Definition
Microservices represent a modern architectural paradigm that decomposes applications into independently deployable services, each encapsulating a specific business capability. This approach contrasts with traditional monolithic architectures, offering benefits such as scalability, modularity, and technological heterogeneity. Each service can be developed, deployed, and scaled independently, facilitating faster releases and improved fault isolation.
Despite these advantages, microservices come with significant complexity. Designing and maintaining a microservices-based system requires a team with advanced skills in distributed systems, service orchestration, inter-service communication (typically using REST or messaging protocols), and infrastructure automation. Poorly designed microservices can result in service sprawl, increased latency, and excessive operational overhead. For this reason, it is often recommended to begin development with a monolithic architecture and later migrate to microservices as the application matures and the need for scalability becomes more pressing. This approach minimizes initial complexity while preserving future flexibility.
There are also hybrid approaches emerging, such as modular monoliths (or service-based architectures), which retain some separation of concerns like microservices but remain within a single deployable unit. These aim to balance the benefits of modularity with the simplicity of monolithic deployments.
Evolution from Static Sites to Web Applications
The evolution of web technologies began with the delivery of static HTML pages, styled with CSS and optionally enhanced with JavaScript. This was based on the fundamental HTTP request-response model, where the server’s primary role was to serve static resources to clients, typically browsers. Each request would fetch a file, which the browser parsed and rendered.
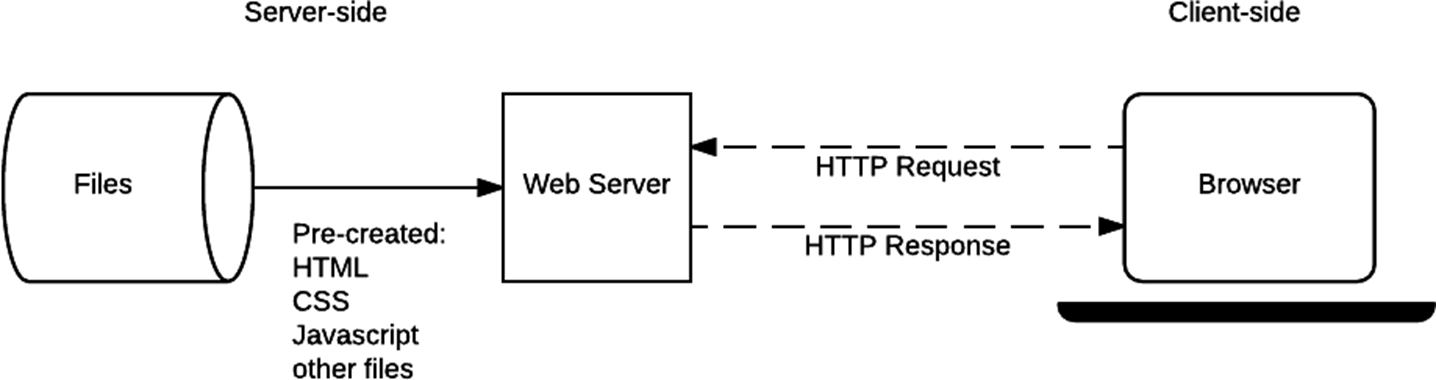
This paradigm shifted significantly with the advent of web applications—dynamic, interactive systems capable of generating content on the server side in response to user input and application logic. Unlike static pages, dynamic responses consider query parameters, session data, and business logic, and often involve database interactions. This architecture enabled the development of full-fledged applications accessible through a browser, blurring the lines between desktop and web software.
Modern web applications increasingly rely on APIs, making it possible to decouple front-end and back-end components.
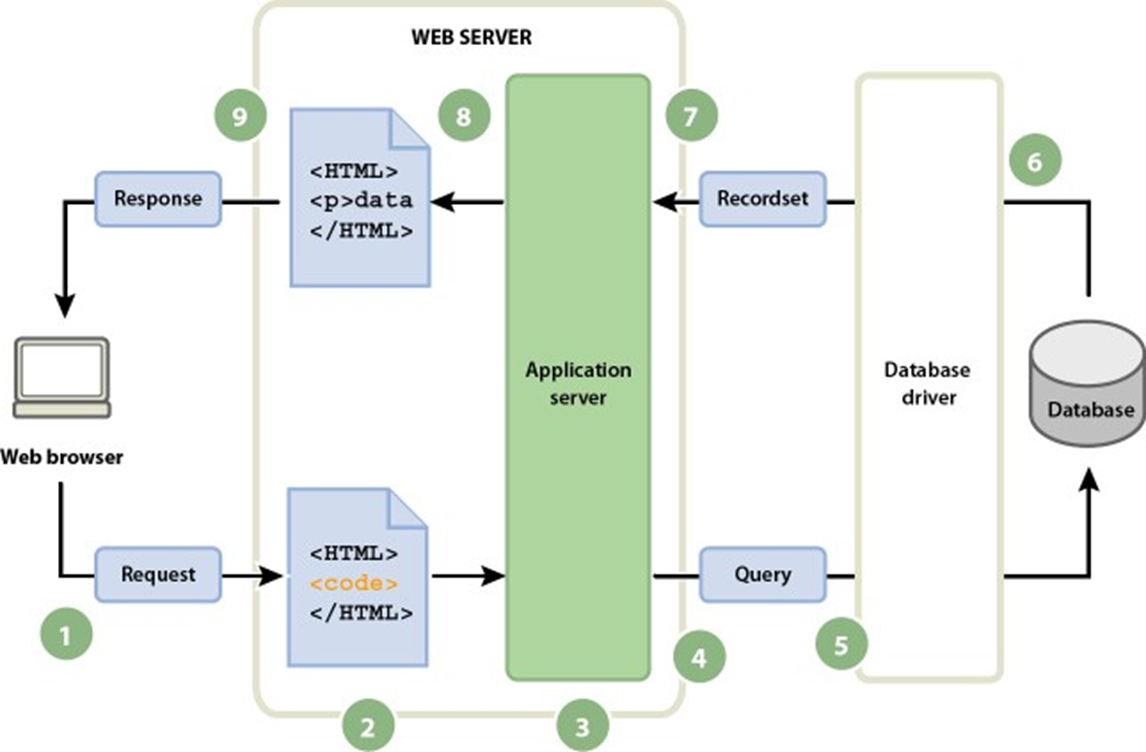
For instance, mobile apps or single-page applications (SPAs) often interact with server-side systems via RESTful APIs or GraphQL, using JSON as the communication format. This decoupling not only enhances scalability and maintainability but also promotes reusability of services across multiple clients and platforms.
Model-View-Controller (MVC)
The MVC (Model-View-Controller) architectural pattern was introduced to enforce a clear separation between different responsibilities within an application. Historically, early web development practices often combined presentation logic (HTML, UI design) and business logic (data manipulation, processing) in a single file or module, which led to numerous issues in scalability and maintainability.
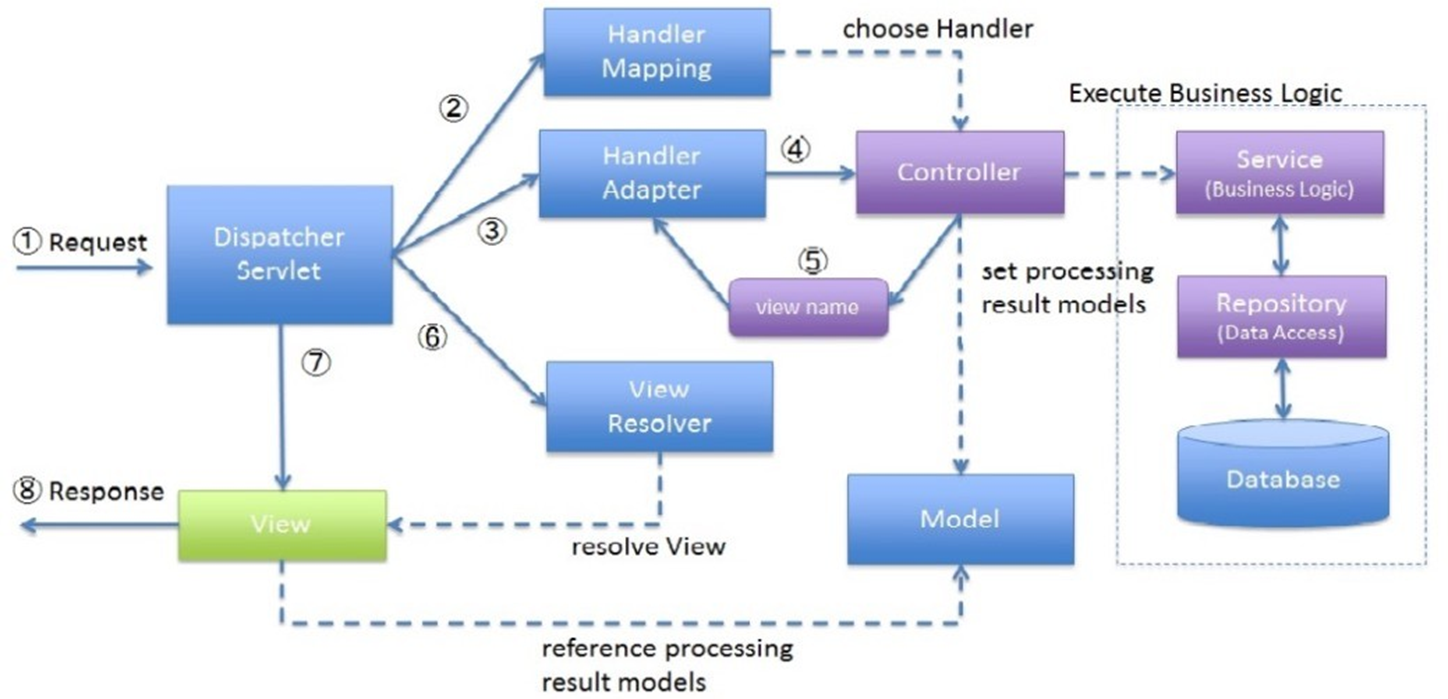
Definition
In the MVC pattern
- the Model represents the application’s data and business logic
- the View handles the presentation and user interface
- the Controller acts as the intermediary that receives user input, interacts with the model, and selects the appropriate view for rendering.
This separation enables independent development and testing of each component, reduces coupling, and improves the organization of code.
As applications grow in complexity, adhering to MVC becomes increasingly beneficial. It allows different teams to work concurrently—developers on business logic, designers on UI—without interference. Moreover, it facilitates better testing strategies, more reusable components, and clearer code structure. MVC also aligns naturally with layered architecture principles and is widely supported in frameworks such as Django, Spring MVC, ASP.NET MVC, and Ruby on Rails.
Monolithic Architecture
Definition
Monolithic architecture refers to a system design in which the entire application—encompassing UI, business logic, and data access—is deployed as a single executable unit.
This approach has been the dominant model for decades and remains widely used due to its simplicity and development efficiency.
In a monolithic system, internal modules (e.g., user management, order processing) are part of the same codebase and runtime environment. While this facilitates high initial productivity, easy deployment, and straightforward inter-module communication, it also introduces challenges as the system grows. These include tightly coupled components, reduced scalability, difficulty isolating faults, and more complex deployments in high-availability environments.
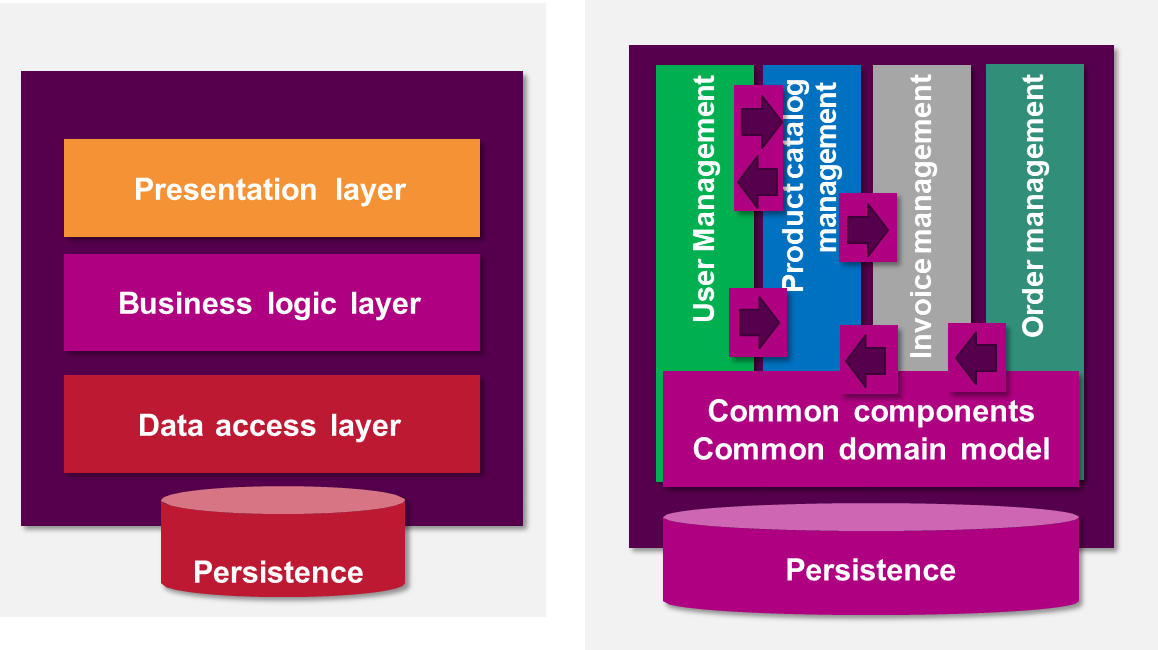
To partially mitigate complexity, developers may organize monolithic applications along two dimensions: architectural layering and vertical domain slicing.
- The first separates responsibilities into presentation, business, and data layers
- The second groups features by user functionality or domain (e.g., sales, inventory, billing).
In enterprise environments, monolithic applications are often deployed on application servers (e.g., JBoss, WebSphere) that support clustering and high availability. Load balancers distribute requests across instances to ensure performance and resilience. However, issues such as memory constraints, update risks, and lack of isolation remain. Even with techniques like session affinity and load balancing, scaling monoliths often requires duplicating the entire application.
Understanding Technical Debt
Definition
Technical debt is a critical concept in software engineering that refers to the long-term consequences of choosing suboptimal or expedient solutions during software development.
Although such decisions might seem efficient in the short term—particularly under intense time constraints—they often compromise the structural integrity, maintainability, and scalability of a system. Over time, technical debt accumulates, eventually hindering development velocity, increasing the risk of defects, and making even minor changes costly and time-consuming.
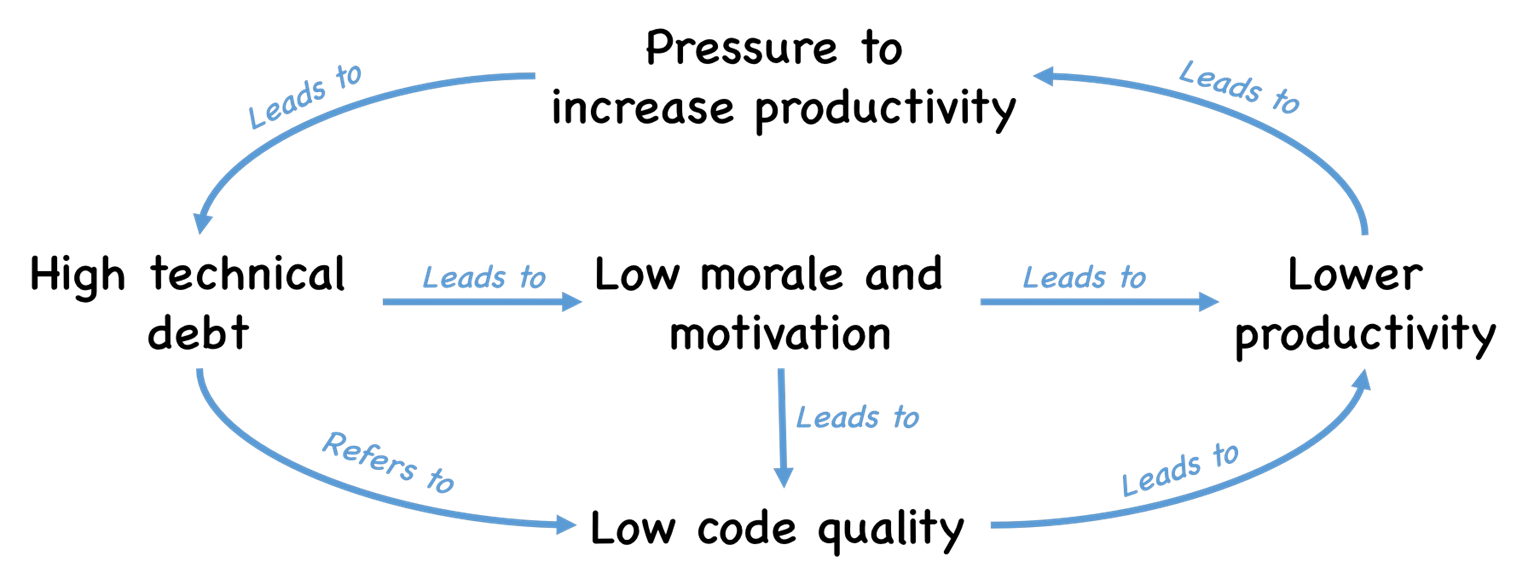
One of the most common sources of technical debt emerges when developers take “shortcuts” to meet pressing deadlines or to satisfy urgent business requirements.
For example, instead of refactoring existing code to accommodate a slightly altered use case, a developer might duplicate a function and modify it superficially, avoiding changes to the original out of fear of breaking dependent components.
This fear-driven avoidance, although understandable in high-stakes environments, contributes significantly to code duplication and architectural inconsistency. Over time, such practices produce brittle systems where small modifications become disproportionately expensive in terms of development effort and testing.
Technical debt is not limited to code-level issues. Architectural decisions made during the early stages of a project can also generate a form of deep-rooted debt. An inadequate or poorly thought-out architecture may limit the flexibility of the system, impair its scalability, and lock the development team into certain technologies or design patterns. This type of structural debt is particularly dangerous because it affects the entire system’s evolution and is difficult to reverse without major refactoring or even a full rewrite.
While it may be tempting to adopt a purist approach that avoids all forms of technical debt, such rigidity is neither practical nor desirable in real-world software projects.
- Overanalyzing every decision can lead to “analysis paralysis,” where excessive planning stalls actual development progress.
- Making decisions with little regard for long-term consequences leads to excessive technical debt.
The goal, therefore, is to find a sustainable balance between pragmatism and foresight.
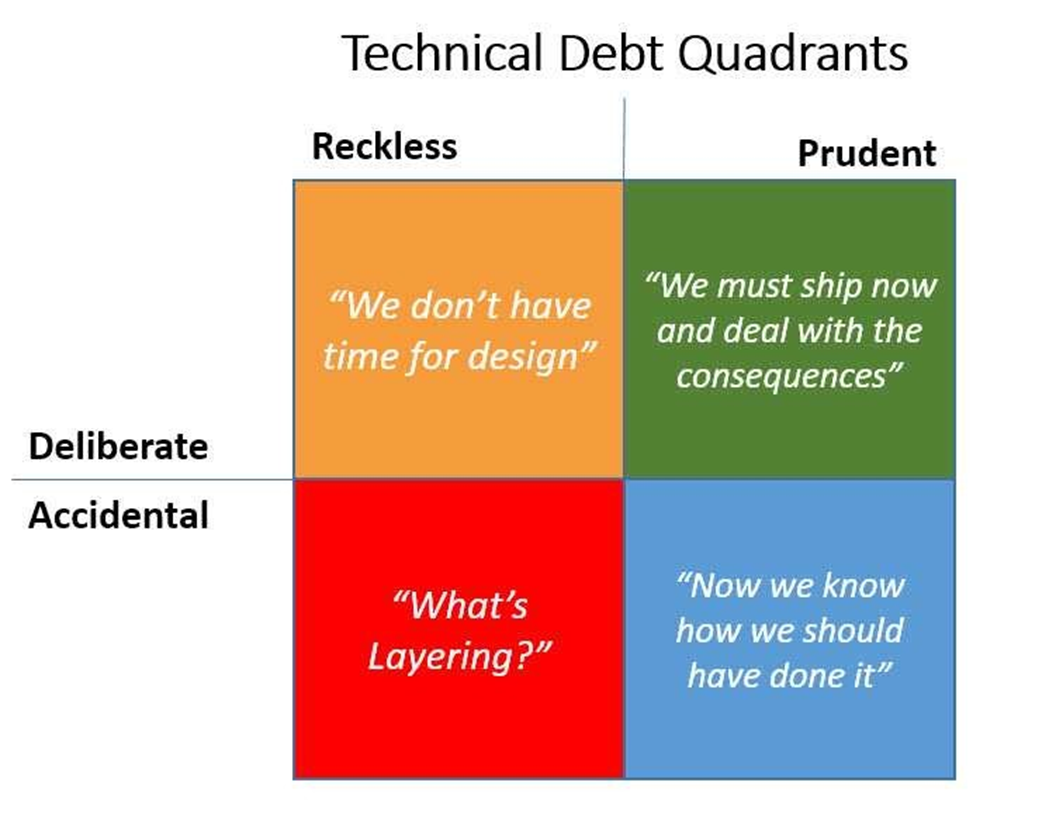
Strategic management of technical debt involves recognizing when it’s appropriate to incur debt and making a conscious commitment to repay it. For instance, during a critical release cycle where investor interest or business momentum depends on fast delivery, it might be reasonable to introduce technical debt. However, this should be done with an explicit plan to refactor in the subsequent iteration. Debt that is knowingly incurred and carefully managed—often referred to as “prudent debt”—can be a useful tool. In contrast, “reckless debt” results from carelessness or ignorance and is rarely defensible.
The Relationship Between Technical Debt and Architecture
Monolithic architectures tend to exacerbate the accumulation of technical debt: all components are tightly coupled, meaning that any change in one part of the system can have cascading effects elsewhere. This rigidity makes it difficult to scale development teams. In fact, once a monolithic system reaches a certain size, adding more developers paradoxically reduces overall productivity due to coordination overhead and increased risk of regression.
Monoliths also struggle with load scalability, which refers to the system’s ability to handle increased traffic or demand. While it’s possible to scale vertically (by adding more CPU and memory) or horizontally (by deploying additional instances), doing so is inefficient when the performance bottleneck lies in just a small part of the system.
Another limitation lies in generation scalability and heterogeneous scalability.
- Generation scalability refers to the ability of an application to evolve alongside changes in the underlying platforms or databases. If a monolith is tightly coupled to a specific database version, for instance, future upgrades may break critical functionality.
- Heterogeneous scalability, on the other hand, pertains to the freedom to integrate new technologies. A monolith bound to a proprietary database language like PL/SQL cannot easily adopt open-source alternatives like PostgreSQL without significant rework.
In cases where technical debt has grown so severe that modifying the system introduces more defects than it resolves, a full rewrite may become the only viable option. Rewriting allows the team to re-architect the system using modern paradigms such as microservices, which promote modularity, flexibility, and maintainability.
Technical debt is often exacerbated by the human element. Developers may duplicate code simply because they are unaware that a similar implementation already exists elsewhere in the system. This problem becomes more pronounced in large teams or legacy systems with poor documentation. Modern AI-assisted tools aim to mitigate this issue by providing holistic visibility into the codebase, helping developers locate existing logic before reinventing the wheel. While these tools are still maturing, they hold promise for reducing unintentional duplication and enhancing code reuse.
The Microservice Paradigm
The transition to microservice architecture stems not primarily from technological innovation, but from business-driven needs. Organizations increasingly face challenges such as the necessity for rapid development cycles, cost-effective scalability, maintainability, and technological agility. These demands have exposed limitations in traditional monolithic architectures, especially when evolving systems must adapt swiftly to changes such as version upgrades, new feature deployments, or infrastructure migration (e.g., moving from costly proprietary databases to open-source alternatives).
An essential principle of the microservice paradigm is that each microservice must function autonomously. This means it must own its bounded context, which includes not only the data entities it manages but also the associated business logic and rules.
The bounded context concept, borrowed from Domain-Driven Design (DDD), ensures that each service handles a specific subdomain of the overall application and maintains its own isolated persistence layer.
Example
For example, a User microservice might manage personal information, while an Order microservice handles purchases—each with its own database schema, even if they share similar entities such as a “User” object. In this case, data duplication is not only tolerated but necessary, provided that each copy is managed independently according to the context’s logic.
A key operational constraint in microservice architecture is communication discipline: services must communicate exclusively through their APIs. Direct database access by external components is strictly prohibited. This ensures that internal data representation and storage mechanisms remain encapsulated, supporting versioning and independent evolution of each microservice without risking tight coupling or schema dependencies.
Collaboration Between Microservices
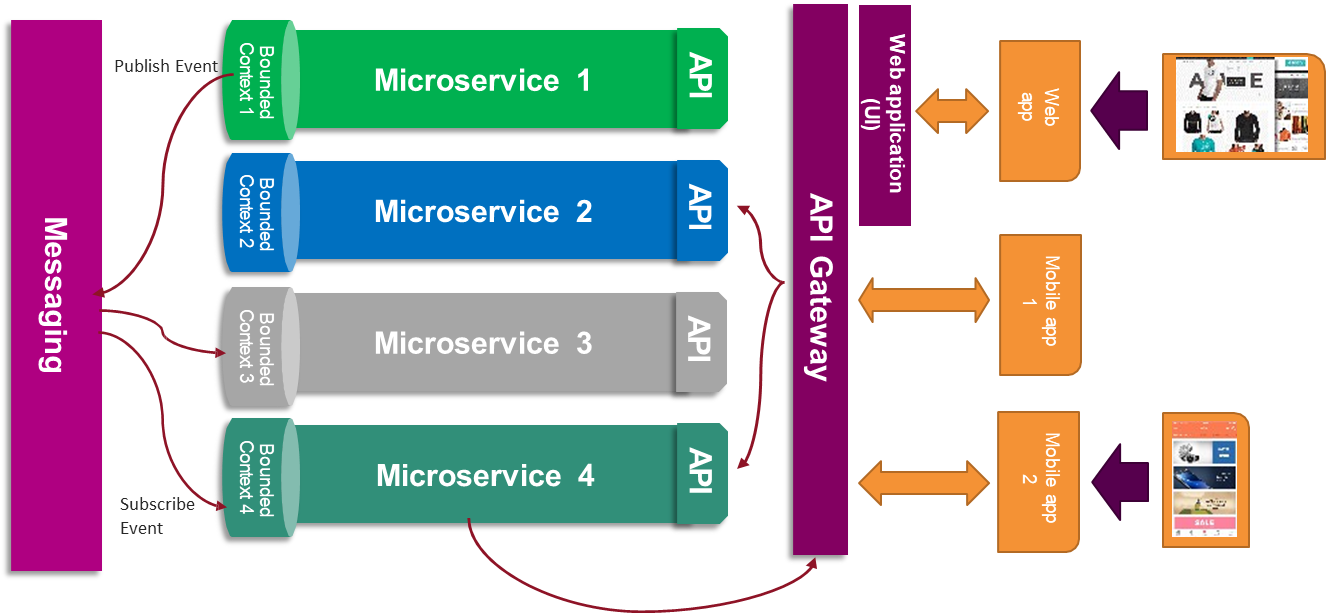
The collaborative behavior of microservices is achieved through asynchronous and synchronous communication mechanisms. Synchronous interactions typically use RESTful APIs or RPC-based protocols to serve real-time queries or commands. However, one of the most powerful features of the microservice architecture is its support for event-driven communication, particularly when dealing with cross-cutting concerns such as distributed transactions or data synchronization.
Example
Consider a scenario in which several services depend on a shared conceptual entity, like a User. The User microservice is designated as the system of record for user data. Other services, such as Cart or Order, may require information about the user to associate orders or carts correctly. However, they must not query the User service’s database directly. Instead, when a user is created or modified, the User service publishes an event to a messaging system (e.g., Kafka, RabbitMQ). Interested services act as subscribers, listening to these events and reacting accordingly—typically by updating their local data representations.
This interaction model, known as publish-subscribe, supports eventual consistency. While not instantaneous, consistency is typically achieved within a short time window (e.g., a few seconds). This model contrasts sharply with the strong consistency guarantees of monolithic systems, where a single database enforces immediate synchronization across all operations. Although eventual consistency introduces temporal discrepancies—such as newly uploaded data appearing with delay in some views—it significantly enhances decoupling and system resilience.
To orchestrate communication and manage concerns such as API versioning, load balancing, service discovery, and fault tolerance, microservices often rely on an intermediate abstraction layer called the API Gateway. This component acts as a reverse proxy, routing client requests to appropriate backend services. It can transform request formats, enforce security policies, and shield internal services from external exposure. Furthermore, health checks and heartbeat signals allow the gateway or service mesh infrastructure to monitor service availability, removing failed instances from the routing pool automatically to preserve system stability.
The Microservices Architecture
Microservices architecture represents a paradigm shift from monolithic software systems, emphasizing the decomposition of a complex application into a suite of small, independently deployable services.
Each microservice encapsulates a specific business domain, allowing for a modular design in which both the logic and data related to a particular domain are encapsulated within a single bounded context.
Unlike traditional Service-Oriented Architectures (SOA)—which often separate business logic from data, leading to orchestration complexities—microservices aim to unify data and behavior. In older SOA-based systems, one would often find business process servers coordinating the activities of many stateless services, which sounds good in theory but often introduces fragility. The microservice model avoids this by allowing each service to maintain its own data store and manage its own logic, minimizing external dependencies and increasing cohesion.
One of the distinctive advantages of microservices is technological flexibility. Within a single application, different microservices can be built using entirely different programming languages and frameworks. This is particularly useful when services have different functional requirements.
Example
For instance, services involving artificial intelligence, natural language processing, or machine learning may benefit from Python due to its rich ecosystem (e.g., LangChain, LlamaIndex), whereas services requiring integration with legacy enterprise systems—such as banking platforms—may be better suited to Java.
This approach allows development teams to choose the most appropriate tool for each job, maximizing productivity and performance without enforcing a uniform technology stack across the entire system. It also enables independent scaling, deployment, and upgrading of services, which greatly enhances maintainability and agility.
Because each microservice operates within its own well-defined domain, isolating and resolving bugs or performance bottlenecks becomes significantly easier. Developers can concentrate their debugging efforts on a single service without needing to comprehend the entire application. This isolation also allows for domain-driven design, where each team can own and manage a specific business capability, leading to team autonomy and organizational scalability. Furthermore, when specific parts of an application experience seasonal or unpredictable traffic peaks—such as a product catalog service during a holiday sale—only the relevant microservices need to be scaled. This selective scalability leads to cost-effective resource usage.
Microservices also align well with modern development methodologies like scrum and DevOps. While the ideal agile team is cross-functional and capable of working on any part of the application, in large-scale systems, it may be more efficient to specialize teams around specific services. Though this may introduce dependencies, it allows teams to develop deep expertise in particular domains, accelerating development cycles and improving quality.
Microservices are cloud-native by design. They support dynamic deployment, infrastructure-as-code, containerization (e.g., via Docker), and orchestration (e.g., via Kubernetes). This readiness facilitates the integration of third-party services or cloud-based APIs, which can replace or extend microservices seamlessly. These principles support the concept of composable architectures, in which an application is constructed like a set of building blocks, increasing adaptability and enabling rapid innovation.
The modularity inherent in microservices also fosters API reusability. Well-designed APIs are essential, as they define the contracts between services. Good API design is an art and science that improves maintainability and enables services to be reused across applications or by external partners.
Challenges and Real-World Behavior
Microservices are powerful but expensive. Choosing them prematurely can lead to over-engineering, diverting resources from product development and market validation. Conversely, underinvesting in technical architecture can make future scaling difficult or even impossible. Striking the right balance between technical debt and business agility is one of the most critical decisions in software architecture.
Refactoring a monolith into microservices mid-development introduces a transition period where both architectures coexist. This duality can create inconsistencies, integration issues, and significant cognitive overhead. Planning and executing such a migration requires experienced architects and robust governance.
The microservice paradigm introduces operational complexity that must be managed effectively. Coordinating distributed components, handling partial failures, ensuring reliable communication, and preserving consistency are all non-trivial tasks. Tools such as distributed tracing, centralized logging, circuit breakers, and retry patterns become essential.
Example
Real-world platforms like Facebook, Netflix, and Amazon exemplify the microservice architecture. For instance, Facebook’s architecture decomposes functionality into dedicated services: one for managing images, another for user timelines, another for private messaging, and so on. Users may have noticed occasional delays in consistency—for example, after uploading a photo, the image might not immediately appear in an album due to asynchronous propagation between services. This lag exemplifies eventual consistency, which is a natural consequence of a distributed, decoupled system.
To manage this, modern observability stacks rely on centralized log aggregation systems (e.g., Elasticsearch, Logstash, Kibana—commonly referred to as the ELK stack). Logs are collected from Docker containers and enriched with trace identifiers that allow developers to follow a single request across the service mesh. These identifiers propagate through both synchronous and asynchronous calls, enabling distributed tracing and root cause analysis. However, setting up and maintaining such an observability platform adds another layer of system complexity.
Continuous Delivery and Deployment Challenges
Deploying a microservices-based system also demands a mature CI/CD pipeline. Unlike monoliths—where deployment often involves a single artifact—microservices require versioned, decoupled delivery strategies. Developers must manage service dependencies, maintain backward compatibility, and avoid deployment races. Coordination between services becomes essential, especially during upgrades or API contract changes.
This complexity makes microservices less suitable for early-stage startups or projects with limited engineering resources. In such scenarios, it is often more pragmatic to begin with a monolithic architecture, prove business viability, and then progressively refactor into microservices as the system grows in size and complexity. This staged migration mirrors the experience of companies like Facebook, which began with a simple monolith and evolved into a sophisticated microservices ecosystem.
Data Consistency and Transaction Management
Another critical challenge in microservices is maintaining consistency across distributed components. Traditional ACID transactions spanning multiple microservices are difficult to implement. Instead, patterns like Saga are used, where a central orchestrator manages the sequence of steps across services and invokes compensation logic if any part fails. While this approach approximates transactional behavior, it is more error-prone and harder to reason about compared to database-native transactions.
When the business domain is unstable or rapidly evolving, microservices can become liabilities. If domain boundaries shift frequently, services must be refactored or recomposed, incurring significant overhead. In such cases, it is advisable to begin with a modular monolith, which maintains separation of concerns without the cost of distributed communication.
Alternative Approaches: Moduliths and Hybrid Architectures
In between monoliths and microservices lie modular monoliths (or “moduliths”)—a design that enforces clear module boundaries within a single codebase. Tools like Spring Modulith or Domain-Driven Design patterns help achieve this internal separation. Such architectures offer many benefits of microservices (e.g., modularity, clear ownership) without the operational complexity of distributed systems.
Eventually, if the architecture is well-modularized, transitioning from a modulith to microservices becomes a matter of decomposing modules into independent services. This progressive path allows a more sustainable and adaptable system evolution.