Modern computer systems aim to provide programmers with an abstraction of virtually unlimited memory that operates at high speed. However, this ideal is constrained by physical and economic limitations. Fast memory technologies, such as Static Random Access Memory (SRAM), offer low latency but are significantly more expensive per bit than slower alternatives like Dynamic Random Access Memory (DRAM). To reconcile this disparity between speed and cost, computer architects design memory systems based on a hierarchical structure.
At the heart of this hierarchy lies the concept that the entire addressable memory space is stored in the largest and slowest memory, typically DRAM or disk storage. Above this foundational level, progressively smaller and faster memory layers—such as various levels of cache (L1, L2, L3)—are placed. These higher-speed memories act as buffers, each storing subsets of the data held in the larger, slower memory beneath it. The effectiveness of this structure is largely attributed to the principles of temporal localityand spatial locality.
Classification and Implications
When data requested by the processor is not found in the cache, a cache miss occurs. Cache misses are a critical factor in system performance, and understanding their types is essential for optimizing memory access. Cache misses are traditionally classified into three main categories: compulsory, capacity, and conflict misses.
-
Compulsory misses, also known as cold start or first reference misses, occur the first time a block of memory is accessed and thus has never been loaded into the cache before. These misses are inevitable, as no cache—no matter how large—can preemptively store data that has never been referenced.
-
Capacity misses arise when the cache does not have enough space to hold all the blocks needed during a particular phase of program execution. When the working set of a program exceeds the total cache capacity, blocks must be evicted and later reloaded, leading to these types of misses. Increasing the cache size can help mitigate capacity misses, though this comes at the cost of more area and power consumption.
-
Conflict misses, sometimes referred to as collision or interference misses, occur when multiple blocks compete for the same cache location due to a restrictive placement policy, such as in direct-mapped or set-associative caches. Even if the cache has enough total capacity, conflict misses can happen if blocks map to the same index and displace each other. Increasing the associativity of the cache—i.e., allowing blocks to be stored in multiple locations—can reduce these misses.
| Compulsory misses | Capacity misses | Conflict misses | |
|---|---|---|---|
| Direct Mapped Cache | Occur normally for first-time access to blocks. Cannot be avoided. | High likelihood if cache size is too small for the working set. | Very frequent due to strict mapping of multiple blocks to the same line. |
| Set Associative Cache | Similar to direct-mapped; occur at first access. | Can still occur if the total cache size is too small. Less likely than in direct-mapped. | Reduced compared to direct-mapped; multiple slots per set reduce likelihood of mapping collisions. |
| Fully Associative Cache | Still present on first access, cannot be avoided. | Can occur if total number of blocks is insufficient for the working set. | Virtually eliminated as any block can go anywhere—no fixed mapping prevents conflicts. |
In multiprocessor systems, an additional category called coherence misses becomes relevant. These are caused by the mechanisms used to maintain cache coherence across multiple processors. When one processor updates a shared memory block, other caches must invalidate or update their copies, which can lead to misses in those caches the next time they access the block.
Strategies to Enhance Cache Performance
AMAT
The performance of a cache is typically evaluated using the Average Memory Access Time (AMAT), defined by the formula:
where, hit time refers to the time it takes to access data found in the cache, miss rate is the fraction of memory accesses that result in a miss, and miss penalty is the additional time required to fetch data from the next lower level of the memory hierarchy.
Improving cache performance, therefore, involves optimizing each term of the AMAT equation:
- Reducing the miss rate can be achieved by increasing cache size, improving associativity, or leveraging advanced prefetching techniques that anticipate future data needs based on access patterns.
- Reducing the miss penalty often involves optimizing the speed of lower memory levels or using techniques like early restart and critical word first, which aim to return necessary data to the processor before the entire block is fetched.
- Reducing the hit time requires careful design of the cache architecture, such as reducing lookup latency and simplifying access paths.
Cache Optimization Summary
Technique Miss Rate Miss Penalty Hit Time Complexity Larger block size ✔️ ✖️ 0 Higher associativity ✔️ ✖️ 1 Victim cache ✔️ 2 Pseudo-associativity ✔️ 2 Hardware prefetching ✔️ 2 Compiler prefetching ✔️ 3 Compiler reduced misses ✔️ 0 Read priority ✔️ 1 Sub-block placement ✔️ ✔️ 1 Early restart ✔️ 2 Non-blocking caches ✔️ 3 Second-level cache ✔️ 2 Small simple cache ✖️ ✔️ 0 Avoid address translation ✔️ 2 Pipeline writes ✔️ 1
Reduce the Miss Rate
Reducing the cache miss rate is a key strategy for enhancing memory system performance in modern computer architectures. A lower miss rate means fewer accesses to slower memory levels, which in turn leads to better average memory access times.
0. Increasing Cache Capacity
One of the most straightforward ways to reduce capacity misses is by increasing the total size of the cache. With more storage available, a greater number of memory blocks can be held simultaneously, which reduces the likelihood that a needed block will be evicted prematurely.
However, this strategy is not without trade-offs. A larger cache inevitably increases the hit time, as more bits must be accessed and searched. Additionally, it consumes more silicon area, leads to higher power consumption, and raises manufacturing costs.
1. Enlarging Cache Block Size
Another approach is to increase the block size, or the amount of contiguous memory fetched into the cache on a single miss. Larger blocks can reduce compulsory misses, which occur during the first access to a memory block, by taking advantage of spatial locality—the principle that nearby memory locations are likely to be accessed soon after one another.
However, excessively large blocks can introduce new problems. They increase the miss penalty, since more data must be fetched from lower memory levels, and they decrease the number of blocks the cache can hold. This reduced number of blocks can lead to higher conflict and even capacity misses, especially in smaller caches where storage space is already limited.
2. Increasing Cache Associativity
To specifically target conflict misses, designers can increase the associativity of the cache.
- In a direct-mapped cache, each memory block maps to a single cache line, making it prone to conflicts when multiple blocks compete for the same location.
- In contrast, set-associative caches allow a block to be placed in any one of several lines (or “ways”) within a set, thereby reducing the likelihood of conflicts.
- A fully associative cache, where a block can go anywhere, eliminates conflict misses altogether, but is impractical for large caches due to its high cost and complexity.
Even modest increases in associativity can improve performance, though diminishing returns apply. The 2:1 Cache Rule is a heuristic that states a direct-mapped cache of size
Multibanked Cache Architecture
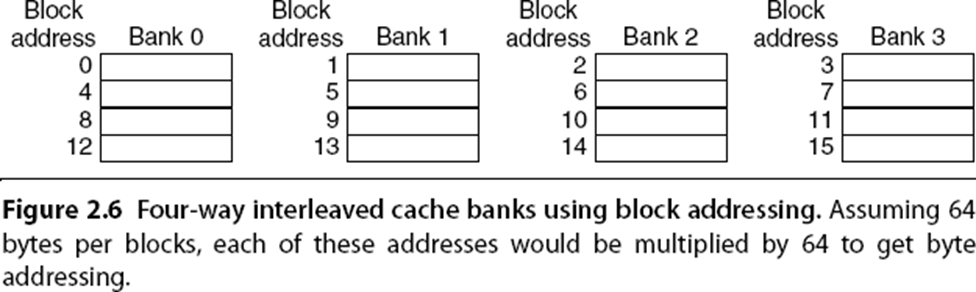
A related design technique is the use of multibanked caches, which aim to improve bandwidth and parallelism in memory accesses. By organizing the cache into independently accessible banks, the system can support multiple simultaneous accesses, increasing throughput without necessarily increasing associativity in the traditional sense. Banks are typically interleaved based on block addresses to ensure a uniform distribution of accesses.
Example
For example, the ARM Cortex-A8 processor allows between one and four banks in its L2 cache, while the Intel i7 uses four banks in L1 and up to eight banks in L2. This architecture helps alleviate contention and allows better utilization of the cache’s bandwidth under high-load conditions.
3. Victim Cache as a Buffer

To address both conflict and capacity misses, some systems implement a victim cache, a small fully associative cache placed between the primary cache and the next lower level in the memory hierarchy. When a block is evicted from the main cache, it is stored temporarily in the victim cache. On a subsequent miss, the system first checks this victim cache before proceeding to the lower memory levels. If the block is found there, a block swap occurs between the main and victim cache, exploiting temporal locality. This strategy effectively gives a “second chance” to recently evicted data and is particularly beneficial in workloads with frequent data reuse.
4. Pseudo-Associativity and Way Prediction
Some processors employ way prediction or pseudo-associativity techniques to combine the speed of direct-mapped caches with the reduced conflict miss rate of associative caches. In way prediction, used in set-associative caches (e.g., 2-way set associative), additional bits are maintained to predict which “way” of a set is more likely to contain the requested block. If the prediction is accurate, the access proceeds with minimal delay. If the prediction is incorrect, the system must check the other way, incurring a pseudo-hit time—slower than a normal hit but faster than a full miss.

In pseudo-associative caches, typically based on a direct-mapped structure, the cache is logically divided into two banks. The system first checks one bank; if the block is not found, it checks the second bank before declaring a miss. If the block is found in the second bank, this is called a pseudo-hit. While slower than a regular hit, it is significantly faster than accessing the next memory level. This design offers a compromise between hit time and miss rate without incurring the full complexity of set-associative caching.
5. Hardware-Based Pre-fetching of Instructions and Data
Hardware pre-fetching is a dynamic technique that exploits the spatial and temporal locality of instruction and data access patterns. The central idea is to fetch not only the currently requested memory block but also additional nearby blocks that are likely to be accessed soon. This anticipatory strategy is particularly useful for sequential or predictable memory access patterns.
Example
A classic example is the Alpha AXP 21064 processor, which implements instruction pre-fetching by fetching two consecutive instruction blocks on a cache miss. Specifically, when block
is requested and not found in the instruction cache, the processor retrieves both block and block . The requested block is placed into the instruction cache, while the next block is stored in a dedicated instruction stream buffer (I-stream buffer). If a subsequent access misses the cache but hits in the stream buffer, the data can be retrieved much faster than from main memory. Additionally, the pre-fetch mechanism continues by fetching block , maintaining a pipeline of anticipated accesses.
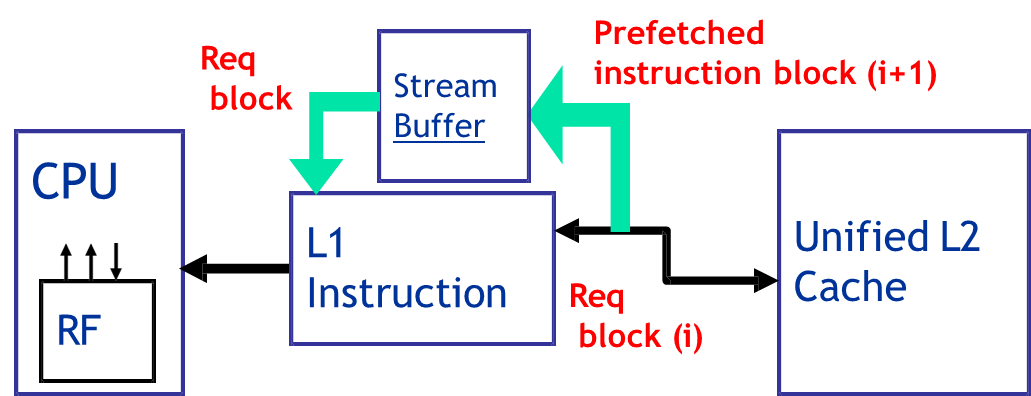
For data pre-fetching, a similar mechanism is employed through the use of a data stream buffer (D-stream buffer). Early research by Jouppi (1990) demonstrated that a single stream buffer could eliminate approximately 25% of misses in a 4KB data cache. Later studies by Palacharla and Kessler (1994) extended this by showing that for scientific applications, using up to 8 stream buffers could capture between 50% and 70% of the misses in large, 64KB, 4-way set associative caches.
The effectiveness of hardware pre-fetching hinges on the availability of spare memory bandwidth, which is essential for transferring additional data without interfering with regular demand accesses. If pre-fetching saturates the available bandwidth or interferes with cache replacement policies, it can paradoxically degrade performance instead of enhancing it.
6. Software-Controlled Pre-fetching
In software-based pre-fetching, the compiler explicitly inserts pre-fetch instructions into the program code. These instructions direct the processor to load data into registers or cache lines before they are needed by the execution logic, based on compile-time analysis of data access patterns.
Two primary forms of software pre-fetching exist.
- Register pre-fetching, where data is loaded directly into registers. This is supported by architectures like HP PA-RISC.
- Cache pre-fetching, in which data is fetched into the cache, typically using specific instructions available in ISA extensions such as those in MIPS IV, PowerPC, and SPARC v9.
Although software pre-fetching introduces instruction overhead, which consumes CPU resources and bandwidth, this cost is often offset by the reduction in cache misses. In highly superscalar architectures, where multiple instructions can be issued per cycle, this overhead can be amortized more effectively, making software pre-fetching a viable and powerful optimization.
7. Compiler Optimizations for Cache Performance
Beyond pre-fetching, compiler-level transformations can be employed to restructure programs in ways that better exploit the behavior of the memory hierarchy. These optimizations typically rely on profiling data—information gathered about how a program accesses memory during execution.
One foundational study by McFarling (1989) showed that by using profiling information, software could be optimized to reduce cache misses by up to 75% on small, direct-mapped caches. Several specific techniques fall under this umbrella:
-
Instruction Reordering is a strategy in which instructions are rearranged in memory to reduce conflict misses. By analyzing instruction access patterns, the compiler can group together instructions that are frequently accessed together, reducing the chance of eviction due to conflicts in set-associative caches.
-
Merging Arrays is a method to improve spatial locality by combining multiple arrays into a single structure. For instance, instead of using two separate arrays for
val[]andkey[], a single array of structures, such asstruct { int val; int key; }, ensures that related data is stored in contiguous memory locations. This improves the chance that both values are loaded into the cache together, minimizing separate memory accesses. -
Loop Interchange targets multidimensional arrays and reorders nested loops to access memory in the order it is laid out. For example, in row-major storage (as used in C), accessing rows sequentially leads to more cache-friendly behavior than accessing columns. Swapping the order of loops ensures that cache lines are fully utilized before being replaced.
-
Loop Fusion enhances spatial locality by merging adjacent loops that iterate over the same data structures. This reduces the number of times data is loaded into and evicted from the cache. By combining multiple passes over data into a single loop, the likelihood of reusing data in cache before it is evicted increases significantly.
-
Loop Blocking, or tiling, is an advanced optimization that enhances temporal locality. It breaks down large loops that operate over matrices or arrays into smaller blocks, or tiles, that fit into the cache. By repeatedly operating on these smaller sub-blocks, data stays in the cache longer and is reused more effectively. The blocking factor (often denoted
) is carefully chosen based on the cache size and data layout to optimize performance.
Reduce the Miss Penalty
Reducing the miss penalty is a critical strategy in optimizing memory performance within a memory hierarchy. When a cache miss occurs, the time required to retrieve data from the next level of memory or from main memory introduces delays in the processor’s execution. Various hardware and architectural techniques have been developed to mitigate this latency and improve overall system efficiency.
1. Prioritizing Reads Over Writes on a Miss
A common technique to reduce the penalty of a miss is to give read requests a higher priority than write operations. This is based on the observation that read operations are usually on the critical path of execution, while writes can be buffered and delayed. In this approach, the system uses a write buffer that temporarily holds data waiting to be written to memory. By sizing the buffer appropriately—usually larger than conventional designs—it can hold more pending writes and reduce contention.
However, this prioritization can introduce complexity. One key issue is the possibility of read-after-write (RAW) hazards. For instance, if a read miss targets a memory location whose updated value is still in the write buffer, returning the old value from memory would cause incorrect behavior. To manage this, the system must check the write buffer for potential conflicts before servicing a read miss. If no conflict exists, the read proceeds immediately. Otherwise, the read must stall until the write buffer is flushed, which can diminish the intended performance gains.
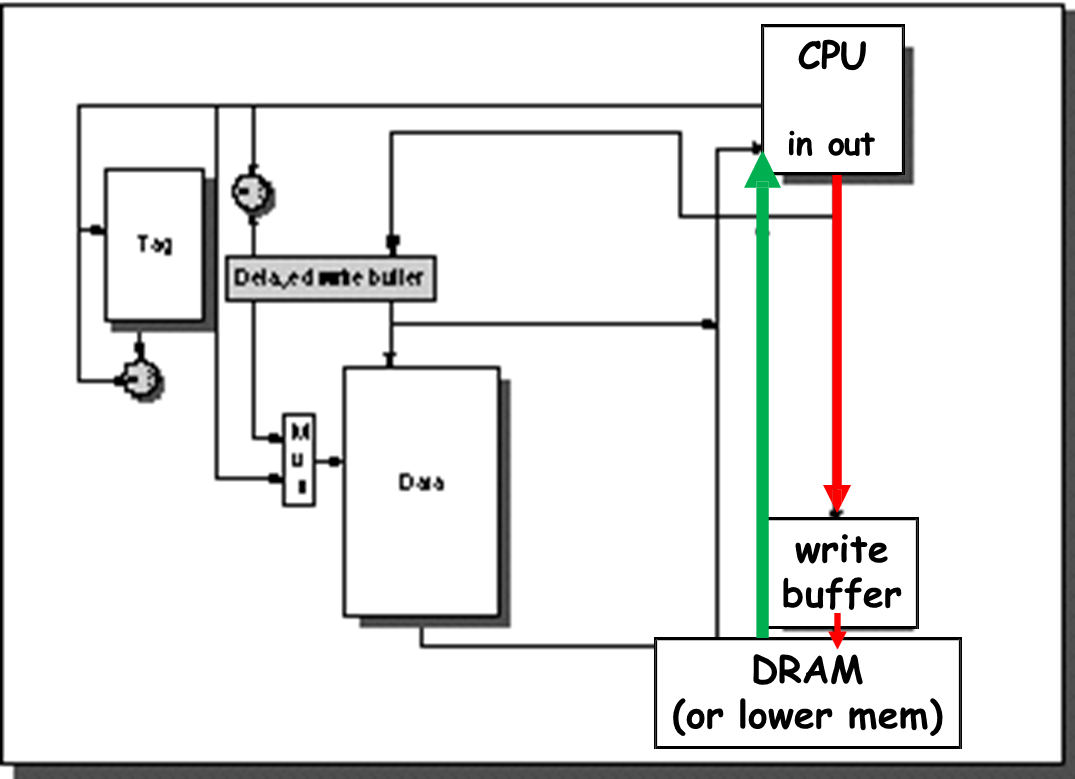
A related enhancement is used in write-back caches, where if a dirty block must be evicted on a read miss, instead of writing it back to memory first, the system copies the dirty block into the write buffer. This enables the cache to immediately serve the new read request and delays the memory write until later, thus reducing CPU stall time.
2. Sub-block Placement for Partial Transfers
Another technique to reduce miss penalties involves sub-block placement, where only the portion of a cache block (a sub-block) that is actually needed is fetched on a miss. This avoids transferring and filling the entire block from memory, which is beneficial when memory bandwidth is constrained.
However, this approach typically requires maintaining valid bits for each sub-block to indicate whether the data is valid. A major drawback is the reduced ability to exploit spatial locality since not all adjacent data is fetched, which may lead to future misses if the neighboring data is accessed shortly afterward.
3. Early Restart and Critical Word First
Often, when a cache miss occurs, the CPU only requires one word from the missed block to proceed with execution. Instead of waiting for the entire block to be fetched, the early restart technique allows the CPU to resume execution as soon as the required word is returned. In this case, the remaining words are fetched and filled into the cache in the background.
An enhancement of this idea is critical word first, where the memory system requests the required word first, regardless of its position in the block. This method ensures that the most immediately useful data reaches the CPU as early as possible. This approach is particularly advantageous when dealing with large cache blocks, where waiting for all data would introduce significant delays. However, its benefits are diminished when the CPU is likely to access other words in the block soon after, due to spatial locality. Hence, the effectiveness of early restart and critical word first strategies depends heavily on the access patterns of the workload.
4. Non-blocking (Lockup-Free) Caches
To improve performance during a cache miss, non-blocking caches, also known as lockup-free caches, allow the cache to continue processing subsequent hits even while a miss is being serviced. This is referred to as hit under miss. It permits the CPU to keep fetching instructions or accessing data that result in cache hits while waiting for the missed data to arrive. This capability is particularly beneficial in out-of-order execution architectures, where the processor can continue executing independent instructions that are not waiting on the missed data.
A more advanced variant is miss under miss, where the cache can handle multiple outstanding misses simultaneously. This requires sophisticated hardware support, such as multiple memory banks to avoid access conflicts and an advanced cache controller capable of managing several concurrent memory operations.
5. Second-Level Cache (L2)
A widely used architectural improvement for reducing miss penalties is the addition of a second-level cache (L2). The L1 cache, being small and fast, is designed to operate at the same clock speed as the CPU. However, its small size limits its ability to store data. The L2 cache, being larger and slower, sits between the L1 cache and the main memory, capturing many accesses that would otherwise go to main memory.
The effectiveness of the L2 cache in reducing miss penalty can be quantified using the Average Memory Access Time (AMAT), expressed as:
Thus, the L2 cache reduces the number of accesses to main memory and the associated high latency. An important distinction is made between local miss rate, which measures the fraction of accesses that miss in L2 given L1 misses, and global miss rate, which measures how often memory accesses from the CPU go all the way to main memory. Ultimately, reducing the global miss rate has the most significant impact on system performance.
This concept of a multi-level memory hierarchy can be extended further by introducing additional levels (L3, L4, etc.) in high-performance systems, thereby continuing to reduce access times for cache misses.
6. Merging Write Buffers
Another technique to improve performance in write-intensive applications is merging write buffers. Instead of requiring a separate buffer entry for each word written to memory, modern write buffers can merge multiple words from different addresses into a single buffer entry. This reduces the chance that the buffer fills up and stalls the CPU.
Reduce the Hit Time
Cache hit time is a fundamental performance metric in processor design. It refers to the time it takes to access data from the cache once a request hits. Lowering hit time is essential for improving CPU performance, particularly for L1 caches that are accessed most frequently.
1. Fast Hit Time Using Small and Simple L1 Caches
One of the most effective ways to reduce cache hit time is to design the L1 cache to be both small in size and structurally simple. This is the approach taken by processors like the Alpha 21164, which features separate 8KB instruction and 8KB data caches in the L1 stage, complemented by a larger 96KB L2 cache. The compact size of the L1 cache allows it to operate at the full speed of the CPU clock without introducing significant latency.
These caches are typically direct-mapped, meaning each block in memory maps to exactly one location in the cache. Direct-mapped caches are faster than set-associative or fully-associative caches because they allow overlapping the tag comparison and data transmission processes. When the requested address is provided, the system can simultaneously access the tag memory and retrieve the associated data, then verify the match with minimal delay. This simple organization also results in lower power consumption, since fewer cache lines need to be activated per access.
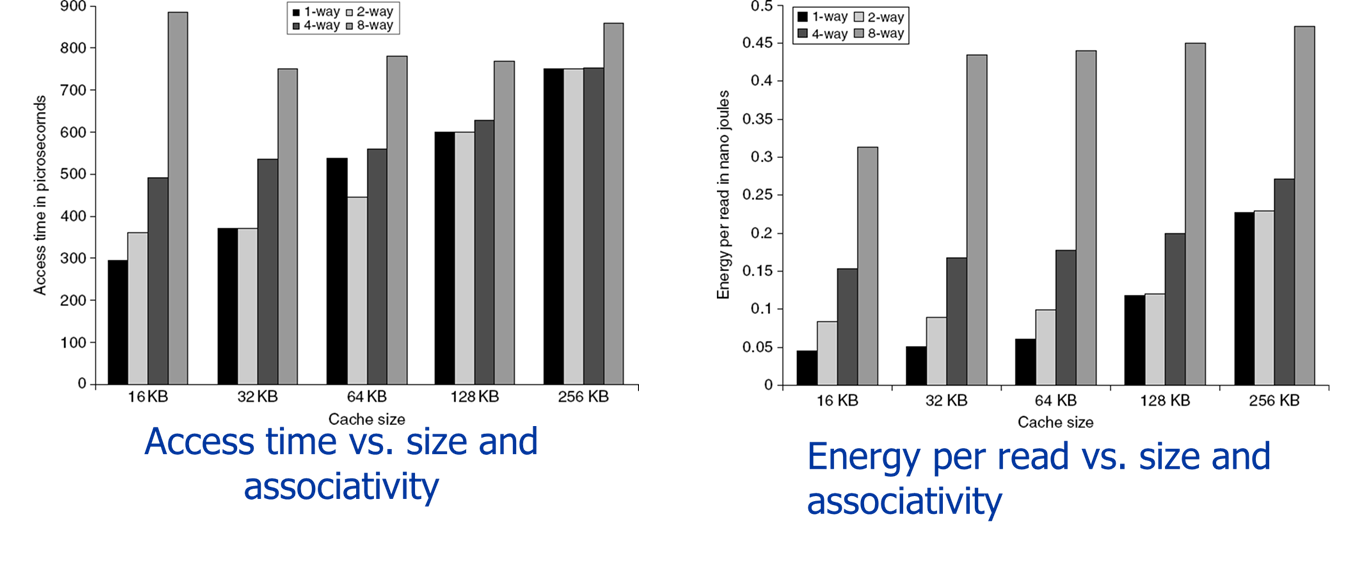
However, the trade-off of small and direct-mapped L1 caches is a potentially higher conflict miss rate due to limited associativity.
2. Reducing Hit Time by Avoiding Address Translation
Another major source of delay in cache access is address translation, which converts virtual addresses (used by applications) into physical addresses (used by hardware). If a cache must wait for this translation before accessing data, the hit time increases. To eliminate this delay, virtually addressed caches—also called virtual caches—are designed to accept virtual addresses directly.
While this technique accelerates cache access, it introduces its own challenges.
- Cache flushing: When a context switch occurs, the cache may contain data from the previous process that is no longer valid for the new process. This necessitates flushing the cache to ensure that only relevant data is accessed, which can introduce additional latency.
- Address aliasing: This occurs when two different virtual addresses map to the same physical address. If both addresses are cached, it can lead to inconsistencies and coherence issues, as the cache may not be able to distinguish between the two.
An alternative and more robust strategy is to index the cache using the physical portion of the virtual address. In this scheme, the system begins tag lookup in parallel with the address translation. Because indexing is done using bits that do not change after translation, cache access and translation can proceed concurrently. However, this approach restricts cache size to the page size of the virtual memory system, limiting scalability. To support larger caches, designers often use higher associativity, which relaxes the index constraint but increases access time.

3. Pipeline Optimization for Writes
A powerful architectural improvement to accelerate writes is the use of pipelining within the cache access mechanism. Specifically, the system separates the tag comparison and cache update stages into different pipeline stages. This technique allows a new write operation to begin its tag check while a previous write completes its data update, increasing throughput without sacrificing correctness.
This approach often includes a delayed write buffer, which temporarily stores the data to be written. During a read, the system must check this buffer to ensure that the most recent data is returned, not stale data from the main cache. While this mechanism increases the complexity of the cache controller, it helps maintain low hit times under high memory traffic.
4. Efficient Write-through Using Sub-blocks
For write-through caches, in which every write to the cache is immediately reflected in main memory, hit time can be further reduced by using sub-blocking. In this design, each block in the cache is divided into smaller sub-blocks, often the size of a single word. When most writes affect only one word, this organization allows the system to update the sub-block and its tag instantly without waiting for the rest of the block.
This strategy relies on maintaining valid bits for each sub-block, which indicate whether the sub-block contains up-to-date data. If the tag matches and the valid bit is already set, the system can proceed with the write immediately. If the tag matches but the valid bit is not set, the write operation itself is enough to mark the sub-block as valid. If the tag does not match, it is treated as a cache miss. In a write-through system, this does not pose a risk because the main memory always holds the latest copy of the data.
However, this mechanism is not compatible with write-back caches, where the cache alone holds the most recent data until it is written back to main memory. In such cases, modifying part of a block without properly handling the rest of it could result in inconsistent or lost data.