TL;DR
This document provides an overview of multiprocessor systems, which integrate multiple CPUs to enhance performance and reliability.
- Core Concepts: Multiprocessors, often in the form of multicore chips, use a Multiple Instruction Multiple Data (MIMD) model. Key design choices involve the number and type of processors, their interconnection, and data sharing mechanisms.
- Interconnection: Processors are connected via a single bus (simple, cheap, but a bottleneck for >8-16 cores) or scalable interconnection networks (e.g., mesh, hypercube), which offer better performance at a higher cost. Network efficiency is measured by total and bisection bandwidth.
- Data Sharing & Memory Models:
- Logical Model: Processors can use a shared address space (all CPUs see one memory, simplifying programming but requiring cache coherence) or private address spaces (each CPU has its own memory, requiring explicit message-passing).
- Physical Organization: Memory can be centralized (UMA), with uniform access time for all processors, or distributed (NUMA), where accessing local memory is faster than remote memory.
- Architectures:
- Centralized Shared Memory (SMP): Common in small multicore chips, uses UMA and snooping protocols for cache coherence.
- Distributed Shared Memory (DSM/CC-NUMA): Scales to more cores by physically distributing memory while maintaining a single logical address space, using directory-based coherence.
- Distributed Memory (Clusters): Highly scalable systems where each node has private memory and communicates via message passing (e.g., MPI).
- Programming Models: Communication is managed through shared memory (implicit data exchange), message passing (explicit
send/receiveoperations), or data parallelism (multiple processors performing the same operation on different data subsets).
In recent decades, computer architecture has undergone a significant transformation, marking the beginning of a new era centered around multiprocessor systems. These systems, once reserved for specialized or high-performance computing environments, now span a wide range of applications—from embedded systems in mobile devices and appliances to high-end, general-purpose computing platforms. The primary objectives driving the development and adoption of multiprocessor architectures include achieving extremely high computational performance, ensuring system scalability as workloads grow, and maintaining high levels of system reliability.
Definition
Multiprocessors are systems that integrate multiple processing units (CPUs) in a tightly coupled configuration. These processors typically operate under the control of a single operating system and share a common address space, allowing them to access shared memory.
This architectural style simplifies programming models and data sharing but introduces complexities in coordination and memory consistency.
A specific subset of multiprocessor systems is referred to as multicore architectures.
Definition
In a multicore processor, multiple processing cores are integrated onto a single chip, allowing for high communication speed and low latency between cores. When the number of cores exceeds 32, the architecture is often termed manycore.
These designs offer significant performance benefits, especially in parallelizable workloads, by maximizing on-chip concurrency and reducing the need for off-chip communication.
Multiprocessor systems typically employ a Multiple Instruction Multiple Data (MIMD) model. In MIMD systems, each processor can execute different instructions on different data simultaneously, offering great flexibility and parallelism suitable for a wide array of applications, from scientific simulations to real-time analytics.
Designing efficient and effective multiprocessor systems involves addressing a number of critical architectural and operational questions.
- How many processors should be included in the system?: The number of processors directly influences the system’s performance and cost. A balance must be struck between the number of processors and the workload they are expected to handle.
- What type of processors should be used?: The choice between high-performance cores, energy-efficient cores, or a hybrid approach can significantly impact the system’s performance and power consumption.
- How should the processors be interconnected?: The interconnection strategy is crucial for ensuring efficient communication between processors. Options include a single shared bus or more complex interconnection networks.
- How should data be shared and coordinated among processors?: This involves addressing issues such as cache coherence and memory consistency, which are essential for maintaining a consistent view of memory across multiple processors.
- How should the system be programmed?: The programming model must support parallel execution and efficient data sharing, often requiring specialized languages or libraries.
Single-Bus vs. Interconnection Networks
The method used to connect multiple processors significantly impacts both system performance and scalability.
Definition
In a single-bus architecture, all processors communicate with memory and with each other over a single shared bus.
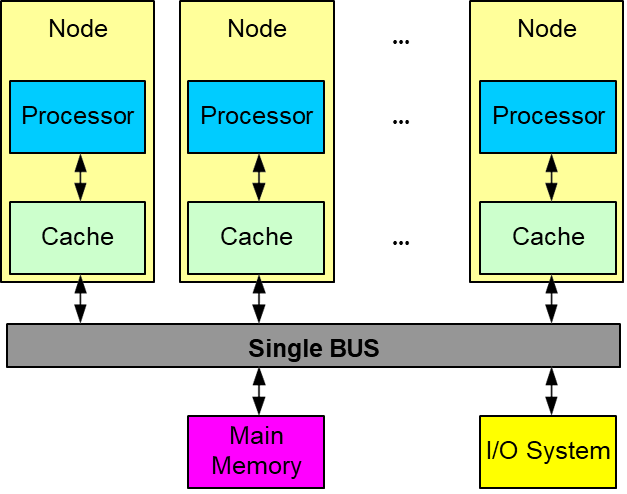
This design is simple and cost-effective for a small number of processors. However, the bus quickly becomes a point of contention as more processors are added. In commercial systems, the largest practical number of processors connected via a single bus is around 36. Beyond this point, the bus becomes saturated, and system performance plateaus regardless of the number of additional processors.
To overcome these limitations, interconnection networks are introduced in systems requiring high scalability. These networks use switches and multiple communication links to interconnect processors and memory modules, allowing for higher bandwidth and lower contention. Though more complex and initially more expensive to implement, network-connected multiprocessor systems offer better long-term performance scalability.
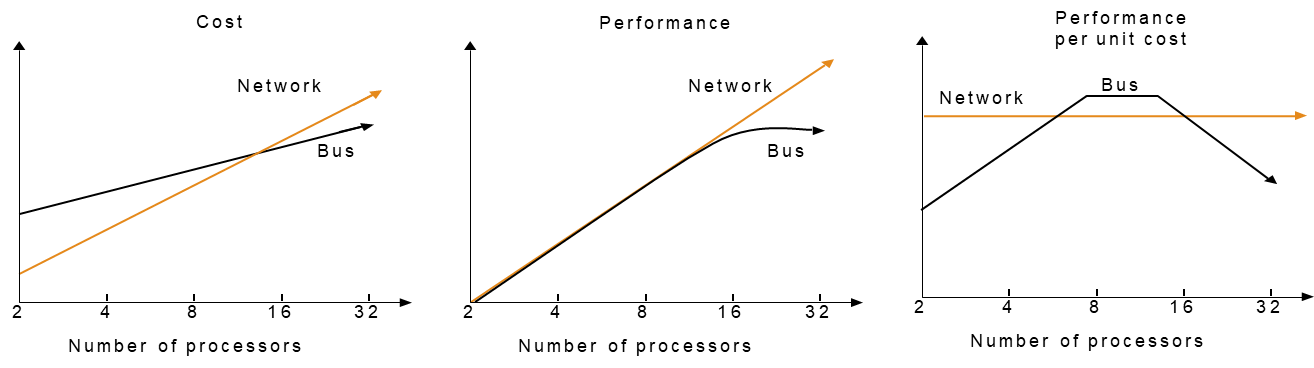
From a cost-performance perspective, there is a notable trade-off between single-bus and network-connected multiprocessor designs.
- Single-bus systems are generally less expensive and provide good performance for a limited number of processors. However, as the number of processors increases, the performance gains diminish due to bus saturation, leading to a flat performance curve. This results in what is often called a “sweet spot”, typically found between 8 and 16 processors, where the system achieves the best balance of cost and performance.
- Network-connected systems, while more expensive at the outset, scale more effectively with increasing numbers of processors. Their performance continues to grow linearly (or nearly so) as more nodes are added. Consequently, when evaluating systems either to the left or right of the sweet spot, network-connected multiprocessors tend to offer better performance per unit cost.
Architecture Comparison: Single-Bus vs. Network-Connected Multiprocessors
Feature Single-Bus Multiprocessors Network-Connected Multiprocessors Memory Organization Shared centralized memory Distributed local memory per processor Interconnect Single shared bus High-speed interconnection network Scalability Limited (typically up to 8–36 processors) High (scales to many processors/nodes) Communication All memory and interprocessor communication use the bus Communication via explicit network messages Contention/Bottleneck Bus becomes a bottleneck as processors increase Lower contention; network scales with nodes Cost Lower hardware cost for small systems Higher initial cost, better cost/performance at scale Programming Model Shared memory (easier programming) Often message passing (more complex) Typical Use Case Small to medium SMP systems Large-scale clusters, supercomputers
Network Topologies in Multiprocessor Systems
In the design of multiprocessor systems, the architecture of the interconnection network plays a pivotal role in determining overall system performance and scalability.
Definition
Network topology refers to the structural configuration through which processors (and their associated memory units) communicate.
While a fully connected network—where each node has a direct link to every other node—offers the best theoretical performance due to minimal communication latency and maximal bandwidth, such configurations are prohibitively expensive to implement in practice, especially as the number of processors increases.
At the other extreme lies the single-bus architecture, which is inexpensive but becomes a severe bottleneck when supporting many processors, due to contention for the shared medium.
Between these two extremes, a variety of topologies have been developed to provide trade-offs in cost and performance. These include the ring, mesh, hypercube, and crossbar topologies. Each presents a unique configuration of processor interconnects, leading to different communication patterns, hardware complexity, and network characteristics.
It is important to note that the interconnection network used for data transmission may differ from the one used for address transmission.
This separation can be exploited to optimize performance or reduce contention under specific architectural designs.
Interconnection networks are frequently modeled using graph theory. In these graphical representations:
- Nodes (often depicted as black squares) represent processor-memory pairs.
- Switches (represented as red circles) serve as intermediary routing elements, connecting processors to the network or to other switches.
- Arcs correspond to communication links, which are usually bidirectional, enabling data flow in both directions.
The cost of a network topology depends on several factors: the total number of nodes, the number of switches, the number of links, and the physical characteristics of the links (e.g., length, bandwidth).
Single-Bus and Ring Topologies
The single-bus topology remains the most elementary and cost-effective network. All processors communicate via a single shared bus, resulting in minimal hardware requirements.

However, this simplicity limits the network’s ability to scale, as only one transaction can occur on the bus at any time, leading to contention and performance degradation.
The ring topology, on the other hand, organizes nodes in a closed loop where each processor is connected to two neighbors.

This setup allows multiple simultaneous data transfers—akin to a segmented bus—thereby improving performance. Nonetheless, communication between non-adjacent nodes may require data to traverse through multiple intermediate nodes (a characteristic known as multi-hop communication), which can introduce latency and complexity in routing.
Evaluating Network Performance
Performance of interconnection networks is typically measured using two metrics: total network bandwidth (representing the best-case scenario) and bisection bandwidth (representing the worst-case scenario).
Let:
be the number of processor-memory nodes, the number of links, the bandwidth of a single link.
The total network bandwidth is calculated as
Bisection bandwidth is a more critical metric for understanding the worst-case communication scenario. It is computed by conceptually dividing the network into two halves and summing the bandwidth of the links that cross the dividing line.
- For a ring, the minimum number of links that must be cut is 2, hence its bisection bandwidth is
. - For a single bus, since there is only one bus to cross, the bisection bandwidth remains
.
| Total Bandwidth | Bisection Bandwidth | |
|---|---|---|
| Single Bus | ||
| Ring |
Some topologies are non-symmetric, meaning the choice of where to draw the bisection line significantly affects the result. To determine the worst-case bisection bandwidth in such cases, all possible divisions must be analyzed, and the minimum value selected.
Crossbar Network
The crossbar network offers a high-performance alternative by providing a dedicated communication path between every pair of processors. In such a network, each of the
The total bandwidth of a crossbar network is given by:
and the bisection bandwidth is:
For example, if
, then the total bandwidth is , and the bisection bandwidth is .
Bidimensional Mesh (2D Mesh)
A 2D mesh topology arranges processors in a square grid. Given
The total bandwidth of a 2D mesh is:
The bisection bandwidth, determined by cutting the mesh into two equal parts along one dimension, is:
Example
- For
( ): Total Bandwidth = , Bisection Bandwidth = . - For
( ): Total Bandwidth = , Bisection Bandwidth = .
Hypercube Network
The hypercube, or Boolean N-cube, is a topology where nodes are connected based on binary representations of their indices. A hypercube with
The number of links per switch is
The total bandwidth is given by:
and the bisection bandwidth is:
Example
- For
( ): Total Bandwidth = , Bisection Bandwidth = . - For
( ): Total Bandwidth = , Bisection Bandwidth = . - For
( ): Total Bandwidth = , Bisection Bandwidth = .
How do Parallel Processors Share Data?
In parallel computing systems, one of the most critical design considerations is how processors share and access data. This aspect directly influences system architecture, programming models, and performance characteristics. The mechanism by which processors access and exchange data is fundamentally governed by two conceptual models: the memory address space model and the physical memory organization. These two concepts are orthogonal, meaning they can be independently combined in various ways to suit different system requirements and performance trade-offs.
Memory Address Space Model
The memory address space model defines how memory is logically presented to the processors and how data access is performed at the software level. There are two primary paradigms: shared address space and private address spaces.
Shared Address Space
In systems based on a shared address space model, all processors operate within a single, logically unified memory space. This implies that any processor can access any memory location directly using standard load and store instructions. This model underlies shared memory architectures, where a specific physical address has the same meaning across all processors.
If processor 0x0040, they access the same memory location. This model greatly simplifies inter-processor communication since data can be exchanged by simply reading from and writing to shared memory regions. It also allows for tighter coupling between processes and supports implicit communication without the need for explicit coordination mechanisms.
Despite its conceptual simplicity, shared memory systems are not free of complexity. A significant challenge is the cache coherence problem. Since multiple processors may cache the same memory locations locally, updates made by one processor may not be immediately visible to others, leading to inconsistencies. Maintaining coherence across caches adds both hardware and protocol complexity.
Importantly, shared memory does not necessarily mean the memory is physically centralized.
The memory can be physically distributed across multiple nodes but logically presented as a unified address space.
Private Address Space
Systems based on private address spaces follow a message-passing model. In these systems, each processor has its own private memory, and the address spaces are disjoint — the same numerical address on two processors refers to completely separate memory locations. Inter-processor communication is achieved through explicit message passing, using primitives such as send and receive. The application or operating system is responsible for orchestrating the movement of data between processors.
Because no memory is shared, the message-passing model eliminates the cache coherence issue, simplifying hardware requirements. However, it demands more from the programmer (or software layer) in terms of communication management and synchronization.
Physical Memory Organization
Beyond how memory is logically accessed, systems also differ in how physical memory is structured and distributed. The two dominant approaches are centralized memory and distributed memory.
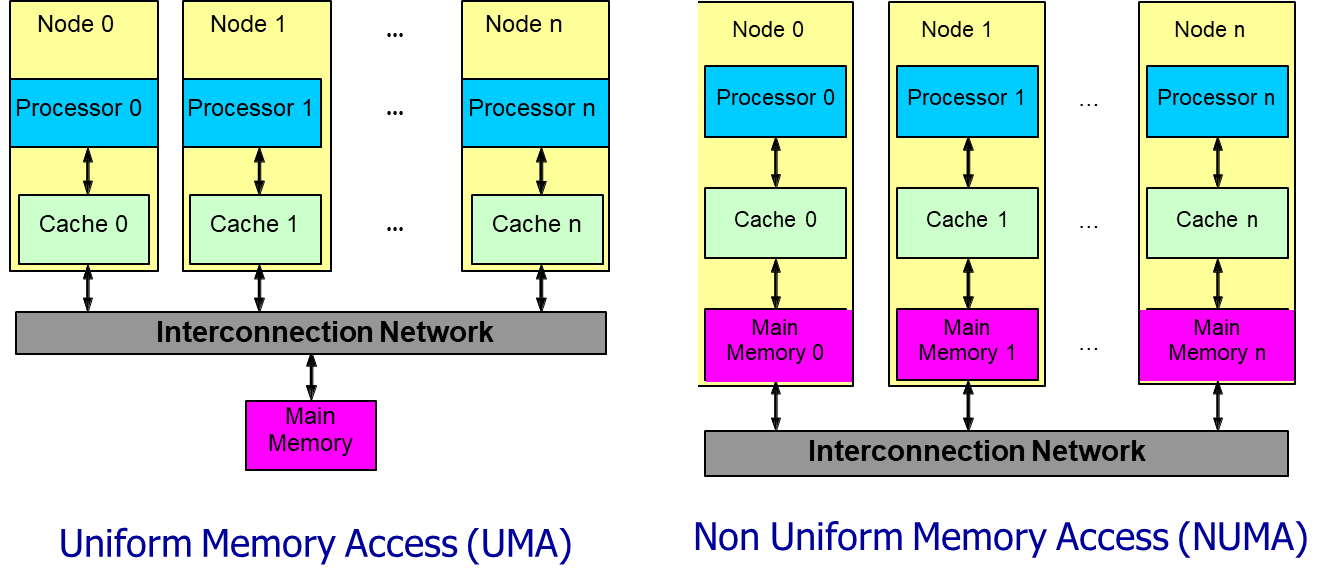
A centralized memory architecture typically follows the UMA (Uniform Memory Access) model. In this setup, all processors share a single physical memory pool, and the access time to any memory location is uniform across all processors. Regardless of which processor initiates a request or which memory address is targeted, the latency remains constant. This uniformity simplifies system behavior and is well-suited to systems with a small number of tightly coupled processors. However, centralized memory becomes a bottleneck as the number of processors increases, due to contention and limited bandwidth.
In contrast, a distributed memory architecture implements the NUMA (Non-Uniform Memory Access) model. Here, each processor is associated with its own local memory module, and the system interconnects these modules through a high-speed network. Accessing local memory is significantly faster than accessing remote memory located on a different processor. Thus, the access time to a given memory address depends on both the location of the data and the identity of the accessing processor. NUMA architectures scale better than UMA systems and are commonly used in large-scale multiprocessor designs. However, they require the software to be more aware of data locality in order to optimize performance and minimize remote memory access penalties.
Important
It’s important to note that the logical memory model (shared vs. private address space) and the physical memory organization (centralized vs. distributed) are independent choices.
- A system might, for instance, present a shared address space while physically distributing the memory (as in distributed shared memory systems).
- Alternatively, a system may use distributed private memory alongside explicit message passing.
The combination chosen will significantly influence programming models, memory management strategies, and achievable performance.
Multicore Single-Chip Multiprocessors
Most contemporary multicore processors are designed as single-chip systems with a relatively small number of cores, typically no more than 8. These cores are usually connected through a single bus and share a centralized memory architecture, resulting in what is known as Centralized Shared Memory (CSM) systems. These architectures are examples of Symmetric Multiprocessors (SMPs), where each core has equal access rights and latency to the memory subsystem. In such systems, memory access times are uniform across processors, a property known as Uniform Memory Access (UMA).
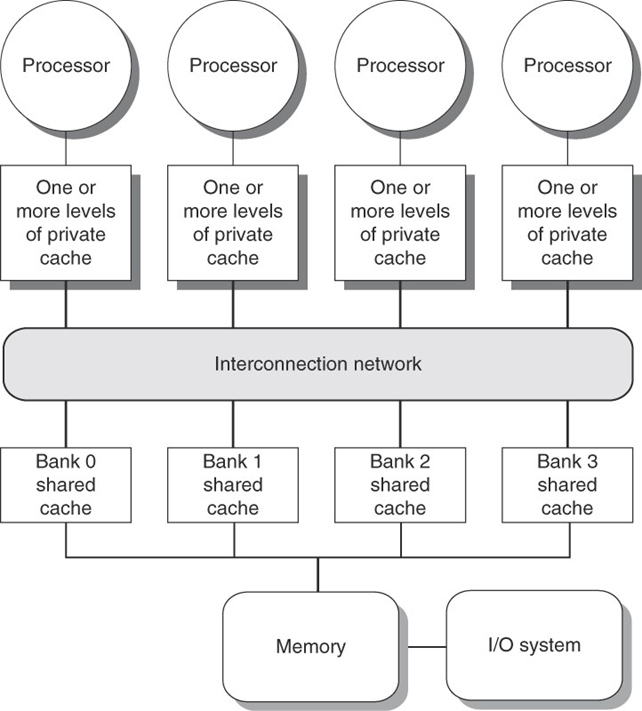
Cache coherence in SMPs is maintained through snooping protocols, which rely on broadcast-based mechanisms where all cores observe memory transactions to maintain a consistent view of memory. The cache hierarchy in SMP systems typically includes private L1 and L2 caches per core, and a shared L3 cache accessible to all processors. However, this centralized design faces scalability issues: as the number of cores increases beyond a certain threshold (commonly eight), the shared resources like the memory bus and centralized cache begin to act as performance bottlenecks due to contention.
To mitigate these issues, newer designs introduce interconnection networks and implement banked shared caches, where the memory or cache is divided into several independent banks to improve bandwidth and reduce contention. These designs attempt to retain UMA characteristics while scaling performance, allowing the architecture to support more cores effectively.
Distributed Shared Memory (DSM) Architectures
As systems scale up in core count (typically from 8 to 32 or more), Distributed Shared Memory (DSM) becomes a viable architecture to overcome the limitations of centralized shared memory. In DSM, each processor or node has its local memory module, but the address space is logically unified, creating a single global memory address space accessible by all processors. This setup introduces Non-Uniform Memory Access (NUMA) behavior: access latency varies depending on whether the data resides in the local memory or a remote node’s memory.
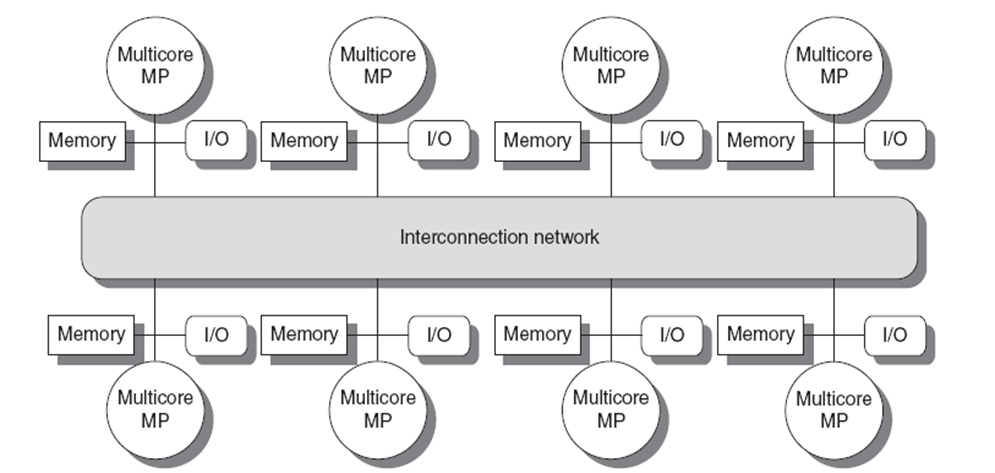
To maintain a consistent memory view across all processors in a NUMA system, cache coherence must be preserved even when memory is physically distributed. A common solution is the use of Cache-Coherent NUMA (CC-NUMA) architectures. These systems employ directory-based coherence protocols, which scale better than snooping approaches by avoiding broadcast traffic and managing coherence state through explicit message-passing.
In CC-NUMA, each node maintains a directory that tracks the coherence status of memory blocks. The directory contains metadata for each memory block, indicating whether the block is cached, which processors have a copy, and which processor, if any, has exclusive write ownership. Unlike snooping systems that rely on a shared bus, DSM systems employ a message-oriented protocol where coherence actions generate messages (e.g., read, write, fetch, invalidate) sent over an interconnection network, allowing better scalability and reduced contention.
Distributed Memory Architectures
Distributed memory architectures take the decentralization of memory even further. Instead of sharing a unified address space, these systems are built from clusters of independent computers, each equipped with its own private memory and processing unit. These nodes communicate by exchanging messages across a scalable interconnection network. This design is at the core of message-passing architectures, which are especially effective in large-scale distributed computing environments such as high-performance clusters and supercomputers. Unlike DSM systems that maintain a global address space, distributed memory systems require explicit communication primitives—typically implemented using libraries such as MPI (Message Passing Interface)—to coordinate tasks and exchange data among nodes.
The key strength of distributed memory systems lies in their scalability. Because memory is not shared, contention for memory resources is avoided, and systems can be scaled up by simply adding more nodes. However, this comes at the cost of more complex programming models, as developers must manually handle data distribution and synchronization.
Communication Models
Parallel computing frameworks are categorized based on how processors communicate and synchronize their operations.
- Multiprogramming is the simplest model, where multiple independent jobs run concurrently on separate processors without any direct interaction. This model is straightforward but lacks the flexibility needed for tightly-coupled parallel algorithms.
- Shared address space models allow all processors to access a common memory space, simplifying programming but requiring careful synchronization.
- Message-passing models emphasize explicit communication between processors through defined
sendandreceiveoperations. This model is foundational in distributed memory systems, where no physical memory is shared, and all inter-process communication must occur over the network. Message passing offers better scalability and control over communication patterns, making it suitable for large-scale systems. - Data parallelism is a specialized paradigm where multiple processors operate on different portions of a data set simultaneously. These processors execute the same operation in parallel across the data segments and then exchange results either through shared memory or message passing. Architectures based on this model, such as SIMD (Single Instruction, Multiple Data), are particularly effective for vectorized computations and applications in scientific computing and machine learning.
Parallel processing faces key challenges that must be tackled to unlock the full potential of multiprocessor systems. A major hurdle is that most programs aren’t inherently designed for parallel execution, requiring significant restructuring by compilers or programmers to introduce independent computations and optimize execution flow.
Another critical issue is the high cost of inter-core communication, particularly when memory access is involved. Delays range from 35–50 clock cycles within a single chip and can exceed 100–500 cycles across different chips or sockets. These latencies can severely impact performance, especially in applications with frequent data sharing.
Shared Memory Model
In the shared memory model, multiple processors operate within a single, globally accessible address space. Processors communicate implicitly by reading and writing to shared memory locations. This model benefits from hardware-supported cache coherence, ensuring that all processors see consistent views of shared data. It simplifies programming since developers can use standard memory operations to exchange information.
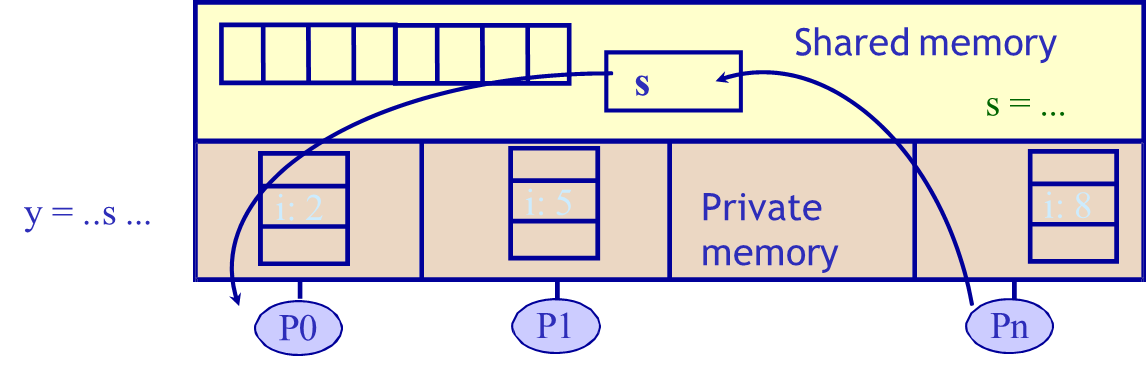
Shared memory architectures are especially effective in small to medium-scale multicore processors due to their low communication latency and straightforward hardware-controlled caching mechanisms.
Each thread in this model possesses private variables such as local stack data, while sharing common variables like global or static data. Threads coordinate their activities by synchronizing on shared variables, using synchronization primitives such as locks, semaphores, or barriers.
Despite its ease of use, the shared memory model faces scalability challenges as the number of processors increases, primarily due to synchronization overhead and difficulties in managing efficient data placement within caches to avoid contention and bottlenecks.
Message Passing Model
The message passing model structures computation as a collection of independent processes, each with its private local memory. There is no shared global memory, and all communication must be performed explicitly through message exchanges, typically using send and receive operations. This explicit communication model reduces hardware complexity because it does not require global cache coherence. It also encourages programmers to think carefully about data locality and communication costs since all data transfers are visible in the program.
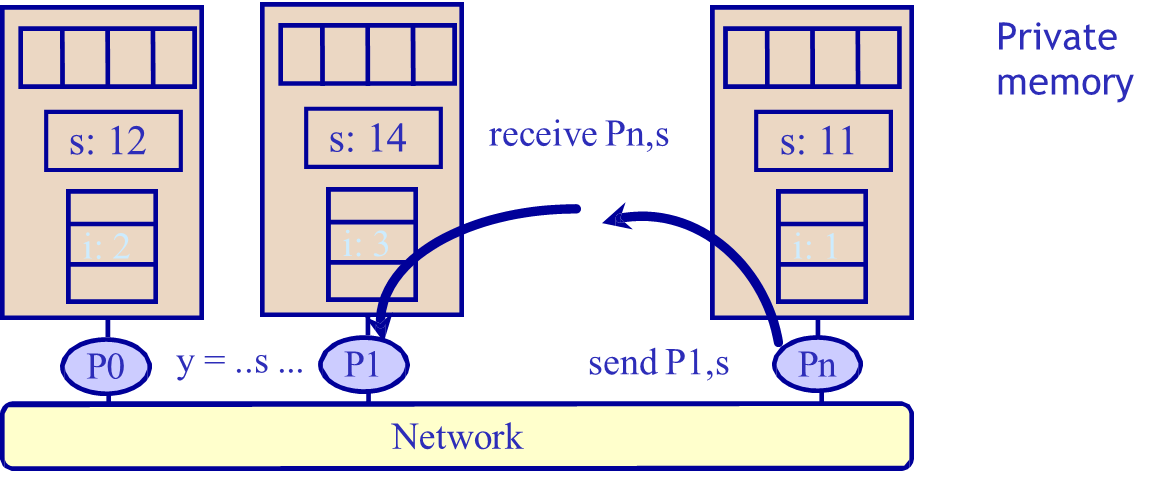
Processes generally start at program initialization and maintain their distinct address spaces. Coordination is implicitly built into the communication events themselves, ensuring that synchronization occurs naturally during message exchanges.
The Message Passing Interface (MPI) is a widely adopted software standard for implementing this model. While message passing offers advantages in controlling data placement and simplifying hardware design, it introduces higher communication overhead and programming complexity. Additionally, mechanisms for receiving messages—whether by interrupt-driven or polling methods—must be carefully managed to maintain performance and responsiveness.
Data Parallel Model
The data parallel model is another influential paradigm, emphasizing the simultaneous execution of operations on large, regular data structures such as arrays or matrices. In this model, a control processor broadcasts instructions to numerous replicated processing elements (PEs), each responsible for a partition of the data. Each PE may include condition flags that allow it to skip operations based on control flow decisions, adding flexibility to the model. This approach has its roots in the early 1980s with the resurgence of SIMD (Single Instruction Multiple Data) architectures, driven by advances in VLSI technology.
Data parallel programming languages are designed to map data layouts onto processor architectures efficiently, and the SIMD model naturally evolved into the Single Program Multiple Data (SPMD) programming model. Under SPMD, all processors execute the same program but operate on different pieces of data, enabling massive parallelism with uniform instruction streams. These languages and models facilitate communication patterns where all processors synchronize at global barriers before proceeding to the next phase of computation. This “bulk synchronous” approach helps coordinate data exchanges and computation, ensuring consistency and reducing synchronization overhead.