadeType.REMOVE is a direct consequence of a parent’s deletion; the remove operation on the parent entity is simply propagated down to its children. If the parent is not removed, the children are unaffected, even if the link between them is severed.
In contrast, orphanRemoval is triggered by the act of severing the relationship itself, irrespective of the parent entity’s state. If an OrderLine is removed from an Order’s list of lines, orphanRemoval ensures the OrderLine is deleted from the database, even though the Order itself persists.
@Entitypublic class Order { @OneToMany(orphanRemoval = true) private List<OrderLine> lines; //...}// Removing a line from the order will delete it from the database:order.getLines().remove(line);