Architectural decisions play a critical role in determining various software qualities, and their impact can be observed across multiple aspects of the system. Some of the key qualities affected by architectural choices include scalability, reliability, availability, and usability. Each of these qualities is essential for the overall effectiveness of a system and must be carefully considered during the design phase.
To manage and improve these qualities, it is crucial to adopt a structured approach. First and foremost, we need to establish metrics that provide a clear, quantitative measurement of these qualities. For example, scalability can be measured in terms of how well a system can handle an increasing number of users or requests, while reliability may be assessed by evaluating the system’s ability to function correctly over time without failure. Usability could be measured through user satisfaction and task completion time, among other factors.
Once we have metrics in place, we can then focus on specific methodologies designed to analyze the quantitative impact of architectural decisions on these qualities. These methodologies allow architects and engineers to make informed choices about the system’s design. By applying these approaches, we can assess potential trade-offs and determine how each architectural decision influences the overall quality attributes of the system.
In addition to metrics and methodologies, tactics are also necessary to directly address the challenges that arise in achieving desired software qualities. Tactics are actionable strategies and design patterns that can be applied to mitigate issues related to scalability, reliability, or other quality concerns. For example, the use of redundancy mechanisms may improve reliability and availability, while modularization can enhance scalability and maintainability. These tactics are essential tools for ensuring that the software architecture supports the system’s functional and non-functional requirements.
Availability
The concept of availability in IT systems is critical to ensuring that services are continuously accessible to users with minimal disruption. For a service to achieve high availability, it must experience minimal downtime and, when failures do occur, recover rapidly to minimize the impact on users. Achieving this level of availability requires a thoughtful architecture and efficient management processes, as the availability of a service is influenced by several factors. Key elements include the complexity of the IT infrastructure, the reliability of each component, the speed and effectiveness with which the system can respond to faults, the quality of maintenance and support provided, and the robustness of the operational management processes.
System Life-Cycle and Failure Response
To maintain availability, it is essential to understand the system’s life-cycle in terms of how it manages and responds to failures:
- Time of Occurrence: This is when the user first experiences and becomes aware of a failure.
- Detection Time: This is the point at which operators or automated systems detect the failure, which can vary based on monitoring effectiveness.
- Response Time: Following detection, the operators need time to diagnose the issue and communicate with users, providing an initial response.
- Repair Time: This includes the actual time required to repair the fault within the system, whether it involves replacing components or rectifying software issues.
- Recovery Time: Once repairs are complete, the system may require additional time for re-configuration or re-initialization to restore full service availability.
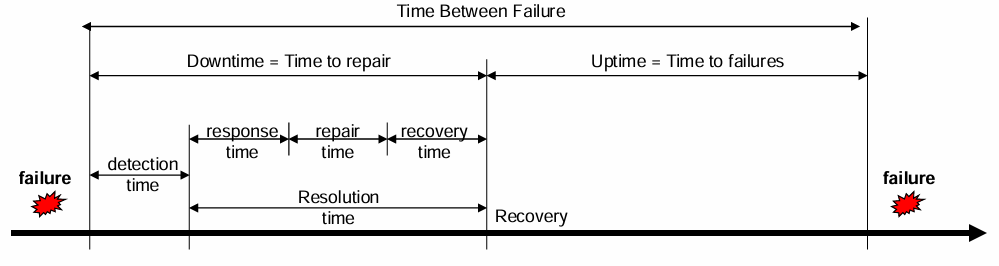
Key metrics used to quantify these phases and support availability assessments include:
- Mean Time to Repair (
), which measures the average time from when a failure occurs to when the system is back online, encompassing downtime duration. - Mean Time to Failures (
), representing the average operational period between a system’s recovery and the next failure occurrence, effectively measuring uptime. - Mean Time Between Failures (
), calculating the average duration between two consecutive failures.
Availability Metrics and “Nines Notation”
Definition
Availability is quantified by the probability that a system or component is operational at any given time, denoted mathematically as:
where a smaller
leads to approximating , reflecting fewer failures over time.
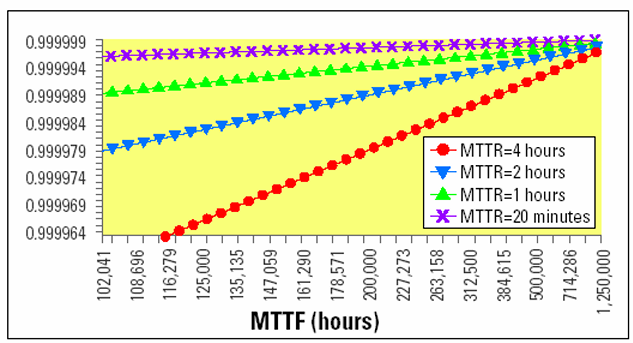
High availability is often expressed using “nines notation,” which reflects the percentage of time a system is operational. For example:
- 99.9% (3-nines) availability translates to roughly
hours of downtime per year. - 99.999% (5-nines) availability represents only about
minutes of downtime per year.
| Availability | Downtime |
|---|---|
| 90% (1-nine) | 36.5 days/year |
| 99% (2-nines) | 3.65 days/year |
| 99.9% (3-nines) | 8.76 hours/year |
| 99.99% (4-nines) | 52 minutes/year |
| 99.999% (5-nines) | 5 minutes/year |
This notation helps organizations set and communicate availability targets based on the criticality of their services.
Availability Analysis Methodology
To effectively calculate availability, systems are often modeled as interconnected elements in series and parallel:
- Series Configuration: When elements operate in series, a failure in any single element results in the failure of the entire series. This setup demands high reliability of each individual component.
- Parallel Configuration: In parallel configurations, a failure in one element can be compensated by other elements, which take over the operations of the failed component. This configuration increases redundancy and, therefore, overall availability.
By analyzing and balancing these configurations, system architects can design infrastructures that optimize availability, ensuring that critical services are consistently accessible with minimal downtime and quick recovery capabilities.
Availability in Series
When system components are arranged in series, the entire system remains operational only if every individual part is functional. This configuration makes the system highly dependent on the availability of each component, as a failure in any single part will cause the entire system to fail. The combined availability of components in a series configuration is calculated as the product of the individual availabilities:
Example
For example, if a system consists of two components where Component 1 has 99% (2-nines) availability and Component 2 has 99.999% (5-nines) availability, the combined availability is calculated as 98.999%. This means that the total system downtime would be approximately 3.65 days per year, driven primarily by the lower availability of Component 1. In series configurations, the system is only as strong as its weakest link—a concept illustrating the importance of ensuring high reliability across all components to prevent performance bottlenecks.
Component Availability Downtime Component 1 99% (2-nines) 3.65 days/year Component 2 99.999% (5-nines) 5 minutes/year Combined 98.999% 3.65 days/year
Availability in Parallel
For systems configured in parallel, availability is enhanced by introducing redundancy. In this setup, the overall system remains operational as long as at least one component is functioning. The combined availability in a parallel configuration is determined by the probability that not all components fail simultaneously, and is calculated as:
Parallel configurations are common in mission-critical systems where downtime must be minimized. By combining components with lower individual availabilities, the overall system can achieve a much higher level of availability.
Example
For instance, if two components each have an availability of 99% (2-nines), the combined availability reaches 99.99% (4-nines), translating to only 52 minutes of downtime per year. This configuration showcases the effectiveness of redundancy in improving system reliability and availability.
Component Availability Downtime Component 1 99% (2-nines) 3.65 days/year Component 2 99% (2-nines) 3.65 days/year Combined 99.99% (4-nines) 52 minutes/year
Availability of Complex Systems
In complex systems, availability is often a combination of series and parallel configurations. The challenge lies in optimizing these configurations to achieve the desired availability level while managing the cost and complexity of redundant components.
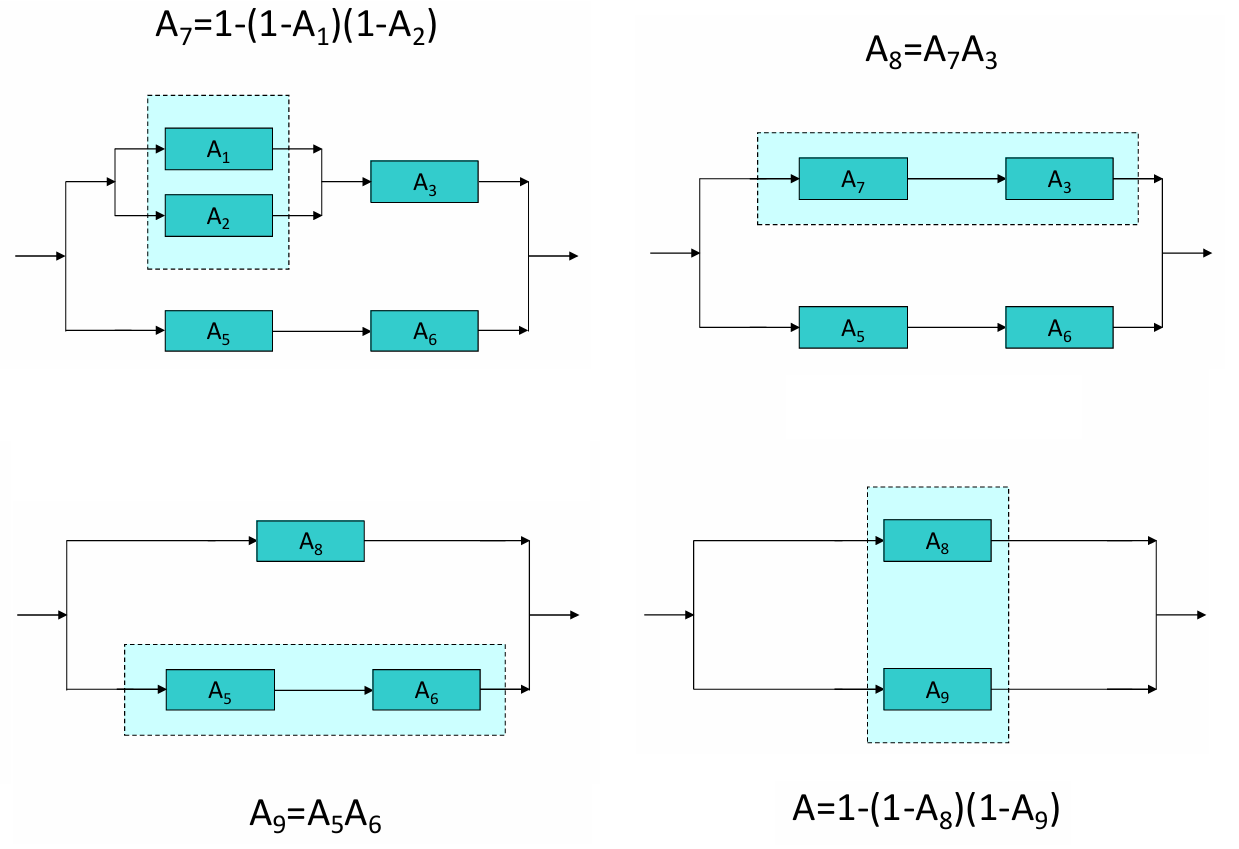
Tactics for Ensuring Availability
In system architecture, tactics refer to specific design decisions aimed at controlling and enhancing one or more quality attributes, such as availability. To ensure that a system remains available despite failures or disruptions, certain tactics can be employed to minimize downtime and optimize recovery.
One fundamental tactic for achieving high availability is replication, which involves duplicating system components to provide redundancy. Replication is straightforward when dealing with stateless components since each replicated instance operates independently. However, for stateful components, replication strategies become more complex, as the system must ensure that all replicas maintain up-to-date state information. Additional tactics include forward error recovery and implementing a circuit breaker pattern, particularly useful in microservice architectures.
Replication Strategies
Several replication approaches are commonly used to maintain availability:
-
Hot Spare: In this approach, Component 1 (
) is actively processing requests, while Component 2 ( ) is on standby, fully operational and ready to take over instantly if fails. This configuration provides rapid failover and is best for high-availability systems where even minimal downtime is unacceptable. 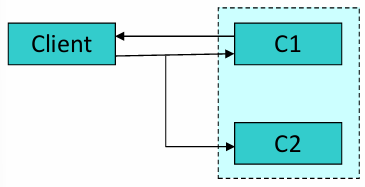
-
Warm Spare: Here,
operates as the primary component, and is partially updated at regular intervals. In the event of ‘s failure, will require some additional time to synchronize and fully take over operations. Although this strategy involves a brief delay, it reduces resource consumption compared to the hot spare approach. 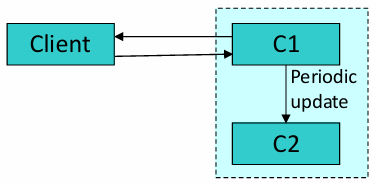
-
Cold Spare: In a cold spare setup,
remains inactive until it is needed. When fails, is started and updated to assume ‘s role. This approach is more resource-efficient but involves a longer delay for to become fully functional, as it must initialize and update before taking over. 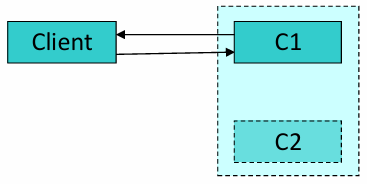
-
Triple Modular Redundancy (TMR): This approach involves three active components (
, , and ), all performing the same tasks simultaneously. In TMR, the output is determined by a majority vote, providing high fault tolerance and availability. This tactic is highly effective in critical systems where reliability and availability are both priorities, as it allows the system to continue functioning accurately even if one component fails. 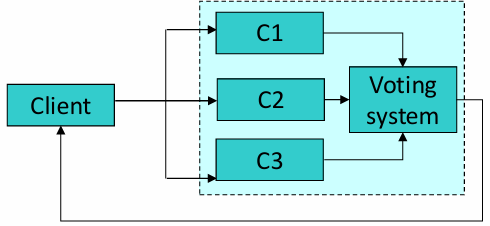
Forward Error Recovery
Forward error recovery is a tactic applied when a component, such as
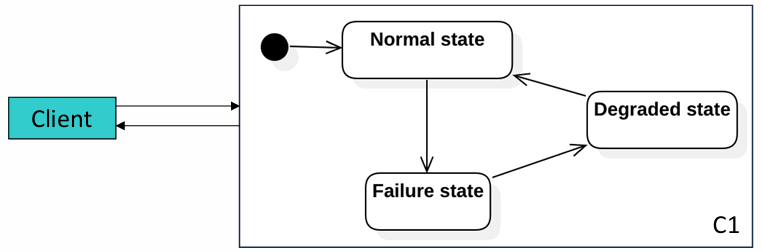
Performance
Performance in software systems reflects how well a system or component meets its requirements for timeliness, often gauged by how effectively it handles operations and resource usage under specified conditions. As noted by Connie U. Smith and Lloyd G. Williams,
performance measures how responsive and efficient a system is, which directly impacts user experience and satisfaction.
While sometimes defined simply as the efficient use of resources, performance is closely linked to scalability. Scalability is the ability of a system to maintain its response time and throughput as demand increases. This means a scalable system can handle more users or requests without significant degradation in performance. Common metrics to assess performance include response time (the time it takes to complete a request), throughput (number of requests processed per time unit), CPU and memory utilization, and I/O operations.
Tactics to Improve Performance
Several tactics can be employed to enhance system performance. These tactics broadly focus on controlling resource demand and improving software efficiency.
Controlling Resource Demand
-
Manage Input: By controlling input, systems can prevent overload and ensure smoother operation.
- Event Arrival Management: Regulate the arrival rate of events or requests to reduce bottlenecks.
- Sampling Rate Management: Adjust the sampling rate for data-intensive operations to balance precision with performance.
- Queue Size Boundaries: Limit the size of event queues to avoid delays caused by excessive backlog.
- Event Prioritization: Prioritize critical events over less important ones to improve responsiveness.
-
Improve Software Efficiency: This approach focuses on optimizing how software components interact and execute tasks.
- Reduce Indirection: Minimizing intermediate layers in processing to reduce latency.
- Co-locate Resources: Place interacting resources in close proximity (e.g., within the same server or data center) to reduce latency.
- Bound Execution Time: Setting execution time limits ensures no process dominates resources.
- Algorithm Efficiency: Select efficient algorithms for processing to optimize response times, especially in data-heavy applications.
Leveraging Resources for Improved Performance
- Increase Resources: Allocate additional computing power, memory, or network capacity to handle increased loads.
- Introduce Concurrency: Use parallel processing to perform multiple tasks simultaneously, improving throughput.
- Add Multiple Replicas and Load Balancing: Using replicas of services or data can reduce response times by distributing requests across multiple resources.
- Data Replication and Caching: Storing frequently accessed data in multiple locations or caching can reduce retrieval times and server load.
- Resource Scheduling: Implement intelligent scheduling strategies to optimize resource allocation for prioritized tasks.
- Input Splitting: Dividing input into smaller, manageable parts can enhance efficiency by enabling focused processing for each subset.
Case Study: Twitter’s Performance Challenges and Tactics
To illustrate the application of these performance tactics, consider Twitter’s approach to handling the vast number of requests generated by its users. Twitter’s infrastructure faces two primary operations:
- Posting a Tweet: When a user posts a tweet, it generates about 4.6k requests per second on average, peaking at 12k requests per second.
- Home Timeline Generation: The home timeline shows tweets from people a user follows, with around 300k requests per second, creating a significant challenge due to the high volume of connections between users and their followers.
Design Approach 1: Direct Retrieval from Tweets Table
Initially, a basic design could involve storing all tweets in a central tweets table. When a user requests their home timeline, the system retrieves the tweets of the people the user follows directly from this table. While functional, this design struggles with scalability, as it requires multiple lookups for each user request, leading to inefficiencies under high loads.
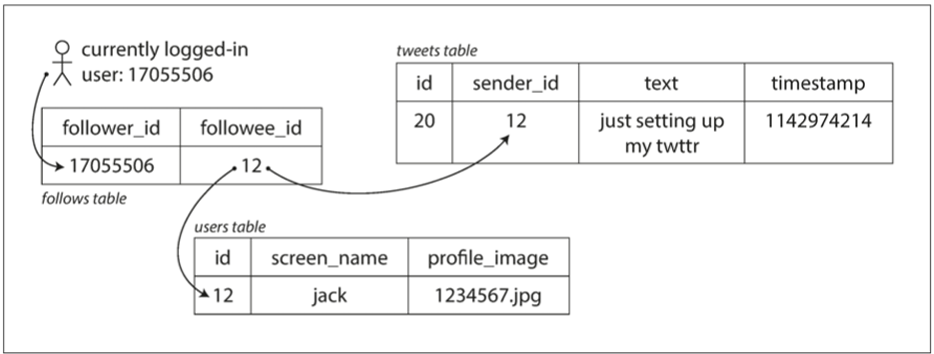
Design Approach 2: Enhanced Design with Data Replication and Caching
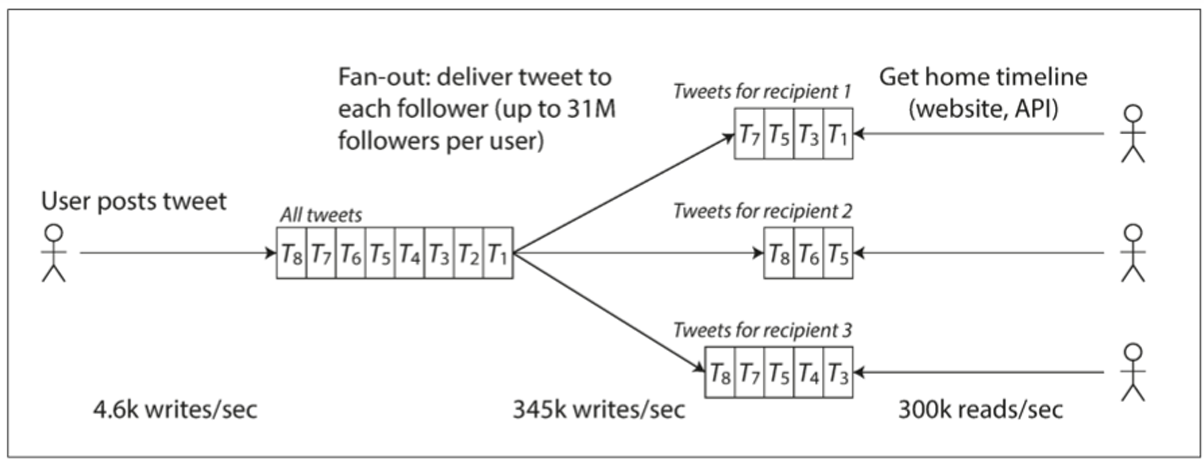
An improved design would involve data replication and caching. By creating redundant copies of user data and using caches for frequently accessed information, Twitter can reduce retrieval times and lower the load on the main database. This design also benefits from load balancing, distributing requests across replicas, and concurrency, allowing for simultaneous processing of multiple requests. This approach not only scales more effectively but also enhances the user experience by delivering quicker and more reliable responses, even under heavy traffic.