Compilation often involves the application of translation functions that cannot be accomplished purely through syntactic means. These functions require operations that go beyond simple symbolic manipulation and involve computations or mappings that are not inherently expressible using basic automata or syntactic frameworks.
For instance, traditional automata such as finite-state or pushdown I/O automata, which rely on a single input and output tape, and more advanced devices like free transduction grammars or syntactic transduction schemes, are insufficient for these tasks.
To understand this concept, consider the following examples of translation challenges encountered during compilation:
Base Conversion of Fractional Numbers: Translating a fractional number in fixed-point notation from one base, such as binary (base 2), to another base, such as decimal (base 10), is a task that involves arithmetic computations. This translation cannot be handled by purely syntactic systems as it requires numerical calculations.
Memory Address Assignment in Complex Data Structures: Another critical translation task involves converting a complex data structure, such as a record or struct, into its corresponding memory representation. This includes assigning a unique memory address to each element within the data structure, such as fields in a record or struct.
Example: Symbol Table Construction for a Record
Consider a record definition in Pascal syntax:
BOOK: record AUTHOR: array [1..8] of char; TITLE: array [1..20] of char; PRICE: real; QUANTITY: integer;end;
The compilation process for this record involves creating a symbol table that maps each field of the record to its respective type, size, and memory address. For the BOOK record example, the symbol table might look as follows:
Symbol
Type
Size (in bytes)
Address (in bytes)
BOOK
record
34
3401
AUTHOR
string
8
3401
TITLE
string
20
3409
PRICE
real
4
3428
QUANTITY
integer
2
3432
Here, the translation process involves arithmetic computations to determine the memory addresses of each field. For example, the address of TITLE is calculated by adding the size of AUTHOR to the starting address of BOOK, and similar calculations are performed for the other fields. This step requires more than a syntactic transduction; it necessitates the use of arithmetic functions that operate on the sizes and alignments of the fields.
Syntax-Driven Transducer
A syntax-driven transducer is a computational device that operates on the structure of a syntax tree to compute variables or semantic attributes associated with each node. These attributes encapsulate the semantics of the syntactic phrases from the source code, effectively translating the syntax into its intended functionality or representation.
The attributes in a syntax-driven transducer serve two main purposes:
They provide a semantic interpretation of the source phrase by associating specific values with nodes of the syntax tree.
They facilitate the translation of the source code into a target representation, such as machine instructions or higher-level semantic models.
Attribute grammars combine syntactic rules with semantic functions that compute attribute values. However, they are not purely formal models because the procedures used to compute the attributes are essentially programs, which can be informal or vary across implementations. Despite this limitation, attribute grammars are widely adopted in compiler design due to their systematic and coherent approach. They help developers avoid inefficient or incorrect design decisions by organizing the translation process in a structured manner.
Two-Pass Compilation Model
In a two-pass compilation approach, the process can be broken into two distinct stages:
Parsing or Syntax Analysis: The compiler analyzes the source code to construct an abstract syntax tree (AST), capturing the syntactic structure of the program.
Evaluation or Semantic Analysis: The compiler decorates the syntax tree by computing attribute values, thereby creating a decorated syntax tree. This tree represents both the syntax and semantics of the program.
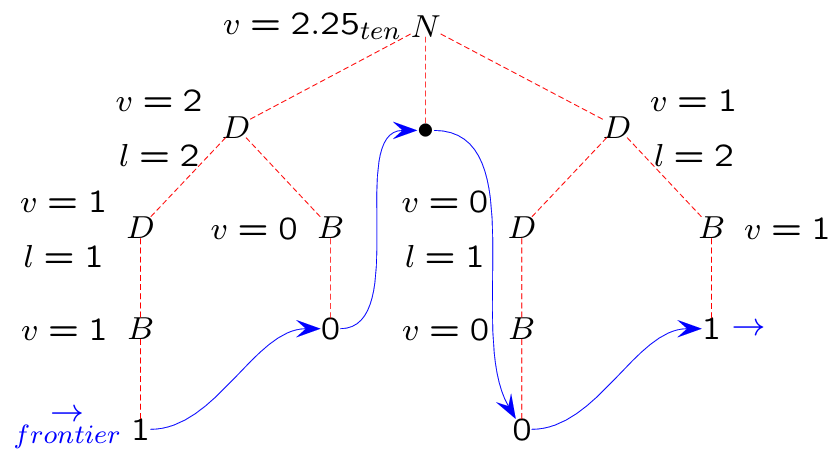
Example: Base Conversion Using Attribute Grammars
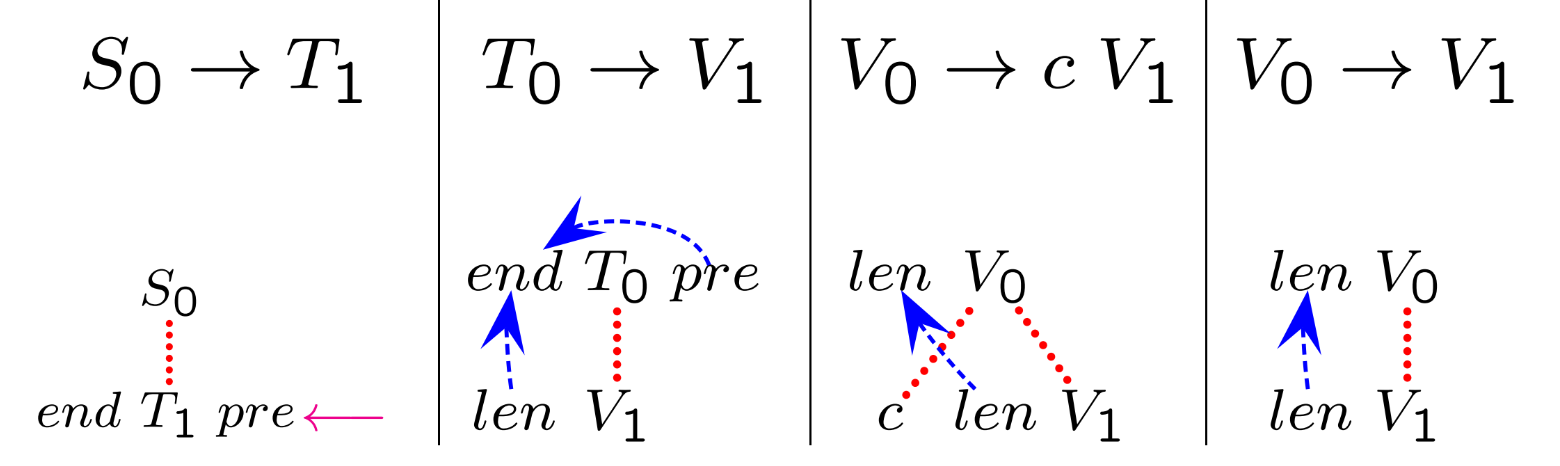
To illustrate the role of a syntax-driven transducer, consider the problem of converting a binary number with fractional parts into a decimal number. The source language is defined over the alphabet , where the bullet separates the integer and fractional parts. For instance, the binary number translates into the decimal number .
An attribute grammar for this task consists of syntactic production rules paired with semantic functions:
Syntax Rule
Semantic Function
Here, the semantic functions compute attributes like the value and length , which are associated with the syntactic components of the number.
Attributes provide semantic meaning for the syntax tree nodes. For the base conversion example:
(value) represents the fixed-point numerical value of the node ().
(length) represents the length of the digit sequence ().
Semantic Function Application and Decorated Syntax Trees
The semantic functions are applied to the nodes of the syntax tree, starting from the terminal nodes (leaves) where the attributes can be directly computed. These computations propagate upwards to decorate the entire tree with semantic values. The decorated syntax tree represents both the syntax of the source string and its translated meaning.
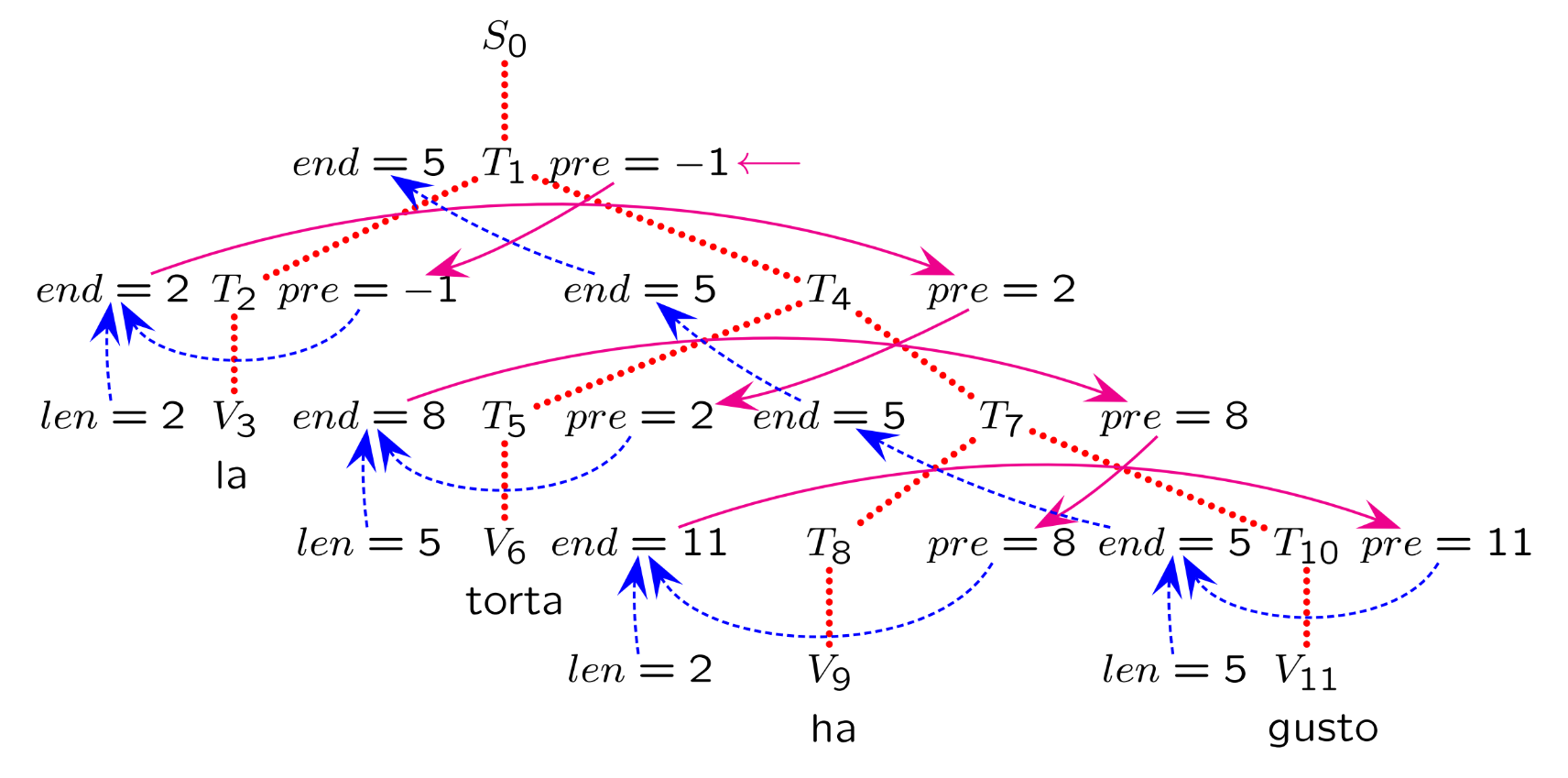
For example, converting into :
The integer part evaluates to using the semantic rules for and .
The fractional part evaluates to using similar rules, incorporating the positional weight .
Combining these results yields .
Attributes in syntax-driven translation are categorized as:
Synthesized Attributes: Computed from the child nodes and associated with the parent node. For example, is synthesized for in .
Inherited Attributes: Passed down from the parent to the child nodes. In more complex scenarios, these guide the computation by propagating contextual information downward. However, in the base conversion example, all attributes are synthesized.
Significance in Compiler Design
The use of attribute grammars and syntax-driven transducers highlights the interplay between syntax and semantics in compiler construction. By systematically associating computations with syntactic rules, they enable compilers to perform complex translations, such as arithmetic evaluations or memory address assignments, in a structured and efficient manner. This methodology underpins the practical success of compilers in managing diverse and intricate programming languages.
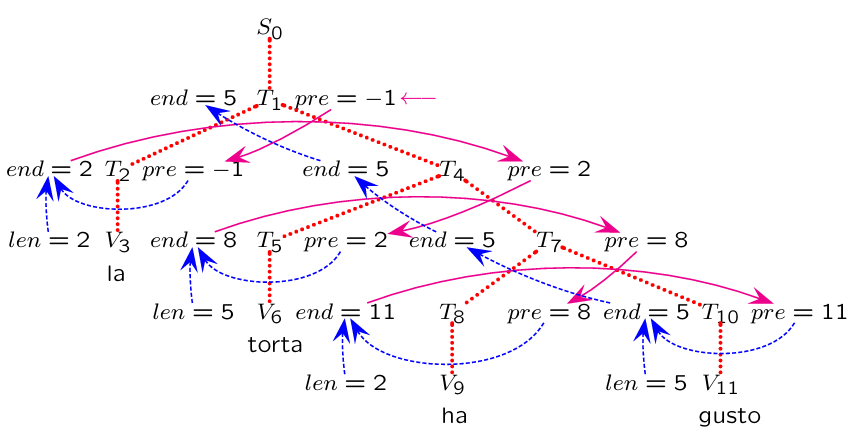
Example: Text Justification within Line Length Limit
The problem of justifying a piece of unformatted natural language text involves ensuring that lines of text contain as many unsplit words as possible while respecting a maximum line length, . Words are separated by blanks (), and terminal symbols represent characters (). Hyphenation or word-splitting is not considered.
Input Text: A sequence of words represented as characters separated by (blanks).
Output Text: Lines formatted such that:
Each line has a length characters.
Words are not split across lines.
Blanks are minimized, and every line ends with as many words as fit within .
Example Input:
Phrase: “la torta ha gusto ma la grappa ha forza”
English Equivalent: “the pie has taste but the brandy has strength”
Line Width Limit:
Correctly Justified Text:
| Column | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|--------|------|------|------|------|------|------|------|------|------|------|------|------|
| Line 1 | l | a | | t | o | r | t | a | | h | a | | |
| Line 2 | g | u | s | t | o | | m | a | | l | a | | |
| Line 3 | g | r | a | p | p | a | | h | a | | | | |
| Line 4 | f | o | r | z | a | | | | | | | | |
The semantic attributes involved are:
: The length of the current word (measured in characters). This is a left attribute.
: The column number of the last character of the previous word. This is a right attribute.
: The column number of the last character of the current word. This is a left attribute.
The value of for a word is computed as:
Where:
- is the column position of the last character of the preceding word.
- is the length of the current word.
- accounts for the blank separating the words.
Grammar and Semantic Rules
The grammar and associated semantic rules are as follows:
Syntax Rule
Right Attributes
Left Attributes
Computation process:
Initialization:
, to ensure no leading blank before the first word.
Recursive Attribute Computation:
Slide through the words in the text and compute for each word using and .
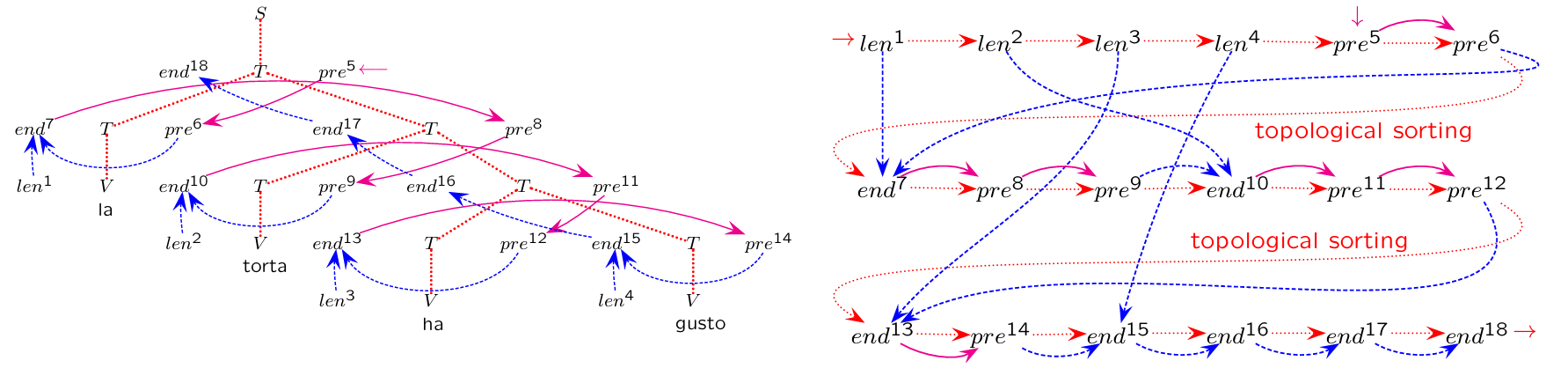
The graph is acyclic, ensuring that attribute evaluation can proceed in a single pass over the syntax tree, provided all dependencies are resolved.
Notational conventions for drawing the graph:
Dashed edges: Syntactic relations
Solid arcs: Computation of
Dashed arcs: Computation of
Place right attributes () and left attributes (, ) on the right and left sides of the corresponding tree node, respectively. The dependence graph is loop-free (acyclic).
Any computation order that satisfies all dependencies allows determining the values of the attributes. If the grammar satisfies certain conditions (to be explained later), the results do not depend on the computation order of the semantic functions.
Definition of Attribute Grammar
Steps
Let be a BNF syntax, where:
and are the nonterminal and terminal alphabets, respectively.
is the rule set.
is the axiom.
The axiom is not referenced in the rule right parts.
The axiomatic rule is unique (normal form).
Define a set of semantic attributes associated with nonterminal and terminal symbols:
The attributes associated with a nonterminal symbol are denoted by (Greek letters) and are grouped in the subset .
The set of all attributes is divided into two disjoint subsets: left (or synthesized) attributes, e.g., , and right (or inherited) attributes, e.g., or .
For each attribute (be it left or right), specify a domain, i.e., a finite or infinite set of possible values. An attribute can be associated with one, two, or more (non)terminal symbols. If attribute is associated with symbol , write with a subscript .
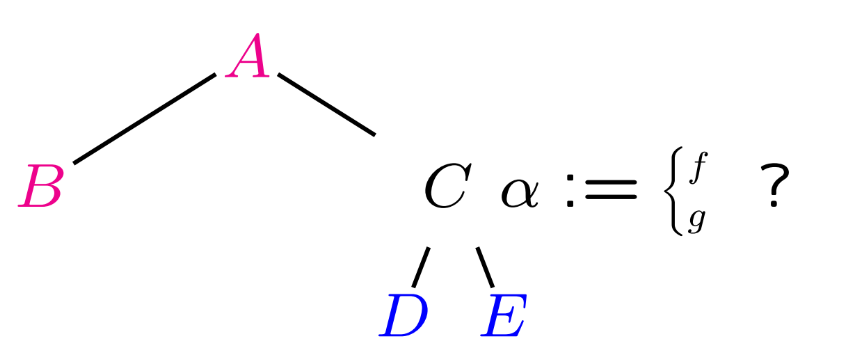
Define a set of semantic functions (or semantic rules). Each semantic function is associated with a support syntax rule : . Two or more semantic functions may share the same syntactic support rule. The set of all functions associated with a given support rule is denoted as (may be empty).
A generic semantic function, as follows: where , assigns a value to attribute ( of ) by means of an expression . The operands of expression are attributes associated with the same syntax rule (not another one), except for the expression value itself (). Semantic functions must be total.
Semantic functions are denoted by means of a suited semantic metalanguage:
Often it is a programming language of common use, e.g., C or Pascal.
Sometimes it is a pseudo-code, i.e., an informal specification.
Or it may even be a standard software specification language, e.g., XML and others.
Models of semantic functions for computing left and right attributes of rule , respectively:
defines a left attribute, associated with the parent node .
() defines a right attribute, associated with a child node .
An attribute associated with a terminal symbol:
Is always of the right (inherited) type.
Is often directly assigned a constant value during lexical analysis, i.e., before semantic analysis. A semantic function may be used.
And commonly is directly assigned the terminal symbol it is associated with.
The elements of the set of the semantic functions that share the same support rule must satisfy the following conditions:
For every left attribute it holds:
If there exists one, and only one, defining semantic function: .
If there does not exist any defining semantic function: .
For every right attribute it holds:
If there exists one, and only one, defining semantic function: .
If there does not exist any defining semantic function: .
Conclusion: If is left, never have (). If is right, never have .
It is permitted to initialize some attributes with constant values or with values computed initially by means of external functions. Indeed, this is the case for the attributes (always of the right type) that are associated with the terminal symbols of the grammar.
An attribute cannot be defined as both left and right within the same syntax, as this would lead to conflicting assignments.
Example
For example:
Support
Semantic Function
1:
Right attribute
2:
Left attribute
A semantic function must not use an attribute that is external to its supporting rule. For instance, modifying rule 2 from the previous text instrumentation example results in:
Syntax Rule
Semantic Function
Note
1:
…
2:
is a non-local attribute
3: …
…
Here, the attribute is associated only with nonterminal , which does not appear in rule 2. This breaks the locality condition and causes confusion in attribute association.
Construction of the Semantic Evaluator
A semantic evaluator is derived from an attribute grammar. This grammar defines the translation of syntactic constructs into semantic information but does not prescribe a specific order for computing attributes. The computation order must be deduced from the dependencies between attributes, either automatically by a tool or manually by the designer. The evaluator’s design must respect the functional relationships that exist between attributes in the grammar.
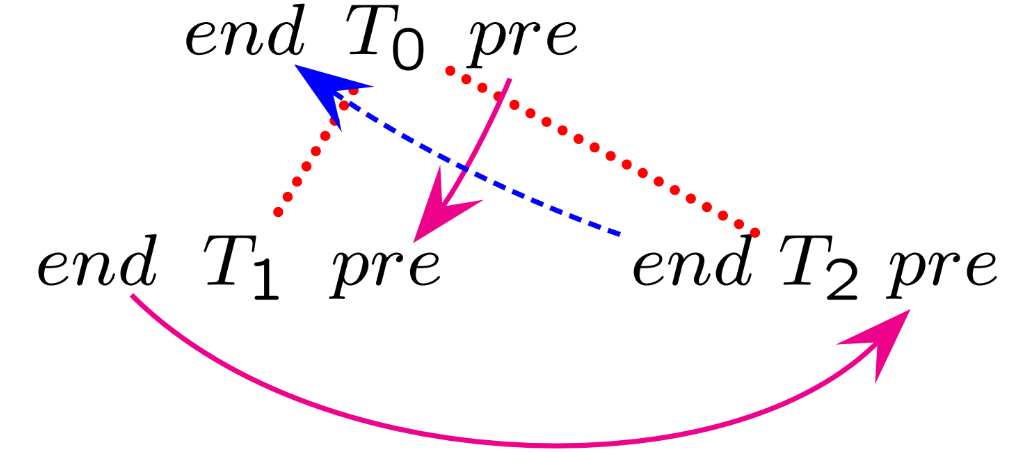
To understand and organize the evaluation of attributes, a dependence graph is constructed. This graph represents the flow of information and dependencies between attributes within a given semantic function. The dependence graph is both directed and wrapped around the syntax tree of the supporting grammar rule. Each node in the graph corresponds to a terminal or nonterminal symbol in the rule, while arcs represent the computational dependencies between attributes.
Attributes are visually grouped around the syntax tree:
Left (synthesized) attributes are displayed on the left of the corresponding symbol node and propagate upwards in the tree.
Right (inherited) attributes are shown on the right of the node and flow downwards or laterally within the tree structure.
The arcs in the dependence graph connect the arguments of a semantic function to its computed result.
Example
For example, in the syntax rule:
The graph would show:
An upward arrow from to (synthesized attribute dependency).
A downward arrow from to (inherited attribute dependency).
A lateral or downward arrow from to (mixed dependency).
In this example, the terminal symbol is omitted for brevity, as it does not participate in semantic evaluations.
Dependency Categories and Analysis
Attributes in the dependence graph can be categorized as internal or external to the current syntax rule:
Internal attributes: These are fully defined and resolved within the scope of the current rule. Their values depend only on computations in the rule itself.
External attributes: These depend on information from other rules or parts of the syntax tree. They require additional semantic context or evaluation beyond the current rule.
For a complete understanding, the syntax tree is decorated with the dependence graph. This combined representation illustrates the relationships between all attributes and their roles in propagating semantic information.
Evaluating the Semantic Functions
The evaluation process must respect the dependencies indicated by the graph. For this:
Cyclic Dependencies: The graph must be acyclic to ensure that attribute computation terminates correctly. Cycles in the graph indicate conflicting or circular dependencies, which need to be resolved by redesigning the semantic functions.
Evaluation Order: The evaluator determines the sequence of computations such that all dependencies of an attribute are satisfied before its value is computed. This is typically achieved through techniques like topological sorting of the dependence graph.
Existence and Uniqueness of Solutions in Attribute Grammars
For an attribute grammar, the existence of a valid solution (an assignment of values to attributes) depends on the absence of cyclic dependencies within its dependence graph. If the dependence graph for a given syntax tree is loop-free (i.e., acyclic), there is guaranteed to be a unique assignment of values that satisfies all semantic rules. This ensures that attributes are consistently and correctly evaluated.
An attribute grammar itself is considered acyclic if every possible syntax tree derived from it has a loop-free dependence graph. This property is crucial for guaranteeing that the evaluation process can be executed deterministically without conflicts or ambiguities.
To confirm the loop-free nature of a dependence graph and establish the order in which attributes should be evaluated, topological sorting of the graph is employed. Topological sorting arranges the nodes (attributes) in a linear sequence such that every dependency is resolved before the dependent attribute is evaluated.
Algorithm for Topological Sorting
The topological sorting algorithm works on a directed, loop-free graph , where:
represents the nodes (attributes) in the graph.
represents the directed edges, which correspond to dependencies between attributes.
The algorithm produces: a linear ordering of the nodes, represented as a vector , where each element gives the position of the node labeled by index in the sorted sequence.
This sorted order ensures that the computation of each attribute is scheduled after all its dependencies have been resolved.
Example
For example:
Begin with nodes that have no incoming arcs (attributes with no dependencies).
Process each node by removing its outgoing arcs and adding it to the sorted order.
Repeat until all nodes are processed. If a cycle is detected during this process, the graph is not acyclic, and evaluation order cannot be established.
Checking for Acyclicity in Attribute Grammars
A general decision algorithm exists to verify if an attribute grammar is loop-free for all possible syntax trees. However, this algorithm is NP-complete, meaning its computational complexity grows exponentially with the size of the grammar. Consequently, it is infeasible for large grammars to apply this decision process directly.
Instead, practical solutions rely on sufficient conditions that guarantee acyclicity by construction. These conditions guide the design of attribute grammars and their corresponding dependence graphs to ensure that no loops are introduced during attribute assignment. By adhering to these conditions:
Dependence loops are avoided by definition.
The evaluator can rely on topological sorting to compute attributes without the risk of cyclic dependencies.