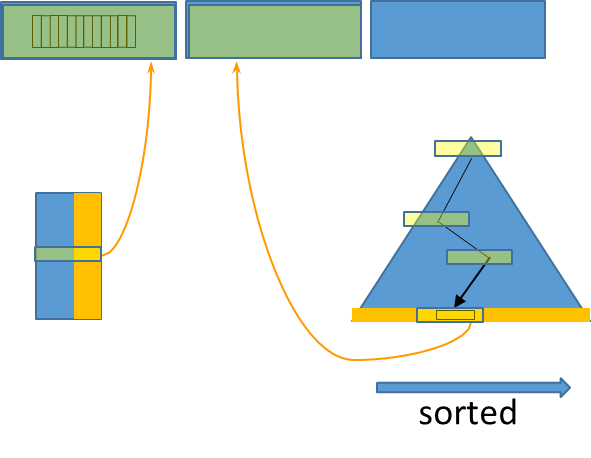
In the context of database management system (DBMS), understanding how to efficiently execute queries is paramount. When executing a query, the DBMS can utilize various methods to retrieve data, and this flexibility raises the question of how it determines the optimal approach.
The process begins with the DBMS receiving a SQL query, which it must analyze to determine the best execution plan. This is accomplished through a multi-step optimization process that includes lexical, syntactic, and semantic analysis, followed by translation into an internal representation akin to algebraic trees.
The initial phase of the optimization process involves lexical analysis , where the DBMS breaks down the query into its fundamental components. This is followed by syntactic analysis , ensuring that the structure of the query adheres to SQL grammar rules. Semantic analysis is then performed to validate that the elements of the query make sense within the context of the database schema, checking for the existence of tables, columns, and data types.
Once the query has been validated, it is translated into an internal representation that resembles algebraic trees. This structure facilitates various optimization techniques. The DBMS employs algebraic optimization to rearrange the components of the query to enhance efficiency. One key technique involves cost-based optimization , wherein the DBMS can “rewrite” the query for improved performance.
To illustrate the optimization process, consider a query that retrieves the last names and first names of students enrolled in a specific course. Given the following tables:
The SQL query is structured as follows:
SELECT LastName, FirstName FROM Student S JOIN Exam E ON S . ID = E . SID WHERE E . CourseID = 'DB2' ; This query can be represented through a query tree , where each node corresponds to an operation, such as selecting rows or projecting specific columns. The tree indicates the logical flow of operations, starting from the projection of last names and first names (from the SELECT clause JOIN clause WHERE).
graph LR
A[π LastName, FirstName] --> B[σ Student.ID = Exam.SID] --> C[σ Exam.CourseID = 'DB2'] --> X((x))
X --> D[Student]
X --> E[Exam]
The DBMS optimizes the query in several ways, including restructuring the query tree to create an equivalent but more efficient version, utilizing database statistics, and selecting efficient implementations for each operator. For example, consider an alternative optimization where the DBMS first filters Exam entries with the specified CourseID before joining with the Student table. This change reduces the number of rows processed in the join, which can significantly enhance performance.
graph LR
A[π LastName, FirstName] --> B[σ Student.ID = Exam.SID] --> X((x))
X --> D[Student]
X --> C[σ Exam.CourseID = 'DB2'] --> E[Exam]
To assess the effectiveness of various optimization strategies, the DBMS relies on statistics regarding the database. In this case, consider the following statistics:
The university has
Each student is enrolled in an average of
Only
With this data, the optimizer evaluates the cost associated with each potential query execution plan. It assesses costs for various operations, such as filtering exams by CourseID and joining the results with the student records. By comparing the costs of different execution plans, the optimizer can select the most efficient one.
graph TD
A[π LastName, FirstName] --> B[σ Student.ID = Exam.SID] --> C[σ Exam.CourseID = 'DB2'] --> X((x))
X --> D[Student]
X --> E[Exam]
A --- cost1{{200}}
B --- cost2{{200}}
C --- cost3{{3 600 000}}
X --- cost4{{3 240 000 000}}
D --- cost5{{18 000}}
E --- cost6{{180 000}}
A1[π LastName, FirstName] --> B1[σ Student.ID = Exam.SID] --> X1((x))
X1 --> D1[Student]
X1 --> C1[σ Exam.CourseID = 'DB2'] --> E1[Exam]
A1 --- cost11{{200}}
B1 --- cost21{{200}}
X1 --- cost31{{3 600 000}}
D1 --- cost41{{18 000}}
C1 --- cost51{{200}}
E1 --- cost61{{180 000}}
style cost1 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost2 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost3 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost4 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost5 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost6 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost11 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost21 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost31 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost41 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost51 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
style cost61 stroke:#f66,stroke-width:2px,color:#fff,stroke-dasharray: 5 5
Relation Profiles
In the context of relational database systems, relation profiles serve as essential metadata constructs that describe the quantitative characteristics of database tables. These profiles are not concerned with the actual data content per se, but rather with structural and statistical information that supports efficient query processing and system optimization. The information contained in relation profiles is maintained within the data dictionary , a specialized system catalog that stores metadata about the schema and statistics of the database.
One of the core components of a relation profile is the cardinality of a relation, which refers to the number of tuples (or rows) present in a given table. This metric is critical for query optimization, as it helps the database management system (DBMS) estimate the size of the data that will be processed . The DBMS can retrieve this information efficiently using queries like SELECT COUNT(*) FROM T, which often access precomputed values in the data dictionary rather than scanning the entire table.
Another important aspect of relation profiles concerns the dimensions of attributes , or columns. Each attribute is characterized by a specific data type and size, typically measured in bytes. This dimensional information is vital for memory management, especially in operations such as buffer allocation and data transfer during query execution.
The number of distinct values for each attribute is another statistical indicator maintained by the system.
For a given attribute selectivity of the attribute, which in turn influences the effectiveness of selection predicates.
Furthermore, relation profiles include minimum and maximum values for each attribute. These boundary values enable the DBMS to make rapid decisions regarding range-based queries and comparisons involving relational operators such as <, >, <=, and >=. By consulting these stored statistics, the system can often eliminate large portions of the data from consideration early in the query evaluation process, thereby improving performance.
Importantly, relation profiles are not static . To remain effective, they must be periodically refreshed to reflect changes in the underlying data. Maintaining up-to-date statistics is crucial for cost-based query optimization , a strategy in which the DBMS selects execution plans based on estimates of resource consumption.
Data Profiles and Selectivity of Predicates
Data profiles focus on the selectivity of predicates in query conditions.
Selectivity is defined as the probability that a given row will satisfy a specific predicate.
For an attribute
For example, if City = 'SomeCity' would be
In scenarios where data distribution information is lacking, the DBMS generally assumes a homogeneous distribution of values, which simplifies the estimation process but may lead to inaccuracies in specific cases.
Operations and Access Methods
The efficiency of query execution is also influenced by the choice of operations and access methods.
Operations Access Methods Description Selection Sequential access This operation retrieves rows that satisfy a certain predicate. It typically employs sequential access methods , scanning through the dataset to find matching tuples. Projection Hash-based indexing This operation focuses on extracting specific columns from the rows . Hash-based indexing is commonly used to optimize projection, allowing for faster access to relevant attributes. Sorting Tree-based indexing When data needs to be ordered based on specific attributes, tree-based indexing is an effective method. It allows for efficient traversal and retrieval of ordered data. Joining Varies The method of joining tables can vary widely based on the DBMS implementation, with various algorithms (e.g., nested loop, hash join) potentially used to optimize performance. Grouping Varies Similar to joining, the approach to grouping data for aggregation can differ based on the underlying database system, necessitating careful consideration of the method used for optimal performance.
Sequential Scan
A sequential scan is a fundamental method employed by DBMS to access and retrieve data from tables or intermediate results. This process involves sequentially accessing all tuples (rows) within a specified table and simultaneously executing various operations , such as projection and selection .
In the context of a sequential scan, projection refers to the operation of selecting a specific subset of attributes (or columns) from the tuples in a table. This allows the DBMS to retrieve only the necessary information , reducing the amount of data processed and returned to the user. Meanwhile, selection involves applying a simple predicate, typically in the form of
To illustrate the concepts of sequential scans and access methods, let’s consider a practical example involving two tables: STUDENT and EXAM.
STUDENT Table:
Total Tuples:
Each Tuple Size: ID, 25 for Name, 25 for LastName, 25 for Email, 12 for City, 3 for Birthdate, and 1 for Sex)
Block Size: 8KB (8,192 bytes)
Block Factor:
Total Blocks:
EXAM Table:
Total Tuples:
Each Tuple Size: SID, 4 for CourseID, 3 for Date, and 4 for Grade)
Block Factor:
Total Blocks:
If we execute the query
SELECT * FROM STUDENT WHERE City = 'Rome' ; the DBMS will perform a sequential scan on the STUDENT table. Given that the City attribute is not indexed, the DBMS must examine each tuple to determine if it meets the condition. This results in a total of STUDENT table.
However, if we perform a query like
SELECT * FROM STUDENT WHERE ID < 500 ; the DBMS can optimize the sequential scan by leveraging the ordering of the data. In this case, it can stop scanning once it reaches the first tuple where ID >= 500, effectively reducing the number of I/O accesses required to retrieve the relevant tuples.
Hashing and Tree-Based Indexing
Hashing is a technique primarily supporting equality predicates. It allows for rapid data retrieval based on exact matches . When a query includes a condition such as
On the other hand, tree-based indexes offer a broader range of capabilities. They support selection and join criteria, enabling efficient retrieval of related tuples from multiple tables. Furthermore, tree-based indexes are instrumental for operations that involve sorting, such as ORDER BY and GROUP BY clauses, as well as for eliminating duplicates through operations like UNION and DISTINCT.
Lookup
Predicate-based access , often referred to as lookup , is an efficient mechanism used by DBMS to retrieve data based on specified conditions or predicates. Indexes built on attributes
Simple Predicates : These are straightforward conditions of the form Interval Predicates : These include conditions that specify a range of values, such as
The cost of performing lookups is influenced by the storage structure being used:
Sequential Structures :
These structures do not inherently support efficient lookups, resulting in a full table scan for access , which can be costly in terms of performance. However, if the data is stored in a sequentially ordered manner, the cost can be reduced somewhat, as the DBMS may stop searching once the desired condition is met.
Hash and Tree Structures :
Lookups are supported when
Storage Type : This includes whether the index is primary or secondary.Search Key Type : The nature of the keys, whether they are unique or non-unique, plays a significant role in determining lookup costs.
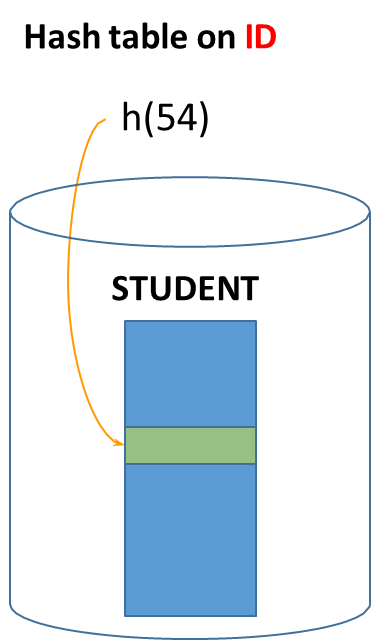
Equality Lookup on a Primary and Secondary Hash
Consider the following SQL query that aims to retrieve a specific student record based on the unique identifier:
SELECT * FROM STUDENT WHERE ID = '54' ;
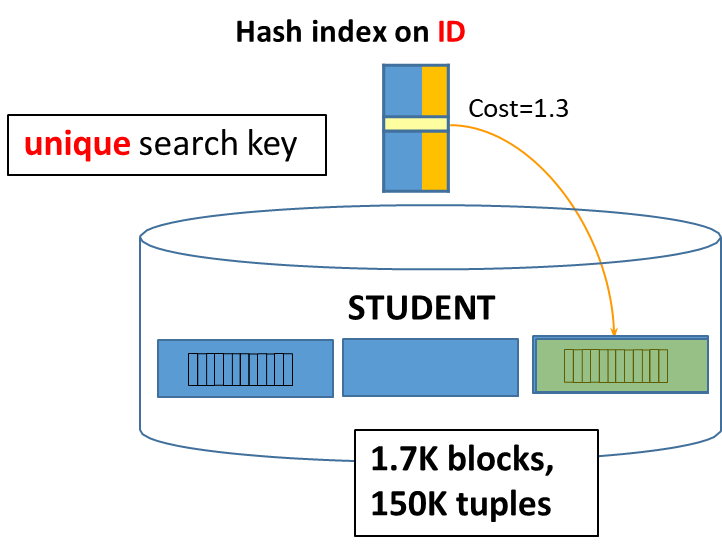
In this case, the query predicate directly targets the search key (no overflow chains , the DBMS can access the block containing the tuple with
However, if there are overflow chains (additional data that might be stored elsewhere due to collisions in the hash structure), the cost may increase. For instance, if the cost of handling overflow chains is
Now, consider the same SQL query, but this time using a secondary hash index :
When using a secondary hash index, the situation is similar to that of a primary hash index regarding the initial lookup cost. The cost remains
Misplaced & 1 \text{ I/O accesses} & \text{ (no overflow chains)}\\ 1.3 \text{ I/O accesses} & \text{ (overflow chains)} \end{aligned}$$ However, <u>with a secondary hash, the DBMS must also access the block that contains the full tuple, which adds to the overall cost</u>. Therefore, the total cost for this operation can be represented as: - Cost with overflow chain: **$1.3$ I/O accesses** (to access the hash index) - Plus an additional access for the block containing the full tuple. $$\text{TOTAL COST: } \qquad 1.3 + 1 = 2.3 \text{ I/O accesses}$$ ### Query Predicate on a Non-Unique Search Key $$\text{STUDENT}(\underline{\text{ID}}, \text{FirstName}, \text{LastName}, \text{Email}, \text{City}, \text{Birthdate}, \text{Sex})$$ Consider a query that retrieves students with a specific $\text{LastName}$, which may not be unique across the dataset: ```sql SELECT * FROM STUDENT WHERE LastName = 'Rossi'; ``` In this case, the query predicate targets a **non-unique search key**, meaning that multiple tuples can correspond to the same $\text{LastName}$. The cost structure for this operation includes the following components: - **Initial Access to the Hash Index**: The cost remains **$1$ I/O access**. If overflow chains exist, this cost increases by the size of the overflow chain (e.g., $0.3$), leading to a total of **$1.3$ I/O accesses**. - **Accessing Full Tuples in Primary Storage**: Since the query could return multiple tuples (for example, all students with the last name "Rossi"), additional I/O accesses are necessary. If we assume $val(LastName) = 75,000$ in a dataset of $150,000$ tuples, we estimate that each last name appears, on average, twice ($\frac{150K}{75K}= 2$). Therefore, for each last name, the DBMS would need to follow **$2$ pointers** to access the corresponding tuples. The total cost of accessing the relevant data in this scenario can be summarized as: - Cost to access the hash index (with overflow chain): **$1.3$ I/O accesses**. - Plus the cost to access the full tuples needed for the `SELECT *` operation: **$2$ I/O accesses** (for the two tuples corresponding to "Rossi"). $$\text{TOTAL COST: } \qquad 1.3+2 = 3.3 \text{ I/O accesses}$$ > [!NOTE] > > When retrieving data using a non-unique key, we cannot assume that all "Rossi" tuples are stored in the same block of primary storage. This lack of certainty can further influence the I/O costs associated with the query execution. ## Equality Lookup on a Primary and Secondary B+ Tree When performing a lookup on a primary [[2.2 - Indexes|B+ tree]], the efficiency of data retrieval is significantly influenced by whether the query predicates target unique keys or non-unique keys. \begin{aligned}
\text{STUDENT}&(\underline{\text{ID}}, \text{FirstName}, \text{LastName}, \text{Email}, \text{City}, \text{Birthdate}, \text{Sex}) \
\text{EXAM}&(\underline{\text{SID}}, \underline{\text{CourseID}}, \text{Date}, \text{Grade})
\end{aligned}
You can't use 'macro parameter character #' in math mode For instance, consider the following SQL query aimed at retrieving a specific student record using a unique identifier: ```sql SELECT * FROM STUDENT WHERE ID = 54; ``` ![[2.3 - Introduction to Optimization-1753622305527.png|153x177]] In this case, the search key is unique, meaning that <u>only one tuple corresponds to the key value of </u>$54$. The cost associated with this query involves traversing the [[2.2 - Indexes|B+ tree]] structure. Specifically, the query requires accessing $3$ intermediate levels of the tree and 1 leaf node, resulting in $$\text{TOTAL COST: } \qquad 3 + 1 = 4 \text{ I/O accesses}$$ > [!important] It is important to note that the leaf nodes of a primary [[2.2 - Indexes|B+ tree]] contain the entire tuples, allowing for efficient retrieval once the appropriate leaf node is reached. > If the query does not use the search key, as in the following SQL statement: ```sql SELECT * FROM STUDENT WHERE City = "Milan"; ``` ![[2.3 - Introduction to Optimization-1753622342237.png|164x175]] In this scenario, the DBMS needs to reach and scan all the leaf nodes in the [[2.2 - Indexes|B+ tree]] to identify relevant records. The cost is considerably higher due to the necessity of scanning through all the leaf nodes. $$\text{TOTAL COST: } \qquad \underbrace{(4-1)}_{\text{intermediate levels}} + 2000 = 2003 \text{ I/O accesses}$$ For queries that target a non-unique search key, the access cost calculation involves several factors: ![[2.3 - Introduction to Optimization-1753622451351.png|167x192]] 1. **Access Levels**: It takes 4 levels to reach the first leaf node. 2. **Statistics**: With $val(City) = 150$, we can determine that there are approximately $1,000$ tuples per city, given that the total number of student tuples is $150,000$. 3. **Leaf Node Capacity**: Since each leaf node can contain about $75$ tuples ($150,000$ tuples / $2,000$ leaf nodes), the number of blocks needed for students from "Milan" can be calculated as follows: - Total Milan tuples = $1,000$ - Leaf nodes needed = $1,000 / 75 \approx 13.33$, which rounds up to **$14$ leaf nodes**. $$\text{TOTAL COST: } \qquad 3 + 14 = 17 \text{ I/O accesses}$$ ### Equality Lookup on a Secondary B+ Tree Using a secondary [[2.2 - Indexes|B+ tree]], consider the following SQL query that retrieves a student record based on a unique identifier: ```sql SELECT * FROM STUDENT WHERE ID = "54"; ``` ![[2.3 - Introduction to Optimization-1753622538742.png|209x210]] In this case, the cost for the operation includes accessing 3 intermediate levels of the [[2.2 - Indexes|B+ tree]], 1 leaf node, and an additional access for the data block containing the full tuple. $$\text{TOTAL COST: } \qquad (3 + 1) + 1 = 5 \text{ I/O accesses}$$ If the query does not target the search key, as in the example: ```sql SELECT * FROM STUDENT WHERE City = "Milan"; ``` ![[2.3 - Introduction to Optimization-1753622578917.png|214x215]] In this case, the index becomes ineffective, and the DBMS would need to perform a full table scan. This full scan incurs a cost of approximately **$1700$ I/O accesses**, which is considerably higher than the indexed lookup. $$\text{TOTAL COST: } \qquad (4-1) + 1700 = 1703 \text{ I/O accesses}$$ For a query on a non-unique search key, such as: ```sql SELECT * FROM STUDENT WHERE LastName = "Rossi"; ``` ![[2.3 - Introduction to Optimization-1753622604725.png|199x183]] We can derive the cost as follows: 1. **Statistics**: Assume $val(LastName) = 75,000$. Given there are $150,000$ pointers to student tuples, on average, each last name appears approximately twice. 2. **Block Calculation**: The number of pointers fitting in each block can be computed: - $150,000$ pointers / $75,000$ distinct last names = $2$ pointers per last name. - $150,000$ pointers / $2,000$ blocks = $75$ pointers per block, which means 2 tuples fit in one block. The total cost includes the following components: - Accessing the B+ tree levels: **$3$ intermediate $+ 1$ leaf**. - Accessing the blocks containing the student records: **$2$ blocks**. Thus, the total cost for the query is **$6$ I/O accesses** (3 for intermediate levels, 1 for the leaf node, and 2 for accessing the student records). $$\text{TOTAL COST: } \qquad (3 + 1) + 2 = 6 \text{ I/O accesses}$$ For a query like: ```sql SELECT * FROM EXAM WHERE Date = "10/6/2019"; ``` Assuming $val(Date) = 500$, we can compute the number of tuples per date. With a total of $1.8$ million tuples, the average is $1,800,000 / 500 = 3,600$ tuples per date. ![[2.3 - Introduction to Optimization-1753622701621.png|236x170]] The number of leaf nodes that would contain pointers to these tuples can be estimated as follows: - Pointers per leaf node = $1,800,000 / 2,000 \approx 900$. - Leaf nodes per date pointers = $3,600 / 900 \approx 4$, which suggests that these pointers would fit across 4 blocks. Consequently, the cost can be broken down into: - Number of intermediate levels: $3$. - Number of leaf nodes accessed: $4$. - Total number of blocks to access in the `EXAM` table: $3,600$ (for the pointers to the tuples). $$\text{TOTAL COST: } \qquad 3 + 4 + 3,600 = 3,607 \text{ I/O accesses}$$ > [!important] It is important to note that <u>the queried date may not be located at the left-most key in the block, necessitating further I/O operations for complete retrieval</u>. > > [!summary]- Summary Table: Lookup Costs by Access Method and Key Type > > > | Access Method | Key Type | Cost (I/O Accesses) | Notes | > |---------------------- |--------------|------------------------------------|-----------------------------------------------------------------------------------------| > | **Sequential Scan** | Any | $\approx$ Total blocks in table | Full table scan; no index support; cost proportional to table size | > | **Primary Hash** | Unique | 1 (no overflow), 1.3 (with overflow) | Direct access to block; overflow chains increase cost | > | **Secondary Hash** | Unique | 2 (no overflow), 2.3 (with overflow) | Index block + data block; overflow chains increase cost | > | **Primary Hash** | Non-Unique | 1 (no overflow) + pointers | 1 for index + 1 per tuple; cost increases with duplicates | > | **Secondary Hash** | Non-Unique | 1 (no overflow) + pointers | 1 for index + 1 per tuple; cost increases with duplicates | > | **Primary B+ Tree** | Unique | `#levels` (e.g., 4) | Traverse tree to leaf; leaf contains full tuple | > | **Secondary B+ Tree** | Unique | `#levels + 1` (e.g., 5) | Traverse tree to leaf + access data block | > | **Primary B+ Tree** | Non-Unique | `#levels + #leaf` blocks | Traverse tree; scan all leaf blocks for key; cost depends on duplicates | > | **Secondary B+ Tree** | Non-Unique | `#levels + #leaf blocks + #tuples` | Traverse tree; scan leaf blocks; 1 data block per tuple | > | **Primary B+ Tree** | Interval | `#levels + #leaf` blocks in interval | Traverse to first leaf; scan linked leaves for range | > | **Secondary B+ Tree** | Interval | `#levels + #leaf blocks + #tuples` | Traverse to first leaf; scan leaves; 1 data block per tuple in interval | > > **Legend:** > - `#levels`: Number of intermediate tree levels traversed (typically 3–4) > - `#leaf` blocks: Number of leaf blocks containing matching keys > - `#tuples`: Number of matching tuples (for non-unique or interval queries) > - Overflow: Additional cost due to hash collisions ## Indexes on Non-Unique Attributes When a [[2.2 - Indexes|B+ tree]] index is created on a **non-unique attribute**, multiple tuples can be associated with the same search key. This results in <u>several pointers within the leaf nodes pointing to the tuples corresponding to that key</u>. Here are some important points to consider: - **Multiple Leaf Nodes**: It's possible for the [[2.2 - Indexes|B+ tree]] to have multiple leaf nodes corresponding to the same key value. These nodes may contain pointers to tuples with identical values for the indexed attribute. There may also be intermediate nodes that contain keys present in the first position of multiple leaf nodes. - **Key Order**: Each level of the B+ tree will maintain a sorted order of keys, where $K_1 ≤ K_2 ≤ K_3 ≤ ... ≤ K_m$. This ordering applies not only to the leaf nodes but also to the intermediate nodes. - **Search Algorithm Modification**: When searching for a key, once a leaf node is reached, if the search key $K$ is found as the first key in that node, the algorithm must also check the preceding sibling. This necessitates the use of a **doubly linked list** among leaf nodes to facilitate traversal. The search continues through the chain of leaf nodes until a key greater than $K$ is encountered. ![[2.3 - Introduction to Optimization-1753622852758.png]] ### Interval Lookups A<sub>i</sub><v, v<sub>1</sub> ≤A<sub>i</sub>≤v<sub>2</sub> **Interval lookups** enable the retrieval of data tuples that fall within a specified range of values for a given attribute. This capability is exemplified in SQL queries such as ```sql SELECT * FROM EXAM WHERE Date < "10/6/2019" SELECT * FROM EXAM WHERE Date BETWEEN "10/6/2019" AND "10/10/2019" ``` The efficiency with which these lookups are performed is heavily dependent on the underlying physical data structures employed by the database. **Sequential and hash-based storage structures** inherently lack efficient mechanisms for interval lookups. In both cases, <u>the absence of an ordered arrangement of data based on the lookup attribute necessitates a full table scan</u>, where every record must be examined to identify those that satisfy the interval criteria. **This leads to a performance bottleneck**, particularly for large datasets. Conversely, **tree-based** indexing structures, specifically B+ trees, are well-suited for supporting interval lookups, provided that the indexed attribute $A_i$ serves as the search key. > [!important] The performance and cost associated with these lookups are influenced by whether the [[2.2 - Indexes|B+ tree]] is a [[2.2 - Indexes|primary or secondary index]] and whether the key values are unique or non-unique. > When an interval lookup, such as $v_1 \leq A_i \leq v_2$, is performed on a **primary B+ tree**, the process begins by accessing the root node. Subsequently, one node at each intermediate level of the tree is read until the first leaf node containing tuples where $A_i = v_1$ is located. From this point, if all the required tuples within the specified range ($v_1$ to $v_2$) reside within the initial leaf block, the search can be terminated. However, if the interval spans beyond this single block, the search continues by traversing through the horizontally linked leaf nodes until all tuples up to $A_i = v_2$ have been retrieved. <u>The total cost for such an operation is calculated as the sum of 1 block access for each intermediate level traversed and the number of additional leaf blocks that must be accessed</u> to encompass all tuples within the defined interval. Similarly, an interval lookup on a **secondary B+ tree** follows a comparable procedure. The operation initiates with reading the root node, followed by accessing one node at each intermediate level until the first leaf node is reached. This leaf node contains pointers to data records where $A_i = v_1$. If all the necessary pointers to tuples within the range up to $v_2$ are contained within this initial leaf block, the search concludes. Otherwise, the traversal continues through the linked leaf nodes, accessing additional blocks that contain pointers until the $v_2$ threshold is met. The cost associated with this process includes 1 block access for each intermediate level, plus the block accesses required for any additional leaf blocks accessed to retrieve all pointers within the interval. Crucially, an additional data block access is incurred *for each* pointer retrieved, as this is necessary to fetch the actual data tuple from the data file. ## Predicates in Conjunction and Disjunction **Predicates in conjunction** and **disjunction** refer to the logical operations used in SQL queries that combine multiple conditions in the `WHERE` clause. ```sql SELECT * FROM STUDENT WHERE City = "Milan" AND Birthdate = "12/10/2000" ``` In this case, <u>both conditions must be true for a tuple to be included in the result</u>. If indexes support the predicates, the DBMS will choose the most selective predicate (the one that filters the most rows) for data access. The remaining predicates will be evaluated in **main memory**, which can improve performance by reducing the number of rows that need to be scanned from the disk. ```sql SELECT * FROM STUDENT WHERE City = "Milan" OR Birthdate = "12/10/2000" ``` For disjunction, <u>at least one of the conditions must be true for a tuple to be included in the result</u>. If all predicates have corresponding indexes, the DBMS can utilize the indexes for each condition, but this may require **duplicate elimination** to ensure that the same tuple is not included multiple times in the result set. If any of the predicates lack supporting indexes, a **full scan** of the relevant table must be performed, which can significantly impact performance. ![[2.3 - Introduction to Optimization-1754411348942.png]] ![[2.3 - Introduction to Optimization-1754411364614.png]] ## Join Methods **Join** operations are fundamental in relational databases, facilitating the combination of rows from multiple tables based on a common field, typically a primary or foreign key. Despite their necessity, <u>joins are often resource-intensive</u> and can impact database performance, especially when dealing with large datasets. Database management systems employ several join strategies, each tailored to different data characteristics and optimized for specific scenarios. The primary join methods include: - The **[[#nested-loop-join|Nested-Loop Join]]** is the simplest form of join operation, where **each row in the first table is compared with every row in the second table to find matching rows based on the join condition**. This approach is intuitive but can be computationally expensive for large datasets, as its time complexity is generally $O(n \times m)$, where $n$ and $m$ are the number of rows in each table. Therefore, <u>nested-loop joins are often more suitable for small tables or scenarios where more efficient indexing is not feasible</u>. - The **[[#merge-scan-join|Merge-Scan Join]]** offers a more efficient alternative when both tables are pre-sorted on the join key. This join strategy **sequentially scans each sorted table, merging rows based on the join condition**. The merge-scan join is highly efficient for equi-joins (joins where the relationship is based on equality) because it takes advantage of sorted data to avoid repetitive scans. Its time complexity is closer to $O(n + m)$, making it significantly faster than a nested-loop join for large datasets. However, <u>this method requires that both tables be sorted in advance</u>. - The **[[#hashed-join|Hashed Join]]** is commonly used for equi-joins and works by **building a hash table based on the join key for one of the tables**, typically the smaller one. **The second table is then scanned, and each row is checked against the hash table for matches**. This approach leverages the rapid lookup capabilities of hash tables, making it efficient and reducing the need for repeated scanning of rows. The hashed join is particularly advantageous when memory is sufficient to hold the hash table for the smaller dataset, as it minimizes disk I/O. Its time complexity approximates $O(n+m)$, like the merge-scan join, but with a more random access pattern rather than sequential. Selecting the optimal join method depends on several critical factors, which database administrators and query optimizers take into account to ensure efficient performance. - The **size of the tables** is a primary consideration, as smaller tables can often benefit from hashed joins, while larger, sorted datasets may align better with merge-scan joins. - The **availability of indexes** on join keys can also be a determining factor; indexed columns make nested-loop joins more feasible by reducing the number of rows that need to be scanned. - The **distribution of the data** (such as the uniqueness or duplication of values in join columns) influences performance, as highly unique keys can reduce the need for duplicate elimination and make certain join types more efficient. - Memory constraints are another consideration; the availability of **sufficient memory for hashing** can enable hashed joins, while limited memory might necessitate a nested-loop approach if indexing and sorting are unfeasible. `` > [!example]- > > > $$ > \begin{aligned} > \text{STUDENT}&(\underline{\text{ID}}, \text{Name}, \text{LastName}, \text{Email}, \text{City}, \text{Birthdate}, \text{Sex}) \\ > \text{EXAM}&(\underline{\text{SID}}, \underline{\text{CourseID}}, \text{Date}, \text{Grade}) > \end{aligned} > $$ > > The `STUDENT` Table contains a total of $150,000$ records (referred to as "tuples") with each tuple requiring about 95 bytes of storage. Here is a breakdown of the storage requirements for each field: > > - **ID**: 4 bytes > - **Name**: 20 bytes > - **LastName**: 20 bytes > - **Email**: 20 bytes > - **City**: 20 bytes > - **Birthdate**: 10 bytes > - **Sex**: 1 byte > > Given a block size of 8 KB (8192 bytes), we calculate the **Block Factor** to determine how many tuples can fit in one block. By dividing the block size by the tuple size, we find that each block can hold approximately 87 tuples: > $$ > \text{Block Factor} = \left\lfloor \frac{8192}{95} \right\rfloor = 87 \text{ tuples/block} > $$ > > Consequently, to store all 150,000 records, the **Total Blocks** required for the `STUDENT` table is calculated as follows: > $$ > b_{STUDENT} = \left\lceil \frac{150,000}{87} \right\rceil \approx 1,724 \text{ blocks} > $$ > > The `EXAM` Table, on the other hand, contains $1,800,000$ tuples, each requiring 24 bytes of storage, with the storage breakdown as follows: > > - **SID**: 4 bytes > - **CourseID**: 4 bytes > - **Date**: 12 bytes > - **Grade**: 4 bytes > > For this table, the Block Factor is calculated similarly, with each block capable of holding approximately 340 tuples: > $$ > \text{Block Factor} = \left\lfloor \frac{8192}{24} \right\rfloor = 340 \text{ tuples/block} > $$ > > This means the **Total Blocks** required for the `EXAM` table is: > $$ > b_{EXAM} = \left\lceil \frac{1,800,000}{340} \right\rceil \approx 5,294 \text{ blocks} > $$ > > ##### Equality Joins With One Join Column > > ```sql > SELECT * FROM STUDENT JOIN EXAM ON ID = SID > ``` > > In relational algebra, this join can be represented as: > > $$ Student \bowtie_{ID=SID} Exam $$ > > This equality join links the `ID` from the `STUDENT` table with the `SID` from the `EXAM` table. ### Nested-Loop Join A **nested-loop join** is one of the simplest and most intuitive methods for joining two tables in a database. It works by **scanning the external table and, for each block of that table, scanning the internal table to find matching tuples**. ![[2.3 - Introduction to Optimization-1753623744107.png]] It compares the tuples of a block of table $T_{ext}$ (the external table) with all tuples of a block of table $T_{int}$ (the internal table). The process continues until all blocks of the external table have been processed. We always assume that <u>the buffer does not have enough available free pages to host more than a few blocks of the internal table</u>, which is why it is referred to as a "nested-loop" join. > [!new-formula] Formula > > The cost of a nested-loop join is influenced by the number of blocks in both tables: > $$ \text{Cost} = b_{Ext} + b_{Ext} \times b_{Int} \approx b_{Ext} \times (1 + b_{Int}) \approx b_{Ext} \times b_{Int} $$ > where, $b_{Ext}$ is the number of blocks in the external table, and $b_{Int}$ is the number of blocks in the internal table. **Optimal Scenario**: If one of the tables is small enough to fit entirely in memory (buffer), it is chosen as the internal table: $$ \text{Cost} = b_{Ext} + b_{Int} $$ > [!example] > > In a simple nested-loop join, each row in one table is compared with every row in another table to identify matching entries based on a join condition. Here, the join operation is performed between two tables, `STUDENT` and `EXAM`, based on the `ID` in `STUDENT` matching the `SID` in `EXAM`. This join type, although straightforward, can be computationally expensive, especially as table sizes increase, due to the high number of I/O operations required. > > The `STUDENT` table occupies approximately $1,700$ blocks ($b_{STUDENT} = 1.7K$). The `EXAM` table is larger, occupying around $5,300$ blocks ($b_{EXAM} = 5.3K$). > > The join operation is represented by the following SQL query: > > ```sql > SELECT STUDENT.* FROM STUDENT JOIN EXAM ON ID = SID > ``` > > In a nested-loop join, the cost is calculated based on the number of I/O accesses required to perform the join. The cost depends on which table is designated as the "external" (outer) table and which as the "internal" (inner) table, as this affects the number of times each block needs to be read: > > 1. **When `STUDENT` is the external table**: Each block in `STUDENT` is read once, and for each block, the entire `EXAM` table is scanned to find matching rows. This results in a cost of: > $$ > \begin{aligned} > \text{Cost} &= b_{STUDENT} + b_{STUDENT} \times b_{EXAM} \\ > & = 1.7K + 1.7K \times 5.3K \\ & \approx 9 \text{ million I/O accesses} > \end{aligned} > $$ > > 3. **When `EXAM` is the external table**: In this case, each block in `EXAM` is read once, and for each block, the `STUDENT` table is scanned. This also results in: > $$ > \begin{aligned} > \text{Cost} &= b_{EXAM} + b_{EXAM} \times b_{STUDENT} \\ > & = 5.3K + 5.3K \times 1.7K \\ > & \approx 9 \text{ million I/O accesses} > \end{aligned} > $$ > > Regardless of which table is chosen as the external or internal, the cost remains approximately the same, totaling around 9 million I/O operations. This high number of accesses illustrates why nested-loop joins can be costly for large datasets and why alternative join methods (such as hashed joins or merge-scan joins) may be preferable when table sizes are substantial. #### Nested-Loop Joins with Caching **Caching** can significantly enhance the efficiency of nested-loop joins by storing the smaller table (the "internal" table) entirely in memory, reducing the need for repetitive disk I/O operations. This method is effective when the internal table is small enough to fit into cache, minimizing the need to read each block multiple times. > [!example] Example with Cached CITIES Table > > > Consider a scenario where a small table, `CITIES`, is used in a join operation with a larger table, `STUDENT`. > > $$ \text{CITIES}(\underline{\text{City}}, \text{Region}, \text{Description}) $$ > > The `CITIES` table is small, occupying only 10 blocks, making it suitable for caching (with a block size of 8KB, totaling 80KB). By storing `CITIES` in memory, each block in `STUDENT` can be scanned and joined with the cached blocks of `CITIES`, significantly lowering the total I/O cost. > > ```sql > SELECT STUDENT.* FROM STUDENT NATURAL JOIN CITIES > ``` > > 1. **Cache the CITIES Table**: All 10 blocks of `CITIES` are read into memory once, resulting in just 10 I/O accesses. > 2. **Scan the STUDENT Table**: With `CITIES` cached, only the `STUDENT` table’s blocks need to be scanned, totaling 1.7K I/O accesses. > > $$ > \text{TOTAL COST: } \qquad 10 + 1.7K \approx 1.7K \text{ I/O accesses} > $$ > Filters on join conditions can further optimize nested-loop joins by reducing the number of rows processed, though the approach varies based on where the filtering occurs. Below are two options for filtering: applying the condition to the `STUDENT` table or to the `EXAM` table, each with distinct cost implications. #### Filter the External Table First In this approach, we apply a filter to the `STUDENT` table to "*only include students located in Milan and having received a grade of 30*". This allows us to narrow down the `STUDENT` table before joining it with `EXAM`. ```sql SELECT STUDENT.* FROM STUDENT JOIN EXAM ON STUDENT.ID = EXAM.SID WHERE City = 'Milan' AND Grade = '30' ``` 1. **Scan `STUDENT` Blocks**: All 1.7K blocks in `STUDENT` must be read initially, totaling **$1.7K$ I/O accesses**. 2. **Filter Students by City**: With an average of 150 cities represented in `STUDENT`, we can estimate the filtered result for Milan to include around: \frac{150K \text{ total students}}{150 \text{ cities}} = 1K \text{ students}
\text{TOTAL COST: } \qquad 1.7K + 5.3M \approx 5.3M \text{ I/O accesses}
You can't use 'macro parameter character #' in math mode #### Filter the Internal Table First In this option, we start by filtering the `EXAM` table, selecting only the rows with a grade of 30. This initial reduction is beneficial if `EXAM` contains numerous grades. 1. **Scan `EXAM` Blocks**: First, we read all $5.3K$ blocks in `EXAM`, totaling **$5.3K$ I/O accesses**. 2. **Filter Exams by Grade**: Assuming $17$ possible grades in `EXAM`, we can estimate: \frac{1.8M \text{ total exams}}{17 \text{ grades}} \approx 106K \text{ exams with Grade = 30}
\text{TOTAL COST: } \qquad 5.3K + 180M \approx 180M \text{ I/O accesses}
You can't use 'macro parameter character #' in math mode #### Indexed Nested Loop Join In an **indexed nested loop join**, <u>one table can be accessed via an index based on the join predicate</u>. This method reduces the number of I/O operations by allowing direct access to matching tuples in the internal table without performing a full scan. The cost of an indexed nested loop join is significantly lower than that of a standard nested loop join, especially when one table has an index that supports the join condition. 1. **Selection of Internal Table**: If one table supports indexed access, it can be chosen as the internal table to exploit this indexing for quicker access to joining tuples. If both tables support lookups on the join predicate, the one with the more selective predicate is selected as internal. 2. **Cost Components**: The total cost is calculated as follows: $$ \text{Cost} = b_{Ext} + t_{Ext} \times \text{cost of one indexed access to } T_{Int} $$ Here, $b_{Ext}$ is the number of blocks in the external table, and $t_{Ext}$ is the number of tuples in the external table. Consider the following query: ```sql SELECT STUDENT.* FROM STUDENT JOIN EXAM ON STUDENT.ID = EXAM.SID WHERE City = 'Milan' AND Grade = '30' ``` - **Tables**: - `STUDENT`: $1.7K$ blocks, filtered for City. - `EXAM`: Indexed by SID, supporting indexed access. - $val(City)=150$ is the number of different cities in the database ![[2.3 - Introduction to Optimization-1753624456515.png|431x177]] Using a secondary hash index on `EXAM` allows for optimized access. - **Scan STUDENT**: $1.7K$ I/O accesses. - **Filtered Students**: $\frac{150K \text{ tuples}}{150 \text{ different cities}} = 1K$ students. - **Hash Index Access**: For each of the $1K$ students, access the hash index to find matching exams. Assume no overflow chains. - **Exam Access**: On average, for each student, there are $\frac{1.8M \text{ exams}}{150K \text{ students}} = 12$ exams to retrieve. $$\text{Total Cost} = \underbrace{1.7K}_{\text{student scan}} + \underbrace{1K}_{\text{hash index access}} + \underbrace{(1K \times 12)}_{\text{exam access}}= 14.7K$$ When the goal is to check the existence of matching tuples rather than retrieving all columns, the cost can be further reduced: ```sql SELECT STUDENT.* FROM STUDENT JOIN EXAM ON STUDENT.ID = EXAM.SID WHERE City = 'Milan' ``` - **Scan `STUDENT`**: $1.7K$ I/O accesses. - **Filtered Students**: Again, results in $1K$ students. - **Hash Index Access**: For each student, access the hash index to check existence. - Total lookups required are only $1$ access per student. $$ \text{Total Cost} = 1.7K + 1K \times 1 = 1.7K + 1K = 2.7K $$ ### Merge-Scan Join A **merge-scan join** is an efficient way to <u>join two tables that are already sorted on the join attribute</u>. This method requires both tables to be ordered according to the same key attribute, which is also used in the join predicate. ![[2.3 - Introduction to Optimization-1753624676954.png]] > [!steps] > > 1. **Prerequisite**: Both tables must be sorted on the join key. > 2. **Execution**: > - Scan both tables simultaneously. > - Compare the current values of both tables: > - Advance in the table with the lesser value. > - If values match, output the tuple pair `<l, r>`. > 3. **Output**: The result will include all combinations of matching tuples from the two tables. The cost is linear in the size of the tables: $$ C = b_L + b_R $$ where $b_L$ and $b_R$ are the number of blocks in the left and right tables, respectively. If a table needs to be sorted, we need to also add the cost of the sorting operation: - **Ordered Full Scan**: This is possible if the primary storage is sequentially ordered with respect to the join attribute or if a [[2.2 - Indexes|B+ tree]] index on the join attribute is defined. - **Sorting Cost**: If tables need to be sorted prior to the merge, add the cost for sorting: $$ 2b_L \times (\text{\# of passes}) + 2b_R \times (\text{\# of passes}) $$ where the number of passes can be calculated as: $\text{\# of passes} = 1 + \lceil \log_{B-1} \lceil N/B \rceil \rceil$ with $N$ being the number of blocks and $B$ being the number of buffer pages. > [!example] Example: Merge-Scan Join on Ordered Tables > > > ```sql > SELECT STUDENT.* FROM STUDENT JOIN EXAM ON ID = SID > ``` > > ##### Case 1: Both Tables Sequentially Ordered > > - `STUDENT`: Sequentially ordered by ID. > - `EXAM`: Sequentially ordered by SID. > $$ C = b_{STUDENT} + b_{EXAM} = 1.7K + 5.3K = 7K \text{ I/Os} $$ > > ##### Case 2: STUDENT Ordered, EXAM with Primary B+ Index > > - `STUDENT`: Sequentially ordered by ID. > - `EXAM`: Primary storage with a B+ tree on SID. > $$ C = b_{STUDENT} + (\text{\# Intermediate Nodes}) + (\text{\# Leaf Nodes in EXAM}) $$ > Assuming 3 intermediate nodes and $8K$ leaf nodes: > $$ C = 1.7K + 3 + 8K \approx 9.7K \text{ I/Os} $$ > > ##### Case 3: STUDENT Ordered, EXAM with Secondary B+ Index > > - `STUDENT`: Sequentially ordered by ID. > - `EXAM`: Secondary index on SID. > > $$ C = b_{STUDENT} + (\text{\# Intermediate Nodes}) + (\text{\# Leaf Nodes in EXAM}) $$ > > Assuming 3 intermediate nodes and $4K$ leaf nodes: > > $$ C = 1.7K + 3 + 4K \approx 5.7K \text{ I/Os} $$ > #### Indexed Merge Scan Join When additional filtering is applied, such as selecting specific grades, the cost can significantly increase. ```sql SELECT S.SID FROM STUDENT S JOIN EXAM E ON ID = SID WHERE GRADE > 17 ``` - `STUDENT`: Sequentially ordered by ID. - `EXAM`: Secondary index on SID. - Cost: The cost of accessing both the intermediate nodes and leaf nodes, plus the number of tuples in `EXAM`: $$ C = b_{STUDENT} + (\text{\# Intermediate Nodes}) + (\text{\# Leaf Nodes in EXAM}) + (\text{\# Tuples in EXAM}) $$ Assuming: - $b_{STUDENT} = 1.7K$ - $3$ intermediate nodes - $4K$ leaf nodes - $1.8M$ tuples in EXAM $$ C \approx 1.7K + 3 + 4K + 1.8M \approx 1.8M \text{ I/Os} $$ ### Hashed Join A **hashed join** is an efficient method for <u>joining two tables based on a common attribute, particularly when both tables are hashed on the join key</u>. This method can significantly reduce the search space for matching tuples, as they can only be found in corresponding buckets. ![[2.3 - Introduction to Optimization-1753624991194.png]] > [!steps] > > 1. **Hashing**: Both tables are hashed on the join attribute, which creates a number of buckets. Each bucket will contain tuples that hash to the same value for the join attribute. > 2. **Bucket Matching**: During the join operation, only the buckets with matching hash values are examined, allowing for quick identification of matching tuples. > 3. **Output**: The result consists of the combinations of matching tuples from both tables. The cost of a hashed join is linear with respect to the number of blocks in the hash-based structure. If both tables are primary storage (i.e., the hashed structure is stored as part of the primary storage), the cost can be calculated as: $$ C = b_L + b_R $$ where: - $b_L$ = number of blocks in the left table. - $b_R$ = number of blocks in the right table. > [!NOTE] > > > - **Buckets**: While both hashed tables will have the same number of buckets, the actual number of blocks ($b_L$ and $b_R$) may differ slightly due to overflow handling. Overflows occur when multiple tuples hash to the same bucket and the bucket becomes full. > - **Efficiency**: The hashed join is particularly efficient for large datasets when the hash function evenly distributes tuples across the buckets, minimizing the number of comparisons needed. > [!example] Example of Hashed Join > > > Consider the following SQL query that joins the `STUDENT` table and the `EXAM` table on the condition where `ID` from `STUDENT` matches `SID` from `EXAM`: > > ```sql > SELECT S.* FROM STUDENT S JOIN EXAM E ON S.ID = E.SID > ``` > To analyze the cost of this hashed join, we need to consider the number of blocks for each table: > > - The `STUDENT` table consists of approximately $1.7K$ blocks ($b_{STUDENT} = 1.7K$). > - The `EXAM` table consists of about $5.3K$ blocks ($b_{EXAM} = 5.3K$). > > The steps for the hashed join are as follows: > > 1. **Building the Hash Table**: First, the hash table is created for the smaller table, which in this case is the `STUDENT` table. This requires reading all $1.7K$ blocks of `STUDENT` into memory. > > 2. **Probing the Hash Table**: Next, each block of the `EXAM` table is scanned to find matching entries in the hash table. This requires reading all $5.3K$ blocks of `EXAM`. > > The total cost of the hashed join can thus be calculated as: > > $$ > C = b_{STUDENT} + b_{EXAM} = 1.7K + 5.3K = 7K \text{ I/Os} > $$ > The hashed join method is notably more efficient than nested-loop joins, especially when dealing with large datasets. In this scenario, the **total I/O cost of $7K$** is significantly lower than what would be encountered with a nested-loop join, demonstrating the effectiveness of hashing for reducing the number of required I/O operations during the join process. ![[2.3 - Introduction to Optimization-1754412036326.png]] ![[2.3 - Introduction to Optimization-1754412047995.png]] ## Sorting in Databases **Sorting** is essential in databases for organizing and quickly retrieving data based on specific attributes. Efficient sorting algorithms can improve query performance, index maintenance, and data processing in relational database systems. There are two primary methods for sorting, depending on the size of the data: 1. **In-Memory Sorting**: For data that fits into main memory, algorithms like [quicksort](https://it.wikipedia.org/wiki/Quicksort) and [merge sort](https://it.wikipedia.org/wiki/Merge_sort) are typically used. These algorithms offer fast sorting for smaller datasets, allowing the entire data to be processed in-memory without repeated disk access. 2. **External Sorting**: For larger datasets that cannot fit into memory, **external sorting** becomes necessary. This approach involves reading, sorting, and merging blocks of data in chunks that fit into memory. The most common method for this type is **[external merge sort](https://en.wikipedia.org/wiki/External_sorting)**, which efficiently handles large files by sorting manageable chunks and then merging them into a fully sorted sequence. ### External Merge Sort **External merge sort** is structured to handle files that exceed memory capacity by processing and merging data in multiple passes. Each pass involves reading data into memory in blocks, sorting it, and writing it back in a way that each subsequent pass combines larger and larger sorted sequences until the entire dataset is sorted. > [!algorithm] > > 1. **Initial Pass**: > - In this pass, blocks of data are read into memory, sorted, and then written to temporary files, often called chunk files. This initial sorting creates smaller sorted chunks, each representing a portion of the data. > - **Calculation of Chunks**: If $N$ represents the total number of blocks and $B$ is the number of blocks that fit into memory, the number of sorted chunks created can be calculated as: > $$ > \text{Total Chunks} = \left\lceil \frac{N}{B} \right\rceil > $$ > - **Cost for Initial Pass**: This pass requires reading and writing each block once, resulting in a cost of $2N$ I/O operations (one read and one write per block). > ![[2.3 - Introduction to Optimization-1753625077911.png]] > > 2. **Subsequent Passes: > - In each subsequent pass, the algorithm uses `B-1` blocks for reading sorted chunks and one block for writing the merged output. > - During each pass, the smallest record among the sorted chunks is selected and written to the output. Once the output buffer is full, it is written to disk. > - This process continues until all chunks have been merged into a single, fully sorted file. > ![[2.3 - Introduction to Optimization-1753625116464.png]] > [!example] Example of External Merge Sort > > > Suppose we have `N = 40` blocks to sort and can only fit `B = 5` blocks into memory at a time. > > 3. **Initial Pass**: > - We read $5$ blocks at a time, sort them, and write each sorted chunk to disk. > - Total I/O cost: $40$ reads + $40$ writes. > - Outcome: $8$ sorted chunks, each containing $5$ pages. > > 4. **Subsequent Passes**: > - **Pass 2**: We load $4$ chunks (using $4$ blocks) into memory, merge them, and produce a new chunk of $20$ pages. > - **Pass 3**: The final pass merges two $20$-page chunks into a single sorted chunk of $40$ pages. > > **Total Passes**: $3$ > **The total cost of external merge sort depends on the number of passes required**. For a given dataset of $N$ blocks and a memory buffer size of $B$, the number of passes can be calculated as: \text{Number of Passes} = 1 + \left\lceil \log_{B-1} \left\lceil \frac{N}{B} \right\rceil \right\rceil
\text{Total Cost} = 2N \times \text{(Number of Passes)}
You can't use 'macro parameter character #' in math mode This table shows the number of passes required to sort datasets of varying sizes ($N$) with different memory buffer sizes ($B$): | N | B=3 | B=5 | B=9 | B=17 | B=129 | B=257 | | :------------ | --- | --- | --- | ---- | ----- | ----- | | 100 | 7 | 4 | 3 | 2 | 1 | 1 | | 1,000 | 10 | 5 | 4 | 3 | 2 | 2 | | 10,000 | 13 | 7 | 5 | 4 | 2 | 2 | | 100,000 | 17 | 9 | 6 | 5 | 3 | 3 | | 1,000,000 | 20 | 10 | 7 | 5 | 3 | 3 | | 10,000,000 | 23 | 12 | 8 | 6 | 4 | 3 | | 100,000,000 | 26 | 14 | 9 | 7 | 4 | 4 | | 1,000,000,000 | 30 | 15 | 10 | 8 | 5 | 4 | ## Cost-Based Optimization in Databases Cost-based optimization is a critical aspect of database query processing that focuses on determining the most efficient way to execute a query. This involves analyzing various execution plans and selecting the one with the lowest estimated cost. 1. **Decision Variables**: - **Data Access Operations**: Deciding whether to use a full table scan or index access. - **Order of Operations**: Determining the sequence in which operations are performed, such as the order of joins. - **Method Selection for Operations**: Choosing the best join method (e.g., nested-loop, hash join). - **Parallelism and Pipelining**: Leveraging parallel execution and pipelining to enhance performance. 2. **Optimization Approach**: - **[[8 - Project Management|Cost Estimation]]**: Using profiles and approximate cost formulas to assess the cost of different execution strategies. - **Decision Trees**: Constructing a decision tree where: - Each node represents a choice in the query execution. - Each leaf node corresponds to a specific execution plan. ![[Pasted image 20241012124418.png | This image illustrates a decision tree for query optimization, showing various nodes corresponding to different choices and leaf nodes representing specific execution plans.]] 3. **Cost Calculation**: The total cost of a query plan can be represented as: $$ C_{\text{total}} = (C_{I/O}\cdot n_{I/O}) + (C_{\text{cpu}} \cdot n_{\text{cpu}}) $$ Here, $C_I/O$ represents the cost of I/O operations, $C_{\text{cpu}}$ represents the CPU cost per operation, and $n_{\text{cpu}}$ is the number of CPU operations involved. 4. **Plan Selection**: Optimizers utilize operations research techniques, such as **branch and bound**, to efficiently explore the decision tree and identify the plan with the lowest estimated cost. The goal is to obtain a "good" execution plan quickly. ## Query Execution Query execution is the process of executing a SQL query against a database to retrieve or manipulate data. The execution process can vary based on the database management system (DBMS) and the specific query being executed. Here are two common approaches to query execution: 1. **Compile and Store**: In this approach, the query is compiled once and stored for subsequent executions (known as a **prepared statement**). The DBMS retains the compiled internal code and tracks dependencies on specific catalog versions used during compilation. If relevant changes occur in the catalog, the compilation is invalidated, and the query must be recompiled. 2. **Compile and Go**: This method involves immediate execution of the query without storing the compiled code. Although not stored, the code may remain in memory temporarily and be available for other executions during that period. ### Prepared Statements (MySQL) **Prepared statements** are a feature in many relational database management systems (RDBMS) that allow for the pre-compilation of SQL queries. This approach enhances performance and security by separating query structure from data, enabling the reuse of execution plans and preventing SQL injection attacks. - **Performance**: Prepared statements can be executed multiple times with different parameters without the need for re-parsing and re-compiling the SQL statement, leading to faster execution. - **Security**: By using placeholders for parameters, prepared statements help prevent SQL injection attacks, as user input is treated as data rather than executable code. Prepared statements are typically used in applications where <u>the same query is executed multiple times with different parameters</u>, such as in web applications or data processing tasks. ```sql PREPARE my_query1 FROM 'SELECT * FROM users WHERE id = ?'; ``` The query is prepared with a placeholder (`?`) for the parameter. When executing the prepared statement, the actual value is bound to the placeholder: ```shell EXECUTE my_query1 USING 54; EXECUTE my_query1 USING 2; ``` During query execution, one of the most critical aspects of performance optimization involves the **buffer pool**, which acts as a memory-resident cache for database pages. > [!definition] > > A **page** is the fundamental unit of data storage and transfer between disk and memory, typically containing a fixed-size block of data such as table rows, index nodes, or even compiled execution plans, depending on the DBMS architecture. When a query is issued, the DBMS attempts to retrieve the necessary pages from the buffer pool before resorting to disk access. If a requested page is **already present** in the buffer pool, this results in what is known as a **cache hit**. Cache hits significantly improve performance by eliminating the need to perform time-consuming disk I/O operations. On the other hand, if the requested page is **not in memory**, a **cache miss** occurs, forcing the system to read the page from disk and load it into the buffer pool, which is considerably slower. The types of data stored in the buffer pool are diverse. Primarily, it contains **data pages** that hold the actual tuples (rows) of database tables. In addition to data pages, the buffer pool often includes **index pages**, which facilitate efficient data retrieval by allowing the DBMS to quickly locate rows based on indexed attributes. Some database systems also store **compiled execution plans** in the buffer pool, enabling the reuse of previously optimized query strategies without re-parsing and re-optimizing the same statements. Since the buffer pool operates within a limited memory space, it cannot accommodate all pages indefinitely. As a result, the DBMS must implement a **page replacement policy** to determine which pages should be evicted when new pages need to be loaded. A common strategy employed is the **Least Recently Used (LRU)** algorithm or one of its variants. This policy assumes that pages that have not been accessed recently are less likely to be accessed again in the near future. Thus, when the buffer pool reaches its capacity, the DBMS discards the pages that have remained unused for the longest time, freeing space for new, potentially more relevant data. We can also deallocate the prepared statement when it is no longer needed: ```shell DEALLOCATE PREPARE my_query1; ``` <div class="page-break" style="page-break-before: always;"></div>