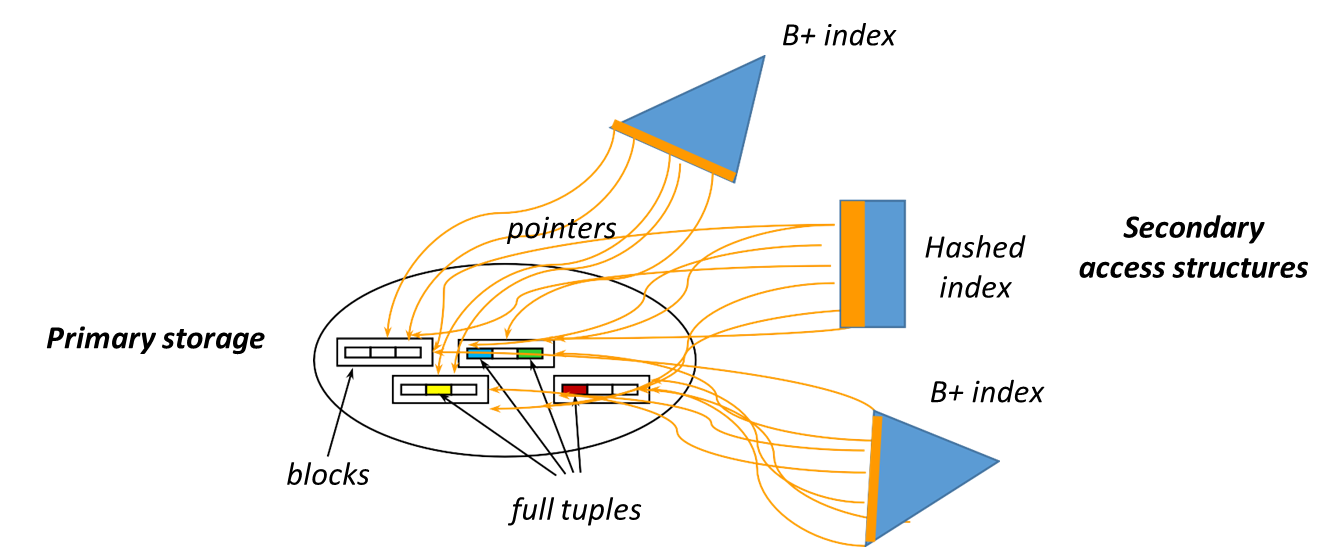
In database management, data structures are critical for enabling efficient retrieval of tuples using a specific search key (). These structures often store records in the form [search key, pointer to block], where the search key acts as an identifier to locate the associated data block. This concept is analogous to an analytical index found at the back of a book, where terms are listed alongside their corresponding page numbers in alphabetical order. The use of indexes in databases significantly improves the speed of data retrieval by organizing data access through a systematic approach.
Indexes come in two primary forms: dense and sparse indexes.
A dense index includes an entry for every search key value present in the data file. This type of index ensures that data can be retrieved quickly because the system needs only to search through the index to locate the corresponding tuple. This is especially useful when working with entry-sequenced primary structures, where every record is indexed, providing direct access to the required data. The downside of a dense index, however, is the higher storage requirement, as each search key in the file must be stored in the index.
A sparse index only holds entries for a subset of search key values. While this requires less storage space, it results in slower performance when trying to retrieve data. After identifying an approximate location using the index, the system may need to perform additional sequential scans of blocks to find the exact tuple. Sparse indexes work well when the data is sequentially ordered, and the search key matches the ordering key (). Despite the reduced space consumption, sparse indexes can slow down performance due to the extra steps involved in data access.
Primary Index
Definition
A primary index is defined on sequentially ordered data structures where the search key () is unique and aligns with the attribute by which the structure is organized, known as the ordering key (). This relationship is expressed as .
In a database table, only one primary index can be established, typically based on the primary key of the table, although it is not strictly required to be so. The primary index can be classified as either dense or sparse, depending on the specific implementation and data distribution.
It is crucial to differentiate between a search key and a primary key. While a search key is a collection of attributes utilized in an index to enhance the speed of tuple retrieval, a primary key is a set of attributes that uniquely identifies a tuple within the table.
A primary key must be minimal, unique, and not null, functioning as a constraint in SQL. The PRIMARY KEY designation in SQL denotes this constraint, which is facilitated through an underlying index.
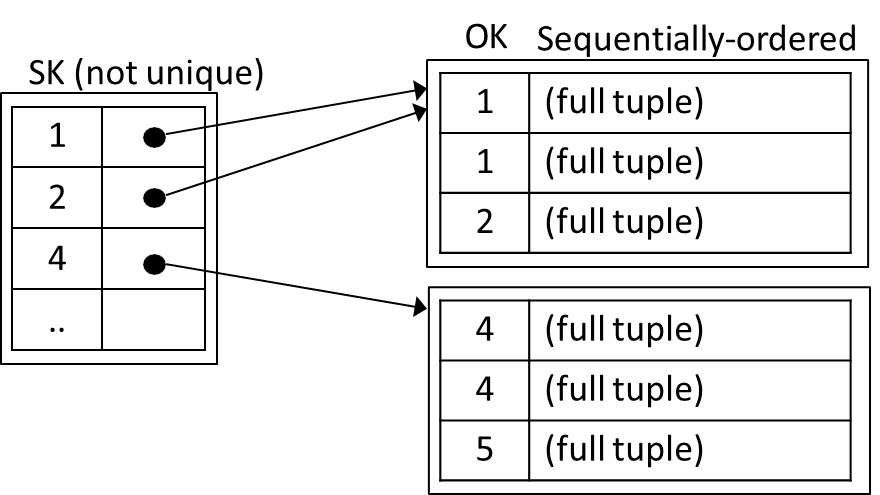
In contrast, a search key defines a common access path for retrieving data, where each search key value corresponds to one or more pointers. These pointers may lead to a single tuple (in the case of a unique search key) or multiple tuples (in the case of a non-unique search key).
Secondary Index
Definition
A secondary index is defined on a search key that specifies an order distinct from the sequential order of the file, represented as .
Unlike primary indexes, multiple secondary indexes can be created for a single table, each based on different search keys. Because the tuples associated with contiguous values of the key may be dispersed across various blocks in the database, secondary indexes are inherently dense. This density ensures that every search key value has an associated pointer, facilitating efficient access to the relevant tuples.
Clustering Index
Definition
A clustering index can be viewed as a generalization of the primary index, where the relationship holds, but the ordering key does not need to be unique. In this type of index, the pointer associated with a key directs to the block containing the first tuple corresponding to that key.
Clustering indexes can be either sparse or dense, but they are typically implemented as sparse. This means that one entry in the index corresponds to multiple tuples that share the same key, enabling efficient access to grouped data.
Summary of Index Types
Type of Index
Type of Structure
Search Key
Density
How Many
Primary
Sequentially ordered with
Unique
Dense or sparse
One per table
Secondary
Entry sequenced or sequentially ordered with
Unique and non-unique
Dense (not possible to scan primary data structure with respect to SK)
Many per table
Clustering
Sequentially ordered with
Non-unique
Typically sparse
One per table
Terminology can vary between different database systems. Terms such as primary, secondary, key, clustering, and clustered may have different meanings depending on the context and the specific database management system (DBMS) being used.
Smaller than primary data structures, secondary and clustering indexes can be efficiently loaded into main memory, enabling support for point and range queries, as well as sorted scans. For point queries, hash-based indexes may outperform other index types in terms of efficiency.
introducing indexes to database tables necessitates updates to the index following anyinsert, update, or deleteoperation. Therefore, while indexes enhance retrieval performance, they also come with a cost, potentially slowing down data modification operations due to the overhead of maintaining the index structure.
It is vital to recognize that
Hash-Based Indexes
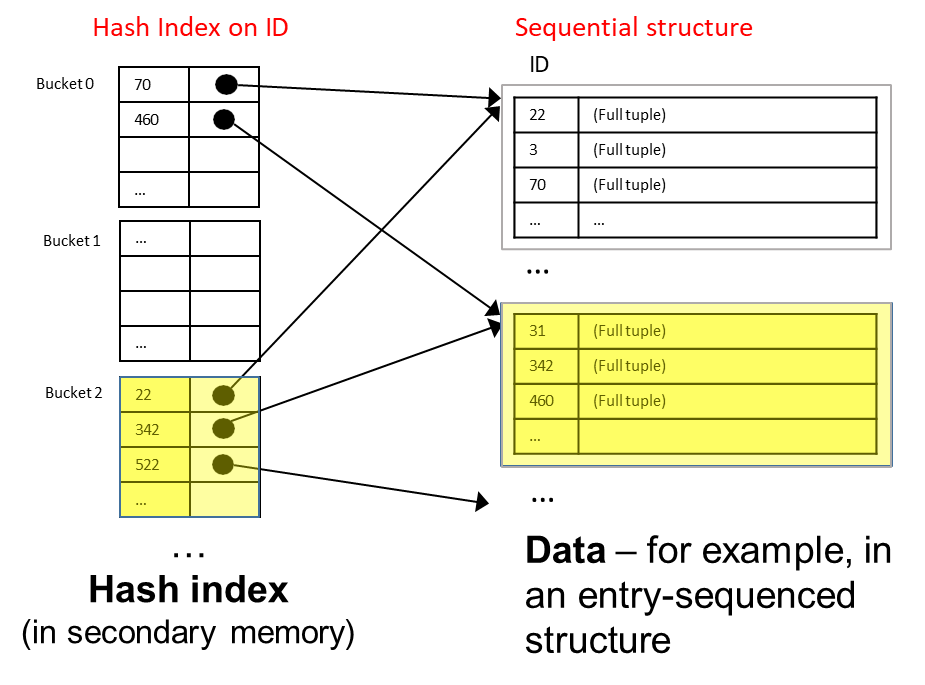
Hash-based indexes are a powerful data structure that can be employed as secondary indexes in database systems. They are structured and managed similarly to hash-based primary structures. However, instead of storing entire tuples, the buckets in a hash-based index only contain key values and pointers that reference the blocks holding the complete tuples. This design is particularly effective for optimizing queries that involve equality predicates on the search key, allowing for fast access to data based on specific criteria.
Example
Consider a scenario where we need to execute the SQL query
SELECT * FROM Student WHERE Student.ID = '342'
In this case, we can set the key to be the ID field in the Student table schema. The hash-based index will quickly compute the hash value for the ID and access the corresponding bucket.
To illustrate this process, let’s examine the steps involved in executing the aforementioned query using a hash-based index:
Hash Calculation: The database computes the hash value for the ID value ‘342’.
Index Access: The database accesses the hash index using this hash value, which takes one I/O operation.
Pointer Dereferencing: The index provides a pointer to the block containing the full tuple associated with ID ‘342’. This requires another I/O operation to fetch the complete tuple.
Overall, the total number of I/O operations in this example is : one for accessing the hash index (assuming there are no overflow chains involved) and another for retrieving the full tuple based on the pointer.
Advantages
Limitations
Efficiency: Enables rapid access to data for equality-based queries, significantly reducing the number of I/O operations required compared to traditional indexing methods.
Equality Predicate Limitation: Optimized for equality predicates, not suitable for range queries or pattern matching operations since they do not maintain any order among the keys.
Space Utilization: By storing only key values and pointers, hash-based indexes can save space, especially in scenarios where full tuples are large and frequently accessed.
Collision Handling: If multiple keys hash to the same bucket (a collision), managing these collisions may require additional structures like overflow chains, which can complicate retrieval times and degrade performance.
Tree-Based Indexes
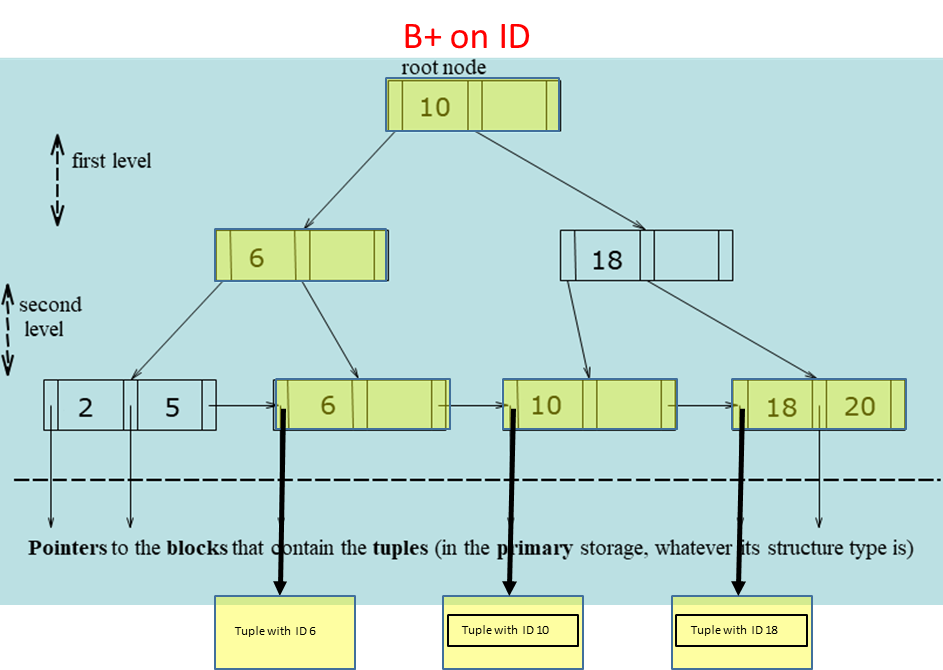
Tree-based indexes are a foundational data structure in most relational database management systems (DBMS), providing efficient associative access to data. Unlike hash-based structures, which excel only at point queries, tree-based indexes are highly versatile, offering excellent performance for both point queries (equality conditions) and range queries (interval conditions). The most prevalent implementation of this structure in modern SQL databases is the B+ tree, which is optimized for systems that read and write large blocks of data from disk storage.
B+ Tree Structures
Definition
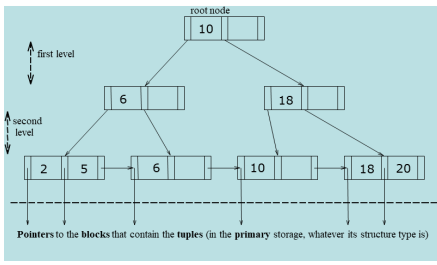
The B+ tree is a self-balancing, multi-level index structure with the following components:
Root node: The top-level node of the tree.
Intermediate nodes: Nodes between the root and the leaf nodes.
Leaf nodes: Contain all the key values and pointers to the blocks containing the full tuples.
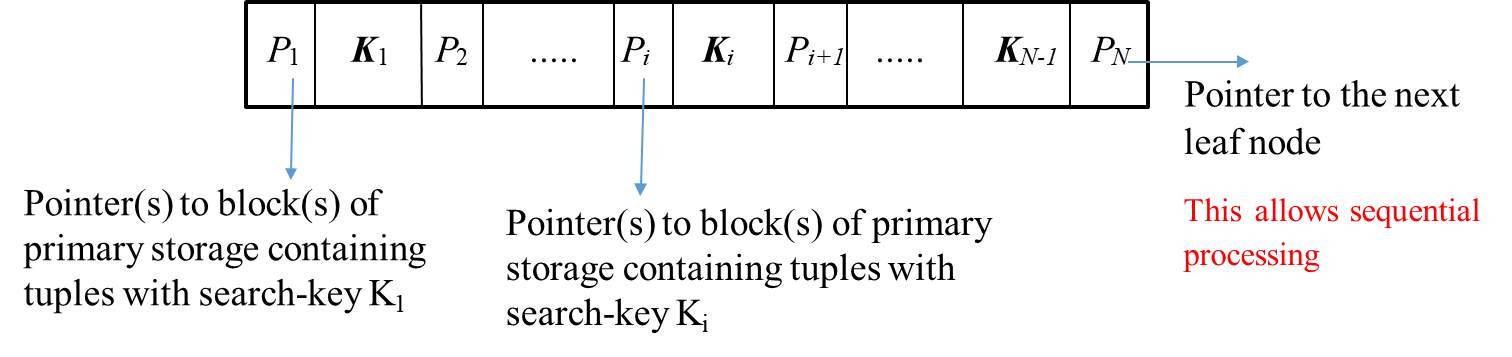
Each node in a B+ tree is stored in a block, and the structure generally supports a large number of descendants, known as the fan-out (or degree). Most of the blocks in the tree are leaf nodes. The fan out is determined by several factors, including the size of the block, the size of the key values, and the size of the pointers stored within each node. The number of levels in the tree structure is determined by the fan-out and the number of leaf nodes as where is the number of leaf nodes.
Each node can contain up to search keys, with at least key values required to maintain balance. These keys are stored in sorted order ( for ), ensuring that the tree remains balanced. The leaf nodes form a dense index, where each existing key value is stored in the node.
The intermediate nodes form a sparse index on the leaf nodes, holding up to search keys and pointers. Each internal node must have at least pointers (except the root node), ensuring that each node is at least half full.
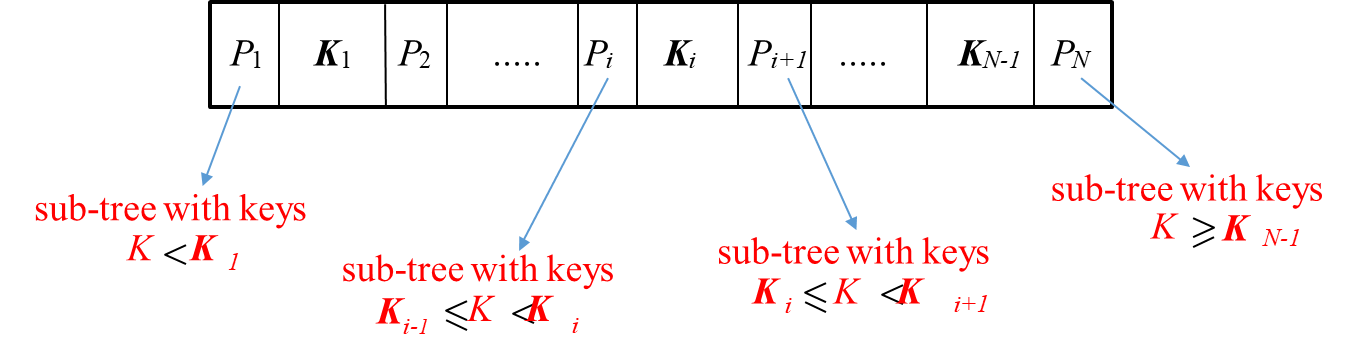
When searching for a tuple with a key value , the lookup process involves descending through the tree from the root to the leaf node. At each intermediate node, the search key values guide the traversal:
If , follow pointer .
If , follow pointer .
Otherwise, follow the pointer such that .
This method ensures an efficient search process, typically involving a logarithmic number of I/O operations relative to the number of tuples stored in the tree.
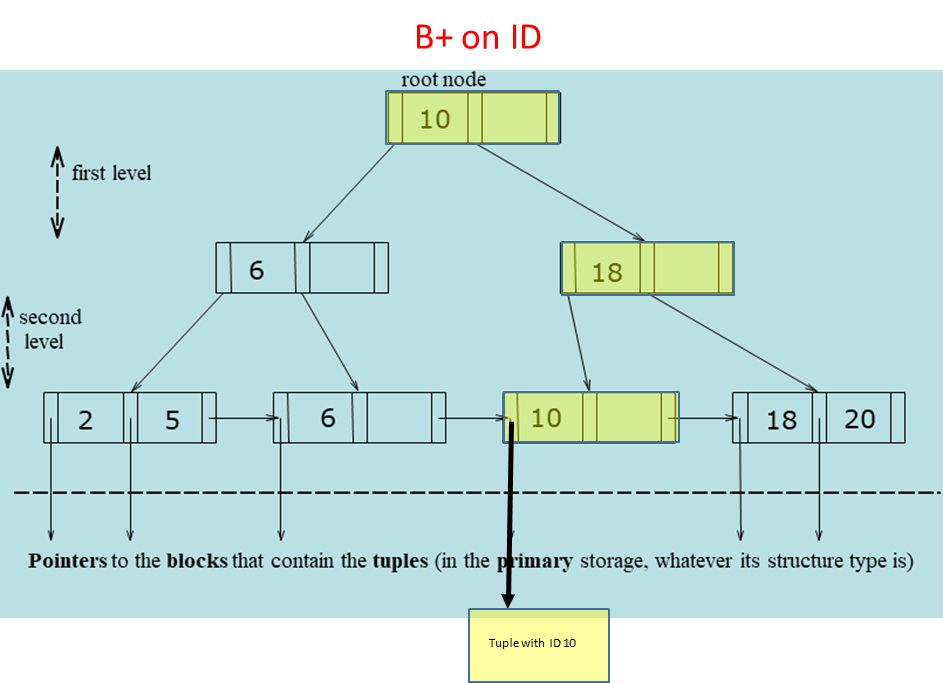
Consider the following example of a query using a B+ tree:
SELECT * FROM Student WHERE Student.ID = '10'
In this case, the number of I/O operations required is equivalent to the number of levels in the tree needed to reach the leaf node, plus one additional access to retrieve the block containing the full tuple.
For interval queries, such as:
SELECT * FROM Student WHERE Student.ID BETWEEN '6' AND '19'
The query needs to traverse the tree to find the starting point at leaf level and then continue visiting adjacent leaf nodes to retrieve all matching records. The number of I/O operations depends on the number of levels traversed to reach the leaf nodes, the number of leaf nodes visited, and the number of data blocks accessed.
In a modified version of the query, where we only need to retrieve the key values (without accessing the full tuples):
SELECT Student.ID FROM Student WHERE Student.ID BETWEEN '6' AND '19'
In this case, the leaf nodes themselves contain all the relevant key values, so only the B+ tree is accessed. As a result, fewer I/O operations are needed compared to retrieving full tuples.
The example requires 5 I/O operations: 2 intermediate levels to reach the leaf nodes and 3 leaf nodes to retrieve the key values.
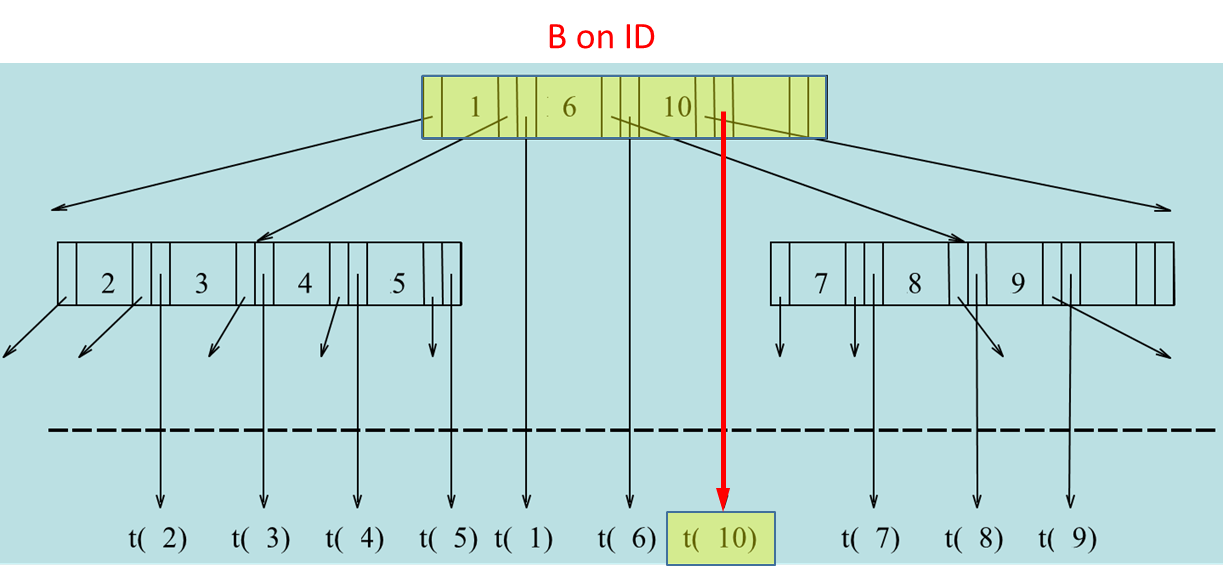
B Trees
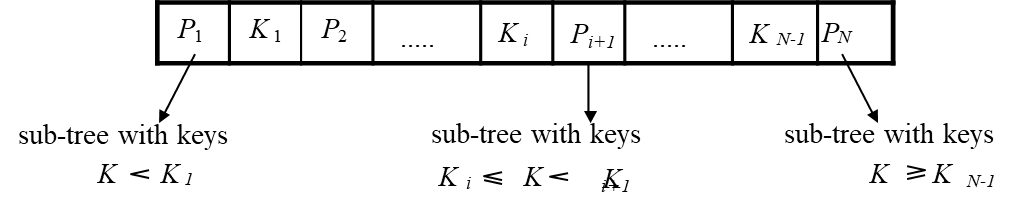
A B tree differs from a B+ tree in that it eliminates the redundant storage of search key values in the leaf nodes. In a B tree, each search key value appears only once, and intermediate nodes point to subtrees containing ranges of key values. For each key , the internal node holds a pointer to the subtree with keys between and , along with pointers to the blocks containing the tuples corresponding to .
While B trees can offer slightly faster lookups for exact matches, they are less efficient for interval queries compared to B+ trees. This is because B+ trees store all key values in a sequential order at the leaf level, enabling more efficient range queries.
Comparison
Feature
B+ Tree
B Tree
Key Storage
Stores all key values in leaf nodes and links them in a chain for efficient range queries.
Stores key values only once and uses intermediate nodes to link to subtrees and blocks.
Intermediate Nodes
Contains a sparse index to the leaf nodes. Supports equality and interval queries effectively.
More efficient for exact matches but less suited for range queries.
Advantages
Efficiently supports both point queries and range queries. Well-suited for scenarios requiring sorted access to data.
Space-efficient alternative but generally less preferred for interval queries.
Use Cases
Widely used in DBMSs due to their ability to efficiently support both point queries and range queries.
Suitable for exact matches but not ideal for range queries due to lack of sequential ordering at the leaf level.
Example
Consider to perform the following query: SELECT * FROM Student WHERE Student.ID = '10'. In this case, the number of I/O operations in the B tree is equal to the levels of the tree to find the ID ‘10’ plus 1 additional access to retrieve the block containing the full tuple. In the example only 2 I/O operations are required: one for the root node and one for the data block.
SQL Indexes
SQL indexes are essential for improving the performance of database queries. They function similarly to an index in a book, where you look up a keyword to quickly find the page number. In a database, an index allows the DBMS to locate records without scanning the entire table. SQL indexes can be created, modified, and dropped with specific SQL commands.
Definition
A SQL index can be created following the syntax:
CREATE [UNIQUE] INDEX IndexName ON TableName (AttributeList);DROP INDEX IndexName;
where:
CREATE INDEX: This command generates a new index.
UNIQUE: This ensures that all values in the indexed column(s) are unique.
ON TableName (AttributeList): Specifies the table and the column(s) to index.
DROP INDEX: Removes an existing index from the database.
SQL Index Example: Oracle and MySQL
In Oracle and MySQL, the syntax may slightly vary depending on the index type being created:
index_type: Specifies the structure used for indexing. The available types in MySQL are USING {BTREE | HASH}.
For instance, BTREE is commonly used for B+ tree indexes, which are suitable for range and equality queries, whereas HASH is used for hash-based indexes, which are ideal for equality searches.
For most tables, the following rules should apply:
Primary Storage: Each table should have a suitable primary storage, which is often sequentially ordered (for instance, on the primary key). This ensures efficient access for queries based on the primary key.
Secondary Indexes: Several secondary indexes, both unique and non-unique, should be created on the columns frequently used in queries, especially for WHERE clauses and joins.
Indexes help speed up data retrieval, but they also add overhead to INSERT, UPDATE, and DELETE operations. Therefore, indexes should be carefully selected based on usage patterns and query requirements.
Guidelines for Choosing Indexes
Here are some best practices to consider when deciding which indexes to create:
Do not index small tables: Indexing may not be necessary for small tables because the DBMS can scan the table quickly.
Index the Primary Key: If the primary key is not used as the key in the primary file organization (e.g., a heap), create an index for it. Some DBMSs automatically create unique indexes for primary and unique keys.
Index Heavily Used Columns: Add secondary indexes to columns heavily used as search keys or for joins.
Index Foreign Keys: Add secondary indexes on foreign key columns if they are frequently used in queries.
Index Columns for Sorting Operations: Index columns that are often involved in ORDER BY, GROUP BY, or operations requiring sorting such as UNION and DISTINCT.
Avoid Indexing Frequently Updated Columns: Indexing columns that are frequently updated will increase the overhead on INSERT, UPDATE, and DELETE operations.
Avoid Indexing Large Data Proportions: If a query retrieves a large proportion of records from a table, indexing may not be beneficial. Full-table scans might be more efficient in such cases.
Avoid Indexing Long Character Columns: Indexing columns that contain long strings (such as VARCHAR columns) may degrade performance due to the complexity of managing long key values.