Before diving into Bison, it’s essential to be comfortable with a few advanced features of the C language that are fundamental to building multi-part programs like compilers.
Real-world programs are rarely contained in a single file. Instead, they are built from multiple source files to organize code logically and promote reusability. The process involves two key steps:
Steps
Compilation: Each source file (e.g., main.c, library.c) is compiled separately into an object file (e.g., main.o, library.o). An object file contains machine code (binary) but is not yet a complete, executable program. It may contain unresolved references to functions or variables defined in other files.
Linking: The linker’s job is to combine multiple object files into a single executable program. It resolves the cross-file references, connecting function calls to their definitions.
Consider a simple program split into two files: library.c, which defines a function, and main.c, which calls it.
// filename: main.c// Prototype of the function from library.cvoid hello(void);int main() { hello();}
To build the final program, you would compile and link them together in a single step using a command like:
cc -o program main.c library.c
This command tells the C compiler (cc) to compile both source files and link them into an output executable named program.
Notice that in the main.c example above, we had to manually declare the function prototype void hello(void);. If hello() were called from many different files, we would have to repeat this declaration in every single one. This is error-prone and difficult to maintain.
The solution is to use header files (conventionally with a .h extension). A header file contains shared declarations, such as function prototypes, type definitions, and macros, that are relevant to a specific .c file. Other files can then simply #include this header to gain access to those declarations.
Let’s refactor our example using a header file.
// filename: library.h// Prototype for the hello functionvoid hello(void);
// filename: library.c#include <stdio.h>#include "library.h" // Include the header file to get the prototypevoid hello(void) { printf("hello!\n");}
// filename: main.c#include "library.h" // Include the header file to get the reference for hello()int main() { hello();}
Now, the build command remains the same. It’s crucial to understand that header files are not passed to the compiler directly. The #include directive is a preprocessor command that effectively copies and pastes the content of the header file into the source file before compilation begins.
A union is a compound data type that allows you to store different data types in the same memory location. They are similar to structs, but with one critical difference:
Structs allocate memory for all their members sequentially.
Unions allocate only enough memory to hold their largest member, and all members overlap in that memory space.
The consequence is that assigning a value to one member of a union invalidates the values of all other members. This makes unions useful for representing a value that can be one of several different types at any given time, but never more than one simultaneously.
// Define a union that can hold either an int or a doubletypedef union { int a; double b;} an_union_t;// Example usage of the unionan_union_t an_union; // Declare a variable of type an_union_tan_union.a = 10;/* At this point, an_union.b contains garbage data */an_union.b = 999.5;/* Now, an_union.a contains garbage data */
This concept is central to how Bison manages the values associated with different tokens and grammar rules.
Introduction to Syntactic Analysis
With the C preliminaries covered, we can now focus on the core topic: syntactic analysis. The American Heritage Dictionary defines syntax as:
"The study of the rules whereby words or other elements of sentence structure are combined to form grammatical sentences."
In computer science, a language’s syntax is defined by a grammar. The purpose of syntactic analysis is to take the stream of tokens produced by the lexer and determine if they form a valid sentence according to the grammar. A syntactic analysis must:
Identify grammar structures: Recognize patterns like expressions, statements, and blocks.
Verify syntactic correctness: Ensure the sequence of tokens conforms to the language rules.
Build a derivation tree: Construct a tree structure (often an Abstract Syntax Tree or AST) that represents the input’s grammatical structure.
It is important to note what syntactic analysis does not do: it does not determine the meaning of the input. That is the task of the subsequent phase, semantic analysis.
The input to the parser is a stream of terminal symbols, which are the tokens produced by the lexer (e.g., IF, NUMBER, IDENTIFIER). The parser uses these to derive nonterminal symbols (e.g., expression, statement), which represent higher-level grammatical constructs, through a process called reduction.
Bison: The GNU Parser Generator
Bison is a standard tool for generating parsers (syntax analyzers). It is an improvement on an earlier, influential tool called YACC (Yet Another Compiler-Compiler) and is designed to work seamlessly with the scanner generator Flex.
Bison generates an LR parser, a type of bottom-up parser that reads input from Left to right and produces a Rightmost derivation. Specifically, it is based on LALR(1) theory, a practical variant of LR(1) that is powerful enough for most programming languages. Internally, the generated parser implements a push-down automaton, using a stack to keep track of its state during the parsing process.
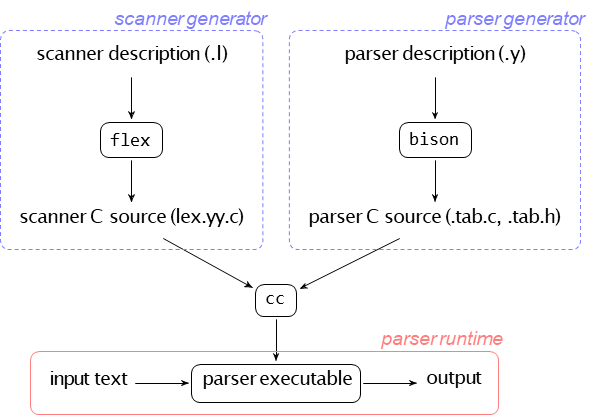
The process of building a parser with Flex and Bison involves several steps, as illustrated below.
Scanner Generation: You write a scanner description in a .l file. The flex tool processes this file to generate C source code for a scanner, typically named lex.yy.c.
Parser Generation: You write a parser description (a grammar) in a .y file. The bison tool processes this file to generate C source code for a parser (.tab.c) and a corresponding header file (.tab.h) containing token definitions.
Compilation: The C compiler (cc) compiles both the generated scanner source (lex.yy.c) and the generated parser source (.tab.c) and links them together to create a final parser executable.
Execution: This executable can then process input text, performing syntactic analysis and producing output based on the actions you defined in your grammar.
Important
To easily build the final executable, you can use a Makefile with rules to automate the generation and compilation steps.
Where we first define some variables for the source files and the output executable name. The all target depends on the final executable, which in turn depends on the generated C source files. The pattern rules specify how to generate the parser and scanner source files from their respective descriptions. The clean target removes all generated files. To build the parser, you simply run make.
Alternatively, you can execute the commands manually in the terminal:
flex *.lbison -d *.ycc -o output *.tab.c *.yy.c
Inside the Parser
The generated parser orchestrates the entire process at runtime.
The parser is the controlling component. When it needs a token, it calls the scanner.
The scanner reads the input text and returns the next token to the parser.
The parser analyzes the sequence of tokens to decode grammar derivations. For each derivation it recognizes, the parser executes a corresponding semantic action (a piece of C code you provide).
These semantic actions are responsible for producing the final output of the program, whether it’s a calculated result, generated code, or an abstract syntax tree.
The Bison Interface
The code generated by Bison has a well-defined interface:
Generated Files: Bison produces a C file (e.g., parser.tab.c) and a header file (e.g., parser.tab.h). The header is crucial for sharing token definitions with the scanner.
Main Parsing Function: The primary function is int yyparse(void);. You call this function from your main() to start the parsing process.
Token Reading: To get tokens, yyparse() repeatedly calls the function int yylex(void);. This is the exact same function that Flex-generated scanners provide, which is why the two tools integrate so perfectly.
Basic Features of a Bison Specification
A Bison input file (.y) has a structure that is very similar to a Flex file. A Bison file is divided into four sections, separated by %%.
Section
Separator
Description
Prologue
%{ ... %}
C code that is copied verbatim to the beginning of the generated C file. This is used for #include directives, global variable declarations, and helper function prototypes.
Definitions
Bison declarations for tokens, operator precedence, and the data types of semantic values.
Rules
“
Additional C code copied to the end of the generated file, typically for main(), yyerror(), and other helper functions.
%{ /* Prologue: C declarations */%}/* Definitions Section: Bison declarations *//* User Code Section: Additional C code */
The Definitions Section: Declaring Tokens
The most fundamental declaration in the definitions section is %token, which declares a terminal symbol.
%token IF ELSE WHILE DO FOR
When Bison processes this, it generates a header file (.tab.h) that defines a unique integer code for each token. This allows the scanner to return these codes.
Partial contents of the generated .tab.h file:
enum { /* ... */ IF = 258, ELSE = 259, WHILE = 260, /* ... */};
The scanner must #include this header file so it can use these symbolic names (e.g., return IF;) instead of magic numbers.
The Rules Section: Grammar and Semantic Actions
This section contains the grammar rules in a format similar to Backus-Naur Form (BNF). The left-hand side (l.h.s.) of a rule is a nonterminal, followed by a colon (:), and then one or more right-hand side (r.h.s.) alternatives, separated by a pipe (|). The rule ends with a semicolon (;). By default, the nonterminal on the l.h.s. of the first rule is the axiom (or start symbol) of the grammar.
Example: Simple Parser for Configuration Files
sections : sections section | /* empty */ ;section : LSQUARE ID RSQUARE options ;options : options option | option ;option : ID EQUALS NUMBER | ID EQUALS STRING ;
Just like Flex, Bison allows you to specify semantic actions—blocks of C code enclosed in {}—that are executed whenever a rule is recognized. An action is placed at the end of a rule alternative.
Example with Semantic Actions
option : ID EQUALS NUMBER { /* associate the number with * the specified key */ } | ID EQUALS STRING { /* same but for string values */ } ;
Semantic actions are executed only after all components of their corresponding rule have been fully recognized. Because Bison parsers work bottom-up, the execution order follows the construction of the syntactic tree from the leaves up to the root.
Consider a parse tree for a simple input. The semantic actions for the lowest-level rules (leaves) are executed first, followed by the actions for the rules that depend on them, and so on, until the action for the root rule is executed last.
Mid-Rule Semantic Actions
Bison also allows actions to be placed in the middle of a rule. Internally, Bison normalizes the grammar by transforming a mid-rule action into an end-of-rule action for a new, empty rule.
This transformation can sometimes introduce conflicts (like shift/reduce conflicts) into the grammar that were not present before, so mid-rule actions should be used with care.
Managing Semantic Values
Recognizing a grammar structure is often not enough; we need to know the actual value associated with it. For example, when the lexer finds a number, the parser needs to know which number (e.g., ‘1234’ is different from ‘5432’). This is handled using semantic values.
For tokens, the semantic value is assigned by the lexer.
For non-terminals, the semantic value is computed and assigned by a semantic action.
This allows information to flow up the parse tree.
Since tokens and non-terminals can have values of different types (e.g., integers, strings, custom structs), Bison uses a C union to manage them.
%union Declaration: You specify all possible data types in a %union block in the definitions section.
Type Association: You associate a type from the union with each token (%token <type>) and each non-terminal (%type <type>).
// 1. Define all possible types for semantic values%union { int int_val; const char* str_val; option_t option_val; // A custom struct type}// 2. Associate types with terminals (tokens)%token <str_val> ID STRING%token <int_val> NUMBER// 3. Associate types with non-terminals%type <option_val> option
Internally, Bison uses this %union declaration to create a typedef union YYSTYPE. The global variable yylval, used for communication between the scanner and parser, will be of this type.
// Code generated by Bison based on the %union abovetypedef union YYSTYPE { int int_val; const char* str_val; option_t option_val;} YYSTYPE;extern YYSTYPE yylval;
The Flex scanner is responsible for setting the semantic value of a token before returning its code. It does this by assigning to the appropriate field of the global yylval variable.
Example Flex Semantic Action
[0-9]+ { yylval.int_val = atoi(yytext); // Set the integer value return NUMBER; // Return the token code }
Inside a semantic action, you can access the semantic values of the components of the rule using special variables:
$$: The semantic value for the non-terminal on the l.h.s. of the rule. Your action should typically assign a value to this.
$1, $2, $3, …: The semantic values for the symbols on the r.h.s. of the rule, from left to right.
Here, $1 is LSQUARE, $2 is ID, $3 is RSQUARE, $4 is the instruction { printf("%s", $2); } and $5 is options. The action assigns a value to $$ by calling create_section() with the ID and options.
Integrating Flex and Bison
To successfully build a parser using both tools, follow these steps:
In the Flex Source File (scanner.l):
#include the header file generated by Bison (e.g., "*.tab.h") in the prologue section. This gives you access to the token definitions.
In the semantic actions for your rules, assign the token’s value to the correct member of the yylval union.
Return the token identifiers declared in the Bison file (e.g., return NUMBER;).
In the Bison Source File (parser.y):
Declare and implement the main() function in the user code section. This function should at least call yyparse().
Provide an error-reporting function, void yyerror(char *s), which Bison calls on a syntax error.
Compilation process:
To compile and link the Flex and Bison generated code, follow these steps:
Generate the scanner
Generate the parser and its header file
Compile and link everything together
flex scanner.lbison -d parser.ycc -o out lex.yy.c parser.tab.c
An RPN Calculator
To solidify the concepts from the previous section, let’s build our first complete program with Flex and Bison: an interpreter for a Reverse Polish Notation (RPN) calculator.
Example
RPN, also known as postfix notation, is a mathematical notation in which every operator follows all of its operands.
It has several properties that make it an excellent starting point for a parser:
Unambiguous: The order of operations is explicit, so parentheses are never needed.
Simple Grammar: The structure is straightforward and easy to describe with a context-free grammar.
Stack-Based: It is naturally evaluated using a stack, which aligns well with how parsers operate.
For example, the standard infix expression would be written in RPN as: .
The grammar for our calculator is very simple. A program consists of multiple lines of input. Each line can be empty or contain an expression, which is either a number or two preceding expressions followed by an operator.
program : lines NEWLINE ;lines : lines line | ε ;line : exp NEWLINE ;exp : NUMBER | exp exp PLUS | exp exp MINUS | exp exp DIV | exp exp MUL ;
The Bison Parser (rpn-calc.y)
The parser is the heart of our interpreter. Its semantic actions will perform the calculations directly.
// Definitions Section%{ #include <stdio.h> int yylex(void); void yyerror(char *);%}/* Define the semantic value type */%union { int value;}/* Associate types with tokens and non-terminals */%token <value> NUMBER%token NEWLINE PLUS MINUS MUL DIV%type <value> exp// User code section/* Error reporting function */void yyerror(char *s) { fprintf(stderr, "Error: %s\n", s);}/* A main function is required to start the parser */int main() { yyparse(); return 0;}
This parser demonstrates several key features:
Semantic Actions for Calculation: The action { $$ = $1 + $2; } takes the values of the two preceding exp non-terminals ($1 and $2), adds them, and assigns the result back to the semantic value of the current exp rule ($$).
YYACCEPT: This macro tells Bison to end the parsing process successfully.
%empty: This special directive denotes an empty rule, allowing the lines non-terminal to match zero lines of input.
yyerror(): We must provide this function. Bison calls it when a syntax error is encountered.
The Flex Scanner (rpn-scanner.l)
The scanner’s job is to recognize numbers and operators and pass them, along with their semantic values, to the parser.
Notice how the scanner includes rpn-calc.tab.h to get the token definitions (like PLUS, NUMBER) and the yylval union declaration. When a number is matched, atoi() converts the text to an integer and stores it in yylval before returning the NUMBER token.
This program is an interpreter because it computes the value of the expression while it parses. The computation is immediate.
Building a Compiler: From RPN Interpreter to RPN Compiler
What if, instead of calculating the result immediately, we wanted to generate a program in another language (like C) that would perform the calculation when executed? This is the core function of a compiler.
The RPN Compiler (rpn-compiler.y)
The key change is in the semantic actions. Instead of performing arithmetic, they will now print C code. The semantic values will no longer hold computed results, but rather identifiers for temporary variables in the generated code.
%{ #include <stdio.h> int next_var_id = 1; int yylex(void); void yyerror(char *);%}%union { int value; /* For incoming numbers from the lexer */ int var_id; /* For tracking generated variable IDs */}%token <value> NUMBER%token NEWLINE PLUS MINUS MUL DIV%type <var_id> expd\\n\", v%d);\n", $1); } ;exp : NUMBER { $$ = next_var_id++; printf(" int v%d = %d;\n", $$, $1); } | exp exp PLUS { $$ = next_var_id++; printf(" int v%d = v%d + v%d;\n", $$, $1, $2); } | exp exp MINUS { $$ = next_var_id++; printf(" int v%d = v%d - v%d;\n", $$, $1, $2); } | exp exp MUL { $$ = next_var_id++; printf(" int v%d = v%d * v%d;\n", $$, $1, $2); } | exp exp DIV { $$ = next_var_id++; printf(" int v%d = v%d / v%d;\n", $$, $1, $2); } ;/* ...rest of the file (yyerror, main) */
This new program does not compute the value of the expression. Instead, it produces C source code that, when compiled and executed in turn, will compute the value.
This illustrates the fundamental distinction between an interpreter and a compiler and introduces two critical concepts: compile time and run time.
Definition
Compile Time
Computations performed in the compiler (our Bison program) to produce the compiled output. In our example, this includes incrementing next_var_id and executing the printf statements that generate the C code.
Run Time
Computations performed by the compiled program when it is later executed. In our example, this includes the actual arithmetic operations (v2 + v3, v1 - v6, etc.) performed by the generated C code.
Handling Ambiguity: Precedence and Associativity
Our RPN examples were simple because the notation is unambiguous. Most programming languages use infix notation, where operators are placed between their operands. This introduces ambiguity. Consider the expression . It could be parsed in two ways:
By convention, we know the second interpretation is correct because multiplication has a higher precedence than addition.
When operators have the same precedence, like in , we need associativity rules.
Left-associative: (most arithmetic operators)
Right-associative: is (assignment)
Non-associative: is a syntax error (comparison)
Encoding Precedence in BNF Grammars
A pure BNF grammar must encode these rules manually by introducing multiple non-terminals for different precedence levels and using recursion to define associativity.
/* Left-associativity is expressed with left-recursion */exp : exp PLUS term | exp MINUS term | term ;term : term MUL factor | term DIV factor | factor ;/* Parentheses reset the precedence level */factor : NUMBER | LPAR exp RPAR ;
This is verbose and hard to maintain. Bison provides a much simpler mechanism to resolve these ambiguities. We can write a simple, ambiguous grammar and declare the precedence and associativity of our tokens in the definitions section.
exp : NUMBER | exp PLUS exp | exp MINUS exp | exp DIV exp | exp MUL exp | LPAR exp RPAR ;
To resolve the ambiguity, we add declarations to the definitions section. These declarations list tokens in order of increasing precedence.
%left: Declares tokens that are left-associative.
%right: Declares tokens that are right-associative.
%nonassoc: Declares tokens that are non-associative.
Tokens on the same line have the same precedence. Lines that appear later have higher precedence.
/* PLUS and MINUS have the same, lowest precedence and are left-associative */%left PLUS MINUS/* MUL and DIV have higher precedence and are also left-associative */%left MUL DIV
The precedence of a grammar rule is determined by the precedence of the last terminal symbol in that rule. Bison uses these declarations to automatically resolve shift/reduce conflicts caused by ambiguity.
The Infix Calculator (infix-calc.y)
Here is the full parser for a simple infix calculator, using Bison’s precedence mechanism.
%{ #include <stdio.h> int yylex(void); void yyerror(char *);%}%union { int value; }%token <value> NUMBER%token NEWLINE PLUS MINUS/* Note: PLUS, MINUS, etc. don't need <value> since they have no semantic value */%token MUL DIV LPAR RPAR%type <value> exp/* PRECEDENCE DECLARATIONS */%left PLUS MINUS%left MUL DIV/* yyerror and main functions... */
This code is much cleaner and more intuitive than the version with multiple non-terminals.
How Precedence and Associativity Work
When a parser encounters an ambiguous situation, it faces a shift/reduce conflict. For the input , after parsing (stack: exp PLUS exp), the parser sees the lookahead token MUL. It has two choices:
Reduce: Apply the rule exp -> exp PLUS exp. This gives + higher precedence.
Shift: Push MUL onto the stack and wait for the next operand. This gives * higher precedence.
Bison resolves this conflict using the following algorithm:
Let be the grammar rule that could be reduced (e.g., exp -> exp PLUS exp). Its precedence is that of PLUS.
Let be the lookahead token that could be shifted (e.g., MUL).
Compare Precedence:
If , the parser will reduce.
If , the parser will shift. (This is our case: MUL > PLUS, so it shifts).
Compare Associativity (if precedences are equal):
If the associativity is %left, the parser will reduce (to evaluate from the left).
If the associativity is %right, the parser will shift (to evaluate from the right).
If it is %nonassoc, it is a syntax error.
Context-Dependent Precedence: The Unary Minus
A classic problem is the unary minus. In , the unary minus should have higher precedence than multiplication, so it is parsed as . However, in , the binary minus has lower precedence than multiplication. The MINUS token needs two different precedences depending on its context.
Bison’s %prec directive allows you to override a rule’s default precedence.
The strategy is to:
Define a “dummy” token in the precedence hierarchy that has the desired precedence level for the unary operator. This token doesn’t need to be returned by the lexer.
In the grammar rule for the unary operator, use %prec to assign it the precedence of the dummy token.
/* ... token declarations ... */%left PLUS MINUS%left MUL DIV%right UMINUS /* A dummy token for unary minus, with highest precedence */%%exp : /* ... other rules ... */ | MINUS exp %prec UMINUS { $$ = -$2; } /* Unary minus rule */ ;
Here, the rule MINUS exp would normally have the precedence of MINUS. However, %prec UMINUS tells Bison to treat this specific rule as if its precedence were that of UMINUS, which is higher than MUL and DIV. This correctly resolves the ambiguity, ensuring is parsed correctly without affecting the precedence of the binary minus.