Fuzzing is a software testing technique designed to complement traditional functional testing methods, such as manually defined test cases based on functional requirement specifications. Unlike these structured approaches, fuzzing operates by providing randomly generated inputs to the system under test. It can be applied at either the component level or the system level, offering flexibility in its application. Beyond verifying correctness, fuzzing is particularly valuable for assessing external qualities like reliability and security, as it introduces unexpected or invalid inputs that might not be considered in other testing strategies.
One of fuzzing’s primary strengths lies in its ability to uncover defects that are difficult to identify using conventional methods. By relying on randomness, it generates scenarios that may reveal vulnerabilities or failures under rare and unpredictable conditions. The essence of fuzzing can be summarized as follows: it creates random inputs and evaluates whether they cause the system to behave incorrectly or break. Over time, prolonged fuzzing increases the likelihood of exposing latent issues within the system, providing an invaluable tool for quality assurance and security validation.
The Heartbleed Bug
A famous example of fuzzing’s effectiveness is its role in detecting the Heartbleed bug, a critical security vulnerability discovered in the OpenSSL library. OpenSSL is widely used for implementing cryptographic protocols that secure remote communications. The Heartbleed bug, introduced in 2012 and discovered in 2014, was a result of unchecked memory access in the library. Exploiting this flaw, an attacker could send a specially crafted command to the SSL heartbeat service, enabling unauthorized access to sensitive data from memory.
The discovery of Heartbleed was facilitated by researchers at Google who employed fuzzing techniques in conjunction with runtime memory-checking tools. This approach allowed them to identify and fix the vulnerability, preventing further exploitation. The incident highlights how fuzzing, combined with other diagnostic methods, can uncover even deeply embedded and critical security flaws in widely used software.
For more details about Heartbleed, visit Heartbleed.com.
An Example of Fuzzing: Testing the bc Utility
To illustrate how fuzzing works in practice, consider the UNIX utility bc, a basic calculator that interprets and evaluates mathematical expressions. For instance, the command:
echo "(1+3)*2" | bc
would return the result 8.
Fuzzing can be employed to evaluate the robustness of bc by subjecting it to unpredictable input streams. This involves the following steps:
Building a Fuzzer: A fuzzer is a program specifically designed to generate a random stream of characters. These characters will be used as inputs to the bc program, simulating unpredictable or malformed input conditions.
Testing bc with the Fuzzer: The goal is to use the fuzzer to send random inputs to bc in an attempt to cause unexpected behavior, errors, or crashes. This process evaluates the program’s ability to handle invalid or edge-case inputs gracefully.
For example, instead of sending structured mathematical expressions, the fuzzer might generate a nonsensical stream of characters, such as *&%$#1++ or incomplete expressions like (2+. By observing how bc processes these inputs, testers can identify vulnerabilities, memory leaks, or robustness issues.
The power of fuzzing lies in its systematic randomness, which often uncovers defects that deterministic testing misses. By generating a vast array of inputs over extended periods, fuzzing can simulate edge cases and rare conditions that traditional test cases are unlikely to address. Moreover, when combined with tools for runtime analysis, such as memory checking or logging mechanisms, fuzzing provides a deeper understanding of how the program behaves under stress or unexpected inputs.
In the example of bc, a robust implementation would safely handle any input, providing meaningful error messages or safely rejecting invalid data. A poorly implemented version, however, might crash, enter an infinite loop, or produce incorrect outputs—behaviors that fuzzing seeks to reveal. This approach exemplifies the broader utility of fuzzing in improving software quality, resilience, and security.
Building a Simple Fuzzer
Fuzzers are essential tools in software testing, generating random, unstructured inputs to uncover potential vulnerabilities or robustness issues in programs. Below is an example of a simple fuzzer implemented in Python. This fuzzer creates random strings composed of characters from a specified range, up to a maximum length.
import random# A string of up to `max_length` characters in the range# [`char_start`, `char_start` + `char_range`)def fuzzer(max_length: int = 100, char_start: int = 32, char_range: int = 32) -> str: string_length = random.randrange(0, max_length + 1) # Random integer in [0, max_length] out = "" for i in range(string_length): out += chr(random.randrange(char_start, char_start + char_range)) # chr(n) returns the character with ASCII code n return out
This function generates a string of random length (from 0 to max_length) with characters chosen from a range defined by char_start and char_range. By default, the characters fall between ASCII 32 (space) and ASCII 64 (@), covering symbols and numbers.
Using the default parameters:
max_length = 100char_start = 32char_range = 32
max_length: The maximum number of characters in the generated string. In this case, up to 100 characters.
char_start: The starting ASCII value of the characters to be included (default is 32, representing a space).
char_range: The total range of ASCII values to consider. Adding this to char_start determines the upper bound of the character set (default is 64, ending at ASCII 64, which is @).
For example, with char_start = 32 and char_range = 32, the characters range from ASCII 32 () to ASCII 63 (?). The function might produce output like:
Fuzz Inputs and Their Implications
Fuzz inputs refer to the random, unstructured data generated by a fuzzer. Programs often expect structured inputs in a specific format, such as a comma-separated list, email addresses, or mathematical expressions. Feeding random fuzz inputs to such programs can help identify issues such as crashes, unexpected behavior, or vulnerabilities.
What happens when fuzz inputs are used?
Robust Programs: A robust program should validate input formats and reject invalid inputs gracefully, without crashing or producing unintended behavior.
Weak Programs: Programs with poor input validation might crash, hang, or exhibit unpredictable results when faced with fuzz inputs.
Modifying the Fuzzer to Generate Specific Input Types
The fuzzer() function can be customized to generate various kinds of inputs. Below are some examples of potential modifications:
Sequence of Lowercase Letters (up to 100):
Modify the char_start and char_range to match the ASCII range for lowercase letters (a-z).
def lowercase_fuzzer(max_length=100): return fuzzer(max_length, char_start=97, char_range=26) # 'a' to 'z'
Random Digits (up to 1000):
Adjust the char_start and char_range for ASCII digits (0-9):
def digit_fuzzer(max_length=1000): return fuzzer(max_length, char_start=48, char_range=10) # '0' to '9'
Alternating Lowercase and Uppercase Letters (up to 200):
Modify the fuzzer logic to alternate between lowercase (a-z) and uppercase (A-Z) letters:
def alternating_case_fuzzer(max_length=200): out = "" for i in range(max_length): if i % 2 == 0: out += chr(random.randint(65, 90)) # Uppercase 'A' to 'Z' else: out += chr(random.randint(97, 122)) # Lowercase 'a' to 'z' return out
Integer or Float Values:
Instead of generating strings, you can produce numeric data:
def numeric_fuzzer(max_length=100, float_values=False): out = [] for _ in range(max_length): if float_values: out.append(random.uniform(-1e6, 1e6)) # Random floats else: out.append(random.randint(-1e6, 1e6)) # Random integers return out
Fuzzing External Programs
Fuzzing can also be used to test external programs by feeding them randomly generated input files and analyzing the results. This process is particularly useful for testing how robust a program is against unexpected or malformed inputs. Below is an explanation of how fuzzing can be applied to a program like bc, a simple UNIX calculator utility.
To begin, we define a test case by creating a temporary input file and passing it to the program (bc) for evaluation. The code snippet below demonstrates this:
import osimport tempfileimport subprocessbasename = "input.txt"tempdir = tempfile.mkdtemp() # Create a temporary directoryFILE = os.path.join(tempdir, basename) # Define the temporary file pathprogram = "bc" # Program to be tested (basic calculator)input = "2 + 2\n" # A nominal test input# Write input to the temporary filewith open(FILE, "w") as f: f.write(input)# Run the program with the input fileresult = subprocess.run( [program, FILE], stdin=subprocess.DEVNULL, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
Here:
tempfile.mkdtemp() creates a temporary directory to avoid cluttering the file system.
subprocess.run() executes the external program (bc) and captures its output, errors, and return code.
Similar functions in other languages:
Java: Runtime.getRuntime().exec(...)
C: system(...)
We can integrate the previously discussed fuzzer() function to generate random inputs and test the program against them. The goal is to determine whether the program crashes, hangs, or produces unexpected results when handling malformed inputs. Below is an example:
import random# Define testing parameterstrials = 100 # Testing budget (number of test cases)program = "bc" # Program to be testedruns = [] # Store test results# Perform fuzzingfor i in range(trials): # Run tests within the allocated budget with open(FILE, "w") as f: data = fuzzer() # Generate random input using the fuzzer f.write(data) result = subprocess.run( [program, FILE], stdin=subprocess.DEVNULL, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True ) runs.append((data, result)) # Store the input and result
At the end of the fuzzing process, the runs list contains all the random inputs and their corresponding outputs or error messages.
After executing the fuzzing tests, you can analyze the runs data to gather insights about the program’s robustness:
How many runs passed successfully?
Successful runs will have no error messages and a return code of 0:
sum(1 for (data, result) in runs if result.returncode == 0 and result.stderr == "")
How many runs failed or crashed?
Crashes or failures can be identified by non-zero return codes or non-empty error messages:
sum(1 for (data, result) in runs if result.returncode != 0)
Inspecting Specific Failures
You can iterate over the runs list to inspect specific inputs that caused failures:
for data, result in runs: if result.returncode != 0: print(f"Failed Input: {data}") print(f"Error Message: {result.stderr}")
Warning: Risks of Fuzzing Certain Programs
While fuzzing is a powerful technique, it can pose significant risks, especially when testing programs that modify the system state. For example, testing utilities like rm (file deletion) with random inputs can lead to severe consequences:
rm -fr FILE: Random inputs might inadvertently delete critical files or directories.
" /" (a space before /) could erase the entire file system.
"~ " could delete the user’s home directory.
". " could remove files in the current directory.
To minimize risks, ensure the tested program operates in a controlled environment (e.g., a virtual machine or sandbox).
Common Bugs Identified by Fuzzers
Fuzzing is an effective way to uncover various types of software bugs, particularly those that are hard to identify through traditional testing methods. These bugs often stem from flaws in how programs handle unexpected or malformed inputs.
Buffer Overflow
A buffer overflow occurs when a program writes data beyond the allocated memory for a buffer. This is common in languages like C, which lack built-in protections for such scenarios. For example:
If input contains the string "Wednesday", which is longer than 8 characters, the '\0' terminator will overwrite adjacent memory. This can lead to undefined behavior, including overwriting other variables, causing crashes, or even enabling arbitrary code execution.
Why it happens: Many programs fail to enforce input length restrictions, especially in low-level languages. Real-world impact: Buffer overflows are a common vector for security vulnerabilities, allowing attackers to inject malicious code.
Missing Error Checks
Programs that fail to check for errors when reading input or performing operations can behave unpredictably. Consider this example:
/* getchar returns a character from stdin; if no input is available, it returns EOF */while (getchar() != ' ');
Here, the program reads input one character at a time until it encounters a whitespace (' '). However, if the input ends (reaching EOF) before encountering a whitespace, getchar() will repeatedly return EOF. This leads to an infinite loop, causing the program to hang.
Why it happens: Languages like C often rely on explicit error checking instead of exceptions. Developers may neglect to handle edge cases, such as EOF or invalid inputs. Real-world impact: Missing error checks can result in infinite loops, program crashes, or other erratic behavior.
Rogue Numbers
Fuzzing often generates unusual or extreme numerical inputs that reveal unexpected behaviors. For example:
/* Reads a size from the input and allocates a buffer of the given size */char* read_input() { size_t size = read_size(); char *buffer = (char *)malloc(size); // fill buffer return buffer;}
If size is excessively large, it may exceed the program’s available memory, leading to a crash or a memory allocation failure. Similarly:
A negative value for size might be treated as a very large unsigned integer, causing unexpected behavior.
A small size might result in a buffer too small to hold the expected data, leading to memory corruption.
Why it happens: Programs often assume inputs will fall within a reasonable range, overlooking edge cases. Real-world impact: Rogue numbers can cause crashes, out-of-memory errors, or even security vulnerabilities like heap overflows.
Checking Memory Accesses
One of the best practices for fuzzing is combining it with runtime memory-checking tools. These tools help catch bugs that involve invalid memory operations, which are otherwise difficult to identify during testing.
A prominent example is the Address Sanitizer (ASan) provided by LLVM/Clang. This tool instruments the program at runtime to monitor memory operations and detect violations such as:
Out-of-bounds accesses: Attempting to access memory beyond the allocated bounds of a stack or heap buffer.
Use-after-free: Using memory after it has been deallocated.
Double-free: Attempting to free already deallocated memory.
Advantages
Drawbacks
Effectiveness: ASan can catch many memory-related bugs during testing.
Performance Overhead: Instrumentation typically doubles the program’s execution time and increases memory usage.
Automation: Reduces the need for manual debugging of memory issues.
Trade-off: Despite the slowdown, ASan significantly reduces the human effort required to identify and fix these bugs.
Combining fuzzing with tools like Address Sanitizer offers a powerful approach to uncover and fix bugs such as buffer overflows, rogue input handling, and missing error checks. These techniques enhance both the reliability and security of software, especially for critical systems written in low-level languages like C and C++. By proactively addressing these common issues during development, software teams can prevent vulnerabilities from being exploited in production environments.
Fuzzing with Mutations: Problem and Solution
Many programs require inputs to follow strict formats (e.g., URLs). Random input generation (generational fuzzing) rarely produces valid inputs for such cases.
Example
A valid URL requires specific elements:
scheme://netloc/path?query#fragment
scheme: Protocol (e.g., http, https)
netloc: Network location (e.g., www.example.com)
path: Resource path (e.g., /index.html)
query: Query parameters (e.g., ?q=fuzzing)
fragment: Document fragment (e.g., #section1)
The chance of randomly generating a valid URL (e.g., “http://”) is minuscule:
Generating such inputs through random fuzzing is infeasible due to astronomical time requirements.
Rather than generating inputs from scratch, mutational fuzzing modifies a valid seed input to explore new variations. This approach increases the likelihood of finding edge cases while maintaining valid or near-valid inputs.
Mutational Fuzzing Implementation
Mutation Operators
Simple manipulations (mutators) applied to a string:
Insert: Add a random character at a random position.
Delete: Remove a random character.
Flip: Change a random character (e.g., modify its ASCII value).
import random# Insert a random printable character at a random positiondef insert_random_char(s: str) -> str: pos = random.randint(0, len(s)) random_char = chr(random.randint(32, 126)) # ASCII 32-126 (printable characters) return s[:pos] + random_char + s[pos:]# Delete a random character from the stringdef delete_random_char(s: str) -> str: if not s: # Avoid errors on empty string return s pos = random.randint(0, len(s) - 1) return s[:pos] + s[pos + 1:]# Flip a random character's ASCII valuedef flip_random_char(s: str) -> str: if not s: # Avoid errors on empty string return s pos = random.randint(0, len(s) - 1) random_char = chr(random.randint(32, 126)) # Generate new random char return s[:pos] + random_char + s[pos + 1:]# Generate a fuzz input by applying a random mutatordef mutate(s: str) -> str: mutators = [delete_random_char, insert_random_char, flip_random_char] mutator = random.choice(mutators) return mutator(s)
Multiple Mutations on Seed Input
A single valid input is iteratively mutated to create diverse fuzz inputs:
# Start with a valid seed inputseed_input = "http://www.google.com/search?q=fuzzing"mutations = 50fuzz_input = seed_input# Apply a series of mutationsfor i in range(mutations): print(f"{i} mutations: {fuzz_input}") fuzz_input = mutate(fuzz_input)
With each mutation, the input deviates further from the original seed:
Higher Mutations → Higher Variety
As mutations accumulate, the input increasingly deviates from the original format, exploring a wide range of possibilities.
Too Many Mutations → Invalid Inputs
Excessive mutations may produce inputs that are too malformed to be processed effectively.
Advantages of Mutational Fuzzing
Higher Valid Input Probability : Starts with a valid seed, making outputs more likely to resemble valid inputs.
Deeper Code Coverage: Allows testing of edge cases and rarely executed paths, increasing the chance of finding hidden bugs.
Efficiency: Reduces the time required compared to random input generation by focusing on structured mutations.
Guiding Input Generation by Coverage
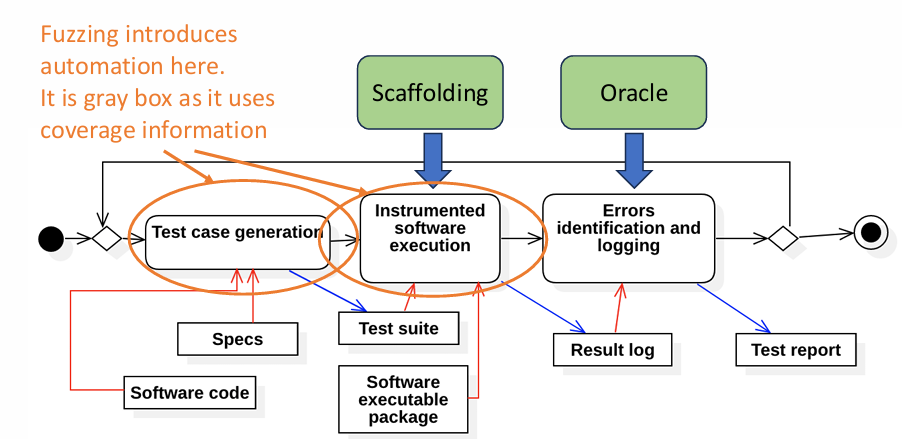
In fuzz testing, one challenge is to maintain a balance between generating diverse inputs and ensuring those inputs are meaningful for testing. A higher variety of inputs increases the likelihood of encountering unexpected edge cases, but it also raises the risk of producing invalid inputs that fail to explore the program effectively. To address this, modern fuzzers often employ coverage-guided fuzzing, a technique that uses code coverage information to prioritize and evolve inputs that uncover new program behaviors.
Coverage-Guided Fuzzing
Coverage is a widely used metric in software testing to evaluate the quality of test cases. It measures how much of a program’s code is exercised during testing, often quantified in terms of lines executed, branches traversed, or paths taken. In coverage-guided fuzzing, the goal is to evolve test inputs that maximize code coverage, which increases the chances of exposing bugs hidden in less frequently executed paths.
This approach operates in a gray-box testing paradigm, meaning the fuzzer has limited insight into the program’s internal structure but can observe code coverage during execution. The fuzzer begins with a set of seed inputs and keeps a population of those inputs that successfully exercise new paths in the program. When a new input discovers previously unexplored paths, it is added to the population for further mutation and testing. By iteratively applying this process, the fuzzer ensures systematic exploration of the program under test.
The implementation involves a utility function to execute test cases and record their coverage. For this, we assume the existence of a Coverage class that provides detailed execution information, such as which lines of code were executed during a test run. Below is an example of how this utility function can be structured:
PASS = "PASS"FAIL = "FAIL"def run_function(foo: Callable, inp: str) -> Any: with Coverage() as cov: try: result = foo(inp) outcome = PASS except Exception: result = None outcome = FAIL return result, outcome, cov.coverage()
Here, run_function takes as arguments a function foo (the program under test) and a string input inp. The function executes foo with inp while tracking code coverage. If an exception occurs, the test case fails (FAIL), otherwise it passes (PASS). The coverage is returned as a list of tuples, where each tuple contains the function name and line numbers executed during the test.
This output indicates that lines 465 in urlsplit and lines 394 and 400 in urlparse were executed during the last test.
Using this utility, a mutation-based fuzzer can evolve test inputs by applying small modifications while leveraging coverage information to guide its choices. Below is an example implementation:
def mutation_coverage_fuzzer(foo: Callable, seed: List[str], min_muts: int = 2, max_muts: int = 10, budget: int = 100) -> List[Tuple[int, str, int]]: population = seed cov_seen = set() summary = [] for j in range(budget): candidate = random.choice(population) trials = random.randint(min_muts, max_muts) for i in range(trials): candidate = mutate(candidate) result, outcome, new_cov = run_function(foo, candidate) if outcome == PASS and not set(new_cov).issubset(cov_seen): population.append(candidate) cov_seen.update(new_cov) summary.append((j, candidate, len(cov_seen))) return summary
This function starts with an initial population of seed inputs and iteratively generates new test cases by mutating these inputs. For each generated input, the program under test (foo) is executed, and its coverage is recorded. Inputs that achieve new coverage are retained in the population and contribute to future mutations. The process continues until the specified budget (number of iterations) is exhausted.
Practical Application
To demonstrate, consider testing the urlparse function with 10,000 fuzz inputs. The fuzzer begins with a valid URL seed:
The summary provides a detailed log of each test case, including its input, iteration count, and the cumulative coverage achieved. This ensures that all inputs generated are valid and explore different program paths.
Advantages of Coverage-Guided Fuzzing
Coverage-guided fuzzing is highly effective for both small and large programs. By focusing on inputs that reveal new code paths, it systematically explores the program, uncovering hidden bugs. Additionally, it is practical as it only requires a mechanism to capture and interpret code coverage, which can be implemented using runtime tools like instrumentation frameworks or specialized libraries.
This technique is particularly well-suited for programs with complex logic or nested conditions, as it ensures that deeper parts of the code are tested. Unlike purely random fuzzing, which may generate irrelevant inputs, coverage-guided fuzzing produces a high percentage of meaningful test cases, making it an invaluable tool for software testing.
AFL: A Successful Fuzzing Tool
American Fuzzy Lop (AFL), first released in November 2013, is one of the most notable successes in the field of fuzz testing. Developed as a robust, practical fuzzing tool, AFL demonstrated that failures and vulnerabilities in complex, security-critical applications could be detected automatically and at scale. This marked a significant milestone in software security.
AFL employs a combination of mutational fuzzing and coverage guidance, making it highly effective for uncovering vulnerabilities. Mutational fuzzing ensures that test inputs evolve from existing ones through small modifications, while coverage guidance focuses on generating inputs that explore new program paths. Together, these strategies enable AFL to systematically and efficiently test applications, even those with large codebases.
The tool’s impact extends beyond its technical achievements—it inspired a new wave of fuzzing tools and techniques, cementing its place as a cornerstone in the software testing ecosystem. For more details, the official AFL page can be found at AFL Official Site.
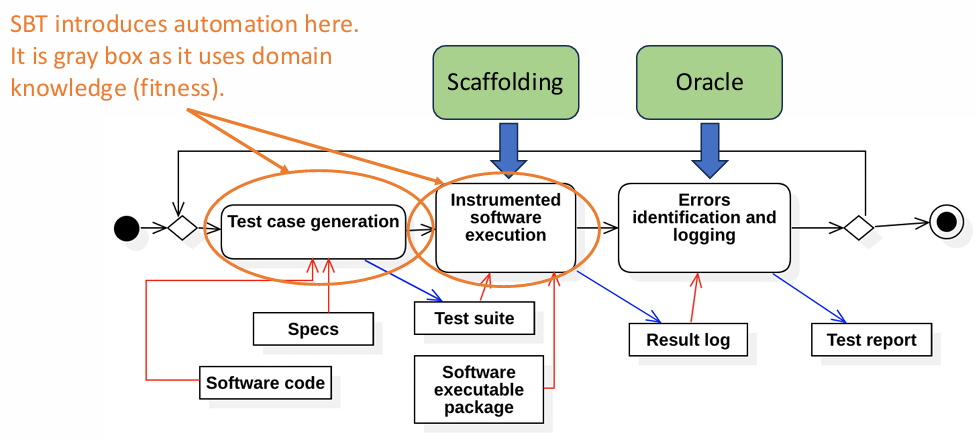
Search-Based Software Testing (SBST)
Search-Based Software Testing (SBST) complements traditional test case generation techniques by working at both the component and system levels. Unlike generic fuzzing approaches, SBST focuses on guiding test generation toward achieving a specific testing objective. This targeted approach often incorporates domain-specific knowledge, allowing for the creation of test cases that are more meaningful and aligned with the application context.
SBST is versatile and can address both functional and non-functional requirements. For example, it can assess the correctness of outputs (functional) or evaluate system reliability and safety (non-functional).
At its core, SBST redefines software testing as an optimization problem, where the goal is to find the best test cases to achieve a defined objective. These objectives can vary widely and might include:
Detecting incorrect or undesired outputs.
Violating specified requirements.
Reaching specific sections of source code.
Traversing specific execution paths.
To achieve these objectives, SBST relies on two key elements:
Search Space: The domain of all possible test cases.
Fitness Function: A metric to evaluate how well a test case achieves the testing objective.
By iteratively generating and refining test cases based on their fitness, SBST gradually narrows the search toward more effective test scenarios. This systematic exploration ensures that the testing process becomes increasingly efficient and goal-oriented.
SBST: A Motivating Example
Consider testing the steering control subsystem of an autonomous vehicle. This subsystem adjusts the steering angle to keep the vehicle on course. A key safety requirement might state:
“The vehicle shall always maintain a given safety distance from the center of the road.”
To test this requirement, SBST could define a search space of possible steering inputs and a fitness function that measures how closely the safety requirement is violated. By optimizing test cases to maximize this fitness value, the testing process identifies inputs that challenge the system’s ability to meet its safety requirements, thereby exposing potential vulnerabilities or flaws.
SBST follows a structured workflow to optimize the generation of test cases toward achieving a specific testing objective.
Algorithm
Identify the Objective
The first step is to define the precise testing objective. This could involve finding inputs that cause undesired outputs, trigger specific code paths, or violate safety requirements.
Define the Fitness Metric
A fitness function is created to measure how close a test case is to achieving the objective. This metric evaluates the “distance” between the current program behavior and the desired or undesired behavior. Each test case is uniquely represented by its input values.
Instrument the Code
To evaluate the fitness of test cases, the program’s code must be instrumented. This step involves modifying or extending the code to capture key information, such as execution traces or performance metrics, needed to compute the fitness values.
Generate Initial Test Cases
Initial test cases can be generated randomly or based on prior knowledge. These inputs provide the starting point for the optimization process.
Execute Test Cases and Measure Fitness
Each test case is executed, and its fitness value is calculated using the fitness function. The results determine how “good” the test case is in achieving the objective.
Refine and Iterate
If the current test cases do not meet the objective, new candidates are generated by refining the existing ones. This process continues in a loop until a sufficiently fit test case is found or computational resources are exhausted.
Stop Criteria
The process ends when a test case successfully achieves the objective or when other criteria, such as budget constraints, are met.
SBST in the Testing Workflow
SBST is positioned in the testing workflow as an advanced approach that complements traditional methods. Unlike generic fuzzing, which focuses on random or mutational test generation, SBST is goal-oriented, using domain-specific knowledge and optimization techniques to explore the input space effectively. By doing so, SBST bridges the gap between broad, unspecific testing methods and highly tailored, systematic approaches like symbolic execution or concolic testing.
Strengths and Weaknesses of SBST
SBST offers several advantages, but it also has limitations:
Strengths
Weaknesses
Specific Objective Guidance
Fitness Definition Complexity: Defining a meaningful fitness function requires detailed domain knowledge, which can be challenging for complex systems.
Unlike concolic testing or fuzzing, SBST explicitly targets defined objectives, such as reaching specific branches or exposing undesired outputs.
Heuristic Dependency: The quality of results heavily depends on the heuristics used to explore the test case space. Poor heuristics can lead to inefficient searches.
Meaningful Test Cases
Computational Overhead: The iterative nature of SBST makes it resource-intensive, especially for large or intricate software systems.
The incorporation of domain-specific knowledge allows SBST to generate test cases that are contextually relevant and actionable.
Incremental Optimization
SBST systematically improves test cases, ensuring eventual success if sufficient resources are available.
Tools Supporting SBST
One notable tool in the SBST ecosystem is EvoSuite, designed for Java programs. EvoSuite automates the generation of test cases to meet predefined objectives, such as achieving specific code coverage criteria. It also handles source instrumentation, making it an accessible choice for integrating SBST into software testing pipelines.
SBST: Latest Trends
The application of SBST has expanded to emerging domains, such as autonomous systems. For instance, SBST is used to test safety requirements in autonomous vehicles by generating scenarios (e.g., road shapes) where the system might fail to maintain lane discipline. This approach has been successful in identifying edge cases that would otherwise be missed through traditional testing methods. More information on this trend can be found in this paper.
Toy Example: Testing an Autonomous Vehicle Subsystem
Consider a subsystem responsible for controlling the steering angle of an autonomous vehicle.
Inputs and Outputs:
Inputs: Description of the road (xa, xb) and the car’s initial position (xcar).
Outputs: The trajectory of the car, represented as a sequence of xcar values.
Objective:
The goal is to identify test cases where the car’s trajectory crosses the center of the road (xi).
Distance Metric:
A function calculates the distance d between the car’s trajectory and the center of the road:
def get_distance(xa: int, xb: int, xcar: int): xi = (xa + xb) / 2 # Center of the road return min(simulate_car(xa, xb, xcar)) - xi
Fitness Function:
The fitness function evaluates how close the test case is to violating the safety requirement.
def fitness(xa: int, xb: int, xcar: int): r = get_distance(xa, xb, xcar) if r <= 0: # Crossing the center return 0 return r
The lower the fitness value, the better the test case, with zero fitness indicating success in finding a violation.
Test Generation as a Search Problem
In the context of software testing, test generation can be framed as a search problem where the goal is to explore a space of possible inputs to find those that meet specific objectives, such as exposing bugs or covering untested parts of code. The search space consists of all possible test cases, and a critical aspect of the search process is the notion of neighborhoods, which represent small variations of a given test case. Each test case in the space has neighbors—inputs that are closely related, often defined by a distance function.
For instance, consider a test case represented by a tuple of three inputs: (xa, xb, xcar). This tuple defines a point in the search space. The neighborhood of this point includes all tuples that differ slightly from the original, such as (xa-1, xb, xcar+1) or (xa, xb+1, xcar-1). For a three-dimensional space where each input can vary incrementally within a range, the neighborhood might include up to neighbors, excluding the test case itself. This localized exploration forms the foundation of many search-based algorithms in test case generation.
Fitness Functions and Heuristics
To navigate the search space effectively, a fitness function is employed to evaluate the “goodness” of each test case. The fitness function assigns a numeric value to a test case, with higher or lower values (depending on the context) indicating a closer alignment with the testing objective. For example, if the objective is to identify a situation where a vehicle crosses the center of the road, the fitness function might measure the minimum distance between the vehicle’s trajectory and the road center. A fitness value of zero would indicate success in finding such a test case.
Example
Here is an example of a simple fitness function in Python:
def fitness(xa: int, xb: int, xcar: int): r = get_distance(xa, xb, xcar) if r <= 0: return 0 return r
In this context, the goal is to iteratively refine the test cases, reducing the fitness value until the desired condition (e.g., a fitness of zero) is met. The definition of the fitness function is tightly coupled with the testing objective and determines the effectiveness of the search process.
Hill Climbing Search Algorithm
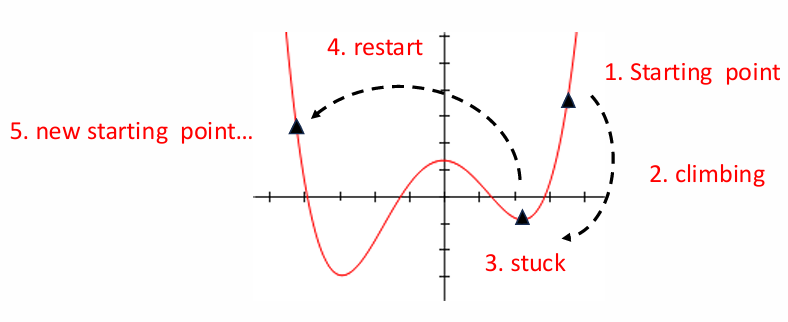
One commonly used algorithm for local search is hill climbing, which is a meta-heuristic approach that systematically explores the neighborhood of a test case to find better solutions. The process begins with a randomly chosen starting point in the search space. The algorithm then evaluates the fitness values of all neighbors and moves to the neighbor with the best fitness. This process repeats until the objective is achieved or the algorithm reaches a local optimum where no better neighbors exist.
The primary limitation of hill climbing is its tendency to get stuck in local optima, which are points in the search space that appear optimal within their immediate neighborhood but are suboptimal globally. A common way to escape such situations is to restart the search from a new random point. This approach, however, can be computationally expensive if the search space is vast or the neighborhood relations are complex.
Evolutionary Search
While hill climbing is effective for small search spaces or well-behaved fitness landscapes, it struggles with large or complex spaces where local search alone is insufficient. In such cases, evolutionary search can be used to perform more global exploration. Evolutionary algorithms, inspired by natural selection, introduce larger variations or “mutations” in test cases to traverse the search space more broadly while retaining key traits of the original inputs.
For example, consider a program that accepts UTF-16 strings of up to 10 characters as input. Since each character can be represented by 16 bits (65,536 possible encodings), the size of the search space becomes astronomically large. Hill climbing, which explores locally, would take an impractical amount of time to cover even a fraction of the space. Evolutionary search addresses this limitation by incorporating global exploration techniques.
Mutations in evolutionary search might include:
For strings: flipping a random character, adding/removing a character, or replacing a character with another randomly selected one.
For integers: adding or subtracting a small random number, flipping random bits in the binary representation, or applying small scaling factors.
These mutations allow the search to make significant leaps while still preserving the essence of the test case, ensuring that the search is neither entirely random nor confined to a narrow region.