Regular languages, while foundational in the study of formal languages and automata theory, have notable limitations that constrain their expressive power.
One of the fundamental limitations is their inability to capture certain types of patterns that require a more complex structure.
For instance, consider the language
This is evident when examining the pattern
Generative Grammar and Syntax
To define a formal language, one can employ a set of syntactic rules that facilitate the generation of valid phrases. These rules, when applied repeatedly, form what is known as a generative grammar.
A prime example of such a grammar can be found in the definition of palindromes. The language of palindromes, denoted as
In this case, the grammar can be defined with several rules:
- The empty string is a valid phrase, represented as
. - A phrase can be constructed by enclosing another phrase with the letter
, expressed as . - Similarly, a phrase can also be enclosed with the letter
, given by the rule .
To illustrate the derivation process (denoted as
- Starting with the non-terminal symbol
, we can derive it to . - Continuing, we replace
with , and then with to yield the string .
The transformation can be visualized as follows:
The list of palindromes can be represented in a formal manner as follows:
Within this grammatical framework, we identify non-terminal symbols that play crucial roles in the language’s structure. The symbol
Context-Free Grammar (BNF - Backus-Naur Form - of Type 2)
A context-free grammar (CFG) is a type of formal grammar particularly useful in describing the syntax of programming languages and natural languages. It is formally defined using four distinct components, each playing a crucial role in the grammar’s structure. These components are:
- Non-terminal Alphabet (
): This is a set of non-terminal symbols that represent different syntactic classes (or categories) within the language. Non-terminal symbols are placeholders for patterns that can be further expanded into terminal symbols or other non-terminal symbols. - Terminal Alphabet (
): This is the set of terminal symbols, representing the actual characters or tokens that make up the valid strings of the language. These are the “building blocks” of the phrases in the language, and once they appear, they cannot be further expanded. - Set of Production Rules (
): The production rules define how non-terminal symbols can be replaced by combinations of terminal and non-terminal symbols. Each rule specifies a pattern that can be transformed into another form, guiding the generation of valid strings. - Axiom (
): The axiom is a particular non-terminal symbol that serves as the starting point for generating sentences or phrases in the language. It is the initial symbol from which all derivations begin.
Each production rule in the set
is a non-terminal symbol. is a string consisting of both terminal and non-terminal symbols. The notation represents any sequence (including the empty sequence) of elements drawn from the union of the non-terminal and terminal alphabets.
The production rules can be written as:
where the vertical bar
In this notation:
is a metasymbol that separates the left-hand side (a single non-terminal) from the right-hand side (a sequence of symbols). is a metasymbol that denotes alternatives in the production rules. represents the empty string, a valid option for many non-terminal expansions, allowing for flexible and recursive generation of phrases. denotes the union, although it’s used less frequently in grammar contexts compared to .
It is important to note that:
- The metasymbols
, , , are not part of the terminal or non-terminal alphabets; they are strictly used for defining the grammar. - The terminal and non-terminal alphabets must be disjoint sets, meaning that no element can appear in both sets. This ensures a clear distinction between the building blocks of phrases (terminals) and the abstract patterns or structures (non-terminals) used to generate those phrases.
Example of Context-Free Grammar
Consider a context-free grammar for a simple language of balanced parentheses. Let:
, where is the non-terminal symbol. , the set of terminal symbols representing the actual characters in the language. , the set of production rules, which states that can either be an empty string or a pair of parentheses enclosing another . Using this grammar, we can generate valid strings of balanced parentheses such as
, , , etc. The derivation for would be as follows:
Conventions in Context-Free Grammar
Context-free grammars employ specific conventions to define their syntax and structure clearly. These conventions help categorize various aspects of the grammar and provide a systematic way to represent the production rules.
The basic production rules for an if-phrase can be defined as follows:
-
General Production Rule:
-
Simplified Production:
In context-free grammars, symbols are classified into different categories:
-
Terminal Symbols: These are the basic characters that make up the language, represented as
. For instance, in programming languages, terminal symbols could be keywords and operators. -
Non-terminal Symbols: Represented as
, these symbols are used to define the structure of the language and can be replaced by other symbols according to the production rules. -
Strings of Terminal Symbols: These strings consist solely of terminal characters, represented as
. An example could be “if,” “else,” or “while.” -
Strings of Non-terminal and Terminal Symbols: Represented as
, these can contain both types of symbols. For instance, a string might look like “if A then B.” -
Strings of Non-terminal Symbols: Denoted as
, these strings consist only of non-terminal symbols, such as or .
Production rules summary
The following table summarizes different types of production rules along with their descriptions and encodings:
Type Description Encoding Terminal Right part contains terminals or is the empty string. Empty Right part is the empty string. Initial Left part is the axiom (starting symbol). Recursive Left part appears in the right part. Left Recursive Left part is a prefix of the right part. Right Recursive Left part is a suffix of the right part. Two-Side Recursive Combination of previous cases. Copy (or Renaming) Change of name. Linear Right part contains at most one non-terminal. Left Linear Non-terminal is a prefix. Right Linear Non-terminal is a suffix. Chomsky Normal Form Production is either one terminal or two non-terminals. Greibach Normal Form Always starts with a terminal, max length 2. Operator Normal Form Always has an infix terminal.
Examples of Production Types
Terminal Production:
This indicates that the non-terminal can produce the terminal symbol or yield an empty string. Recursive Production:
Here, can generate strings that start with and continue recursively, ultimately producing as a terminal. Left Recursive Production:
This structure indicates that can continue to generate more ' 's indefinitely, which can lead to infinite recursion. Chomsky Normal Form Example:
This rule specifies that can either be decomposed into two non-terminals and or can directly produce a terminal symbol .
Derivation and Generated Language in Context-Free Grammars
In the context of formal grammars, derivation refers to the process of generating strings from a non-terminal symbol by applying the production rules of a grammar. A context-free grammar
Definition
Consider two strings
and such that , where is the set of non-terminals, and is the set of terminals. The string is said to be derived from in the grammar , denoted as , if:
is a production rule in , for some strings and , and , where the non-terminal is replaced by .
Language Generated by a Grammar
The language generated by a non-terminal
where
The language generated by the grammar
This set includes all the strings composed only of terminal symbols that can be derived starting from the axiom.
Forms and Sentential Forms
A form generated by a grammar
where
Example: The Structure of a Book
Consider a grammar
that generates the structure of a book. The structure consists of a preface (denoted by terminal symbol ) and a series of chapters. Each chapter begins with a title (denoted by terminal symbol ) and contains a series of lines (denoted by terminal symbol ). The production rules are as follows:
where,
is the start symbol (axiom), and and are non-terminals. The non-terminal generates sequences of chapters, and generates sequences of lines.
- Non-terminal
can generate forms like , which results in the string . - Non-terminal
generates sentential forms like or . The language generated by the non-terminal
is , meaning it generates one or more occurrences of the symbol . The language , generated by the grammar , is described by the regular expression:
Equivalence of Grammars
Two grammars
Example: Equivalent Grammars
Consider two grammars
and that generate the same language:
In both grammars, the non-terminals
in and in generate the same language , indicating that the two grammars are equivalent.
Erroneous Grammars and Useless Rules
When constructing a grammar, it is essential to ensure that every non-terminal symbol is well-defined and contributes to the generation of strings in the language. A grammar is said to be in reduced form (or simply “reduced”) if both of the following conditions hold:
Property
Every non-terminal
is reachable from the axiom, i.e., there exists a derivation such that:
for some strings
and . Every non-terminal
generates a non-empty set of strings, meaning that:
If either of these conditions is not satisfied, the grammar may contain useless rules that do not contribute to generating any valid strings in the language.
Reduction of the Grammar
Grammar reduction is essential for simplifying a Context-Free Grammar by removing unnecessary components while preserving the language generated. The process consists of identifying undefined and unreachable non-terminal symbols and eliminating them. Additionally, recursion must be managed to prevent ambiguity or circular derivations.
-
Identifying Undefined Non-Terminal Symbols To identify non-terminal symbols that are undefined, i.e., those that do not derive terminal strings, we construct the set
of defined non-terminal symbols. The set is initialized with non-terminals that are expanded by terminal rules: where
is the set of production rules, and is the set of terminal symbols. Then, the following transformation is applied repeatedly until no more symbols can be added to
: This process ensures that all non-terminals in
derive terminal strings. -
Identifying Unreachable Non-Terminal Symbols The second phase involves identifying unreachable non-terminal symbols. These are non-terminals that cannot be reached from the axiom
. This can be reduced to finding the set of reachable non-terminals in a graph where: - There is a directed edge from
to if there exists a production . - The non-terminal
is reachable from the axiom if and only if there is a path from to in the graph.
Non-terminals that are unreachable from
are removed from the grammar, along with any production rules where they appear. - There is a directed edge from
-
Handling Circular Derivations Circular derivations (i.e., recursive rules where
) must be eliminated as they can lead to ambiguous behavior. A circular derivation allows for multiple ways to derive the same string, leading to ambiguity. For example: is equivalent to:
. Circularity may arise from null rules, such as and , which complicates derivations and leads to ambiguity.
Example of Non-Reduced Grammar
Consider the following grammars:
The first grammar is properly reduced, but the second and third grammars contain circular derivations or undefined non-terminals, making them not reduced.
Nullable Non-Terminal Symbols and Non-Null Normal Form
A nullable non-terminal
Definition
Formally,
is nullable if:
A set
if , if , where each .
For example, consider the grammar:
where, the nullable non-terminals are
A non-null normal form is one where no non-terminal, except possibly the axiom, is nullable. The axiom is nullable if and only if the language contains the empty string
Recursion and Infinity of the Language
Most formal languages used in practice are infinite, meaning they contain infinitely many strings. The feature that allows a context-free grammar (CFG) to generate infinitely many strings is its ability to allow recursive derivations, which lead to derivations of unbounded length.
In order for a grammar to generate infinitely many strings, it must have recursive rules, which allow a non-terminal symbol to eventually derive itself, either directly or indirectly. A production rule of the form:
is said to be recursive. If
For a language
generated by a grammar to be infinite, the grammar must be recursive.
This means that there must be at least one non-terminal
- Necessity: If there is no recursive derivation in the grammar, then every derivation would be of bounded length, and hence the language
would be finite (containing finitely many strings). - Sufficiency: If there is a recursive derivation of the form
, where is the start symbol and is a recursive non-terminal, then can derive at least one terminal string . Since is in reduced form and does not contain circular derivations, there are infinitely many derivations that yield distinct strings.
This can be illustrated as follows:
Thus, we can generate infinitely many derivations of the form:
This shows that the grammar allows an infinite number of different derivations, hence the language
Recursion and Acyclic Grammars
A grammar does not contain recursion if and only if the graph of the binary relation
Example: Finite Language with No Recursion
Consider the following grammar:
This grammar generates a finite language
because there are no recursive rules. graph LR S -- produce --> B -- produce --> CSince there is no recursive path from any non-terminal to itself, the derivations are of bounded length, and the language is finite.
Example: Arithmetic Expressions (Infinite Language)
Now, consider the following grammar for arithmetic expressions:
This grammar generates arithmetic expressions like:
The non-terminals in this grammar exhibit recursive behavior:
(expression) involves immediate left recursion, as in . (term) involves immediate left recursion, as in . (factor) is involved in indirect recursion, as can eventually produce an expression, and that expression can contain another . Since the grammar is in reduced form (i.e., it contains no undefined or unreachable symbols and no circular derivations), the language
is infinite.
Syntax Tree and Canonical Derivation
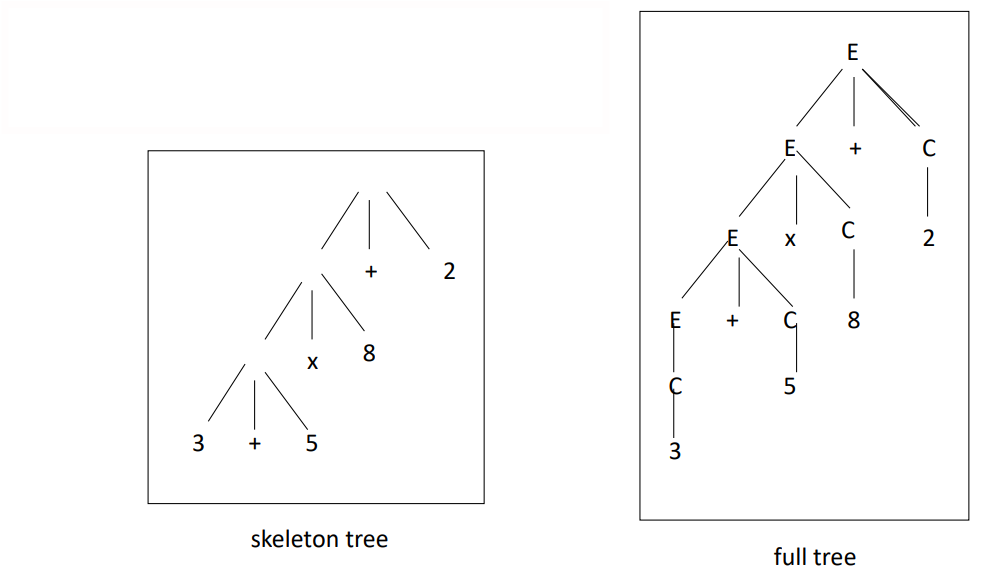
A syntax tree is a directed acyclic graph (DAG), where for every pair of nodes, there is exactly one unique path connecting them. This tree represents the derivation process in a formal grammar and gives a parent-child relationship between symbols or root-node-leaf structure, where the root represents the starting symbol (usually the axiom of the grammar) and the leaves represent terminal symbols or the final output string.
The sequence of the leaves, read from left to right, is called the frontier of the tree. Each node in the syntax tree corresponds to a production rule, and the degree of a node (also called node arity) is the number of children it has, which corresponds to the number of symbols on the right-hand side of the production rule.
The subtree with root
- The immediate siblings of
, - The siblings of the siblings (i.e., descendants of the siblings),
- And so on, recursively.
Thus, a subtree rooted at
A parenthesized representation of the syntax tree shows the nested structure of the derivation. Here’s an example:
This corresponds to a nested derivation, where:
derives , derives , derives the terminal symbol , - And operations like
and combine different subtrees in the derivation.
Leftmost and Rightmost Derivations
A derivation is a sequence of applications of production rules that transforms the start symbol (the root of the syntax tree) into a string of terminal symbols. Two common strategies for derivation are leftmost derivation and rightmost derivation.
In leftmost derivation, at each step, the leftmost non-terminal is expanded first. Here’s an example of leftmost derivation for a simple arithmetic expression grammar:
Explanation:
is expanded to . - The leftmost
is further expanded to , and so on. - The process continues by always expanding the leftmost non-terminal, until all non-terminals are replaced with terminal symbols.
In rightmost derivation, at each step, the rightmost non-terminal is expanded first. Here’s the corresponding rightmost derivation for the same expression:
Explanation:
- The rightmost non-terminal is expanded first.
- The process continues by expanding the rightmost non-terminal at each step.
- The rightmost derivation completes by eventually replacing all non-terminals with terminal symbols, similar to the leftmost derivation, but in a different order.
Property
- The root of the syntax tree is always the axiom (or start symbol) of the grammar.
- The frontier of the syntax tree is the sequence of terminal symbols obtained from the derivation, which forms the generated phrase.
- The degree of a node corresponds to the number of symbols on the right-hand side of the production rule applied to the non-terminal associated with that node.
Both leftmost and rightmost derivations lead to the same terminal string in the frontier, but the order in which non-terminals are expanded differs, which affects the construction of the tree.
Weak and Strong (or Structural) Equivalence
In formal language theory, two grammars can be compared based on how they generate the same set of strings and how they structure those strings. This leads to two concepts: weak equivalence and strong (or structural) equivalence.
-
Weak Equivalence Two grammars
and are weakly equivalent if and only if they generate the same language: This means that both grammars produce the same set of strings, but the way they structure these strings may differ significantly. Different syntactic trees or parse structures may be assigned to the same string, and one of these structures might not be ideal for the intended semantic interpretation of the language.
-
Strong (or Structural) Equivalence Two grammars
and are strongly equivalent (or structurally equivalent) if and only if: - They are weakly equivalent (i.e.,
). - They assign structurally equivalent syntactic trees to each string. In other words, the skeleton trees of the derivations must be identical for each string in the language.
- They are weakly equivalent (i.e.,
Warning
Thus, strong equivalence implies weak equivalence, but the opposite is not true: two weakly equivalent grammars might not be strongly equivalent.
The distinction between the two is important for tasks that require structural adequacy—such as parsing, translation, or semantic interpretation—where the structure assigned to a string influences its meaning.
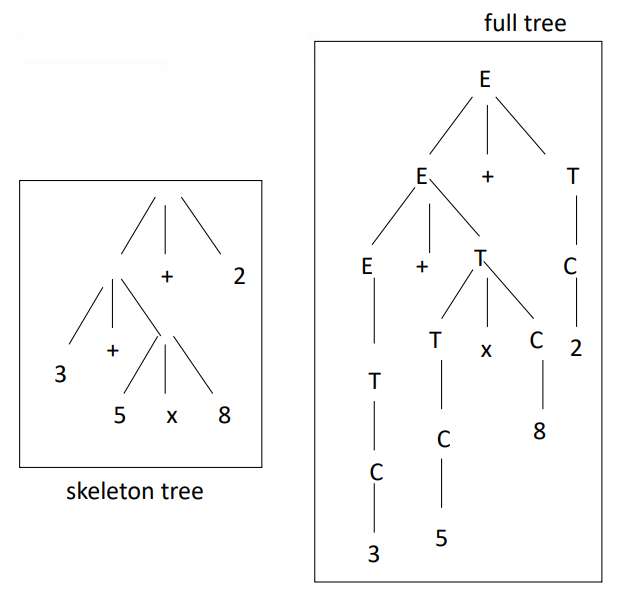
Example: Arithmetic Expressions
Consider two grammars for generating arithmetic expressions, particularly for the expression
. Grammar
:
Grammar
:
Both
and generate the same language of arithmetic expressions, so they are weakly equivalent. However, they generate different syntactic structures for the expression .
- For
, the structure is , which does not respect the conventional operator precedence (multiplication before addition). - For
, the structure is , which does respect operator precedence. Thus,
is structurally adequate, while is not. As a result, and are not strongly equivalent because their syntactic structures for the same phrase are not the same.
Grammar
A third grammar,
, might aim to capture the same structure as , but in a more explicit and detailed manner:
This grammar
includes more rules, but it captures the same structural information as . It is designed to generate syntactic trees that respect operator precedence while being more explicit. is structurally equivalent to and therefore strongly equivalent to .
In some cases, two grammars might not be structurally equivalent in the strict sense, but they are equivalent in a broader sense.
Consider the grammars:
Both generate the language
- In
, the tree is left-linear (i.e., all derivations are left recursive). - In
, the tree is right-linear (i.e., all derivations are right recursive).
While these grammars are not strictly structurally equivalent, they can be considered strongly equivalent in the large sense, because the syntactic trees they produce are mirror images of each other. This broader sense of equivalence abstracts away minor structural differences, focusing instead on overall structural similarity.
Parentheses Languages
Many artificial languages, such as programming languages or markup languages, include nested structures, where paired markers (parentheses or similar symbols) define substructures. These structures are recursive, meaning that the opening and closing symbols can enclose other such pairs, forming hierarchical levels.
Example
Examples of nested markers in different languages include:
- Pascal:
begin ... end- C:
{ ... }- XML:
<title> ... </title>- LaTeX:
\begin{equation} ... \end{equation}
The Dyck Language
The Dyck language is a formal language used to represent strings of properly nested parentheses (or similar symbols). It provides a general framework to model these nested structures. In the Dyck language:
- Alphabet:
- Examples of valid phrases:
The Dyck language can also be defined using cancellation rules: repeatedly remove adjacent matching pairs of parentheses from a string until no more matches are possible. If the result is the empty string, the original string is valid. Formally, this can be expressed as:
Definition
The Dyck language can be generated by a context-free grammar where different types of parentheses are allowed to nest:
In this grammar:
and represent an opening and closing pair of one type of parentheses. and represent another type of parentheses. - The non-terminal
produces balanced strings of nested parentheses.
The Dyck language is linear but non-regular, which means it can handle recursion but cannot be expressed with regular expressions or finite automata.
Example: Subset Language
A simple subset of the Dyck language is the language
of matched pairs of parentheses:
This language can be generated by the grammar:
However,
does not allow multiple levels of nested parentheses—it only supports one pair of matched parentheses at a time. This makes it a subset of the more general Dyck language.
Regular Composition of Free Languages
The family of free languages (which includes the Dyck language) is closed under certain language operations. This means that applying these operations to free languages will result in another free language. These operations include:
-
Union For two free languages
and , the union can be expressed as: To construct the grammar of the union
of two languages and : -
Concatenation To form the concatenation of two free languages
and , the grammar is modified as follows: -
Kleene Star To represent the Kleene Star operation on a language
, the grammar adds the rule: This generates all possible repetitions of strings from
.
Example: Union of Languages
Consider two languages:
Their union can be generated by combining the grammars of
and :
The union
is generated by:
The family of free languages is also closed with respect to string mirroring. Given a grammar
For example, if a rule is
, the mirrored rule would be .
The mirrored language consists of strings that are the reverse of the strings in the original language.
Ambiguity: Semantic versus Syntactic
In natural languages, ambiguity is common and often unavoidable because these languages attempt to describe a vast array of meanings with a finite set of words and structures. Ambiguity in natural language can occur both at the semantic level (where a word or phrase has more than one meaning) and the syntactic level (where a sentence can be parsed in more than one way). However, in artificial languages like programming languages or formal grammars, ambiguity is undesirable, as it can lead to confusion and incorrect interpretation. Therefore, ambiguity must be eliminated or controlled.
Syntactic Ambiguity
Syntactic ambiguity occurs when a phrase in a language has more than one valid syntax tree, representing different derivations or interpretations.
Definition
A grammar
is said to be ambiguous if there exists at least one string in the language it generates that has more than one syntactic structure.
Such ambiguity is problematic in formal languages because it can lead to unpredictable behavior in interpretation or computation.
Example: Ambiguity in Arithmetic Expressions
Consider the following grammar
for arithmetic expressions:
This grammar generates the string
. There are two possible derivations for this string:
First Derivation:
Second Derivation:
The corresponding syntax trees for these two derivations are different, showing that the string
is syntactically ambiguous. Therefore, the grammar itself is ambiguous.
The ambiguity arises because the grammar does not respect the standard precedence rule, which requires that multiplication should have higher precedence than addition. A more complex but unambiguous grammar for arithmetic expressions would correctly enforce operator precedence, though it would likely have more rules.
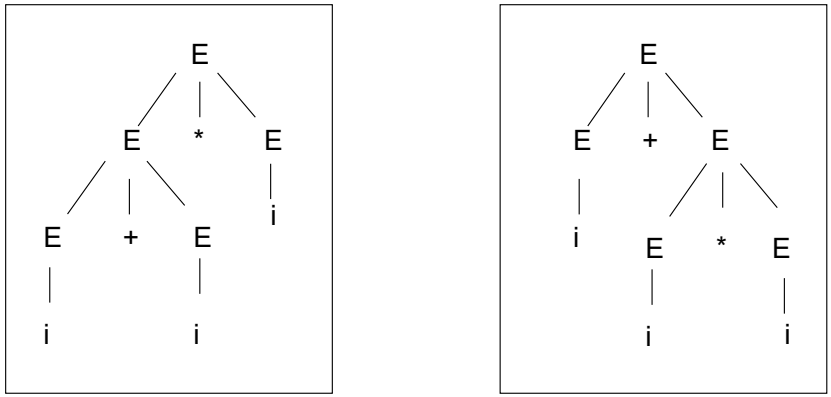
Ambiguity often emerges when a grammar is simplified. For example, while
Ambiguity Degree
The ambiguity degree of a phrase
The ambiguity degree of a grammar
Example: Increasing Ambiguity
Consider the phrase
. Its ambiguity degree is 2, as it can be parsed in two different ways:
Now consider the phrase
. Its ambiguity degree is , as it can be parsed in the following ways:
As the phrases become longer, their ambiguity degree tends to grow, often exponentially, making the problem of ambiguity more challenging to manage.
The Ambiguity Problem
A central problem in formal language theory is determining whether a given grammar is ambiguous. Unfortunately, deciding whether a grammar is ambiguous is an undecidable problem. This means there is no general algorithm that can determine whether an arbitrary grammar is ambiguous or not. In certain specific cases, ambiguity can be determined using specialized methods, but for most grammars, this is not possible in general.
The undecidability arises because any potential decision algorithm would need to examine increasingly long derivations, which becomes infeasible as the length of derivations grows. Theoretical information science demonstrates that this leads to the problem being undecidable.
While the ambiguity problem is undecidable in general, it is often possible to decide whether a specific grammar is ambiguous using ad-hoc methods tailored to the structure of the grammar. For practical purposes, examining all possible derivations of a grammar up to a certain length is often enough to determine if it is ambiguous. However, this approach does not provide a rigorous proof and might miss ambiguities that occur with longer strings.
Given the difficulty of identifying ambiguity after the fact, it is generally advisable to avoid ambiguity by design when constructing grammars.
Direction of Ambiguous Models and How to Remove Ambiguity
Ambiguity in formal grammars is often caused by the structure of the grammar itself, particularly through recursion mechanisms. One notable source of ambiguity is two-sided recursion, where a non-terminal symbol can recursively call itself both on the left and the right. This property can lead to multiple valid derivations for the same string, making it ambiguous.
In a grammar with two-sided recursion, the non-terminal can produce a sequence that allows for more than one derivation path. For example, if we have:
a single non-terminal can be replaced in multiple ways, leading to ambiguity.
Example 1: Ambiguous Grammar with Two-Sided Recursion
Consider the grammar
:
This grammar generates the phrase
through two different leftmost derivations:
- First Derivation:
- Second Derivation:
Despite generating the same string, these derivations correspond to different syntax trees, thus making the grammar ambiguous.
The language generated by this grammar is regular, expressed as:
To resolve the ambiguity, we can use a non-ambiguous version of the grammar. For instance:
- Non-ambiguous Grammar
:
- Alternatively, Grammar
:
Both grammars clearly establish a single structure for each string, removing the ambiguity.
Example 2: Ambiguity from Left and Right Recursion
Another type of ambiguity can arise from having both left and right recursion in the same grammar. Consider the grammar
:
This grammar allows for multiple interpretations when generating strings. For instance, the string
could be derived in different ways:
To eliminate this ambiguity, we can generate the two lists separately or orderly:
Separately Generating Lists: By isolating the left and right recursion:
The corresponding grammar becomes:
where
and . Orderly Generating Lists: Alternatively, you can design a grammar that enforces a strict order of generation:
where
. This approach ensures that all instances of
are generated before any , removing ambiguity while generating the same language .
Ambiguity of Union and Intersection
When dealing with the union of two languages
If the two languages share some phrases, the grammar
Conditions for Ambiguity:
- Disjoint Non-Terminal Sets: It is essential to ensure that the non-terminal sets of
and are disjoint. If they are not, the union grammar may generate a super-language that includes both and but also introduces additional strings that were not part of either language. - Intersection of Phrases: If a phrase
exists in the intersection and can be derived from both grammars and , then it is ambiguous in the context of the union grammar .
Example 3: Ambiguous Grammar
Consider the grammar
: In this case, both
and generate the same language , leading to ambiguity. For instance, the string can be derived in two ways:
- Using
:
Using
: To eliminate the ambiguity, we can define a non-ambiguous version of the grammar:
This grammar generates the same language
but does so without ambiguity.
Example 4: Another Ambiguous Grammar
Consider the grammar:
Language Generation:
generates the language where . generates the language where . In this case, the only ambiguous phrase is
(the empty string) since both and can derive it. A non-ambiguous version of this grammar can be:
This version explicitly defines the base cases for
and , ensuring that each phrase has a unique derivation within the grammar.
Languages That Are Inherently Ambiguous
A language is termed inherently ambiguous if every grammar that generates it is necessarily ambiguous. This means that for any equivalent grammar designed to generate the language, there are always ambiguous phrases derivable in multiple ways.
Example: Inherently Ambiguous Language
Consider the language defined as:
This can be expressed as the union of two languages:
and For any grammar
designed to generate , phrases like can be derived in two or more ways.
- Phrases can be generated by grammar
that checks :
- Or by grammar
that checks : The presence of multiple derivations from different grammars indicates that ambiguity is a fundamental characteristic of the language itself.
When concatenating two languages
Assuming that both
The phrase
Example: Concatenation of Dyck Languages
Consider the languages defined as follows:
The strings
belong to the concatenated language . We can define a grammar for this: In this case, a string like
can be generated by either or , leading to ambiguity.
To remove ambiguity, it is necessary to prevent situations where a suffix of one language overlaps with a prefix of another. A common approach is to introduce a separator that does not belong to the alphabets of either language. For instance, we can define the concatenation language
This separator enforces a clear distinction between the two languages.
Ambiguity can also arise in regular expressions and grammars themselves.
Example 1: Ambiguous Regular Grammar
Consider the grammar:
In this case, every phrase containing two or more
is ambiguous. To remove this ambiguity, we can enforce that the mandatory is the leftmost one. Unambiguous Version:
Example 2: Order of Rule Application
The following grammar is ambiguous:
This allows for multiple derivations to generate the same string:
To resolve this ambiguity, we can fix the order of application of the rules.
Unambiguous Version:
This structure ensures that strings are derived in a unique manner.
Grammar Normal Forms
Grammar normal forms play a crucial role in formal language theory and compiler design by imposing structural restrictions on the rules of a grammar while preserving the language it generates. Transforming a grammar into one of these standardized forms can greatly simplify theoretical proofs and aid in designing efficient parsing algorithms. By restructuring grammars into forms like Chomsky Normal Form (CNF), Greibach Normal Form (GNF), and others, we can optimize the syntax analysis process used in syntactic analyzers, often employed in compilers to validate the structure of programming languages.
Definition
A grammar
is typically defined by the tuple: where:
represents the set of terminal symbols, represents the set of non-terminal symbols, denotes the set of production rules, and is the start symbol (axiom) from which all derivations in the grammar begin.
Non-terminal Expansion
In many grammars, non-terminal symbols can be expanded through production rules to form different strings. This expansion can occur without affecting the language generated by the grammar. For instance, consider a rule
This expansion maintains the generative power of the grammar, preserving the ability to produce any strings derivable from the original rule.
Importantly, this transformation does not alter the structure of derivations but allows greater flexibility for restructuring grammars, particularly useful in constructing efficient parsers.
To prevent the start symbol
This ensures that all production rules use symbols from the set
Copy Rules (Categorization) and Their Elimination
Copy rules are production rules that allow one non-terminal to derive another, essentially copying or categorizing parts of the grammar by grouping similar syntactic elements. For instance, an iterative_phrase could include a while_phrase, for_phrase, or repeat_phrase, indicating that any of these types of phrases could fulfill the role of an iterative phrase.
The set
defines
While copy rules can simplify grammar definitions, they often result in deeper syntax trees, increasing the complexity of parsing. By eliminating these rules, we can obtain a grammar with a more efficient structure, reducing parsing depth without changing the language generated.
Example: Arithmetic Expressions Without Copy Rules
Consider an arithmetic expression grammar with copy rules:
This structure introduces multiple levels of non-terminals, where
can copy itself or pass through or as a copy sequence. The set , showing the derivation depth caused by copy rules. By removing these copy rules, we can flatten the structure while retaining the language:
In this equivalent grammar, the language generated remains unchanged, but unnecessary non-terminal dependencies have been eliminated, resulting in a simpler, more efficient grammar structure.
Chomsky Normal Form (CNF)
Chomsky Normal Form (CNF) is a standardized way of structuring grammars in formal language theory. A grammar is in CNF if every production rule is either a binary rule or a terminal rule, following a strict structure that allows for simplified parsing algorithms and theoretical analysis of languages. In this form, every production rule can be transformed to fit one of two patterns.
- The first is a binary rule where a non-terminal symbol produces exactly two non-terminal symbols. This rule is typically expressed as
, where and are all non-terminals in the grammar’s variable set . - The second form is a terminal rule, where a non-terminal symbol produces a single terminal symbol, expressed as
, with being a terminal from the alphabet .
An additional rule,
Transforming Left Recursion into Right Recursion
One important transformation in grammar design is the elimination of left recursion, a process vital for designing recursive-descent parsers that avoid infinite recursion. A grammar exhibits immediate left recursion if it includes production rules where a non-terminal on the left produces itself on the right-hand side, such as
The transformation is accomplished by first rewriting rules to eliminate left recursion. If a rule exists in the form
, where represents non-recursive terms. , where produces the recursive terms.
Example: Shifting Left Immediate Recursion to the Right
Consider the grammar:
Here, both
and are immediately recursive on the left. The transformation to eliminate the left recursion would look like this:
Real-time Normal Form and Greibach Normal Form
In formal language theory, Real-time Normal Form and Greibach Normal Form (GNF) provide additional structures for context-free grammars with particular parsing properties. Real-time normal form requires that each production rule begins with a terminal symbol, formulated as
-
Real-time Normal Form: Every rule begins with a terminal symbol:
-
Greibach Normal Form (GNF): A special case of the real-time normal form:
This structure is highly beneficial for top-down parsing algorithms, as each step in the derivation consumes one terminal symbol, aligning the length of the derivation sequence with the length of the input string. This property ensures that parsers operate in “real-time,” making GNF a useful standard for designing efficient parsing strategies.
Uni-linear Grammar (Type 3)
Uni-linear grammars, or Type 3 grammars, are grammars with production rules that grow in a single linear direction, either to the left or to the right.
- Right uni-linear rules follow the pattern
, where is a terminal string and is a non-terminal or empty. - Conversely, left uni-linear rules follow
, where is a terminal string.
Syntax trees generated by uni-linear grammars exhibit unbalanced growth, reflecting either left or right recursion. When uni-linear grammars include recursive derivations, they inherently develop recursive patterns based on the grammar’s orientation, either left or right. This unbalanced nature is particularly relevant when analyzing regular languages, as uni-linear grammars that lack recursion generate regular languages with more predictable and constrained structures.
The Role of Self-Inclusive Derivations
In more complex grammars, self-inclusive derivations—where a non-terminal can eventually produce itself within a string—add significant complexity. A self-inclusive derivation takes the form
where both
Such derivations do not occur in uni-linear grammars that produce regular languages, which are characterized by non-recursive derivations. However, in free grammars, self-inclusive derivations are fundamental in defining non-regular languages, such as those involving palindromes or Dyck languages. The presence or absence of self-inclusive derivations in a grammar can greatly affect the language’s structural complexity and is essential in determining whether the language generated is regular. Grammars free from self-inclusive derivations lead to regular languages, which are more manageable within computational models.
Closure Properties of Regular (REG) and Context-Free (LIB) Language Families
The closure properties of regular languages (
- Regular languages are closed under operations such as union, intersection, complementation, and the Kleene star operation, meaning that performing these operations on regular languages results in a regular language.
- Context-free languages, while more powerful, have different closure properties. They are closed under union and the Kleene star operation, but not under complementation and intersection (with an exception in cases where a context-free language intersects with a regular language).
Here:
and represent regular and context-free languages, respectively. denotes the Kleene star operation (zero or more repetitions). indicates the union of two languages. signifies the intersection of two languages.
For instance, if
is a context-free language and is a regular language, the intersection will still be context-free.
These properties allow for predictable behavior when constructing and manipulating languages, particularly in compiler design and formal language processing, where understanding the result of language operations can prevent computational issues or inefficiencies.
Free Grammars Extended by Means of Regular Expressions
Regular expressions (regexps) enhance the expressiveness and readability of free grammars, particularly in contexts where iteration and choice are important. By incorporating regexps into the right sides of grammar rules, we create extended free grammars (also known as Extended BNF or EBNF). These extended grammars are commonly used in technical languages, such as programming and markup languages, due to their clarity.
EBNF rules can be represented visually as syntax diagrams, which act as flow graphs for syntax analysis algorithms. This visual representation helps in understanding the structure of the grammar and the flow of parsing.
The family of
Example: List of Declarations for Variable Names
Consider variable names consisting of characters and integers. The alphabet is defined as
, where represents a variable name. Using a regular expression, we can express a list of variable declarations as:
The corresponding EBNF grammar might look like:
While this grammar is more structured, it is longer and less evident than the corresponding regexp, and the non-terminal names
and are arbitrary.
Extended EBNF Grammar
An extended free grammar (
where
Example: Simplified Algol-like Language
An example of an
grammar for a simplified Algol-like language might be:
Derivation and Syntax Tree in Extended Grammars
In
Given two strings
where there is a rule
This can be generalized to define multiple-step derivations and the overall generated language.
Example: Extended Derivation for Arithmetic Expressions
An extended grammar
that generates arithmetic expressions with the standard operators (in infix notation) is defined as follows: A leftmost derivation for the expression
would look like this: In BNF, the arity of a tree node can be unlimited, but larger trees typically have a lower depth.
Ambiguity in Extended Grammars
A non-extended but ambiguous grammar remains ambiguous when considered as extended (since
Example
For example, the expression:
is ambiguous because
can be derived in two ways: Both derivations lead to different parse trees, thus confirming the ambiguity.
Chomsky Classification
| Grammar | Rule Type | Lang. Family | Recognizer Device |
|---|---|---|---|
| Type 0: recursively denumerable languages | recursively denumerable languages | Turing machine | |
| Type 1: context-dependent languages | context-dependent languages | Turing machine with a memory tape of length equal to that of the string to be recognized | |
| Type 2: context-free or BNF form | context-free languages or BNF languages or algebraic languages | Pushdown automaton (non-deterministic) | |
| Type 3: right or left uni-linear | Regural or rational languages | Finite state automaton or sequential machine |
Footnotes
-
In this context, the arrow
serves as a meta symbol, distinguishing between the left and right sides of each grammar rule. ↩