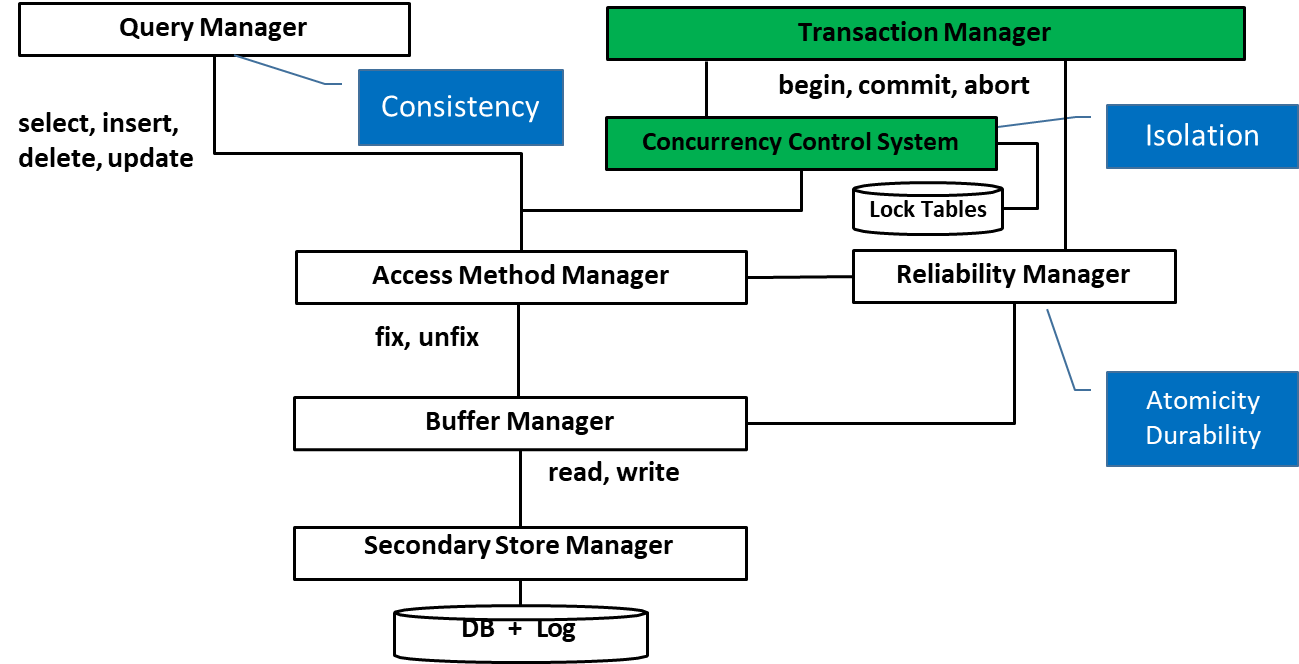
The Concurrency Control System is a fundamental component of a database management system (DBMS) responsible for managing the simultaneous execution of multiple transactions in a way that ensures both consistency and performance. In multi-user environments, where many transactions may be running concurrently, it is crucial to coordinate their execution to prevent conflicts, data corruption, or inconsistency.
Concurrency in database systems often introduces challenges when multiple transactions access and modify the same resources simultaneously. These challenges can lead to several problems such as lost updates, dirty reads, or inconsistent states.
Example of Concurrency Issues
Consider the following two SQL transactions:
-- Transaction T1begin transaction update account set balance = balance + 3 where customer = 'Smith'commit work-- Transaction T2begin transaction update account set balance = balance + 6 where customer = 'Smith'commit work
Both T1 and T2 update the balance for the same customer, ‘Smith,’ but add different amounts: T1 adds 3, while T2 adds 6. If these transactions are executed concurrently without proper management, one of the transactions could overwrite the changes made by the other, resulting in a lost update.
Consider another version of these transactions that explicitly reads and writes values from a variable D representing the balance:
-- Transaction T1begin transaction var x; read(D -> x) x = x + 3 write(x -> D)commit work-- Transaction T2begin transaction var y; read(D -> y) y = y + 6 write(y -> D)commit work
In this scenario, T1 reads the current value of D, adds 3 to it, and writes the result back to D. Simultaneously, T2 reads the same value of D, adds 6 to it, and writes its result back. If T1 and T2 execute concurrently without proper synchronization, the final value of D could reflect only one of the updates (either +3 or +6), depending on which transaction finishes last.
In serial execution, transactions are processed one after the other in a strict order, avoiding any possibility of conflicts. The operations from one transaction fully complete before the next transaction begins. While the exact final value of D might vary depending on the order of transactions, the main advantage is that no updates are lost, and the database maintains a consistent state.
In contrast, concurrent execution requires a concurrency control mechanism, such as locking or timestamping, to ensure that operations on shared resources are coordinated properly. Without these mechanisms, anomalies like lost updates or inconsistent reads can occur, leading to unreliable or incorrect data.
Concurrency Control
Concurrency is indeed a critical aspect of modern database systems, particularly in environments that handle high transaction volumes, such as banking and ticket reservations. Executing tens or hundreds of transactions per second serially would lead to significant inefficiencies and slow down the entire system, impacting user experience and overall performance.
Example
In applications like banks, where numerous customers may be performing transactions simultaneously (such as transferring funds, checking balances, or depositing money) it’s essential to allow these actions to occur concurrently.
Similarly, ticket reservation systems must process multiple requests at once to ensure that users can secure their tickets in real-time, especially during high-demand events.
However, with the ability to execute transactions concurrently comes the risk of anomalies, such as:
Lost Updates: One transaction overwrites the changes made by another, leading to incorrect data.
Dirty Reads: A transaction reads data that has not yet been committed by another transaction, which may lead to inconsistencies if the uncommitted transaction is rolled back.
Non-repeatable Reads: If a transaction reads the same data twice, it may get different results if another transaction modifies that data in between.
Phantom Reads: A transaction retrieves a set of rows that meet a certain condition, but another transaction inserts or deletes rows, changing the result set if the first transaction re-executes the same query.
Summary
Anomaly
Description
Example
Lost update
An update is applied from a state that ignores a preceding update, which is lost
r1 - r2 - w2 - w1
Dirty read
An uncommitted value is used to update the data
r1 - w1 - r2 - abort1 - w2
Nonrepeatable read
Someone else updates a previously read value
r1 - r2 - w2 - r1
Phantom update
Someone else updates data that contributes to a previously valid constraint
r1 - r2 - w2 - r1
Phantom insert
Someone else inserts data that contributes to a previously read datum
r1 - w2(new data) - r1
To mitigate these risks, concurrency control mechanisms must be implemented. These mechanisms can include:
Locking Protocols: Preventing multiple transactions from accessing the same resource simultaneously, ensuring that only one transaction can modify a resource at a time.
Timestamp Ordering: Assigning timestamps to transactions to determine the order of their execution based on when they were initiated, ensuring a consistent state.
Optimistic Concurrency Control: Allowing transactions to execute without locks but validating at commit time to ensure that no other transactions have modified the data in the interim.
Lost Update Anomaly
When two transactions read the same data, perform their updates, and write the results back to the database without knowledge of each other’s operations, an update can be lost.
Example
Initial value: D = 100
Steps:
T1:r(D -> x) → Reads D and stores the value in x.
T1:x = x + 3 → Updates x to 103.
T2:r(D -> y) → Reads D (the original value, still 100) into y.
T2:y = y + 6 → Updates y to 106.
T1:w(x -> D) → Writes 103 to D. Now D = 103.
T2:w(y -> D) → Overwrites D with 106. The update done by T1 is lost!
In this case, the update by T1 is overwritten by T2, leading to the loss of T1’s change.
Note that this anomaly does not depend merely on T2 overwriting T1’s update; it can also occur if T1 reads a value, modifies it, and then writes it back after T2 has already modified the same value.
Dirty Read Anomaly
A transaction reads uncommitted data from another transaction, and if the other transaction is rolled back, the data read becomes invalid or “dirty.”
Example
Initial value: D = 100
Steps:
T1:r(D -> x) → Reads D into x.
T1:x = x + 3 → Updates x to 103.
T1:w(x -> D) → Writes 103 to D. Now D = 103.
T2:r(D -> y) → Reads the updated value of D = 103 (but this is uncommitted).
T1:rollback → T1 rolls back, meaning the change to D is undone, and D should return to 100.
T2:y = y + 6 → Adds 6 to the “dirty” value 103, now y = 109.
T2:w(y -> D) → Writes 109 to D. The rollback from T1 is ignored, and T2’s update is based on a dirty read.
In this case, T2 used a value that was invalidated by T1’s rollback.
Non-repeatable Read Anomaly
A transaction reads the same value multiple times, but between the reads, another transaction modifies the data, leading to inconsistent results.
Example
Initial value: D = 100
-- Transaction T1SELECT balance FROM account WHERE client = "Smith"...SELECT balance FROM account WHERE client = "Smith"-- Transaction T2UPDATE account SET balance = balance + 6 WHERE client = "Smith"
Steps:
T1:r(D -> x) → Reads D, gets x = 100.
T2:r(D -> y) → Reads D, gets y = 100.
T2:y = y + 6 → Updates y to 106.
T2:w(y -> D) → Writes 106 to D. Now D = 106.
T1:r(D -> z) → Reads D again, but now z = 106 (which is different from x!).
This anomaly occurs because T1’s second read returns a different value than the first, leading to inconsistent results.
Phantom Update Anomaly
A transaction reads a set of rows that satisfy a certain condition, but during the execution of the transaction, another transaction modifies rows, making the initial query results invalid.
Example
Suppose we have a constraint: A + B + C = 100, with A = 50, B = 30, and C = 20.
Steps:
T1: Reads A = 50, B = 30.
T2: Reads B = 30, C = 20.
T2: Updates B = 40, C = 10 (so A + B + C = 100 remains valid).
T1: Reads C = 10. Now, for T1, A + B + C = 50 + 30 + 10 = 90, leading T1 to believe the constraint is violated.
In this case, T2’s update is valid, but T1’s view of the data sees a “phantom” anomaly, where the sum appears incorrect.
Phantom Insert Anomaly
A transaction reads data based on a condition, but while it’s still running, another transaction inserts new rows that meet the same condition, causing inconsistent query results.
Example
T1: Calculates the average value for B where A = 1 using a query.
T1: SELECT AVG(B) FROM Tab WHERE A = 1;
T2: Inserts a new row that satisfies A = 1.
T2: INSERT INTO Tab (A, B) VALUES (1, 2);
T1: Reruns the query, but now the average has changed due to the new row inserted by T2. This “phantom” tuple wasn’t there during the initial execution of T1’s query.
This anomaly occurs because the result set T1 was working with has changed due to T2’s insertion.
Concurrency Theory vs System Implementation
Concurrency Theory offers an abstraction to help understand the properties and behavior of transactions when executed concurrently, particularly regarding how to ensure data consistency and isolation. This theoretical model, however, simplifies real-world complexities and doesn’t concern itself with the specific mechanisms used in actual systems to manage concurrency.
Real systems, such as databases, use implementation mechanisms (e.g., locks, snapshots) that achieve the goals outlined by concurrency theory (like isolation and consistency) but at a practical, low-level. In a DBMS, instead of finding theoretical checks like “view serializability” or “conflict serializability,” you’ll observe implementation features such as:
Lock tables: Manage which transactions hold locks on which resources.
Lock types: Shared or exclusive, controlling read or write access.
Lock granting rules: Determine how locks are acquired and released to avoid conflicts.
Snapshots: Provide a versioned view of the data for each transaction to prevent anomalies.
These mechanisms ensure the system maintains the desirable properties postulated by concurrency theory, such as atomicity, consistency, isolation, and durability (ACID), without relying on theoretical constructs at runtime.
Transactions, Operations, and Schedules
Definitions
Operations: The atomic actions that transactions perform on the database. These are either reads (denoted by r) or writes (denoted by w) of specific data items. In concurrency theory:
r1(x) = r1(x -> .) means transaction T1 reads x.
w1(x) = w1(. -> x) means transaction T1 writes to x.
r1(x) and r1(y) are different operations (different data) on the same transaction.
r1(x) and r2(x) are different operations (different transactions) on the same data.
Schedule: A sequence of operations from multiple transactions that interleave based on their execution order. Schedules represent the order in which these operations are executed. A schedule must respect the order of operations within each transaction.
Example
Transaction 1 (T1): r1(x) w1(x) (reads and writes x)
Transaction 2 (T2): r2(z) w2(z) (reads and writes z)
Schedule S1: r1(x) r2(z) w1(x) w2(z) – This schedule shows the operations of two transactions executing in some interleaved order.
Given two transactions, the number of distinct schedules that can arise from their interleaving is limited by the number of ways their operations can be interleaved, while respecting the order of operations within each transaction.
For transactions T1 (r1(x) w1(x)) and T2 (r2(z) w2(z)), the following schedules are possible:
Serial Schedules (operations of one transaction are completely executed before the other):
Interleaved Schedules (operations of the transactions are mixed):
Nested Schedules (more complex interleaving):
In the realm of database transactions, understanding the number of possible schedules is essential for analyzing concurrency control and performance. When we have transactions, denoted as , each transaction can consist of a varying number of operations. Specifically, let transaction have operations, which can be represented as follows:
To analyze how many different schedules can be generated from these transactions, we can break this down into two main categories: serial schedules and distinct schedules.
Serial Schedules
Definition
A serial schedule is one in which the operations of each transaction are executed in a contiguous sequence, without interleaving with operations from other transactions.
The number of possible serial schedules for transactions can be computed using permutations, specifically . This is because any of the transactions can be placed in the first position, any of the remaining transactions can follow, and so on. Thus, the formula for the number of serial schedules, , is:
This formula signifies that there are unique ways to arrange the transactions in a serial order.
Distinct Schedules
Definition
The distinct schedules consider all the possible ways in which the operations from all transactions can be interleaved, while still respecting the internal order of operations within each transaction.
The number of distinct schedules can be calculated using the formula:
where, represents the total number of permutations of all operations, divided by the product of the number of permutations of the operations within each transaction. Each transaction’s internal sequence must be preserved; hence, only one out of the permutations for each transaction is valid. The denominator accounts for this constraint, ensuring that the internal order of each transaction’s operations is maintained.
Principles of Concurrency Control
The goal of concurrency control is to ensure that the resulting database state is consistent and accurate, regardless of the number of concurrent transactions.
To achieve this, a scheduler is employed, which is a component responsible for accepting or rejecting the operations requested by the transactions.
Definition
A serial schedule is defined as a sequence of operations in which the actions of each transaction occur in a contiguous manner without interleaving with operations from other transactions. For example, a serial schedule might look like this:
Here, the operations of transaction are completed before any operations from or begin.
In contrast, a non-serial schedule allows for interleaved operations:
In this case, the actions of the transactions overlap, creating the potential for anomalies if not properly controlled.
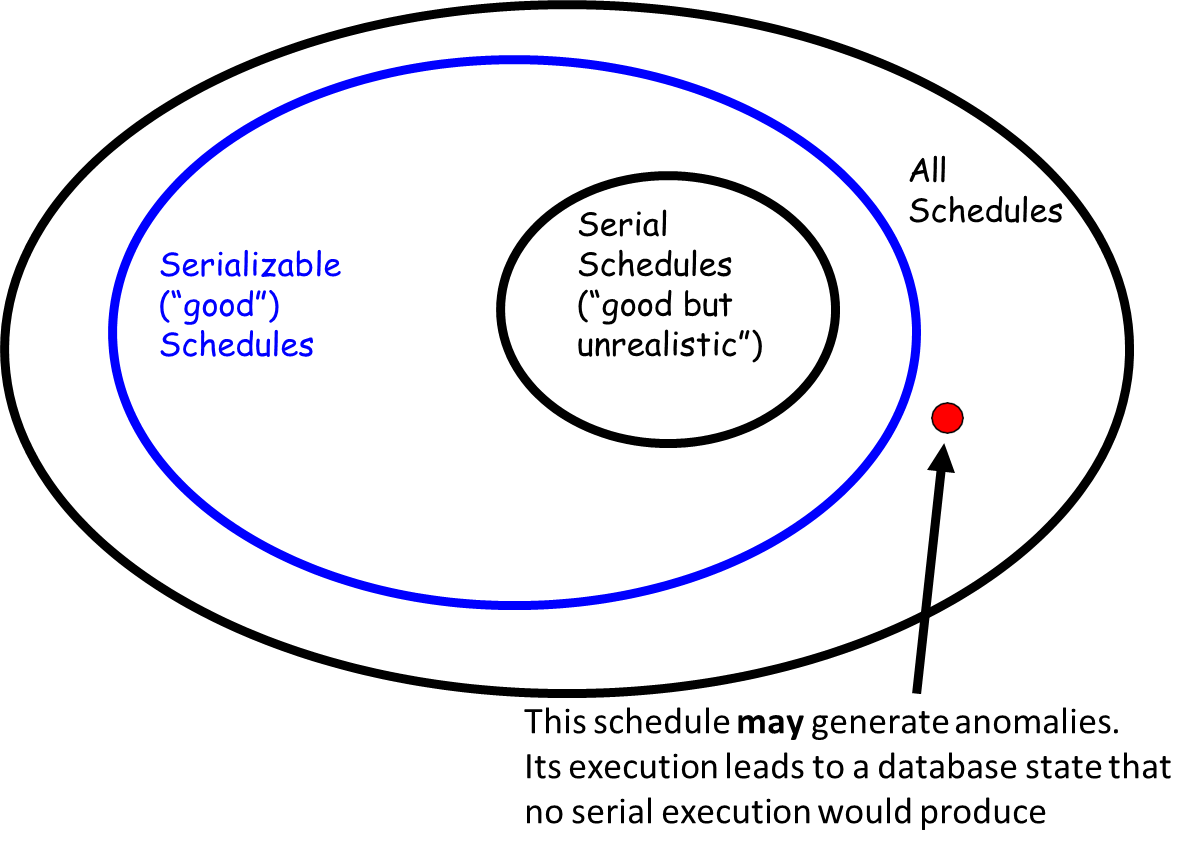
The notion of a serializable schedule is critical to ensuring correctness in database transactions.
A schedule is considered serializable if it leaves the database in the same state as some serial schedule comprising the same transactions.
This criterion is widely accepted as a benchmark for determining the correctness of a schedule. To facilitate this, a concept known as schedule equivalence is employed, which identifies classes of schedules that ensure serializability. However, different equivalence notions lead to different classes of schedules, and the cost of checking whether a given schedule is serializable can vary significantly based on the approach used.
An important assumption in the study of concurrency control is that transactions are initially observed "a-posteriori", limited to those that have committed (a practice known as commit-projection).
Under this model, analysts can evaluate whether the observed schedule is admissible. However, in practical scenarios, schedulers face the challenge of making decisions in real-time while transactions are still running. This requirement underscores the complexity of designing effective concurrency control mechanisms that can adapt to dynamic workloads while maintaining database integrity.