Before the adoption of microservices, most software applications were built using a monolithic architectural style. In a monolithic system, all the components of the application—such as the user interface, business logic, and database access logic—are tightly coupled together into a single deployable unit. This single unit, known as a software artifact, is then deployed onto an application server. This approach is straightforward and typically works well for smaller-scale applications. However, as the application grows in complexity and scale, the monolithic architecture begins to face challenges.
Monolithic systems often become difficult to manage and scale over time due to their tightly coupled nature. Any change made to one part of the application might require redeploying the entire system, which increases the risk of introducing bugs and slows down development and deployment cycles. Additionally, scaling monolithic applications to handle increasing demand is not always straightforward, as it requires scaling the entire application, even if only a specific part of it needs additional resources.
The microservice architectural style, in contrast, emerged as a solution to these challenges.
Quote
The microservice architectural style involves developing an application as a suite of small, independent services.
Martin Fowler
Each service runs in its own process and typically communicates with other services through lightweight mechanisms, such as HTTP-based APIs. Unlike the monolithic approach, microservices are designed to be loosely coupled, meaning that changes or updates to one service can often be made independently of others, allowing for greater flexibility and agility in development and deployment.
Microservices are often organized around a concept known as a “bounded context.” In the context of software development, a bounded context refers to a specific domain or area of responsibility within the application. Each microservice is typically designed to handle a specific concern or function within the system, such as managing user authentication, processing payments, or handling inventory. By dividing the application into smaller, specialized services, each service can focus on a single responsibility, leading to improved maintainability, scalability, and fault tolerance.
The shift from monolithic to microservice architectures was adopted by several large-scale companies, such as Netflix, Amazon, eBay, and Spotify, between 2010 and 2016. These companies transitioned from monolithic systems to microservices in order to improve both their development processes and the products they offered. The primary goal of this transition was to support massive scaling needs. For example, companies like Netflix and Amazon handle millions of users and require a system architecture that can scale easily, accommodate frequent changes, and ensure high availability. Microservices allow organizations to scale individual services as needed, rather than scaling an entire monolithic application, resulting in more efficient resource usage and better performance.
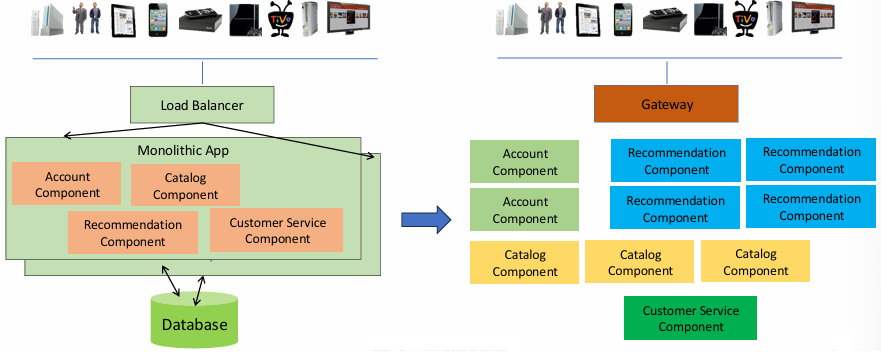
Advantages of Microservices (Product)
One of the primary benefits of adopting a microservices architecture is the ability to implement fine-grained scaling strategies. In a monolithic system, scaling is often all-or-nothing. That is, to accommodate increased demand, the entire system must be replicated as a whole, regardless of which components require more resources. Microservices, on the other hand, allow for selective replication, meaning only the services that need additional capacity can be scaled independently. This flexibility ensures that resources are used more efficiently and enables more precise management of system performance.
In addition to scaling benefits, microservices also reduce the impact of localized issues. In a monolithic system, a problem in one part of the application can potentially bring down the entire system. Microservices are designed with isolation in mind, so if one service fails, the others can continue to operate, possibly with degraded functionality until the issue is resolved. This architecture improves the system’s overall resilience and helps to ensure that service disruptions are more contained and less disruptive to users.
Example
A notable example of the advantages of microservices in terms of resilience comes from Netflix’s experience. Before transitioning to microservices in 2008, Netflix faced a major issue where a single minor syntax error in the codebase brought down the entire platform for hours. After migrating to microservices, issues like this became less impactful, as the failure of one service would not necessarily cause a complete outage.
Microservices also enhance system flexibility in terms of reuse and composability. Since microservices are designed around specific, often domain-driven functions (such as user authentication or payment processing), the same microservice can be reused across different parts of the application or even in different applications entirely. This encourages modularity and allows organizations to avoid reinventing the wheel for each new feature. Furthermore, microservices can be combined in various ways to create different workflows or features, leading to highly customizable systems that can be adjusted to meet specific business needs.
Advantages of Microservices (Process)
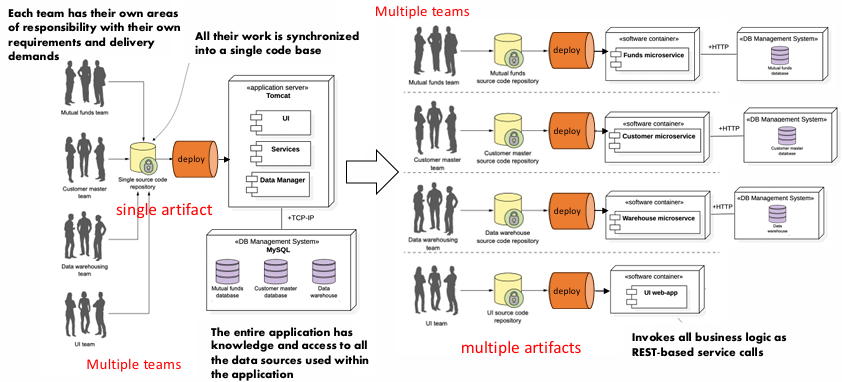
From a process perspective, microservices bring several improvements, particularly in terms of team organization and productivity. Since each microservice is typically owned by a small, dedicated development team, the synchronization overhead is significantly reduced. In a monolithic system, larger teams are often required to coordinate changes across the entire application, which can lead to delays and miscommunications. With microservices, each team has well-defined responsibilities for specific services, enabling faster development cycles and clearer accountability.
Another advantage is the decoupling of teams from underlying technical implementations. Since communication between microservices is always done through technology-neutral protocols (e.g., REST APIs), the internal implementation details of a service do not affect how other services interact with it. This allows teams to select the best technologies and programming languages for their specific needs. For instance, a team working on data analysis might choose a language and framework optimized for data processing, while a team focused on video streaming might opt for technologies best suited for handling large media files.
Microservices also enable teams to experiment with new technologies without disrupting the entire system. Since each microservice is independent, a team can introduce new tools or frameworks within a single service without affecting other parts of the application. This fosters innovation and allows organizations to stay up to date with the latest advancements in technology.
Additionally, the smaller, focused nature of microservices makes the codebase more manageable. As microservices are typically smaller in scope than monolithic applications, they are easier to debug and maintain. This leads to cheaper and faster maintenance, as teams can focus on specific issues within individual services rather than dealing with the complexity of a large, tightly coupled system.
Anatomy of a Microservice
A microservice is typically composed of three main elements that together enable it to provide independent and scalable functionality within a larger application architecture. These elements are the REST API, the application (or business) logic, and data storage.
-
REST API At the heart of every microservice is a REST API that defines the core operations of the service. REST APIs are designed to be lightweight and follow standard HTTP methods, or “verbs,” such as
GET,POST,PUT, andDELETE. These methods correspond to typical operations on resources like retrieving, creating, updating, or deleting data. The API allows external clients to interact with the microservice by sending requests and receiving responses. To facilitate communication, data is serialized in formats like JSON, which is commonly used because it is both human-readable and easy to parse by machines. The REST API ensures that interactions between services are standardized, providing a clear contract for how the service should behave. -
Application (or Business) Logic The application logic refers to the actual implementation of the core operations within the microservice. This is the part of the service that processes incoming requests, performs necessary computations or validations, and executes the required functionality. For instance, in an e-commerce application, the business logic in a “Payment” microservice might involve verifying payment details, processing a transaction, and updating inventory levels. The business logic is what gives the microservice its value and ensures that it performs the right actions when it is called upon.
-
Data Storage Each microservice typically has its own dedicated data storage, often in the form of a local database. Unlike monolithic systems where a central, shared database is used, microservices avoid global databases to reduce dependencies between services. Instead, each microservice owns and manages its own data, which enables greater flexibility and decoupling of services. This localized data approach supports the microservice principle of autonomy, ensuring that changes or failures in one service do not impact others.
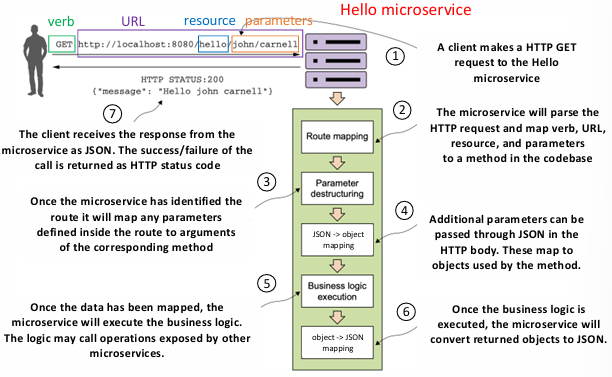
To understand how these components work together in practice, let’s explore a common workflow for processing a REST API request:
- Client Makes HTTP Request: The process begins when a client makes an HTTP request to a microservice, such as a GET request to retrieve information from the “Hello” microservice.
- Request Parsing and Mapping: The microservice receives the HTTP request and parses it, extracting the HTTP verb (GET), the URL, the resource, and any parameters.
- Route Identification and Method Mapping: The microservice maps the URL and HTTP verb to a specific route in its codebase, identifying the appropriate method that corresponds to the request.
- Parameter Handling: Any parameters in the URL (such as a user ID) are mapped to the corresponding arguments of the method. If additional parameters are sent in the body of the request (often in JSON format), these are parsed and mapped to objects that the method will use.
- Execution of Business Logic: After the data has been parsed and mapped, the microservice executes its business logic. The logic may involve operations that require interacting with other microservices (e.g., calling a payment service or fetching data from a user service).
- Return Data Conversion: Once the business logic has been executed, the microservice converts any returned objects or data into JSON format for easy transmission.
- Response to Client: The client receives the response in JSON format, along with an HTTP status code indicating the success or failure of the request (e.g., 200 for success, 404 for not found, etc.).
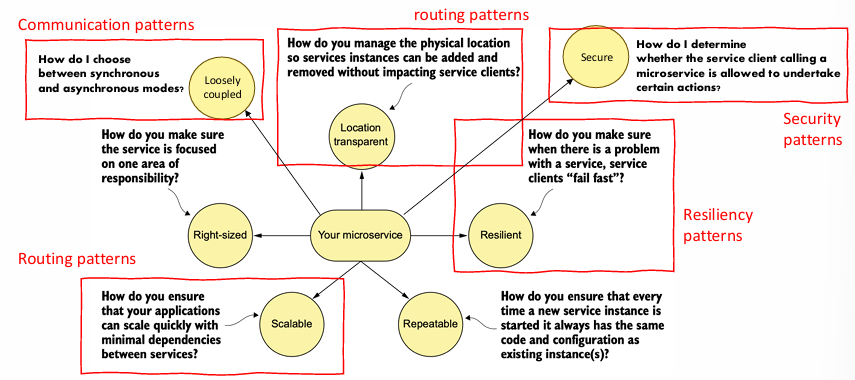
While the core of a microservice is its business logic, there are other important considerations and functionalities that ensure it operates effectively within a larger system. Microservices may need to handle tasks such as authentication, logging, error handling, and security, which extend beyond just executing business logic. These auxiliary functions are often handled by additional services or components integrated into the microservice architecture, allowing the core service to focus on its specific functionality while other concerns are managed separately.
Routing Patterns
In a microservices architecture, the dynamic nature of services requires sophisticated routing mechanisms to ensure that requests are directed to the correct instances. One key characteristic of such systems is that the execution environment has shared, non-pre-allocated resources. This means that the physical location of a running service is potentially unknown, as services can be distributed across a large number of servers or nodes. Therefore, microservices rely on service discovery mechanisms to dynamically locate and route requests to the appropriate service instances.
Service Discovery Requirements
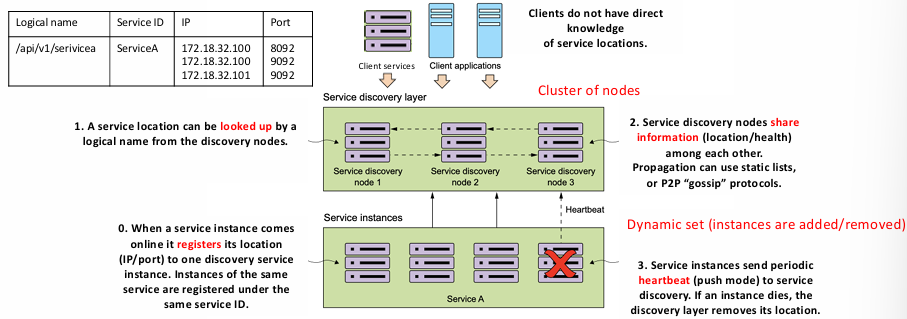
To function effectively, service discovery must meet several critical requirements:
- High Availability: Service discovery should be designed with high availability in mind. Since the discovery service is responsible for helping clients locate available service instances, it cannot become a single point of failure. To achieve this, a cluster of service discovery nodes is typically deployed. If one node becomes unavailable, the others can take over seamlessly.
- Load Balancing: To optimize performance and ensure that no single service instance becomes overwhelmed with requests, service invocations need to be load balanced. This means requests are spread across all available instances of the service, helping to maintain even distribution of traffic and avoid overloading any one instance.
- Resilience: Service discovery systems must be resilient. If the discovery service becomes temporarily unavailable (for example, due to network issues), the system should be able to continue functioning. Clients should still be able to locate services using fallback mechanisms, ensuring that service failures do not completely disrupt the application.
- Fault Tolerance: The service discovery system should be fault-tolerant, meaning it must continuously monitor the health of service instances. If a service instance becomes unhealthy or fails, the discovery system must automatically remove it from the list of available services without requiring human intervention, ensuring that clients are not directed to failed instances.
Service Discovery Architecture
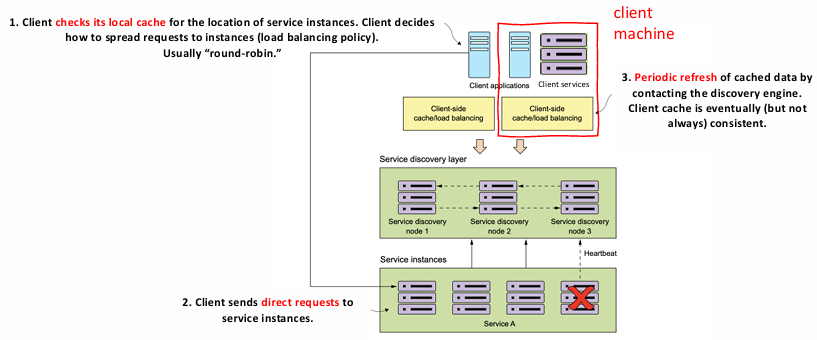
Service discovery involves a few key steps to ensure that services are discovered and requests are routed appropriately:
- Service Registration: When a service instance comes online, it registers its location (typically its IP address and port) with a discovery service. Multiple instances of the same service are registered under the same service identifier. This ensures that clients can discover all available instances of a service.
- Service Lookup: Clients can then look up the location of a service instance by querying the discovery service. The lookup is usually done using a logical service name (such as
user-serviceorpayment-service), abstracting the physical locations of individual instances. - Information Sharing: The service discovery nodes share information about the registered services, such as their locations and health status, among themselves. This information is propagated using various methods, including static lists or more dynamic protocols like peer-to-peer “gossip” mechanisms. This helps maintain up-to-date and consistent information across the discovery nodes.
- Heartbeat Mechanism: To maintain up-to-date information, service instances periodically send heartbeat signals (in push mode) to the service discovery system. If a service instance fails and stops sending heartbeats, the discovery layer will automatically remove the service instance’s location from the list, ensuring that requests are not routed to a dead instance.
To improve performance and reduce the load on the discovery service, microservices often employ client-side caching and local load balancing:
- Local Cache Lookup: When a client needs to access a service, it first checks its local cache for the location of available service instances. The client then decides how to distribute requests across these instances, typically using a load balancing policy like round-robin or more sophisticated algorithms (e.g., weighted round-robin or least connections).
- Direct Requests: Once the client has identified one or more service instances, it sends direct HTTP requests to those instances, bypassing the discovery layer for each call.
- Cache Refresh: The client periodically refreshes its cache by querying the discovery engine for the latest service instance locations. This ensures that the client has up-to-date information, although it is important to note that the cache may not always be perfectly consistent, especially in distributed systems with high service churn.
While client-side caching and service discovery offer many advantages, there are some potential issues that arise:
- Cache Inconsistency: One of the main challenges with client-side caching is that it does not ensure real-time consistency of cached data. For example, if a service instance goes down or is removed from the discovery service but the cache is not updated immediately, clients may still try to communicate with the now-unavailable instance.
- Cache Invalidation: To handle this, clients may be programmed to detect when they contact a dead instance. Upon such an event, the client can invalidate its local cache and trigger a refresh by contacting the service discovery engine. While this helps to mitigate issues with stale data, it can add overhead and reduce the benefits of caching.
- Eventual Consistency: The cache may be eventually consistent, meaning that changes to service availability (such as a new instance coming online or a failed instance being removed) might not be reflected immediately in the client’s local cache. This introduces potential lag in service discovery and increases the complexity of managing distributed systems.
Resiliency Patterns
Resiliency is a key characteristic of robust microservices architectures, ensuring that services can handle failures gracefully without impacting the overall system. One of the central challenges in microservices is how to deal with problems in remote services. Specifically, how can clients ensure that they avoid calling a service that is experiencing issues, while waiting for it to recover?
In a traditional monolithic system, a failure might have been contained within a single process, but in microservices, the failure of one service can quickly propagate, potentially affecting a whole chain of services. In addition to the obvious failure scenarios, there are also more subtle issues that can affect system performance, such as temporary errors or performance degradation in remote resources.
Success
The goal of resiliency patterns in microservices is to allow clients to fail fast, meaning that when a problem occurs, the system should immediately stop trying to perform the operation that’s likely to fail.
This helps avoid wasting resources on calls that are unlikely to succeed and can prevent cascading failures, or ripple effects, that could affect other services in the system.
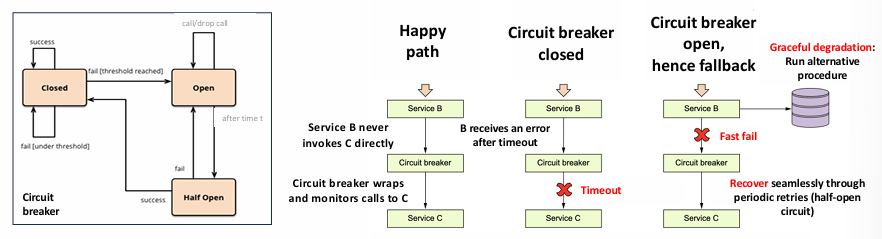
Circuit Breaker (CB) Pattern
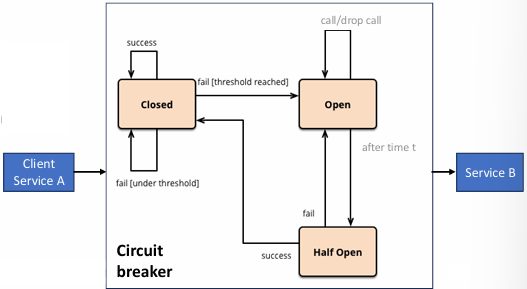
The circuit breaker (CB) is a common resiliency pattern implemented on the client side to handle failures in remote services. It acts as a proxy for a remote service and is designed to monitor the calls to that service. If it detects a failure or performance issue, it prevents further calls to the service and allows time for the problem to be addressed.
When a remote service is called, the circuit breaker monitors the call to determine if it succeeds or fails. It watches for specific types of issues:
- Error Responses (5xx errors): If the service responds with an error indicating a problem on the server side (e.g., 500 Internal Server Error), the circuit breaker marks the service as faulty.
- Timeouts or Slow Responses: If a request takes too long, the circuit breaker can cancel the call before it fully completes, assuming the service is either temporarily overwhelmed or unresponsive.
The circuit breaker has a threshold for the number of failures it can tolerate in a given time window. If this threshold is exceeded (i.e., if there are too many failures), the circuit breaker “opens,” preventing further calls to the service for a defined period. During this time, the client will not try to reach the failing service and can either use a fallback mechanism, return a predefined error response, or trigger an alternative process. After the timeout period, the circuit breaker “closes” again, and service calls are attempted once more.
Example: Circuit Breaker in Action
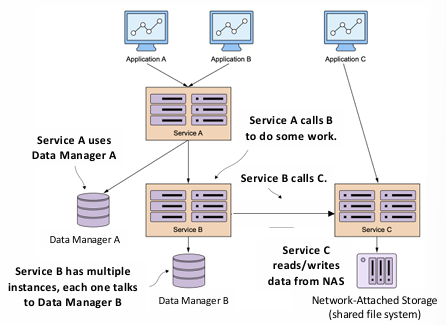
Imagine a scenario where, during the night, operators change the configuration of a NAS system. The following day, requests to a particular disk subsystem become extremely slow. The developers of Service
, which communicates with Service (which is responsible for managing data on the disk subsystem), did not anticipate that these slowdowns would cause problems.
In this scenario, Service
writes data to Data Manager and retrieves data from Service within the same transaction. However, due to the slowdowns at Service , the requests to Service take much longer than expected, causing a bottleneck. As requests pile up, several issues arise:
- Ripple Effects: Service
is waiting on responses from Service , leading to a backlog of requests. This results in an increasing number of concurrent database connections, leading to resource exhaustion. - Excessive Load: Service
, in turn, becomes slow because it’s waiting on Service , which is unresponsive. This exacerbates the problem, as Service now starts calling Service and faces similar delays. Without any safeguards, this slow propagation of failures can result in resource exhaustion and performance degradation across the entire system.
How to Prevent the Problem
By introducing a circuit breaker between Service
and Service , the system can prevent this cascade of failures. If Service becomes slow or starts throwing errors, the circuit breaker will open after it detects a number of failed calls (e.g., timeouts or 5xx errors). When the circuit breaker opens, Service will no longer attempt to call Service , thus protecting the rest of the system from becoming overwhelmed.
Instead of continuing to wait for slow or failing responses from Service
, Service might either:
- Return an immediate error response to the client, informing them that the service is temporarily unavailable.
- Trigger a fallback mechanism, such as using cached data or a default response, to maintain partial functionality while Service
recovers. In this way, the circuit breaker helps maintain system stability by isolating failures and preventing them from cascading throughout the architecture. It also ensures that resources are not consumed by calls that are unlikely to succeed, thus improving overall system efficiency and resilience.
Security Patterns
In microservices architectures, security is often a cross-cutting concern, meaning that it affects multiple layers of the system and must be handled in a way that doesn’t compromise the flexibility or scalability of the individual services. Key security concerns include authentication, authorization, data protection, and logging. To address these concerns effectively, various security patterns are employed to ensure that services remain secure while being accessible in a distributed system.
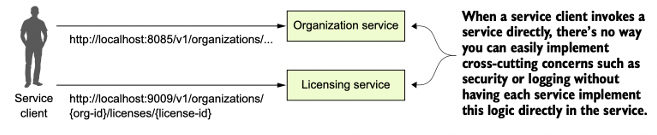
The Service (or API) Gateway Pattern
One of the most common security patterns in microservices is the use of a service gateway (also known as an API gateway). This component acts as a mediator between service clients (such as external users or other services) and the services being invoked. All client requests go through the gateway, which then forwards the requests to the appropriate service. This centralization of requests allows the service gateway to handle a number of important tasks, including security, logging, and traffic management.
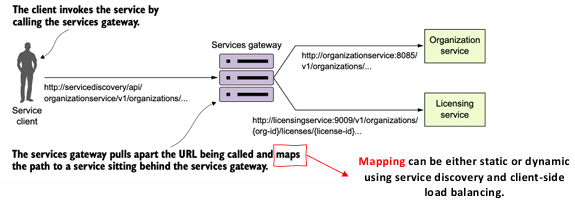
- Client-Only Communication with the Gateway: Clients talk only to the service gateway, which abstracts the individual services and their complexities. This simplifies the client-side interaction by consolidating many responsibilities (such as routing, load balancing, and security) into a single entry point.
- Gatekeeper Role: The service gateway acts as the gatekeeper for all traffic to the microservices, enabling the implementation of centralized security mechanisms like authentication and authorization. For example, the gateway can authenticate incoming requests and ensure that they are authorized to access the requested resources before forwarding them to the relevant service.
- Service Discovery and Load Balancing: The gateway can also use service discovery to dynamically route requests to the appropriate instances of microservices. Additionally, it can employ client-side load balancing to distribute requests evenly across available service instances.
However, the service gateway can also be a potential single point of failure in the system. If it goes down or becomes overloaded, it could prevent clients from accessing services altogether. To mitigate this risk, the gateway is typically deployed with multiple instances, and a server-side load balancer is used to distribute requests across the available instances. This ensures high availability and fault tolerance.
Authentication and Authorization with OAuth2
In microservices, authentication and authorization mechanisms must be designed to ensure that only legitimate users or systems can access protected resources. One of the most widely used and effective methods for implementing these security measures is OAuth2, a token-based security protocol used by many modern applications, including popular platforms like Facebook and GitHub.
OAuth2 operates as a framework that defines several roles and components to manage secure access to resources:
- Protected Resource: The microservices or resources that you want to protect and ensure are only accessible by authenticated users. For example, data stored within a microservice might need to be secured from unauthorized access.
- Resource Owner: The entity that owns or controls access to the protected resources. This could be an individual user who grants permission for applications to access their data or perform certain actions on their behalf.
- Application (Client): The application that will access the protected resources on behalf of a user. It needs to authenticate with the OAuth2 system to obtain an access token that can be used to make requests to the services.
- OAuth2 Authentication Server: This server is responsible for authenticating the user, typically by validating their credentials (such as username and password) and issuing a token. The authentication server acts as an intermediary between the application and the services being consumed, allowing users to authenticate once and obtain tokens that can be used to access multiple microservices, without needing to share their credentials with each service.
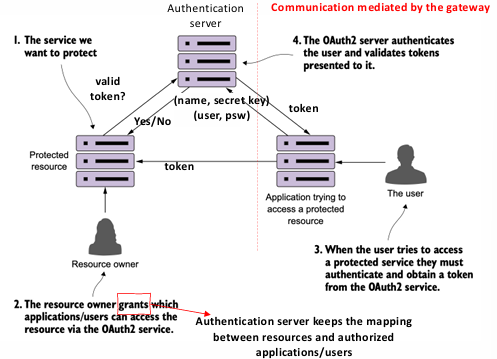
The OAuth2 process follows a series of steps to authenticate users and authorize access to protected resources:
- Token Issuance: The user provides their credentials to the OAuth2 authentication server, which authenticates the user. Once the user is authenticated, the server issues an access token. This token represents the user’s identity and permissions and is used for subsequent requests to access resources.
- Accessing Protected Resources: Once the application has received the token, it can use it to make authorized requests to the microservices. Each request includes the token, which the service gateway or individual microservices will verify to ensure that the caller is authorized to access the requested resource.
- Token Propagation: In cases where a microservice needs to call other microservices as part of its operation (nested calls), it can propagate the original token in its own requests. This ensures that the token is consistently verified across all services involved in the request chain, maintaining secure access control throughout the entire process.
Benefits of Using OAuth2 in Microservices
- Centralized Authentication: By using a service gateway with OAuth2, authentication and authorization logic are centralized, making it easier to manage access controls. Users authenticate once, and their identity and permissions are propagated across the entire microservices ecosystem.
- Scalability: OAuth2 is highly scalable because it decouples the authentication process from the individual services. Microservices don’t need to worry about managing user credentials or performing authentication, which simplifies the implementation and allows each service to focus on its core functionality.
- Security: OAuth2 ensures that credentials are never passed around between services, and tokens are used instead. This minimizes the risk of exposing sensitive information. Additionally, tokens can be scoped to grant only the necessary permissions, and they can be time-limited for added security.
Communication Patterns
In a microservices architecture, communication between services is a critical component that greatly influences system performance, scalability, and resilience. The choice of communication style—synchronous or asynchronous—is a significant factor in determining how well the system handles traffic, failures, and overall complexity.
The decision between synchronous and asynchronous communication patterns can have a profound impact on how microservices interact with each other.
- Synchronous Communication: In synchronous communication, both services (or clients and servers) must be available at the same time to exchange messages. The sender sends a request and waits for a response before continuing, which creates tight runtime coupling between the services. This type of communication requires that both services are operating simultaneously and that the response time is quick enough for the sender to proceed without significant delays.
Example: A service
makes a REST API call to service . Service sends a request and waits for service to process the request and return a response. If service is slow or unavailable, service is also delayed.
- Asynchronous Communication: In contrast, asynchronous communication allows the services to interact without needing to be synchronized in real-time. The sender can send a message and continue processing without waiting for a response. The recipient of the message can pick up the request at its own pace, which leads to loose coupling between the services.
Example: Service
sends a message to a message queue, and service picks it up and processes it at its convenience. This decouples the services, allowing service to continue working without waiting for service ’s response.
Event-Driven Framework for Decoupling
An event-driven framework is often used to implement asynchronous communication in microservices. In this approach, services publish events to a messaging system (such as a message broker) and other services subscribe to those events. The services do not need to be aware of each other, only that they can respond to the events in the system.
Events are typically broadcast to all interested subscribers, and each service consumes events when it’s ready. This mechanism can handle multiple communication styles, such as notification, request/response, and publish/subscribe.
- Notification: In this one-way communication pattern, a service sends a message or event to inform others of a certain event or state change, but no response is expected.
- Request/Response: This is the traditional two-way communication pattern, where one service sends a request and expects a response.
- Publish/Subscribe: In this pattern, a service (publisher) sends out a message (event) to multiple services (subscribers), which can then react to the event as needed. This is commonly used in systems that require high scalability and flexibility.
| Advantages | Disadvantages |
|---|---|
| Loose Coupling: Services only exchange messages, allowing for greater flexibility and easier scaling. | Increased Complexity: Requires handling message delivery, managing queues, and coordinating distributed services. |
| Higher Flexibility and Scalability: Services can handle messages at their own pace, and additional instances can be deployed to manage higher traffic. | Eventual Consistency: Not all services have the same data at the same time, requiring mechanisms to handle unsynchronized services. |
| Improved Availability: If one service is down, messages can be queued until it is available again, ensuring high system availability. | Debugging and Monitoring: Harder to track issues due to non-immediate interactions, requiring advanced monitoring and logging. |
| Queue-Based Resilience: Messages can be queued when a service is busy, and multiple replicas can handle messages in parallel. |
Technologies
Several frameworks and tools are commonly used in microservices development to simplify building and managing services. These technologies help with features like service discovery, load balancing, circuit breaking, and event-driven communication. Here are some popular ones:
Spring Boot
Spring Boot is a popular Java framework for creating microservices. It makes it easier to build applications by providing built-in servers and automatic configuration. This allows developers to focus on writing business logic instead of dealing with complex setup.
Key Features
- Quick setup with minimal configuration
- Built-in web servers (like Tomcat or Jetty)
- Easy integration with other tools in the Spring ecosystem
Spring Cloud Netflix
Spring Cloud Netflix is a set of tools that integrates essential microservice patterns, such as service discovery and load balancing, using Netflix’s open-source components.
Key Features
- Service Discovery (Eureka): Automatically registers and finds services in a distributed system.
- Circuit Breaker (Hystrix): Protects services from failure by stopping requests when an issue is detected.
- Intelligent Routing (Zuul): A gateway that routes requests and handles authentication, load balancing, and monitoring.
- Client-Side Load Balancing (Ribbon): Distributes requests across service instances to ensure better availability.
Spring Cloud Stream
Spring Cloud Stream is a framework for building event-driven microservices that communicate with shared messaging systems like Apache Kafka or RabbitMQ. It allows microservices to send and receive events asynchronously, improving scalability and decoupling services.
- Event-Driven: Services communicate by sending and receiving events rather than direct calls.
- Binder Implementations: It supports different messaging systems like Apache Kafka and RabbitMQ, which handle the delivery of messages between services.