Organizations pursuing efficient execution of complex projects operate within a new architectural paradigm that emphasizes the pivotal roles of both technology and organizational structure. This necessitates economic excellence alongside robust organizational frameworks. Beyond these two critical dimensions, a third area—the management of the software lifecycle—becomes paramount. This encompasses the comprehensive management of all processes, from the initial conceptualization and design phases of an idea to its ultimate production as a software solution.
DevOps emerges as a crucial topic in this context, representing not merely a methodology but rather a holistic collection of tools, practices, and, most significantly, a mindset. While agile methodologies like Scrum often pose challenges in implementation due to the requisite changes in professional behavior, DevOps offers a more tangible path to adoption. Its emphasis on leveraging specific toolchains can significantly streamline processes. However, successful implementation of DevOps also necessitates an understanding and embrace of its inherent shift in mindset, which is as vital as the technological adherence.
Challenges in Traditional Development and Operations
While Agile methodologies significantly accelerate application development, their effectiveness can be undermined by the traditional organizational separation between development and operations teams. In such classic corporate structures, the rapid pace of software creation achieved by development teams often clashes with the deployment bottlenecks imposed by distinct operations teams. Historically, this often led to situations where, despite a completed software package, its release was contingent upon the operational team’s availability and processes. This division was exacerbated by differing leadership, objectives, and priorities. Development teams typically prioritize speed, the delivery of new functionalities, and the adoption of new technology stacks.
Conversely, operations teams are primarily concerned with stability, reliability, and minimizing disruptions, viewing changes with a degree of suspicion due to their potential to introduce system failures. Furthermore, while development teams often seek unconstrained access to external services and components for integration, operations teams are frequently tasked with security responsibilities, leading to inherent conflicts and a persistent tension between these two crucial areas.
DevOps
The optimal solution to this organizational friction is the formation of a unified team that integrates individuals with operational expertise directly into the development process. This approach directly addresses the divergent priorities that historically created an organizational “wall.” Development, driven by innovation, speed, and flexibility, often contrasts with operations’ focus on reliability, security, and meticulous problem management.
In the past, operations typically employed a ticket-driven approach for software deployment; developers would submit a ticket through a ticketing system, place deliverables in a designated folder, and provide deployment documentation. This often led to partial understanding by operations, resulting in deployment challenges due to a lack of comprehension of the underlying changes. Such a fragmented process, driven by distinct objectives, frequently resulted in significant operational walls and inefficiencies. DevOps seeks to dismantle these barriers by fostering a collaborative environment, shared responsibilities, and automated processes across the entire software lifecycle, thereby moving beyond the limitations of traditional, siloed approaches.
The traditional approach to software deployment, often characterized by a ticket-driven system, introduces significant delays in the software development lifecycle.
A common scenario involves developers submitting a ticket for deployment, followed by a waiting period of potentially two weeks before the software is released into a production or even a testing environment, such as a Quality Assurance (QA) environment.
From Local to Production Environments
In the development of complex projects, a structured hierarchy of environments is typically employed.
- Local Development Environment: This is where individual developers write and test their code.
- Development/Integration Environment: A shared space for integrating software components from various teams, allowing for early detection of integration issues.
- Testing Environments: These may include dedicated test environments for unit and integration testing, as well as comprehensive Quality Assurance (QA) environments.
- Pre-Production Environment: This closely mirrors the production environment and is used for final testing before deployment.
- Production Environment: The live system where the software is ultimately deployed. The production environment is typically unique, while other environments may have multiple branches to facilitate parallel testing of different software versions or features.
The transition of software through these environments is orchestrated by sophisticated build and deployment systems. A build system typically interacts with a version control repository, such as Git, to retrieve the source code. Its primary function extends beyond mere compilation; it often involves executing extensive unit tests, which can be computationally intensive, requiring substantial memory and CPU resources.
For instance, testing thousands of unit tests for a single microservice can consume a significant amount of time, sometimes exceeding an hour, highlighting a potential bottleneck in the CD) pipeline if not optimized.
Once the build process is complete, the build system generates a deliverable, an artifact such as a Java Archive (JAR) file for a Spring Boot application or a pre-built Docker container. These deliverables are then stored in an artifact repository, serving as a centralized and versioned store. The deployment system subsequently retrieves these artifacts from the repository and deploys them to the designated target environment.
Automation plays a crucial role in this process.
For example, a new build can be automatically triggered every time a
git pushevent occurs in the repository, leading to automated building and deployment of the component, at minimum, to the development or integration environment. Furthermore, the system allows for programmed or manual deployment to other environments.
While deploying a single executable is relatively straightforward, moving 75 Docker containers across multiple environments, each potentially comprising numerous virtual machines (e.g., 20 VMs for production), presents a considerable challenge. While local environments are typically simplified with single instances of components, integration environments can begin to mirror the production architecture in terms of component configuration and availability.
The “Shift Left” Approach to Quality
A foundational principle within DevOps is the “shift left” approach to quality, representing a significant paradigm shift from traditional software development practices. Historically, the mindset dictated that once a software package and its accompanying documentation were created and a deployment ticket opened, any subsequent problems became the sole responsibility of the operations team. This reactive stance often led to delays and inefficiencies.
Definition
The “shift left” philosophy advocates for the proactive identification and resolution of defects as early as possible in the development lifecycle.
Ideally, source code should only be committed to the Git repository when it is deemed “production-ready,” having passed all local tests. Automated configurations within the development pipeline often enforce this, preventing faulty code from progressing to later stages.
This proactive stance necessitates maintaining a very high quality at the initial stages, ensuring adherence to the “definition of done” established by the Agile team. The integration environment serves as the initial stage for integration testing, where potential issues might first surface. Build systems are configured to provide immediate reports on build success or failure, promptly notifying developers of any breakage at the integration level. Addressing these integration-level problems becomes a top priority, as unresolved issues can impede the progress of numerous team members and disrupt the entire project.
Despite being two sides of the same coin, development and operations teams have historically expressed distinct grievances.
- Operations teams frequently lament the extensive time required to provision environments, a problem that was particularly acute in the past when physical hardware purchases could delay deployments by months. While the advent of virtual machines and cloud computing has significantly reduced these delays, discussions regarding machine sizing and resource allocation still necessitate coordination with operations.
- Operations personnel often find themselves working in emergency mode due to their frontline responsibility for service availability. They are typically the first point of contact for clients reporting system slowdowns or outages, which can lead to unpredictable workloads and hinder proactive planning. Development teams, on their part, often desire broad access to all environments, a request that clashes with the operations team’s imperative to maintain the security and stability of the production environment by restricting access.
To overcome these deeply ingrained challenges and accelerate the software delivery pipeline, it becomes imperative to foster enhanced collaboration between development and operations teams. The cornerstone of this improved collaboration lies in the strategic implementation of a robust toolchain that prioritizes the automation of the entire software lifecycle as much as possible, thereby streamlining processes and bridging the historical divide.
Principles and Practices
DevOps is founded upon a set of core values and principles that fundamentally redefine how software is developed and delivered. A key principle is the “shift left” mentality, which emphasizes anticipating and resolving problems as early as possible in the development lifecycle.
A crucial cultural shift within DevOps involves transcending the perception of development and operations as separate entities. Instead, they are viewed as interconnected teams, each with distinct objectives, yet collaboratively contributing to the same overarching project goal. A significant historical error was the exclusion of operations personnel during the initial project conception phases. This often led to operations teams encountering unforeseen resource constraints (e.g., insufficient disk space, memory, or CPU) at deployment time. By integrating operations specialists from the project’s inception, their unique insights into infrastructure requirements and operational constraints can be leveraged early, fostering enhanced collaboration and smoother deployments.
Furthermore, DevOps advocates for the shared ownership and collaborative decision-making regarding the implementation of the entire development pipeline, encompassing shared technologies, tools, methods, and practices.
Example
For instance, GitFlow represents a widely adopted practice for managing Git repositories, particularly in large teams. GitFlow defines a structured branching model that facilitates the concurrent development of new features, bug fixes, and releases, with distinct branches often corresponding to different environments (e.g., a
masterormainbranch for production,developfor pre-production, and feature-specific branches).
The Three Ways of DevOps
The successful implementation of a robust development pipeline in DevOps is often conceptualized through “The Three Ways,” as articulated by Gene Kim, Kevin Behr, and George Spafford in “The Phoenix Project.”
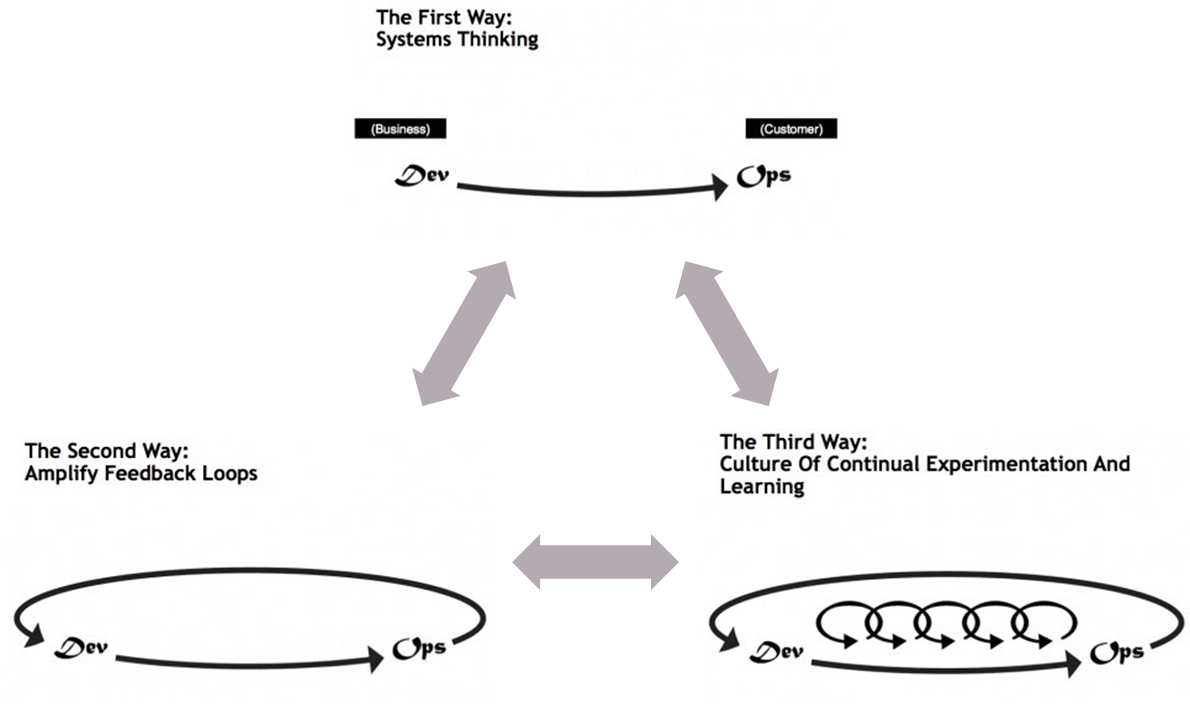
-
System Thinking (Flow): This principle emphasizes optimizing the entire value stream rather than individual components or isolated parts of the chain. It argues against hyper-optimizing one segment of the pipeline while neglecting bottlenecks elsewhere. The goal is to achieve a balanced flow and speed across the entire system, ensuring that quality and reliability are inherent at every stage.
-
Amplify Feedback Loops: This involves creating continuous and rapid feedback mechanisms throughout the software lifecycle. Feedback can come from various sources, including automated metrics, monitoring systems, and direct human input (e.g., customer reports of system crashes or performance degradation). The critical aspect is to ensure that this feedback is promptly disseminated to the relevant teams, particularly developers, enabling them to quickly diagnose and rectify issues.
-
Continuous Experimentation and Learning (Culture of Continuous Improvement): Even when excellent results are achieved, such as daily production deployments (a common occurrence in mature DevOps organizations, sometimes even multiple times a day without service disruption), there is always room for improvement. Through practices like Scrum retrospectives, teams analyze their processes, identify areas for improvement, and implement changes to further enhance the efficiency, reliability, and quality of their delivery pipeline. This involves dedicating time to proactively refine and optimize the pipeline.
Infrastructure as Code (IaC)
A cornerstone of DevOps automation is Infrastructure as Code (IaC). This philosophy posits that infrastructure configurations and provisioning should be managed using code and version control, just like application source code. Instead of manual configurations or ad-hoc scripting, dedicated configuration files and scripts are used to define and deploy environments. Tools like Ansible enable the automated, declarative provisioning and management of infrastructure, from individual servers to entire complex production environments.
The power of IaC becomes evident when considering the need for rapid environment recreation. For instance, the ability to rebuild a complete production environment from scratch in a minimal amount of time (e.g., within hours rather than days) is a critical capability. This is crucial for disaster recovery scenarios, such as the complete loss of a data center, or for establishing identical test environments. By versioning these infrastructure scripts, teams can track changes, collaborate effectively, and ensure consistency across environments. Regular testing of these IaC scripts by attempting to recreate environments is essential to validate their correctness and reliability.
The DevOps Toolchain
The cyclical nature of DevOps, often visually represented by an infinity loop, encapsulates the continuous integration, delivery, and feedback that are central to its philosophy. This loop typically comprises planning, coding, building, and testing phases (often depicted in blue) and then transitions into releasing, deploying, operating, and monitoring phases (often depicted in green or orange).
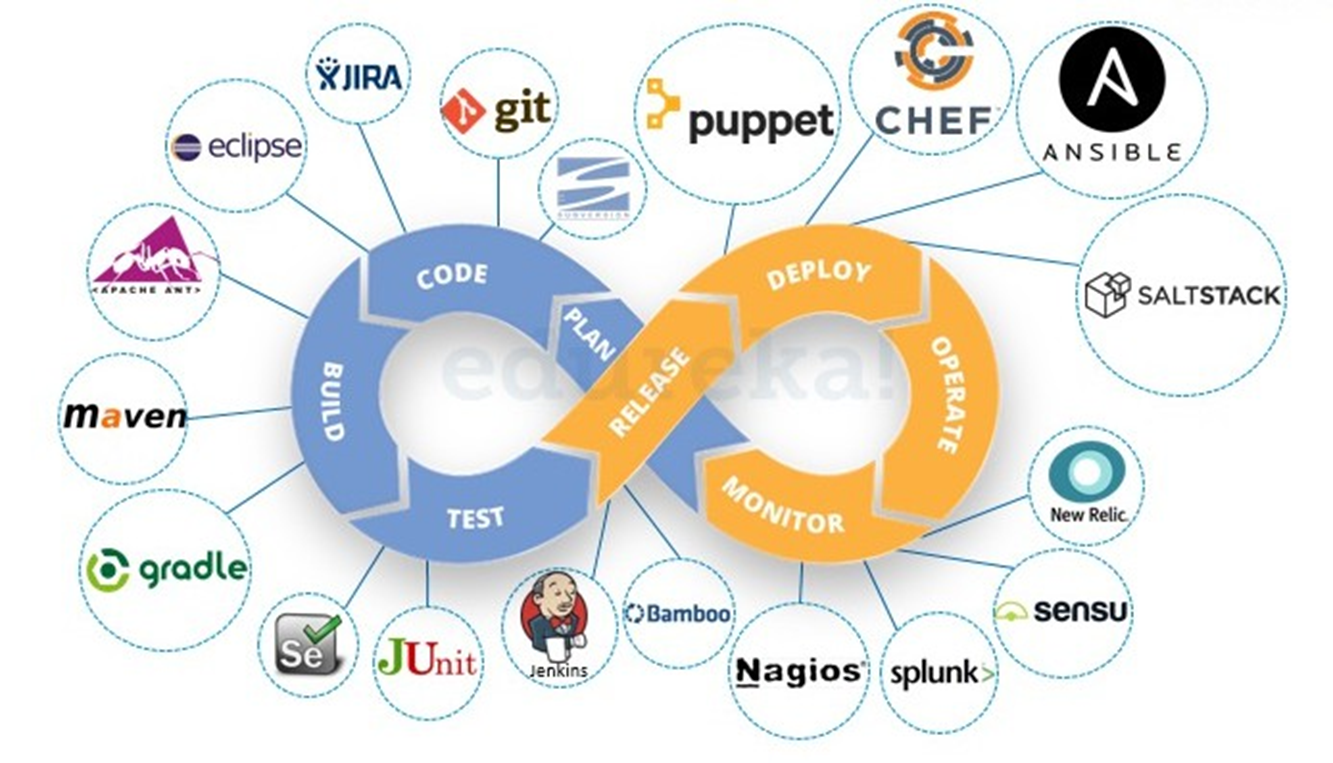
Orchestrating these interconnected processes requires a sophisticated DevOps toolchain, which integrates various tools, some long-established and others more contemporary, to facilitate automation and enhance visibility.
Numerous tools are available to orchestrate the DevOps pipeline.
- Automation servers like Jenkins and GitLab CI/CD are widely used for automating the build and deployment processes. These tools enable the execution of scripts, integration with version control systems, and orchestration of complex workflows.
- Software-as-a-Service (SaaS) platforms, such as GitHub Actions and Bitbucket Pipelines, offer cloud-based solutions for CI/CD, eliminating the need for self-hosting and management of build infrastructure.
- Artifact repositories, such as JFrog Artifactory or cloud-native alternatives, are essential for securely storing and managing build artifacts (e.g., JAR files, Docker images).
- Infrastructure automation tools like Puppet, Chef, and Ansible are indispensable for automating the provisioning, configuration, and management of servers and environments from scratch. These tools empower operations teams to align with the Infrastructure as Code (IaC) paradigm.
- Observability tools like New Relic, Splunk, Nagios, and Dynatrace provide deep insights into system performance by collecting and analyzing metrics, logs, and traces from various components across the entire system. These tools are crucial for diagnosing issues in complex distributed systems, where traditional monitoring methods may fall short.
Continuous Practices: CI/CD
Optimizing the software delivery flow necessitates accelerating the process while simultaneously preempting potential issues. This objective is central to the concepts of Continuous Integration (CI), Continuous Delivery (CD), and Continuous Deployment (CD), which are fundamental pillars of modern DevOps practices.
-
Continuous Integration (CI) refers to the practice of frequently merging developers’ code changes into a central repository. Each merge is then verified by an automated build and automated tests. The core idea is to integrate code continuously into a shared integration environment, enabling early detection and resolution of integration conflicts among software components developed by different teams.
-
Building upon CI, Continuous Delivery (CD) extends this principle by ensuring that software can be released to production at any time. This involves consistently deploying the software to various environments, including development, testing, and quality assurance (QA) environments, after successful integration. The goal is to make the software continuously available for rigorous testing by QA teams, smoke testing by dedicated test teams (to quickly identify major defects), and even pre-production validation by operations personnel.
-
Continuous Deployment (CD), the most advanced stage, takes Continuous Delivery a step further by automating the release of every change that passes all automated tests into production, without explicit human intervention. This means that once code is committed, integrated, and passes all automated checks in various environments, it is automatically deployed to the live production system. This high level of automation allows for extremely rapid deployment cycles, facilitating quick delivery of new features and immediate bug fixes to end-users.
The Testing Pyramid: Unit, Integration, and End-to-End Tests
To address the varying costs and complexities of different testing types, DevOps environments often adopt a testing pyramid strategy:
-
Unit Tests: Forming the broad base of the pyramid, unit tests are the most numerous. They are fast to execute, isolated, and relatively inexpensive to write and maintain. These tests ensure the correctness of individual code units.
-
Integration Tests: Positioned above unit tests, integration tests are fewer in number but more comprehensive. They validate the interactions between different components, such as a microservice communicating with an API Gateway and then verifying data consistency across various databases. These tests are more resource-intensive than unit tests but offer broader coverage.
-
End-to-End (E2E) Tests: At the apex of the pyramid, E2E tests are the least numerous due to their high cost and execution time. These tests simulate real-world user scenarios, involving actual client interfaces like web browsers (driven by automation robots) or mobile application simulators. Their purpose is to validate the entire system’s functionality from the user’s perspective, ensuring that all integrated components work harmoniously to deliver the intended user experience.
The cost proportionality for developing high-quality tests, including edge cases and intelligent logic, can be substantial.
For instance, if developing a component requires 100 hours, achieving 90% test coverage with robust, high-quality unit, integration, and E2E tests might demand an additional 60 hours.
Unfortunately, many projects often fall short of this ideal, with limited or even absent E2E and integration tests, and sometimes only a handful of unit tests. Such deficiencies mean that any code change, even minor ones, carries a high risk of introducing new bugs, necessitating constant vigilance and manual intervention in production.
Benefits of Adopting DevOps
When estimating the cost of implementing a software solution, it is crucial to allocate sufficient effort towards developing a robust test automation strategy within your DevOps pipeline. This upfront investment is vital for realizing the full benefits of DevOps.
A primary advantage of this approach is the significant reduction of waste through problem anticipation. By diligently “shifting left” and identifying problems as early as possible in the development cycle, you dramatically enhance software quality. This proactive problem-solving prevents defects from reaching critical stages like production, where their impact is most severe and costly to rectify. Moreover, catching bugs early also saves the valuable time of your testing team, as they won’t need to spend extensive periods re-testing functionalities that are frequently broken by later-stage defects. Intercepting problems in the initial development environment prevents broken builds and maintains the efficiency of the pipeline. Ultimately, by anticipating and addressing issues early, DevOps ensures a more streamlined, higher-quality, and cost-effective software delivery process.
The Cultural and Organizational Shift of DevOps
The successful adoption of DevOps necessitates a profound cultural and organizational shift that involves all key stakeholders across the software delivery lifecycle.
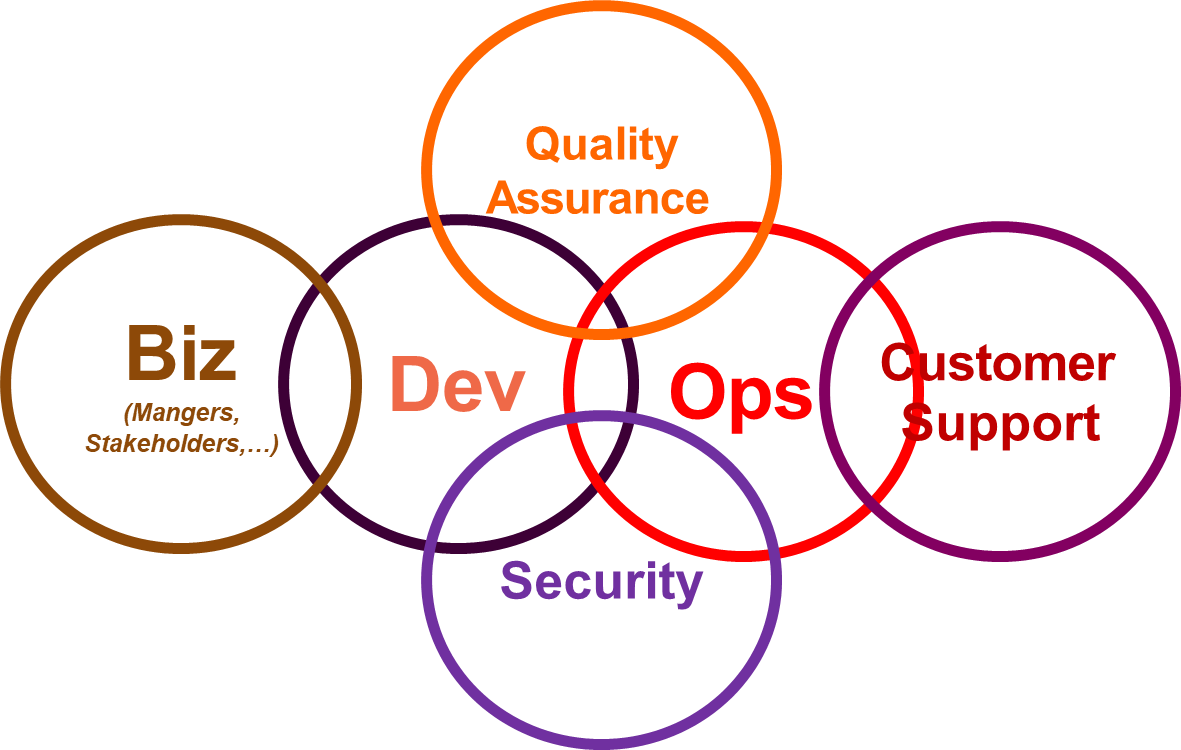
-
Business Stakeholders: These individuals provide essential requirements and define the business needs that drive development. They often dictate critical Service Level Agreements (SLAs), such as the need for hotfix deployments within an hour for critical malfunctions. To meet such demands, the DevOps pipeline must be architected and sized appropriately, ensuring, for instance, that a full software build can be completed in less than 15 minutes. This aligns technical capabilities with business expectations
-
Security Teams: Security is paramount, especially in hybrid environments where parts of the infrastructure might reside on-premise while others are in the cloud. Security teams must be intimately involved in designing the pipeline to ensure secure communication channels, such as Virtual Private Networks (VPNs) and the use of secure protocols with double certificates, between these disparate environments. Their expertise is crucial for safeguarding sensitive data and maintaining compliance.
-
Development and Operations Teams: These are the core constituents of DevOps. Their traditional silos must be dismantled, fostering a collaborative environment where they work together on shared objectives, from project conception through deployment and monitoring.
-
Quality Assurance (QA) Teams: QA teams are integral as they are responsible for thoroughly testing the software in various environments. Their feedback loops are critical for identifying defects before production.
-
Customer Support: As the front line for end-users, customer support teams are crucial for reporting problems identified by the final users. Their input, typically through ticketing systems, provides invaluable feedback that feeds directly back into the development and operations cycle for resolution.
Another critical aspect of DevOps is the promotion of continuous improvement. This embodies an iterative “plan-do-check-act” approach to experimentation and learning, where experiences are constantly refined and repeated to achieve maximum speed and efficiency.
Crucially, DevOps emphasizes promoting active communication across all teams and stakeholders. While dedicated chat channels for specific communities (e.g., backend, frontend, database) are common, the DevOps philosophy advocates for cross-functional presence in these channels to prevent knowledge silos. This ensures that relevant information is shared broadly, fostering collective understanding and problem-solving. Furthermore, this communication extends beyond human interaction to include automated alerts from the system itself.
For instance, monitoring tools can be configured to send instant messages to relevant chat channels (e.g., Slack, Microsoft Teams) when critical events occur, such as a production server's CPU reaching 100% for an extended period or a database query exhibiting unusually long execution times.