Given a grammar , a syntax analyzer or parser is responsible for verifying whether a given input string belongs to the language generated by . This analysis is crucial for checking the syntactic structure of code or natural language input in systems like compilers and interpreters. The parser typically performs the following tasks:
Steps
Reads a source string: It processes the input string to determine if it conforms to the rules of the grammar.
Identifies derivations or syntax trees: If the string belongs to , the parser either produces a derivation (sequence of grammar rule applications) or constructs a syntax tree representing the structure of the string.
Error detection: If the string does not belong to , the parser halts and provides an error message, often with diagnostic information to help identify the issue.
When the source string is ambiguous, meaning it has multiple valid interpretations, the parser generates a forest of syntax trees or a set of derivations, representing each possible interpretation.
Bottom-Up and Top-Down Analysis
In syntax analysis, two primary approaches are employed based on the order of derivation reconstruction and traversal of the syntax tree:
Rightmost Derivation in Reverse Order: This approach reconstructs the derivation starting with the rightmost derivation but processes it in the reverse order.
Tree Traversal from Leaves to Root: In bottom-up analysis, the syntax tree is constructed from the leaves (terminals) up to the root (axiom), achieved by reducing substrings (matches for rule right-hand sides) to their corresponding nonterminals.
Leftmost Derivation in Direct Order: In this approach, the parser follows a leftmost derivation in the natural (direct) order.
Tree Traversal from Root to Leaves: Top-down analysis expands the syntax tree from the root to the leaves by expanding nonterminals into their right-hand sides, continuing until all nonterminals are resolved into terminals that match the input string.
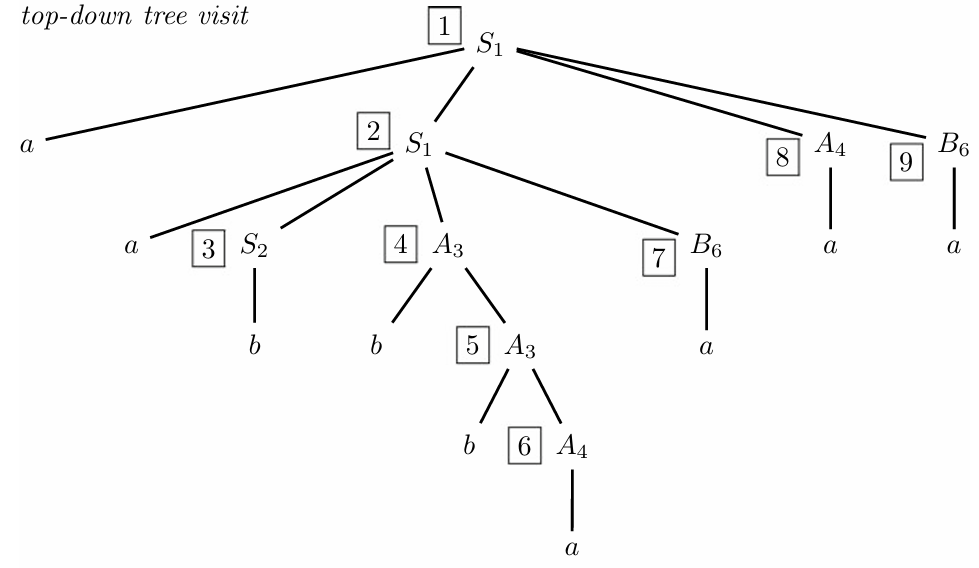
Example of Top-Down Analysis
Consider the phrase . The top-down analysis expands rules based on the grammar provided:
The process begins at the root and applies rules to expand to match the input string. For instance, starting with , further expansions follow until the nonterminals match the input.
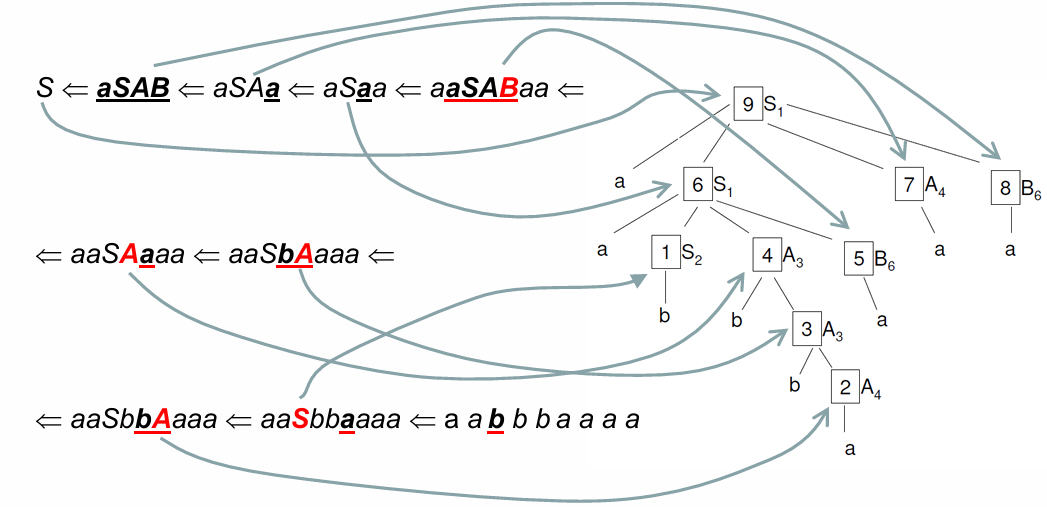
Example of Bottom-Up Analysis
Using the same phrase , a bottom-up parser would start by recognizing and reducing specific sequences from the input according to the grammar rules until it reaches the axiom . For instance begin with recognizing and its derivations in a reverse manner:
Bottom-up parsing emphasizes rightmost derivation in reverse order, incrementally reducing the string to the axiom by applying rules to replace sequences of terminals and nonterminals with higher-level nonterminals, ultimately yielding the axiom if the input string is valid.
Grammar as a Network of Finite State Automata
When a grammar is in Extended Backus-Naur Form (EBNF), each nonterminal is defined by a single production rule , where is a regular expression composed of terminals and nonterminals. This structure allows each rule to be recognized by a finite automaton. Specifically, the expression generates a regular language, meaning there exists a corresponding finite automaton capable of recognizing the strings that generates.
In this framework, a transition in the automaton labeled by a nonterminal indicates a “call” to the finite automaton . If , this would signify a recursive call within the automaton itself.
Definition
Terminal and Nonterminal Alphabets:
Terminal alphabet: , the set of terminal symbols (e.g., actual symbols in the input language).
Nonterminal alphabet: , representing the set of nonterminal symbols in .
Grammar Rules and Regular Languages:
Each nonterminal (e.g., ) is associated with a rule (e.g., ), where , , , etc., define regular languages over the combined alphabet .
Correspondingly, each nonterminal has an associated deterministic finite automaton (DFA) , etc., each recognizing its specific rule-based language (e.g., ).
Machine Network: is the collective set of all DFAs representing the grammar’s nonterminals, functioning as a cohesive network of machines.
Assuming all state names across the machines are unique, each machine associated with a nonterminal has:
: The set of states in ,
: The initial state of ,
: The final state(s) of ,
: The regular language accepted by starting from state .
The final language generated by is context-free in general, given by:
This can be written as when the context is clear. For the start state in machine , this final language is denoted .
To simplify the structure, an additional constraint can be applied: the initial state of any machine should not be re-entered once the computation has started. If a machine does have a transition leading back to , the issue can be resolved by introducing a new initial state, which may cause the machine to have one non-minimal state, but still maintain functional correctness.
graph LR
qa((QA)) -- C --> 0A((0A))
Automata that satisfy this condition are known as normalized automata or automata with a non-reentering initial state.
It is permissible for to also be a final state, which is necessarily the case if .
Examples
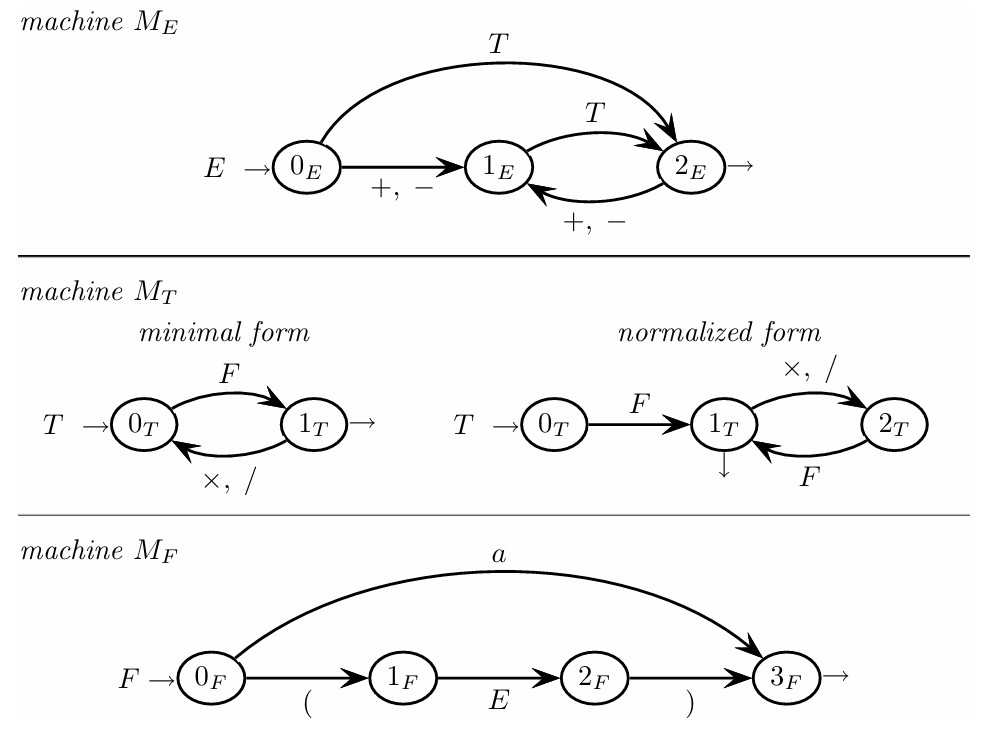
Arithmetic Expressions: Consider the following grammar for arithmetic expressions:
Each rule here represents a deterministic finite automaton (DFA) that can recognize arithmetic expressions with addition, subtraction, multiplication, and division.
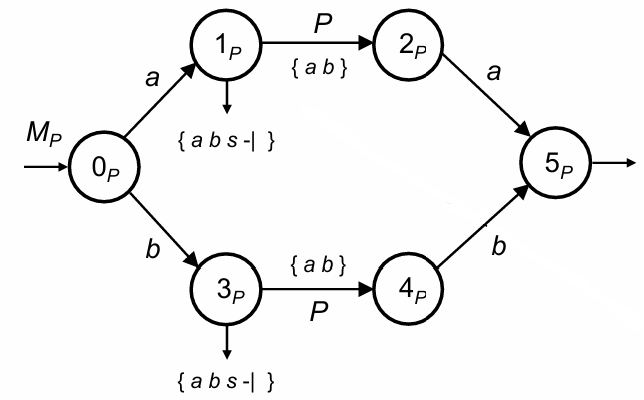
List of Palindromes of Odd Length Separated by “s”: A grammar for such a language could be structured as:
In this case, each rule corresponds to a DFA recognizing the palindromic pattern with each representing an odd-length palindrome.
graph
subgraph 1[Ms]
s[start1] --> 0s((0s)) -- P --> 1s(((1s))) -- s --> 2s((2s)) -- P --> 1s
end
subgraph 2[Mp]
s1[start2] --> 0p((0p)) -- a --> 1p(((1p))) -- P --> 2p((2p)) -- a --> 5p(((5p)))
0p -- b --> 3p(((3p))) -- P --> 4p((4p)) -- a --> 5p
end
Top-Down Analysis via Recursive Procedures
Top-down analysis can be efficiently performed using recursive procedures, especially when the structure of the grammar allows for straightforward decision-making based on the current input symbol. Recursive procedures provide a simple and elegant way to model the parsing process: the code structure mirrors the transitions of the finite automaton corresponding to the grammar.
Example: Arithmetic Expressions
Consider the following grammar for arithmetic expressions:
This grammar defines expressions with addition and multiplication and uses recursive calls for each grammar rule. The procedures for parsing each nonterminal , , and directly correspond to the transitions in the finite automaton that recognizes arithmetic expressions.
procedure E: call T while(cc == '+'): cc = next call T end if (cc in {'$', ')'}): // End of input or closing parenthesis return else: errorend Eprocedure T: call F while(cc == '*'): cc = next call F end if (cc in {'$', ')', '+'}): return else: errorend Tprocedure F: if (cc == 'a'): // Recognizing a terminal symbol 'a' cc = next elif (cc == '('): cc = next call E if (cc == ')'): cc = next else: error else: errorend F
In this example:
Each procedure checks the current character (e.g., cc).
E calls T and continues if the next character is +, forming a loop.
F recognizes atomic expressions: either the terminal symbol a or a subexpression enclosed in parentheses.
Top-down analysis is feasible as long as guide sets (the sets of symbols that dictate which production rule to apply) are disjoint. If two productions starting from the same nonterminal share overlapping guide sets, the parser cannot uniquely decide which rule to apply based on the current symbol. For example, consider:
This grammar defines a language , where nonterminals and require examining the lookahead symbols for guidance. With overlapping guide sets (both rules in can start with ), top-down parsing is challenging without further modifications, like lookahead or backtracking.
procedure S: if (cc == 'a'): call N cc = nextend S
Example: List of Palindromes with Odd Lengths Separated by "s"
For a language of palindromes of odd length separated by “s”, the grammar could be:
In this case, the non-determinism inherent in the structure makes top-down parsing difficult, as each palindrome in can start with either or , but the procedure lacks a way to disambiguate effectively by only looking at the current character.
procedure P: if (cc == 'a'): cc = next if (cc in {'a', 'b'}): call P return elif (cc == 'b'): cc = next if (cc in {'a', 'b'}): call P return else: errorend P
In this case, the recursive procedure cannot always predict the correct path by observing the next character alone. Consequently, top-down parsing is inadequate here due to the non-deterministic nature of the language.