Architecture, in the context of computing, refers to the systematic organization of hardware, software, and network resources that collectively enable the functioning of a system. It is a comprehensive blend of these components, structured to meet specific operational goals.
The classification of architectures depends on several parameters. One key parameter is the type and functionality of hardware resources involved in the system. Another critical aspect is the topology of links, which describes how the hardware components are interconnected to form a cohesive system. Additionally, the structure of software modules and their interrelationships play a significant role. This includes how software components communicate, share responsibilities, and integrate into the overall system.
A Brief History of Distributed Architectures
Distributed architectures have evolved significantly over the decades, influenced by advancements in technology and shifts in computing paradigms:
-
1960s-1970s: One-Tier Architectures
During this era, computing systems were predominantly centralized, with a single-tier architecture. These systems relied on monolithic mainframes where both data and applications resided. Users accessed these systems via terminals that served as mere input/output devices. -
1970s-1980s: Client-Server Architectures
This period marked a shift toward two-tier client-server systems. Here, servers handled data management tasks while clients managed the presentation layer. This separation allowed more interactive and efficient use of computing resources. -
1980s: Distributed Architectures Based on Remote Procedure Call (RPC)
With the advent of distributed systems, Remote Procedure Call (RPC) mechanisms enabled applications to execute procedures on remote systems as if they were local, promoting distributed computing. -
1990s: Object-Oriented Distributed Architectures
Object-oriented programming introduced more modular and reusable architectures. Systems were designed with distributed objects that encapsulated both data and behavior, streamlining complex interactions. -
Late 1990s: Internet and Web-Based Architectures
The rise of the internet transformed distributed architectures, emphasizing web-based interactions. HTTP, HTML, and emerging web technologies became foundational for connecting clients and servers globally. -
Today: Advanced Distributed and Cloud-Based Architectures
Modern systems emphasize service-oriented architectures (SOA), including RESTful services and microservices. These approaches prioritize scalability, modularity, and ease of deployment. The proliferation of cloud computing has further evolved these architectures, enabling virtualization and Application Service Provisioning (ASP). Additionally, mobile computing has integrated seamlessly into these distributed environments.
The Client-Server Model
The client-server architecture is characterized by the division of tasks between clients and servers, where each has specialized roles.

- Hardware Specialization: Servers are optimized for managing data, while clients focus on user interaction and presentation.
- Topology: Typically organized in a Local Area Network (LAN), this setup involves one or more servers and multiple clients.
- Software Structure: Client-server systems rely on functional partitioning. Client software combines business logic (processing and decision-making) and presentation logic (user interface rendering). Clients interact with servers by sending requests—often in the form of SQL queries—to access data. Servers handle these queries, enforce data integrity, and return results to the clients. This delineation of roles ensures efficient resource utilization.
Evolution to Three-Tier Architectures
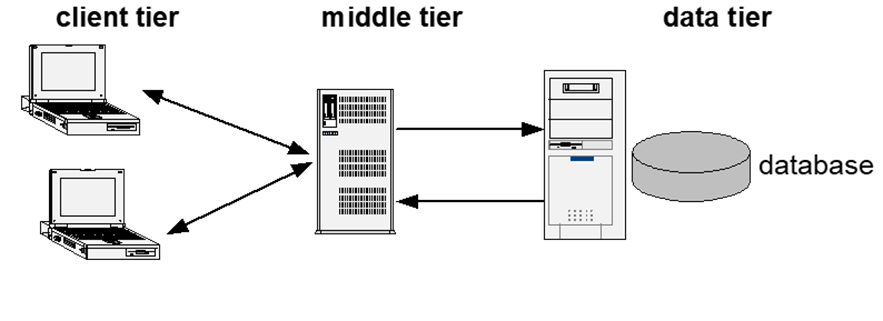
The three-tier architecture emerged as an improvement over the client-server model, introducing a middle tier that acts as an intermediary between clients and servers. This architectural enhancement offers numerous benefits:
-
Centralized Connection Management
The middle tier consolidates connections to the data server, simplifying access and reducing redundancy. -
Data Abstraction
By masking the data model, the middle tier ensures that clients are not directly exposed to the complexity of the underlying database structure. -
Scalability
The middle tier can be replicated to handle increased load, making the architecture more scalable.
The middle tier’s functionality can vary depending on the software features it employs. For example, systems may implement Remote Procedure Calls (RPC) for remote interactions, Object-Oriented Middleware for modular design, Message-Oriented Middleware for asynchronous communication, or Web-Based Services for internet-based interactions. These variants provide flexibility to adapt to different use cases, enhancing the system’s robustness and scalability.
Web “Pure HTML” Three-Tier Architectures

Web-based three-tier architectures utilizing pure HTML represent a straightforward yet powerful design where the client, middle tier, and data tier operate in distinct layers.
-
Client Tier:
The client in this architecture is typically a standard web browser. Its primary role is to handle the presentation layout, serving as a thin client. A thin client offloads computational tasks to the server, focusing solely on rendering the user interface using markup provided by the middle tier. -
Middle Tier:
The middle tier acts as the backbone of this architecture. It incorporates a web server that communicates using standard protocols such as HTTP. This tier houses the business logic, responsible for dynamically generating content from the raw data stored in the data tier. Additionally, it manages the presentation layout, assembling and delivering markup (e.g., HTML) that defines user interfaces. This division ensures flexibility and allows for scalable and maintainable applications. -
Data Tier:
While not detailed above, the data tier typically consists of a database or other persistent storage system. This layer provides the raw data that the middle tier processes and delivers to the client.
Rich Internet Applications (RIAs)
Rich Internet Applications (RIAs) bridge the gap between traditional desktop applications and web-based applications, providing an enriched user experience with desktop-like responsiveness.
RIAs leverage client-side scripting, primarily using JavaScript, to offer interactive and dynamic features. This makes them distinct from traditional thin-client web applications by introducing a fat client model.
-
Fat Client Characteristics:
Unlike a thin client, a fat client takes on a more significant portion of the processing workload. It uses standard communication protocols like HTTP or WebSocket, standardized scripting languages such as JavaScript, and APIs like the Document Object Model (DOM) and HTML5. This design enables advanced functionalities while maintaining compatibility across platforms. -
Technological Support:
HTML5 is a pivotal standard for RIAs, enabling seamless functionality and modern features without relying on additional plugins. -
Key Features of RIAs:
- Enhanced User Interfaces: HTML5 introduces new interface events tailored for mobile and touch applications, making RIAs highly adaptable to diverse devices.
- Asynchronous Interaction: RIAs use technologies like AJAX to send and receive data asynchronously, ensuring smoother user experiences without full page reloads.
- Client-Side Persistence: They offer mechanisms for storing data locally, such as web storage and IndexedDB, enhancing performance and enabling offline capabilities.
- Offline Functionality: RIAs support disconnected operations, allowing users to interact with applications even without an active internet connection.
- Multimedia and 3D Graphics: Native support for multimedia elements (audio, video) and advanced graphics (via WebGL) provides rich and engaging content without external dependencies.
By merging web and desktop functionalities, RIAs represent a pivotal step in modern application design, enabling robust, responsive, and versatile software solutions that cater to a wide range of user needs.
Three-Tier Web Applications with Java EE
Java EE (Java Platform, Enterprise Edition) is a comprehensive platform specifically designed for developing, deploying, and maintaining three-tier web applications. These applications are structured into three layers: the client tier (user interface), the middle tier (business logic), and the data tier (data storage and retrieval).
Java EE offers a robust ecosystem consisting of:
- API and Technology Specifications: A set of standard interfaces and guidelines for developing enterprise-grade applications.
- Development and Deployment Platforms: Frameworks and tools that simplify the creation and release of scalable and reliable applications.
- Reference Implementations: Example implementations to demonstrate Java EE technologies in practice.
- Compatibility Test Suites: Tools to ensure that applications adhere to Java EE standards and work seamlessly across compliant platforms.
- Reference Applications (Blueprints): Sample applications that provide best practices and templates for developers.
Java EE offers several key features that make it a preferred choice for enterprise application development:
-
Component-Based Development
Java EE emphasizes modularity by enabling developers to create applications through the assembly of loosely coupled, self-contained components. This approach promotes reusability, easier maintenance, and scalability. -
Container Services
The Java EE runtime environment, often referred to as a container, provides built-in services that address both functional and non-functional requirements. These include:- Security: Authentication and authorization mechanisms.
- Transactionality: Ensuring database consistency across operations.
- Scalability: Seamless handling of increasing loads.
- Failure Recovery: Automatic restoration mechanisms in case of system failures.
- Interoperability: Compatibility with external systems, enabling integration across diverse platforms.
-
Declarative Development
Developers can use declarative programming to specify application behavior without writing detailed implementation code. For example:- Declarative Security: Defining user roles and permissions in configuration files.
- Declarative Transactions: Specifying how transactions should behave in XML or annotations.
- Declarative Object-to-Relational Mapping: Simplifying the translation of objects to database records using frameworks like JPA (Java Persistence API).
The Java EE Stack
The Java EE stack is a layered architecture that integrates multiple technologies to support enterprise application development. It includes foundational elements such as Java Database Connectivity (JDBC) for data access, Java Server Pages (JSP) for dynamic content generation, and more advanced frameworks like JTA (Java Transaction API) and JPA.
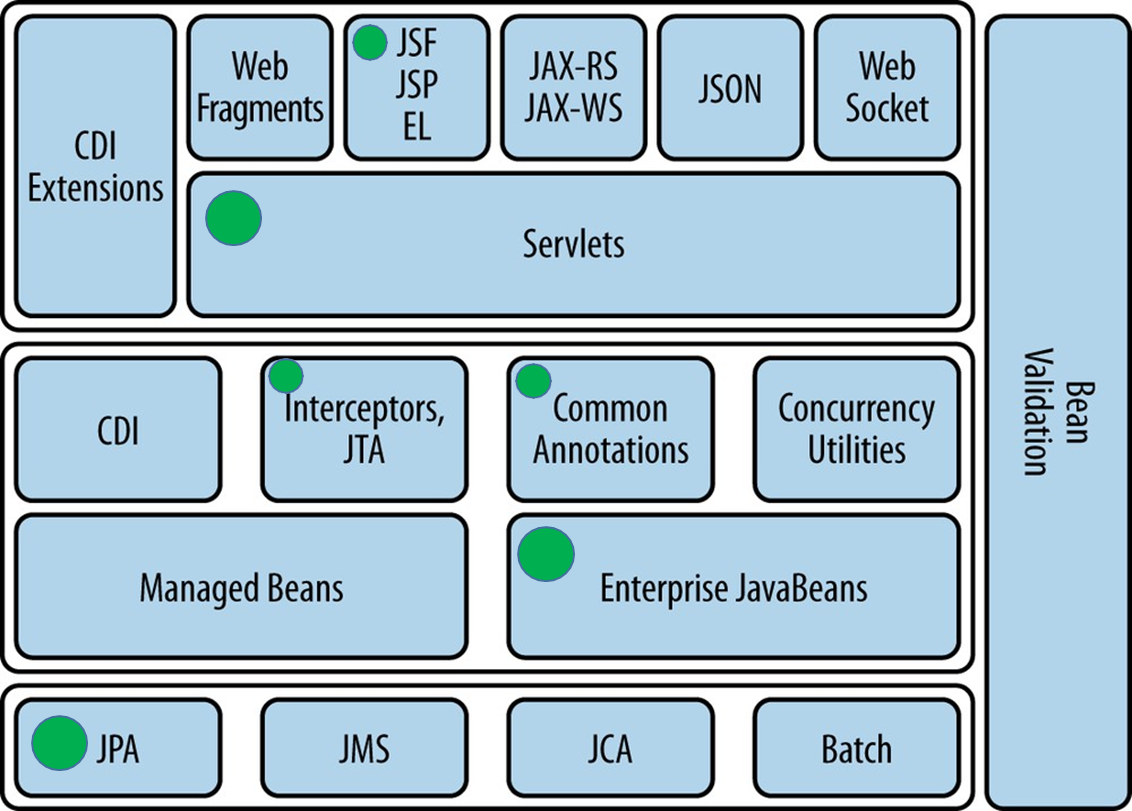
Java Database Connectivity (JDBC)
JDBC was one of the first industry standards introduced to enable database-independent connectivity between Java applications and relational databases. It remains a fundamental part of Java EE, though it is often supplemented or replaced by higher-level abstractions.
- Database Connection: JDBC allows applications to establish connections with databases or other tabular data sources.
- SQL Execution: Developers can send SQL queries and updates to the database directly from Java programs.
- Result Processing: The API includes methods for iterating over query results and extracting data.
While still relevant, JDBC has been largely superseded in many modern applications by technologies like JPA (Java Persistence API) for object-relational mapping and JTA (Java Transaction API) for managing complex transactions. These newer APIs provide higher-level abstractions, reducing boilerplate code and simplifying development.
Servlets
Servlets are a key Java technology for web application development, primarily used in the presentation tier of three-tier architectures. They provide a component-based, platform-independent framework for building web-based applications. Servlets run on the server side within a servlet container, which manages their lifecycle and ensures concurrency handling.
Servlets have seamless access to other Java APIs, such as JDBC, enabling them to interact with enterprise databases effectively. Their execution environment offers additional services like thread management and security, simplifying the development of robust and scalable web applications.
Enterprise JavaBeans (EJB)
Enterprise JavaBeans (EJB) technology serves as the cornerstone for developing server-side components in Java EE, focusing specifically on the business tier. EJB facilitates the creation of distributed, transactional, and secure applications, designed to be portable across platforms.
EJB components operate within an EJB container, which automates several critical tasks, including:
- Lifecycle management: Automatically managing the state and behavior of EJB objects.
- Transaction management: Supporting distributed transactions seamlessly.
- Replication and scaling: Ensuring high availability and performance in distributed environments.
EJB uses advanced Java features, such as annotations for metadata and dependency injection to simplify configuration and enhance modularity. These components are commonly invoked by the web tier to handle complex business logic and interact with data access services, bridging the front-end and back-end layers of enterprise systems.
Java Persistence API (JPA)
The Java Persistence API (JPA) standardizes object-relational mapping (ORM) in Java, providing a robust framework for mapping relational database data to object-oriented models. Integrated into both Java Standard Edition (Java SE) and Java Enterprise Edition (Java EE), JPA simplifies database interaction and minimizes boilerplate code.
Key features of JPA include:
- Core Package: The API is encapsulated in the
javax.persistencepackage. - Query Language: It offers the Java Persistence Query Language (JPQL) for querying databases using an object-oriented approach.
- Metadata: JPA provides a specification for defining metadata to map Java objects to relational database schemas effectively.
JPA has largely replaced older database connectivity methods like JDBC, as it abstracts much of the complexity involved in database access and offers enhanced productivity for developers.
Java Transaction API (JTA)
The Java Transaction API (JTA) is a standard interface for managing transactions in Java applications. It provides a resource-agnostic way to handle transactions, allowing components to manage multiple resources—such as databases or messaging services—within a single transaction.
With JTA, transactional properties can be specified in two primary ways:
- Declaratively: Using annotations like
@Transactional, developers can define transaction boundaries without explicit code, method by method. - Programmatically: The
UserTransactioninterface allows for manual transaction control with functions to start, commit, and rollback transactions.
Connecting an Application to the Database in a Three-Tier Web Architecture
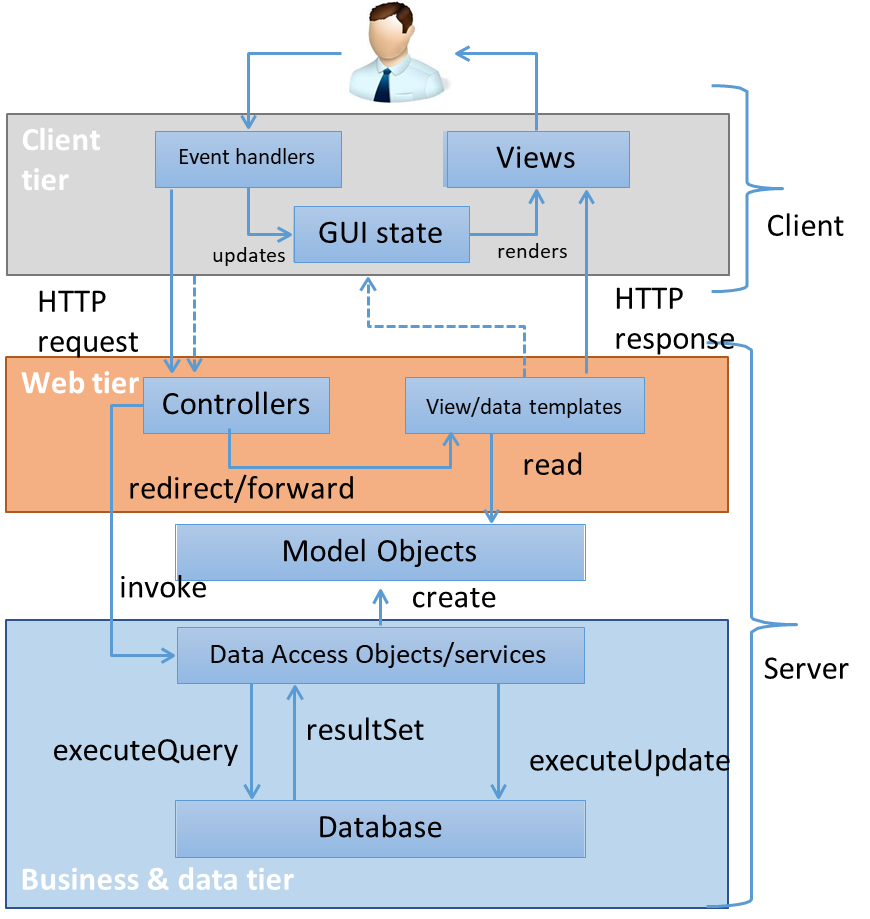
In a typical three-tier web application, interaction with the database is structured across three distinct layers:
-
Client Tier
The client tier is responsible for handling user interactions. It captures events, invokes the web tier to process requests, and renders results in the user interface (commonly referred to as the “view”). -
Web Tier
The web tier acts as the intermediary between the client and business tiers. It dispatches client requests to the appropriate business logic components (acting as controllers), processes the results, and sends formatted responses back to the client. -
Business and Data Tier
The business tier implements the core application logic, handling tasks such as decision-making, calculations, and rule enforcement. The data tier performs database queries and updates, ensuring data integrity within transactions. Tools like JPA and JTA facilitate efficient data handling and transaction management in this tier.
This separation of concerns ensures modularity, scalability, and maintainability, making three-tier architectures a popular choice for enterprise applications.
Case study: Expense Report
A Web application supports the management of travel expenses. After logging in, the user accesses a HOME page where there is a list of travel missions; a mission belongs to a user and has a date, a place, a description, a number of days of duration, and a status (“open”, “reported”, “closed”). The list shows the date and place of the missions, which are sorted by date descending. On the HOME page, there is a form with which the user can create a new mission by entering all the mandatory data. A new mission is always in the “open” state.
After creating a mission, the user is returned to the HOME page. When the user selects a mission in the list, a MISSION DETAIL page appears, showing all the mission data. If the mission is in the “open” state, a form appears for entering the expenses incurred during the mission; the form contains three fields: food costs, accommodation costs, and transport costs. Sending the form data causes the mission status to change from “open” to “reported”, and the return to the MISSION DETAIL page. Total expenses should be less than 100€; otherwise, the report is rejected with an error. If the mission is in the “reported” status, a CLOSE button appears, and the user can click on it to declare that he has received the reimbursement; this causes the mission status to change from “reported” to “closed” and the redisplay of the MISSION DETAIL page. If the mission is in the “closed” status, the MISSION DETAIL page shows the mission data completed with the value of the three types of expenditure.
Database Design
We have three entities: User, Mission, and Expenses. A user has a username, a password, a name, and a surname. A mission has a date, a destination, a state, a description, and a number of days. The state can be “open”, “reported”, or “closed”. An expense report has three fields: food, accommodation, and transport. The relationship between the entities is as follows:
Logical Database Schema
From the previous diagram, we can derive the following logical database schema:
CREATE TABLE user (
id int(11) NOT NULL AUTO_INCREMENT,
username varchar(45) NOT NULL,
password varchar(45) NOT NULL,
name varchar(45) NOT NULL,
surname varchar(45) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE mission (
id int(11) NOT NULL AUTO_INCREMENT,
date date NOT NULL,
destination varchar(45) NOT NULL,
state int(11) NOT NULL DEFAULT '0',
description varchar(45) NOT NULL,
days int(11) NOT NULL,
reporter int(11) NOT NULL,
PRIMARY KEY (id),
CONSTRAINT id_reporter
FOREIGN KEY (reporter) REFERENCES user (id)
ON DELETE CASCADE
ON UPDATE CASCADE
);
CREATE TABLE expenses (
id int(11) NOT NULL AUTO_INCREMENT,
food decimal(19,4) NOT NULL,
accommodation decimal(19,4) NOT NULL,
transport decimal(19,4) NOT NULL,
mission int(11) NOT NULL,
PRIMARY KEY (id),
KEY id (mission),
CONSTRAINT id
FOREIGN KEY (mission) REFERENCES mission (id)
ON DELETE CASCADE
ON UPDATE CASCADE,
CONSTRAINT CHK_TotalExp
CHECK (((food + accommodation) + transport) < 100.00)
);Application Design
At the application level, we can identify the following components:
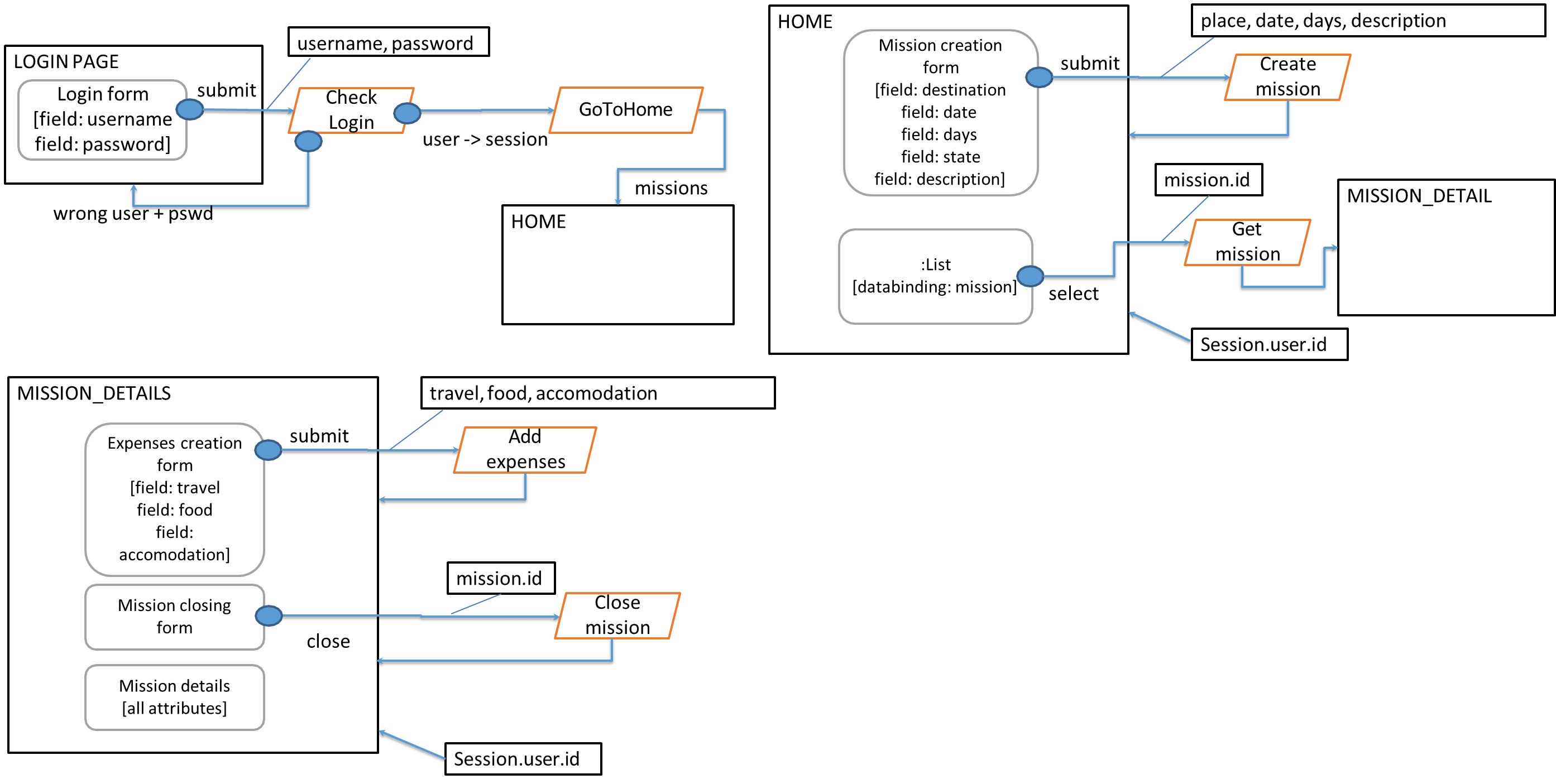
| Main Component | Sub Component |
|---|---|
| Model objects (Beans) | User |
| Mission | |
| ExpenseReport | |
| Data Access Objects (Classes) | UserDAO |
| - checkCredentials(username, pwd) | |
| MissionDAO | |
| - createMission(mission, userid) | |
| - findMissionsByUser(userid) | |
| - findMissionById(missionid) | |
| - changeMissionStatus(missionid, status) | |
| ExpensesDAO | |
| - addExpenseReport(expenseReport, mission) | |
| - findExpensesForMission(missionId) | |
| Controllers (servlets) | CheckLogin |
| GoToHomePage | |
| CreateMission | |
| GetMissionDetails | |
| CreateExpenses | |
| CloseMission | |
| Logout | |
| Views (Templates) | Login |
| Home | |
| MissionDetails |
Database Connection in Web Tier
Web.xmlconfiguration file in the WEB-INF folder of the web application server
<context-param>
<param-name>dbUrl</param-name>
<param-alue>
jdbc:mysql://localhost:3306/db_mission
</param-value>
</context-param>
<context-param>
<param-name>dbUser</param-name>
<param-value>piero</param-value>
</context-param>
<context-param>
<param-name>dbPassword</param-name>
<param-value>fraternali</param-value>
</context-param>
<context-param>
<param-name>dbDriver</param-name>
<param-value>
com.mysql.cj.jdbc.Driver
</param-value>
</context-param>- Utility functions called by all controllers that need be connected to the database. The
ConnectionHandlerclass provides utility functions for managing database connections in a web application. It includes agetConnectionmethod that retrieves a database connection using parameters defined in the web application’s context, and acloseConnectionmethod that safely closes the connection. These methods ensure that database connections are consistently managed across different controllers, reducing redundancy and potential errors.
public class ConnectionHandler {
public static Connection getConnection (ServletContext context) throws UnavailableException {
Connection connection = null;
try {
String driver = context.getInitParameter("dbDriver");
String url = context.getInitParameter("dbUrl");
String user = context.getInitParameter("dbUser");
String password = context.getInitParameter("dbPassword");
Class.forName(driver);
connection = DriverManager.getConnection(url, user, password);
} catch (ClassNotFoundException e) {
throw new UnavailableException("Can't load driver");
} catch (SQLException e) {
throw new UnavailableException("Couldn't get db connection");
}
return connection ;
}
public static void closeConnection (Connection connection) throws SQLException {
if (connection != null) { connection.close(); }
}
}(Repetitive) Code in the Controllers
- At initialization we create a
ConnectionHandlerobject
public void init() throws ServletException {
connection = ConnectionHandler.getConnection (
getServletContext());
}- At termination we close the connection
public void destroy() {
try {
ConnectionHandler.closeConnection(connection);
} catch (SQLException e) {
e.printStackTrace();
}
}Every controller in the application repeats the same code for acquiring and releasing the database connection. This approach is inefficient as each controller maintains its own connection, stored as a data member of the controller class. Additionally, this method increases the risk of forgetting to release a connection, which can be costly in terms of resource management and application performance.
Persistent Data Management with JDBC
The following examples demonstrate how to manage persistent data in a Java application using the JDBC API, specifically focusing on extracting, creating, and modifying data in a database. These methods, part of a MissionDAO class, encapsulate the database interactions related to “mission” entities.
Data Extraction: Retrieving Missions by User
The findMissionsByUser method fetches all missions reported by a specific user, ordered by their start date in descending order.
// Method of the business object MissionDAO
public List<Mission> findMissionsByUser(int userId) throws SQLException {
List<Mission> missions = new ArrayList<Mission>();
String query = "SELECT * from mission where reporter =? ORDER BY date DESC";
try (PreparedStatement pstatement = connection.prepareStatement(query);) {
pstatement.setInt(1, userId);
try (ResultSet result = pstatement.executeQuery();) {
while (result.next()) {
Mission mission = new Mission();
// Copy cursor data into Java bean objects...
mission.setId(result.getInt("id"));
mission.setStartDate(result.getDate("date"));
mission.setDestination(result.getString("destination"));
mission.setStatus(result.getInt("status"));
mission.setDescription(result.getString("description"));
mission.setDays(result.getInt("days"));
mission.setReporterID(userId);
missions.add(mission);
}
}
} // exception handling omitted for brevity
return missions;
}- A SQL query is prepared to filter missions by
reporter. - A
PreparedStatementbinds theuserIdto the query parameter. - The result set is processed row by row to populate
Missionobjects, which are added to a list. - This method returns a
List<Mission>containing the extracted missions.
Data Creation: Adding a New Mission
The createMission method inserts a new mission into the database.
public void createMission(Date startDate, int days, String destination, String description, int reporterId) throws SQLException {
String query = "INSERT INTO mission (date, destination, status, description, days, reporter) VALUES(?, ?, ?, ?, ?, ?)";
try (PreparedStatement pstatement = connection.prepareStatement(query)) {
pstatement.setDate(1, new java.sql.Date(startDate.getTime()));
pstatement.setString(2, destination);
pstatement.setInt(3, MissionStatus.OPEN.getValue());
pstatement.setString(4, description);
pstatement.setInt(5, days);
pstatement.setInt(6, reporterId);
pstatement.executeUpdate();
}
}- The SQL
INSERTstatement specifies the columns and values for a new mission. - Parameters such as date, destination, and status are bound to the query using
setXXXmethods. - The
executeUpdatemethod commits the insertion into the database.
MissionStatus.OPEN.getValue()retrieves the numerical value representing the "open" status, likely defined in an enumeration.
Data Modification: Updating Mission Status
The changeMissionStatus method modifies the status of an existing mission.
// Method of the business object MissionDAO
public void changeMissionStatus(int missionId, MissionStatus missionStatus) throws SQLException {
String query = "UPDATE mission SET status =? WHERE id =? ";
try (PreparedStatement pstatement = connection.prepareStatement(query);) {
// Copy the data to modify into the SQL query
pstatement.setInt(1, missionStatus.getValue());
pstatement.setInt(2, missionId);
pstatement.executeUpdate();
}
}- The SQL
UPDATEstatement targets thestatusfield of themissiontable. - Parameters, such as the new status and mission ID, are bound to the query.
- The
executeUpdatemethod updates the database with the new status.
Transactions in Java Applications
Managing transactions is crucial when performing multiple operations that must succeed or fail together, ensuring data consistency. Below is an example method, addExpenseReport, demonstrating transactional handling using JDBC.
This method inserts a new expense report into the expenses table and updates the mission’s status atomically. If any operation fails, the transaction is rolled back, undoing all changes.
// Method of expenseDAO business object
public void addExpenseReport(ExpenseReport expenseReport, Mission mission) throws SQLException, BadMissionForExpReport {
// Check that the mission exists and is in OPEN state
...
MissionsDAO missionDAO = new MissionsDAO(connection);
String query = "INSERT into expenses (food, accomodation, transport, mission) VALUES(?, ?, ?, ?)";
// Delimit the transaction explicitly
connection.setAutoCommit(false); // Override default commit after each statement
try (PreparedStatement pstatement = connection.prepareStatement(query);) {
pstatement.setDouble(1, expenseReport.getFood());
pstatement.setDouble(2, expenseReport.getAccomodation());
pstatement.setDouble(3, expenseReport.getTransportation());
pstatement.setInt(4, expenseReport.getMissioId());
pstatement.executeUpdate(); // 1st update
// 2nd update, to be executed atomically
missionDAO.changeMissionStatus(expenseReport.getMissioId(), MissionStatus.REPORTED);
connection.commit();
} catch (SQLException e) {
connection.rollback(); // if update 1 OR 2 fails, roll back all work
throw e;
}
} finally {
connection.setAutoCommit(true);
} // reset to standard-
Explicit Transaction Control
setAutoCommit(false): Prevents the database from committing changes after every statement.commit(): Commits all changes as a single unit.rollback(): Undoes all changes in the transaction when an exception occurs.
-
Ensuring Consistency
The method updates two tables (expensesandmissions). These operations must either both succeed or both fail to maintain consistency. -
Proper Resource Management
try-with-resources: Ensures that thePreparedStatementis closed automatically.finally: Restores the default auto-commit mode, leaving the connection in a consistent state.
While JDBC provides low-level control over transactions, modern frameworks like JPA (Java Persistence API) and EJB (Enterprise JavaBeans) simplify these operations significantly by abstracting the transactional logic:
-
Automatic Mapping of Query Results
JPA enables automatic mapping of query results to Java objects, eliminating the need to manually copy data between the database and application objects. -
Seamless Object Creation
In JPA, persisting an object automatically creates the corresponding database record without manual SQL handling. For instance, callingentityManager.persist(expenseReport)would insert a new record for anExpenseReport. -
Transparent Object Updates
Changes made to a managed object are automatically synchronized with the database. For example, updating anExpenseReportobject’s fields and committing the transaction would update the corresponding database row. -
Connection and DAO Transparency
Frameworks handle connection pooling and dispatching, reducing boilerplate code. DAOs are often replaced by repositories or services that integrate tightly with the persistence context. -
Declarative Transactions
With annotations like@Transactional, methods can join or create transactions automatically, simplifying code:
@Transactional
public void addExpenseReport(ExpenseReport expenseReport, Mission mission) {
// JPA handles transactions and connections seamlessly
}Problem-Solution Matrix
| Requirement | Technology | How to |
|---|---|---|
| Avoiding the copy of data from query result cursor to native application types | JPA Object Relational Mapping | Java classes and relational tables can be associated via a declarative mapping |
| Avoiding the copy of data from program to UPDATE and INSERT SQL statement | JPA Object Relational Mapping | Creation and changes to Java objects can be persisted automatically |
| Avoiding the manual management of connections | JTA transactions, EJB dependency injection | Connection object masked by higher level objects (EntityManager) automatically injected into the components that need them |
| Avoiding manual demarcation of transactions | JTA transactions, EJB container managed transactions | Global transactions managed by the container and propagated to object methods that can “join” them |
Data Extraction with JPA
When using JPA (Java Persistence API), data extraction becomes seamless by leveraging the entity relationships defined in your model. In this example, we retrieve a list of missions associated with a specific reporter using JPA’s EntityManager to query the database and map the result to Java objects automatically.
// Method of missionService EJB
public List<Mission> findMissionsByUser(int userId) {
// Find the Reporter entity by its primary key (userId)
Reporter reporter = em.find(Reporter.class, userId);
// Retrieve the list of missions related to the reporter
List<Mission> missions = reporter.getMissions();
return missions;
}Here, the findMissionsByUser method uses the EntityManager’s find method to look up a Reporter entity by its userId. Once the Reporter object is loaded, you can directly access its associated missions (assuming a mapped one-to-many relationship between Reporter and Mission). This eliminates the need for manually creating SQL queries or handling result sets.
Data Creation with JPA
JPA simplifies object creation and database persistence. Instead of manually writing SQL INSERT queries, you can instantiate an entity and rely on the EntityManager to persist it in the database. In this example, we add a new mission and link it to a reporter.
public void createMission(Date startDate, int days, String destination, String description, int reporterId) {
// Find the Reporter entity by its primary key
Reporter reporter = em.find(Reporter.class, reporterId);
// Create a new Mission object
Mission mission = new Mission(startDate, days, destination, description, reporter);
// Add the mission to the reporter's mission list (assuming a bidirectional relationship)
reporter.addMission(mission);
// Persist the reporter, which will also persist the associated mission
em.persist(reporter);
}In the createMission method:
- The
Reporterentity is loaded using theEntityManager’sfindmethod. - A new
Missionobject is created and associated with the reporter. - The
em.persist(reporter)call persists both the reporter and the new mission due to the cascade setting on the relationship (if configured in the entity mapping). There is no need for explicitINSERTstatements.
Data Modification with JPA
Data modification with JPA is simple and efficient. Once an entity is retrieved, you can modify its fields and the changes will be automatically tracked by the EntityManager. Upon committing the transaction, JPA will automatically synchronize these changes with the database.
// Method of the missionService business object
public void reportMission(int missionId, MissionStatus missionStatus) {
// Retrieve the mission entity by its primary key
Mission mission = em.find(Mission.class, missionId);
// Update the mission status
mission.setStatus(MissionStatus.REPORTED);
// JPA automatically tracks changes to the entity and updates the database during commit
}In the reportMission method:
- The
Missionentity is fetched using theEntityManager’sfindmethod. - The mission’s status is updated, and JPA will automatically track this change.
- The changes are persisted during the transaction commit, without requiring any SQL update statements.
Transaction Management in JPA
JPA provides an automatic and declarative way to manage transactions. By default, JPA operates within the context of a transaction, and changes made to entities are automatically committed when the transaction completes successfully.
Here is an example of handling a transaction while adding an expense report to a mission:
public void addExpenseReport(ExpenseReport expenseReport, int missionId) throws BadMissionForExpReport {
// Check that the mission exists and is in OPEN state
Mission mission = em.find(Mission.class, missionId); // Retrieve the mission entity
if (mission == null || mission.getStatus() != MissionStatus.OPEN) {
throw new BadMissionForExpReport("Mission cannot introduce expense report");
}
try {
// The code inside this block is transactional!
mission.setStatus(MissionStatus.REPORTED); // Update mission status
mission.setExpense(expenseReport); // Associate the expense report with the mission
em.persist(mission); // Persist the updated mission entity
} catch (PersistenceException e) {
e.printStackTrace(); // Used for debugging
}
}In the addExpenseReport method:
- A transaction is automatically managed by the JPA persistence context. If the transaction completes successfully, the mission’s status is updated, and the expense report is linked to the mission.
- If any exception occurs during the process, changes made during the transaction are rolled back, ensuring data consistency.
JPA allows you to focus on the business logic, and it automatically handles the transaction lifecycle, commit, and rollback. In more complex cases, you can use annotations like @Transactional for declarative transaction management. This ensures that the database operations within the method are handled within a single transaction, promoting data integrity.