Cloud computing represents a fundamental paradigm shift in how computing resources are provisioned and consumed. The International Organization for Standardization (ISO) defines cloud computing as
a paradigm that enables network-based access to a scalable and elastic pool of shared physical or virtual resources, facilitating self-service provisioning and on-demand administration.
This definition highlights several key attributes:
- scalability, meaning the ability to increase or decrease resources as needed;
- elasticity, which refers to the capacity to automatically adjust resources in response to fluctuating demand;
- shared resources, where multiple users or organizations share the same underlying infrastructure;
- self-service provisioning and on-demand administration, empowering users to independently select and manage their computing resources through online portals.
A critical aspect of cloud computing is the concept of self-service provisioning, which allows users to directly select and configure the desired computing resources via a cloud provider’s web interface. This empowers users with immediate access to infrastructure without manual intervention from the provider. Complementary to this is the option for a fully managed solution, where users specify their infrastructure requirements, and the cloud provider assumes full responsibility for managing the underlying infrastructure, including maintenance, updates, and scaling. This allows organizations to focus on their core business activities rather than on IT operations, offloading the complexities of server maintenance, software patching, and capacity planning to the cloud provider.
While intuitively associated with hardware resources, cloud computing encompasses both hardware and software resources. Cloud providers offer not only raw computing power but also a wide array of software services, including databases, analytics tools, development platforms, and artificial intelligence/machine learning services. This integrated approach allows users to procure comprehensive solutions that include both the necessary computing capacity and the applications to run on it.
Although cloud providers often advertise seemingly unlimited computing resources, practical limitations exist. For instance, providers like AWS may impose initial limits on the actual capacity a user can procure, and substantial resource procurement often necessitates pre-existing contracts or agreements. These contractual arrangements define the maximum resources available and may require advance notification for significant scaling beyond agreed-upon limits, indicating that while cloud capacity is extensive and flexible, it is not truly infinite and is subject to contractual terms and service level agreements. This also means that organizations, particularly those with high-demand or specialized requirements, may need to engage in direct negotiations with cloud providers to secure guaranteed resource availability and performance levels.
Cloud Computing Core Concepts
Cloud computing employs several key concepts that are integral to its operational model and value proposition.
- Horizontal scalability is a foundational principle, allowing systems to expand by adding more nodes rather than enhancing the power of existing ones. This approach contrasts with traditional vertical scaling, where a single server’s resources are increased. Horizontal scalability enables organizations to build robust and flexible infrastructures that can efficiently handle growing workloads. This approach is particularly favored by major cloud providers like Amazon Web Services (AWS), Google Cloud Platform, and Microsoft Azure, as it allows for efficient scaling and resilience.
- Resource pooling is another critical concept, involving the dynamic allocation and reallocation of shared computing resources among multiple users or applications. This allows cloud providers to aggregate and virtualize their physical infrastructure, serving multiple clients simultaneously from the same underlying hardware. This dynamic assignment of resources based on demand is a cornerstone of the cost-efficiency often associated with cloud computing, as users only pay for the resources consumed, often billed by the second.
- Rapid elasticity is a key characteristic of cloud computing, enabling swift and automatic adjustment of computing resources in response to fluctuating demand. This capability ensures that cloud environments can seamlessly scale up or down as needed, accommodating sudden spikes in usage without service interruption or performance degradation. A prime example of this is the gaming industry, where new game releases can generate unpredictable, massive peaks in user activity. Cloud computing allows developers to rapidly provision additional servers to handle such surges, preventing loss of potential users due to insufficient capacity.
- Autoscaling mechanisms are often employed to automatically add or remove computing instances based on predefined metrics, ensuring optimal resource utilization and cost efficiency. This feature is particularly beneficial for applications with variable workloads, allowing them to adapt dynamically to changing demands.
Public vs. Private Cloud
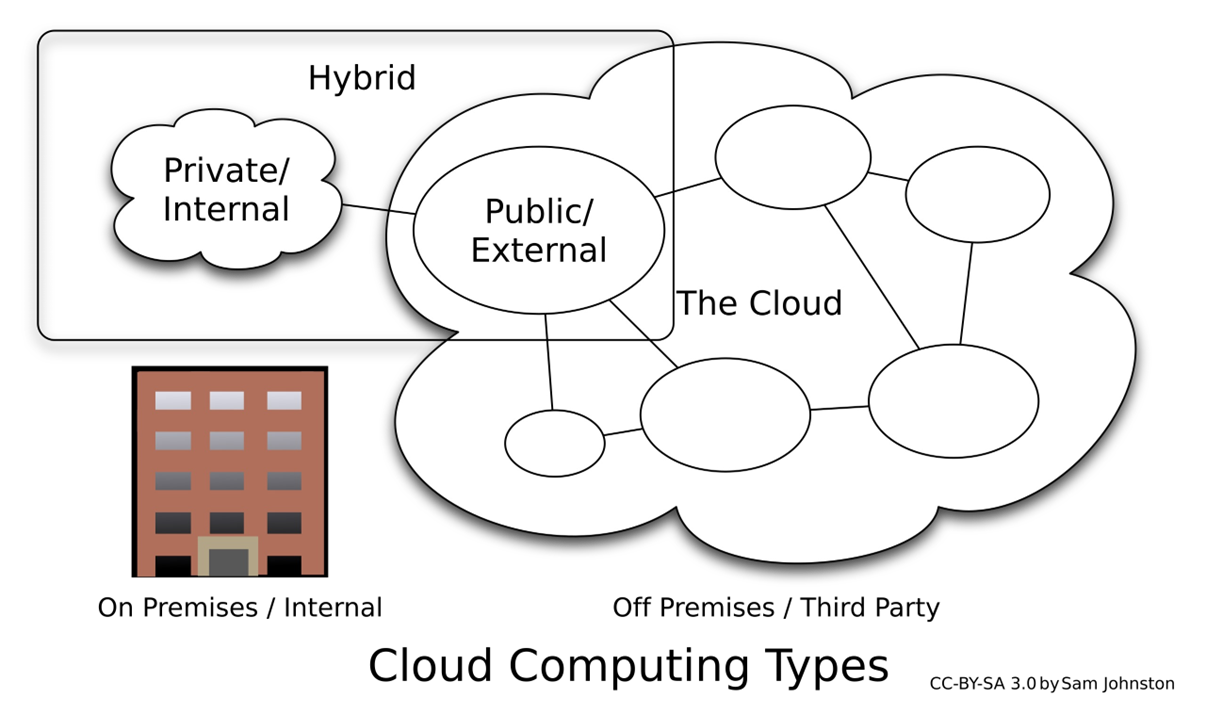
The discussion of cloud computing often distinguishes between public and private cloud deployments.
- A public cloud is characterized by shared infrastructure, where resources (compute, storage, networking) are pooled and made available to multiple customers over the internet by a third-party cloud provider. This model offers significant advantages in terms of flexibility, scalability, and ease of use, as the cloud provider handles all underlying infrastructure management. The simplified operational overhead and the ability to provision resources on-demand with minimal specialized IT skills make public cloud highly attractive, especially for organizations seeking rapid deployment and cost optimization. Furthermore, fully managed solutions offered within the public cloud simplify operations even further by taking care of routine tasks like operating system updates and software patching, allowing organizations to focus on their core business functions.
- Conversely, a private cloud is an IT infrastructure dedicated exclusively to a single organization. This can be hosted either on-premises (within the organization’s own data center) or by a third-party provider as a dedicated cloud environment. The key distinction is that the physical hardware and resources are not shared with other customers. This model offers enhanced control, security, and the ability to meet specific regulatory or compliance requirements, although it typically involves higher upfront investments and ongoing management responsibilities compared to public cloud.
| Private cloud advantages | Public cloud advantages |
|---|---|
| Security | Flexibility |
| Privacy | Scalability |
| More easily meets regulatory requirements | Ease of use (lower reliance on specialized skills) |
| Control | Fully managed solutions (reduced need for maintenance) |
| Customization | Reduced management complexity |
| Dedicated resources (predictable performance) | Greater reliability |
| Capital intensive | Variable costs |
The contemporary trend, however, strongly emphasizes hybrid cloud deployments. This approach intelligently combines the benefits of both public and private clouds, allowing organizations to leverage the scalability and cost-effectiveness of public cloud for certain workloads while retaining sensitive data or critical applications in a more controlled private cloud environment. This strategic combination enables seamless workload portability and data integration across different cloud environments, providing organizations with unparalleled flexibility and resilience.
The past few years have seen a shift from a “cloud-first” mandate, which often encouraged a full migration to public cloud, to a more pragmatic “hybrid-first” approach. This re-evaluation was spurred by experiences where the initial enthusiasm for public cloud transformation led to unforeseen complexities and costs, particularly when organizations realized that not all workloads were optimally suited for the public cloud.
The key lies in leveraging the public cloud’s agility for rapid scaling and growth support, particularly when on-premises data centers cannot accommodate demand quickly, while maintaining critical and sensitive operations within a private cloud.
Cloud Providers and Geographical Considerations
The global cloud computing market is dominated by a few major players, with AWS, Google Cloud Platform, and Microsoft Azure being the most prominent. While some companies may utilize specialized cloud services from other providers (e.g., Oracle for database-specific cloud solutions), reliance on a single major provider or a hybrid approach is common. A crucial consideration when deploying applications in the cloud is the geographical proximity of data centers to end-users. Network latency, caused by the physical distance data must travel, can significantly impact application performance.
For instance, hosting servers in Europe for European end-users ensures lower latency compared to serving them from a data center on another continent.
This regional optimization is critical for applications demanding low response times, such as real-time interactive services or mission-critical enterprise systems. Cloud providers have established vast global networks of data centers to address this, allowing organizations to deploy their services in regions geographically close to their target audience.
Cloud Vendor Value Propositions
The value propositions articulated by major cloud providers are carefully crafted to address the known pain points of modern enterprises. Amazon Web Services, for instance, emphasizes operational agility, offering on-demand resources, a pay-as-you-go pricing model, and a highly automated environment.

Their messaging appeals to a desire for flexibility and rapid prototyping. However, this narrative of freedom can be misleading. The very tools that enable rapid development often create the conditions for vendor lock-in, making it difficult to “throw things away” once an application is in production and scaled. The recommendation from major system integrators to “marry one cloud provider” reflects the practical reality that deep integration is often necessary to extract maximum value, despite the strategic risks it entails.
Google Cloud Platform (GCP) adopts a different marketing posture, leveraging the brand equity of Google’s innovation in areas like artificial intelligence and data analytics. GCP’s proposition is not just about providing infrastructure but about acting as a partner in digital transformation. They offer to bring cutting-edge AI capabilities and data insights to organizations that lack the resources to develop them in-house. This message targets a strategic anxiety among corporate leaders: the fear of being left behind technologically.
Both Amazon’s and Google’s propositions are powerful because they appeal directly to fundamental business needs and fears—the need for agility and the fear of stagnation. They offer simplified solutions to complex problems, promising to handle the technological heavy lifting so that companies can focus on their core business objectives.
Cloud Adoption for Different Organizational Scales
The adoption of cloud computing varies significantly depending on an organization’s scale and global reach.
For Small and Medium-sized Enterprises (SMEs), particularly those with a localized customer base, opting for cloud providers with a strong regional presence can be a pragmatic choice. For instance, a European SME whose primary user base resides within Europe might find suitable and cost-effective alternatives among European cloud providers. These providers can offer competitive latency and compliance with regional data regulations, which might be critical for their operations. However, if an SME aims for global expansion or already serves a worldwide clientele, relying solely on regional providers could introduce performance bottlenecks and increased latency for distant users, necessitating a shift towards globally distributed cloud infrastructure.
In contrast, large organizations with geographically dispersed operations and a global customer footprint often leverage a hybrid cloud strategy. This approach involves procuring cloud capacity from multiple major global providers, such as AWS, Google Cloud Platform, and Microsoft Azure, and integrating these with their on-premises infrastructure. This distributed architecture allows large organizations to strategically place their applications and data closer to their global user base, minimizing network latency and enhancing user experience. This also provides redundancy and mitigates risks associated with relying on a single cloud provider, ensuring business continuity and disaster recovery capabilities across different geographical regions.
Cloud Service Models: IaaS, PaaS, and SaaS
Cloud computing offers various service models, each defining the level of control an organization retains over its IT infrastructure versus what is managed by the cloud provider. These models represent different layers of the computing stack, moving from raw infrastructure to fully managed applications.
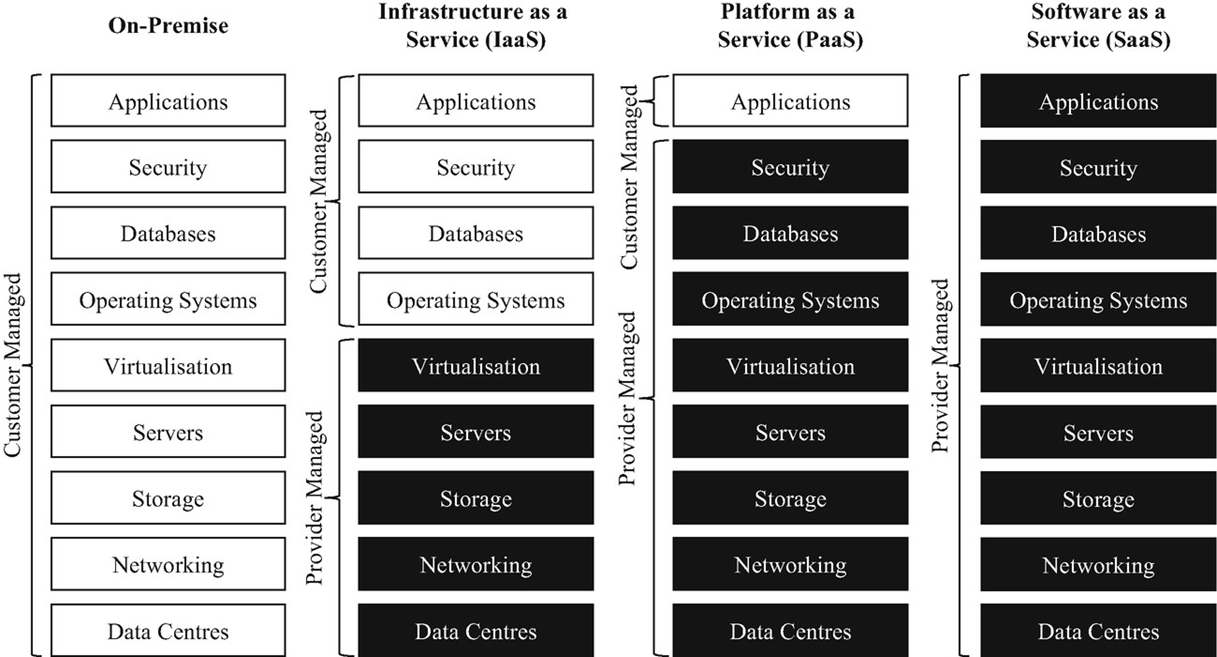
At the foundational level, Infrastructure as a Service (IaaS) provides access to fundamental computing resources, including networking components, storage, servers, and the virtualization layer. In an IaaS model, the cloud provider manages the underlying physical infrastructure, while the user is responsible for managing the operating systems, databases, applications, and security configurations. This model offers the highest degree of flexibility and control, allowing organizations to deploy and manage their virtual machines, storage networks, and applications much like they would with on-premises hardware, but with the added benefits of cloud scalability and elasticity.
Building upon IaaS, Platform as a Service (PaaS) abstracts away the management of the operating system, databases, and security layers. With PaaS, organizations procure a complete development and deployment environment from the cloud provider, including operating systems, programming language execution environments, databases, web servers, and other middleware. This model is particularly beneficial for developers as it allows them to focus solely on coding and deploying their applications without concerns about infrastructure provisioning or maintenance. The cloud provider handles all underlying infrastructure, including patching, security updates, and scaling, thereby accelerating application development and deployment cycles.
Finally, Software as a Service (SaaS) represents the highest level of abstraction, where the entire application stack, including the applications themselves, is hosted and managed by the cloud provider. Users access these applications over the internet, typically through a web browser, without needing to install, manage, or update any software or infrastructure. Examples include email services, customer relationship management (CRM) systems, and enterprise resource planning (ERP) software. SaaS offers maximum convenience, eliminating the need for any on-premises IT infrastructure or management by the end-user organization, thereby reducing operational overhead and capital expenditure.
The choice among IaaS, PaaS, and SaaS depends on an organization’s specific needs regarding control, customization, and resource management. If an organization maintains all its IT infrastructure internally without leveraging any cloud services, this is referred to as an on-premises deployment.
Example
For a small enterprise without significant legacy systems, a SaaS model for core business functions like Enterprise Resource Planning (ERP), using solutions such as NetSuite, can be highly effective. It simplifies management and allows the company to focus on its core business. An IaaS approach may be suitable for initial forays into the cloud, providing maximum flexibility without the cost of fully managed solutions. Large organizations, often burdened with extensive legacy data centers, face a more complex set of choices. They may opt for a phased migration, deciding which applications and data to move based on business criticality and technical feasibility. The management of human resources also becomes a critical issue; training employees on the specifics of one cloud provider’s IaaS paradigm risks making their skills obsolete if the organization’s strategy shifts.
Organizational Architectures
The presented taxonomy of IaaS, PaaS, and SaaS, while fundamental, represents a simplification of the diverse landscape of cloud service provisioning. In reality, organizations often adopt highly granular and customized approaches to cloud adoption, selecting specific services for different layers of their IT stack while retaining others on-premises.
For instance, an organization might procure a fully managed operating system from a cloud provider (similar to PaaS for that specific component) but choose to maintain its databases in-house for specific security or compliance reasons.
This high degree of customization means that a company’s resulting IT architecture is often a complex mosaic of various cloud services and on-premises solutions, tailored to the specific needs and regulatory requirements of each application.
This complexity is further compounded by the application dimension. A large enterprise might utilize Software as a Service (SaaS) for its Customer Relationship Management (CRM) system, benefiting from immediate access and minimal management, while simultaneously running its core Enterprise Resource Planning (ERP) applications on-premises or using an Infrastructure as a Service (IaaS) model for greater control. Ancillary applications might also be procured via SaaS APIs, integrating seamlessly with other systems. This intricate web of services, often involving multiple cloud providers, necessitates a robust catalog of resources. Such a catalog typically details where each resource is hosted, who the end-users are, how it is managed (e.g., fully managed by provider, managed in-house), and defines both business-level and IT-level responsibilities. In certain highly regulated industries, maintaining such a comprehensive and up-to-date catalog is not merely a best practice but a compulsory requirement for compliance and operational transparency.
Software Efficiency
The concept of horizontal scalability represents a fundamental departure from traditional approaches to increasing computing power. Historically, enhancing performance meant vertical scaling—investing in a single, more powerful mainframe or server. In contrast, horizontal scalability is predicated on the use of distributed commodity hardware, where numerous smaller, inexpensive servers work in parallel to handle a workload. This architectural shift offers significant cost advantages, moving away from the high capital expenditure associated with mainframes towards more manageable, standardized servers, often running open-source operating systems like Linux.
A standard server, equipped with 16 or 32 gigabytes of RAM, provides substantial computing power at a fraction of the cost of its mainframe predecessors, democratizing access to large-scale computing.
However, the transition to a horizontally scalable architecture is not without its challenges. Applications designed for a single, monolithic system cannot inherently leverage a distributed environment. They must undergo significant re-engineering and refactoring to be decomposed into components that can operate independently and in parallel. This process is particularly complex for certain classes of algorithms, such as those found in machine learning: while some algorithms are embarrassingly parallel, meaning they can be easily divided into independent sub-tasks, many others are inherently sequential or require frequent synchronization and data convergence points, making them difficult to distribute effectively across multiple nodes.
The necessity of this architectural approach has been profoundly influenced by the stagnation of Moore’s Law, which posited the exponential doubling of processor capacity every two years. As the physical limits of transistor density are approached, the industry has turned to horizontal distribution as the primary means of achieving continued performance gains, thereby sustaining the business models of IT companies that rely on exponential growth in computing capability.
The ubiquity of powerful and scalable hardware has altered the traditional imperatives of software efficiency. For a broad category of application software, the focus on optimizing code for minimal resource consumption has diminished. The prevailing logic is that any performance bottlenecks can be resolved by allocating more hardware resources, a strategy made economically viable by the low cost of commodity servers. This has allowed developers to prioritize speed of development and feature richness over granular performance tuning.
Consequently, the design of modern application software often relies on the assumption that underlying hardware power will compensate for any inefficiencies.
This principle does not, however, extend to all layers of the software stack. For foundational or basic software, such as Database Management Systems (DBMS), operating systems, and network protocols, efficiency remains a paramount design criterion. These systems form the bedrock upon which all other applications run, and their performance directly dictates the overall efficiency and cost-effectiveness of the entire infrastructure. Inefficiencies at this level cannot be easily abstracted away by adding more hardware; they create systemic bottlenecks that affect every process. It is for this reason that such software is still predominantly developed in languages like C, which provide the low-level memory and process control necessary for meticulous optimization. The continued relevance of C in these domains underscores the enduring need for highly efficient code at the core of our computing infrastructure.
Cloud computing pricing is a multifaceted domain, influenced by several key factors that collectively determine the final cost of services. Understanding these principles is crucial for effective budget management and resource optimization in a cloud environment.
Core Pricing Principles
At the heart of cloud pricing is the type of product or service being consumed. This encompasses both the foundational infrastructure—such as virtual machines, storage solutions, and networking components—and the software deployed atop it, which includes operating systems, databases, and specialized applications. The specific configurations and capabilities chosen for each of these elements directly impact the cost.
For example, a virtual machine with more vCPUs and RAM will inherently be more expensive than one with lower specifications. Similarly, premium software licenses will add to the overall expenditure.
Business Models and Market Dynamics
The business model selected for acquiring cloud resources significantly influences pricing.
- On-demand pricing offers the ultimate flexibility, allowing users to pay only for the resources they consume, without any long-term commitments. This model is ideal for workloads with unpredictable demand.
- In contrast, reserved instances provide a cost-effective alternative for consistent workloads. By committing to use specific resources for a predetermined period (typically one or three years), users can often secure substantial discounts compared to on-demand rates.
- A third model, spot pricing, leverages unused cloud provider capacity, offering highly discounted rates. However, these instances are subject to preemption by the provider if demand for on-demand or reserved instances increases, making them suitable for fault-tolerant or batch processing applications.
Beyond internal business models, market conditions also play a pivotal role. The competitive landscape among cloud providers can drive pricing strategies, leading to cost efficiencies for consumers. Furthermore, fluctuations in demand for specific services can introduce dynamic pricing adjustments, sometimes incorporating auction-based mechanisms where the price can vary based on real-time supply and demand.
The level of engagement a user has with a cloud provider can also impact pricing. Organizations with substantial resource consumption or long-term commitments often qualify for volume discounts, reflecting their significant investment and partnership with the provider.
Note
Ultimately, the total price paid is a complex calculation derived from the sum of the base price for each individual resource and any applicable discounts. This intricate interplay necessitates a robust approach to cost accounting, especially for organizations managing multiple applications, each with its unique architecture and blend of cloud services. The variability in usage patterns, chosen service tiers, and negotiated discounts underscores the importance of a dedicated financial operations (FinOps) capability. These teams are responsible for meticulously tracking expenditures, ensuring that provisioned resources (particularly dedicated machines) are actively utilized to prevent unnecessary costs, and fostering a culture of cost-consciousness throughout the organization. Cloud providers typically offer integrated accounting tools and simulators that enable users to monitor consumption, analyze spending trends, and forecast costs based on different usage policies, thereby empowering them to optimize their cloud expenditures effectively.
Google Cloud Platform Pricing Models
Google Cloud Platform (GCP) employs two fundamental pricing models: time-based pricing and unit-based pricing.
-
Time-based pricing dictates that the cost of a resource is directly proportional to the duration of its usage. This model is commonly applied to computational resources, where users pay for the amount of time a virtual machine is running or a specific service is active.
-
Unit-based pricing ties the cost to the quantity or volume of a specific resource consumed. This can manifest in various ways, such as the number of servers deployed, the volume of data stored or transferred, or the number of users accessing a particular service.
It is critical for users to identify the specific pricing model applicable to each individual cloud resource, as this can vary significantly even within the same cloud provider’s ecosystem. The dynamic nature of cloud pricing means that these models and their associated rates are subject to change, necessitating continuous monitoring and adaptation.
Given the complexity arising from diverse pricing models across various cloud resources, tools that facilitate cost estimation and management are invaluable. Google Cloud Platform provides a highly useful Price Calculator, an online utility that enables users to estimate their monthly cloud expenditure. This tool allows users to select specific GCP resources, configure their expected usage, and then provides an estimated cost. It accounts for the inherent pricing models of each resource, and in some cases, allows users to choose from available pricing options (e.g., on-demand versus committed use discounts).
Effective cost management in cloud computing extends beyond initial estimations. It necessitates a continuous process of monitoring, analysis, and optimization. While cloud platforms simplify many aspects of IT infrastructure management, they introduce a new layer of financial complexity that requires dedicated attention. Organizations must actively track their cloud consumption, identify underutilized resources, and implement strategies to control spending. This proactive approach ensures that the benefits of cloud flexibility and scalability are realized without incurring unforeseen or excessive costs.
Use Case Scenarios
Use Case 1: Dedicated Servers
For a company seeking to procure 5 identical dedicated servers, each with a minimum of 16 cores, 32 GB of RAM, and 300 GB of SSD storage, the cost comparison between Google Cloud Platform and Hetzner reveals a substantial difference.
Hetzner, a German cloud provider known for its competitive pricing, offers dedicated root servers. Based on typical offerings, a dedicated server from Hetzner matching these specifications (e.g., an EX-line server with an appropriate AMD or Intel CPU, 32GB RAM, and 500GB NVMe SSD as the closest match for 300GB SSD) could range from approximately €100 to €200 per month. Therefore, for five such servers, the total monthly cost from Hetzner would be in the range of €500 to €1000. Hetzner’s value proposition often centers on providing robust, high-performance hardware at significantly lower price points, primarily by offering less of the fully managed services inherent in hyperscale clouds.
In contrast, obtaining equivalent dedicated servers (or rather, virtual machines that behave like dedicated instances) on Google Cloud Platform (GCP) would involve using Compute Engine with a machine type offering dedicated vCPUs. Finding an exact “dedicated server” equivalent as a single unit in GCP’s pricing structure is not straightforward, as GCP typically bills for virtual machine instances. A custom machine type or a predefined machine type like
c2-standard-16(16 vCPUs, 64 GB RAM) orn2-standard-16(16 vCPUs, 64 GB RAM) with a custom disk size would be the closest approximation. Ac2-highcpu-16(16 vCPUs, 32 GB RAM) would be the most suitable given the specified RAM. Such an instance on GCP, when calculating for 16 vCPUs and 32GB RAM plus 300GB SSD, could easily cost upwards of800+ per month per instance for on-demand pricing. For 5 such instances, the total monthly cost on GCP would be in the range of 4000+. This significantly higher cost reflects GCP’s comprehensive suite of managed services, global network, advanced security features, and the inherent abstraction of virtualized resources. The operational overhead for a user is considerably lower, as Google handles the underlying hardware management, maintenance, and redundancy.
The observed difference, where GCP costs are approximately ten times that of Hetzner for dedicated server equivalents, underscores the different value propositions. Hetzner provides more of a “bare-metal as a service” or virtual private server (VPS) experience with less abstraction and fewer bundled services, appealing to users who prioritize raw cost efficiency and are comfortable with more self-management. GCP, as a hyperscale cloud provider, offers a more abstract and managed environment, simplifying deployment and operation but at a higher price point.
Use Case 2: Shared Servers
When comparing shared servers (cloud instances) with the same specifications across both providers, the cost differences are expected to persist, though the configurations might vary slightly as “shared” instances are more common on cloud platforms.
For Hetzner Cloud, a
CPX51instance offers 16 vCPUs, 32 GB RAM, and 360 GB NVMe SSD. The monthly cost for such a shared cloud instance from Hetzner is approximately €45-€50. For five such instances, the total monthly cost would be in the range of €225 to €250. This again highlights Hetzner’s aggressive pricing for its cloud offerings.On Google Cloud Platform, for shared instances, a general-purpose machine type like
e2-standard-16(16 vCPUs, 64 GB RAM) orn2-standard-16(16 vCPUs, 64 GB RAM) with 300GB SSD would be the closest. A more precise match for the CPU and RAM would be a custom E2 or N2 instance with 16 vCPUs and 32GB RAM. Ane2-highcpu-16(16 vCPUs, 32 GB RAM) instance on GCP, plus 300GB of standard SSD persistent disk, would likely cost around400+ per month per instance. For five such instances, the total monthly cost would be in the range of 2000+. Use Case 3: Fully Managed DBMS on GCP
The cost dynamics shift further when considering a fully managed database management system (DBMS) on Google Cloud Platform, such as Bigtable, a NoSQL wide-column database. Unlike purchasing raw server instances and then installing and managing a DBMS, a fully managed service abstracts away the operational complexities of the database.
Google Cloud Bigtable pricing is primarily based on two key components: provisioned nodes and storage.
- Nodes: Bigtable instances are provisioned with a specified number of nodes, and you are charged per node-hour. The cost per node can vary based on region and committed use discounts. For example, a single Bigtable node can cost approximately $0.85 per hour, which translates to about $612 per month (
). For five “servers” (which would be analogous to five Bigtable nodes if we directly map the concept, though Bigtable scales differently), the node cost alone would be approximately $3060 per month. - Storage: You are also charged for the amount of SSD storage your tables consume, typically per GB per month. For 300GB of SSD, this would be an additional cost per node, if we assume a direct mapping. However, Bigtable storage is charged based on the average amount of data stored, and it includes compression and compaction to reduce costs. The SSD storage cost is approximately $0.17 per GB per month. For 300GB, this would be around $51 per month per “server” equivalent (or per 300GB of data).
Therefore, equipping “five servers” with a fully managed Bigtable instance would involve significant costs for the Bigtable nodes and the storage. The total cost would be a combination of the node charges (which are for provisioned capacity, regardless of actual usage) and the data storage. This managed service significantly simplifies operations, offering automatic scaling, high availability, and built-in replication, but at a premium. The pricing model for Bigtable is indeed unit-based (per node-hour, per GB of storage).
In essence, while the initial cost of raw infrastructure from providers like Hetzner is significantly lower, the decision to opt for a hyperscale cloud provider like GCP with its managed services involves paying a premium for operational simplicity, reduced management overhead, advanced features, and global reach. For a startup or an organization without dedicated IT staff for server management, the higher cost of managed services can be justified by the immense time and resource savings on infrastructure and database administration, security, and scaling.
Cloud Pricing and Business Strategy
The comparison between Google Cloud Platform (GCP) and Hetzner for similar infrastructure highlights a crucial disparity in cloud pricing models, often reaching a factor of ten for Infrastructure as a Service (IaaS). This significant difference is not primarily due to technical performance variations, as both providers can offer comparable underlying hardware capabilities. Instead, the premium charged by hyperscale providers like Google stems from a combination of brand equity, perceived reliability, and the extensive ecosystem of managed services they offer. While Hetzner boasts excellent availability and focuses on cost-efficiency for bare-metal or near-bare-metal services, companies often opt for GCP due to its brand reputation, a psychological factor of choosing a perceived “best-in-class” provider, and the inherent trust in a global technology leader to handle any unforeseen issues.
The pricing structure reveals that the “cost” of cloud computing from hyperscale providers is often less about the raw infrastructure and more about the value of abstraction and fully managed services. For dedicated instances, the cost on GCP can be so substantial that it brings the trade-off between hiring in-house IT personnel to manage on-premise servers and purchasing cloud capacity much closer. This is particularly salient when considering that even self-managing an on-premise server farm involves significant costs related to power, cooling, physical security, and specialized IT staff, which can be double the cost of a provider like Hetzner. Thus, the decision to migrate to cloud, especially with a hyperscale provider, is rarely driven by direct cost savings on infrastructure alone.
A critical differentiator and a significant driver of higher costs for hyperscale providers is the fully managed software concept. Unlike providers such as Hetzner, which primarily offer hardware, GCP (along with AWS and Azure) provides a vast array of fully managed software services, such as databases (e.g., Bigtable), analytics platforms, machine learning services, and more. This means the cloud provider takes on the responsibility for provisioning, patching, scaling, and maintaining the software, thereby offloading complex operational tasks from the end-user.
This “hardware plus fully managed software” model is exceptionally valuable for developers and startups prioritizing rapid prototyping and agile development. By leveraging high-level, fully managed components and APIs, developers can quickly compose applications without needing deep operational expertise in each underlying system. This accelerates time-to-market and allows companies to focus their human resources on core business logic rather than infrastructure management. The ability to abstract away operational complexities at the software level is a significant benefit, especially in scenarios where speed and agility are paramount.
The prevailing narrative that cloud services are inherently cheaper than on-premise solutions is often a misconception. For many businesses, particularly Small and Medium-sized Enterprises (SMEs), cloud adoption may not lead to direct cost savings but rather to a shift in expenditure from capital expenditures (CapEx) to operational expenditures (OpEx). The benefits derived are often in terms of operational efficiency, increased agility, reduced time-to-market, and the ability to leverage specialized managed services that would be prohibitively expensive or complex to implement in-house. Companies like McKinsey or KPMG readily adopt cloud and Software as a Service (SaaS) because it simplifies their operations, allows them to deploy resources that are less scarce (e.g., low-code/no-code platforms), and enables faster, more dependable project delivery.
However, this model presents a challenge for European companies, which are often smaller in scale compared to their U.S. counterparts. The high cost of hyperscale cloud solutions, particularly for managed services, can be disproportionate to their size and business models, especially for more traditional industries. This creates a situation where the primary beneficiaries of the “softwareization” and cloud transformation are often the cloud providers and system integrators, with the end-user companies potentially struggling with increased costs without equivalent direct financial savings.
The key is awareness and strategic decision-making. Organizations must critically assess their business needs and trade-offs. If rapid prototyping and speed of delivery are paramount, a hyperscale cloud provider with its fully managed services is an excellent choice, even at a higher cost. However, if price competitiveness is a primary concern, then a strategy reliant heavily on expensive fully managed cloud services may not be suitable. Understanding these dynamics is crucial for companies, especially startups, to avoid being “caught in expenses that will take you nowhere” and to make informed decisions about their technology investments.