Compiler transformations and register renaming are essential techniques used to mitigate Write After Read (WAR) and Write After Write (WAW) hazards. These hazards often occur during instruction execution due to data dependencies or resource conflicts, particularly in pipelined processors. While the Tomasulo algorithm employs dynamic register renaming using reservation stations to handle these hazards at runtime, compilers can apply static transformations to achieve similar results. By applying techniques such as register renaming and loop unrolling, compilers can optimize the instruction sequence and enhance instruction-level parallelism (ILP).
Register Renaming and Loop Unrolling
Definition
Register renaming is a process where logical registers specified in the code are dynamically (or statically) mapped to a larger set of physical registers. This mapping prevents false dependencies caused by register reuse.
When combined with loop unrolling, where multiple iterations of a loop are executed within a single iteration of the unrolled loop, the compiler can further reduce stalls caused by data hazards.
Consider the following example in assembly language that represents a loop performing load, multiply, and store operations:
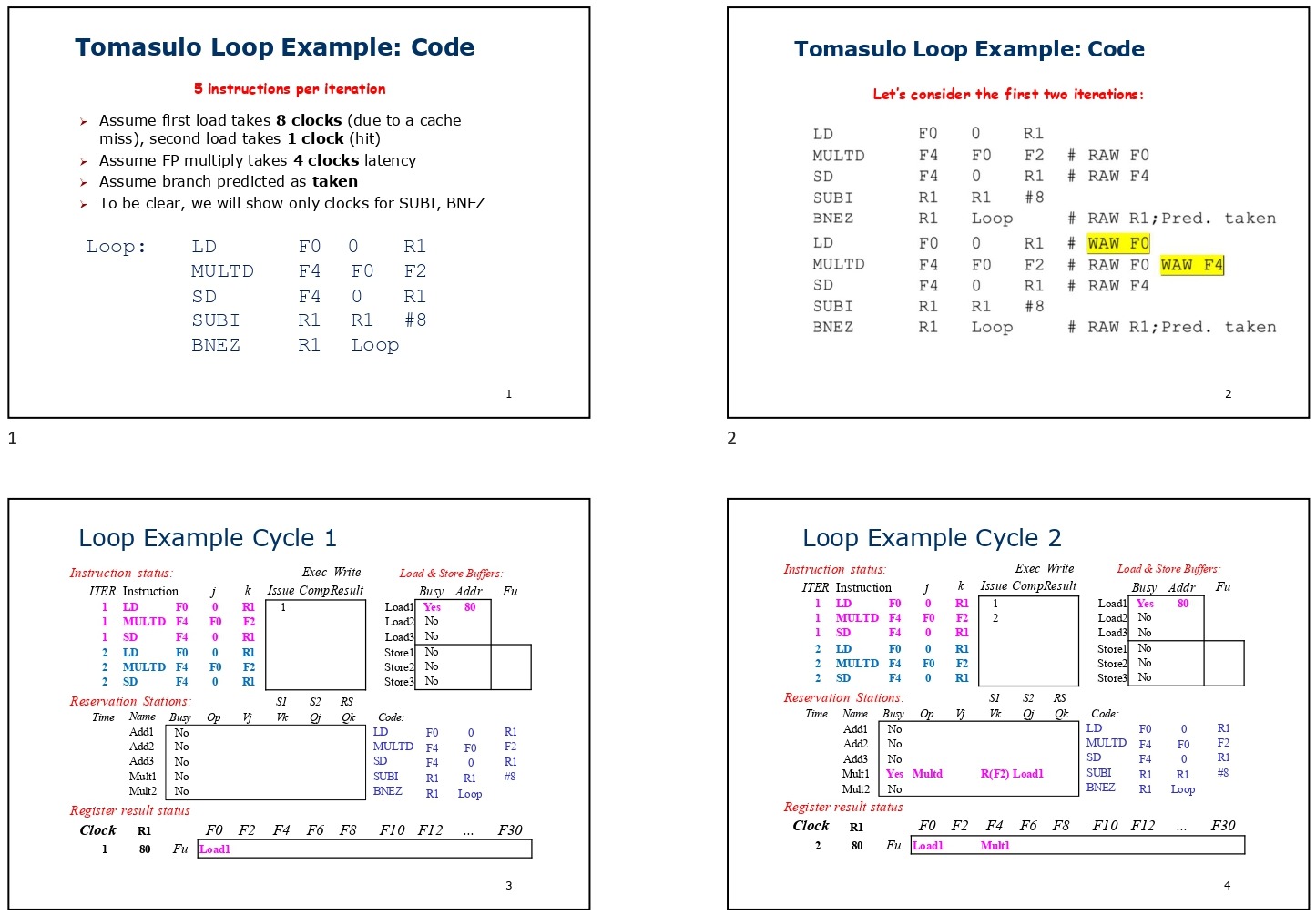
Loop: LD F0, 0(R1)
MULTD F4, F0, F2 # RAW hazard on F0
SD F4, 0(R1) # RAW hazard on F4
SUBI R1, R1, #8
BNEZ R1, Loop # RAW hazard on R1; Predict takenIn this case, read-after-write (RAW) hazards occur due to the dependency on register F0 for both the MULTD and SD instructions. Additionally, since the loop involves writing to F4 in each iteration, it may lead to write-after-write (WAW) hazards when multiple instructions attempt to write to the same register before it is read.
Eliminate WAW and RAW Hazards
To address these hazards, the compiler can apply loop unrolling by executing 4 iterations of the loop simultaneously, while using register renaming to ensure that no 2 instructions write to the same registers. By assigning unique registers for each iteration’s results, both WAW and RAW hazards are avoided. The modified loop looks like this:
Loop: LD F0, 0(R1)
MULTD F4, F0, F2
SD F4, 0(R1)
LD F6, -8(R1) # -8(R1) = 0(R1) - 8
# where 8 is the size of the data
MULTD F8, F6, F2
SD F8, -8(R1)
LD F10, -16(R1) # -16(R1) = -8(R1) - 8
MULTD F12, F10, F2
SD F12, -16(R1)
LD F14, -24(R1) # -24(R1) = -16(R1) - 8
MULTD F16, F14, F2
SD F16, -24(R1)
SUBI R1, R1, #32 # 4 iterations * 8 bytes = 32 bytes
# The branch delay slot is filled
# with the next instruction
BNEZ R1, LoopIn this form, registers F0, F4, F6, F8, F10, F12, F14, F16 are used to ensure that no write conflicts occur. Each load, multiply, and store operation is performed independently using different registers, eliminating the risk of WAW hazards. Since 4 iterations are unrolled into a single loop body, the number of instructions is reduced to approximately
Instruction Rescheduling to Prevent RAW Stalls
Although unrolling reduces WAW hazards, the risk of RAW hazards remains if the instructions are not scheduled properly. RAW hazards arise when an instruction tries to read a value from a register that has not yet been written. By rearranging the instruction order to allow independent instructions to execute while waiting for data dependencies to resolve, stalls are minimized.
The following rescheduled version reduces RAW hazards by performing all load operations before executing the dependent multiply and store operations:
Loop: LD F0, 0(R1)
LD F6, -8(R1)
LD F10, -16(R1)
LD F14, -24(R1)
MULTD F4, F0, F2
MULTD F8, F6, F2
MULTD F12, F10, F2
MULTD F16, F14, F2
SD F4, 0(R1)
SD F8, -8(R1)
SD F12, -16(R1)
SD F16, -24(R1)
SUBI R1, R1, #32
BNEZ R1, Loop
SD F16, 8(R1) # branch delay slot (8 - 32 = -24)This separation of load and computation further reduces RAW stalls. Additionally, the compiler has strategically placed the store instruction SD F16, 8(R1) in the branch delay slot, that is a feature in some architectures where an instruction following a branch is executed before the branch takes effect, utilizing otherwise wasted cycles.
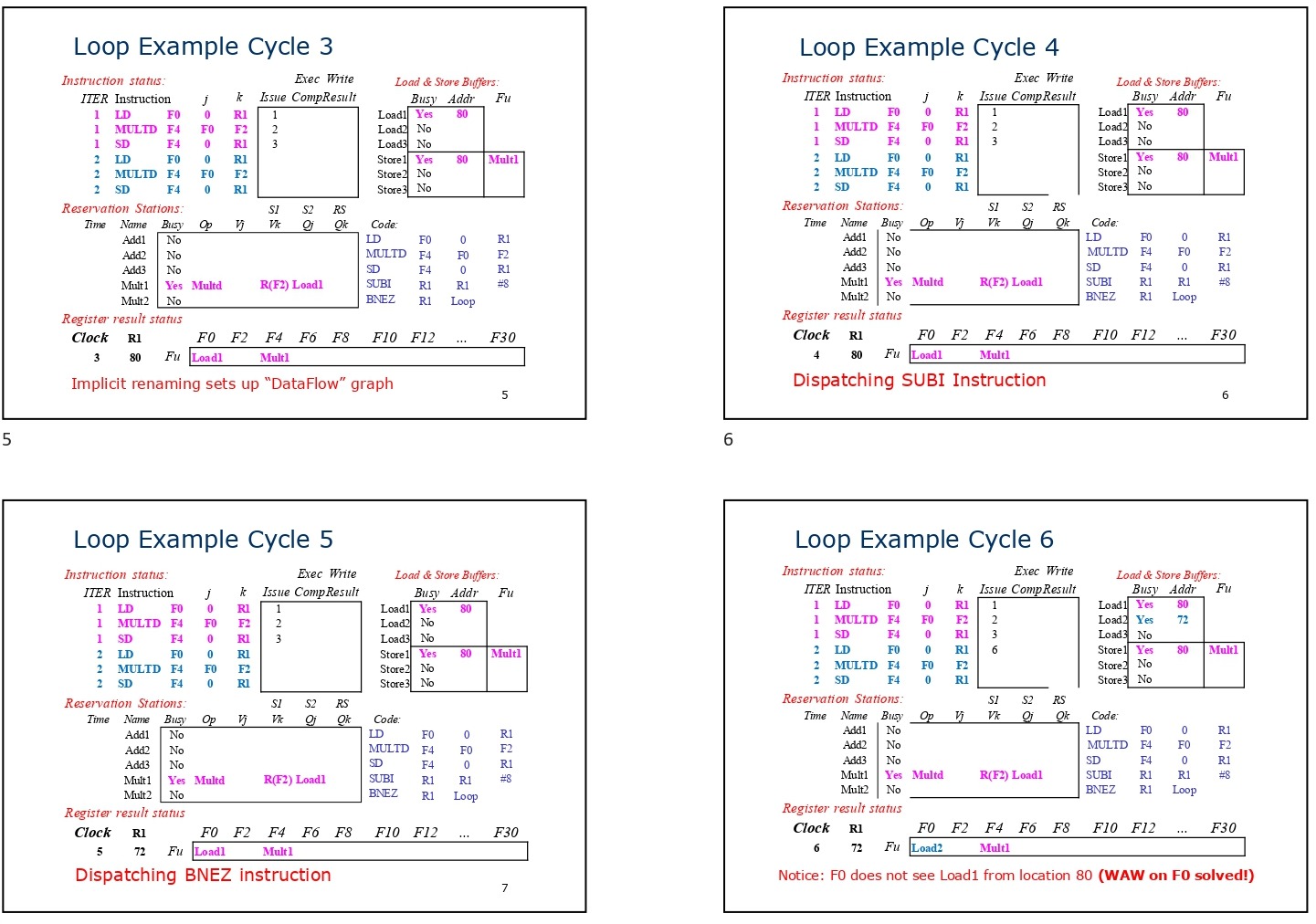
Tomasulo Algorithm and Implicit Register Renaming
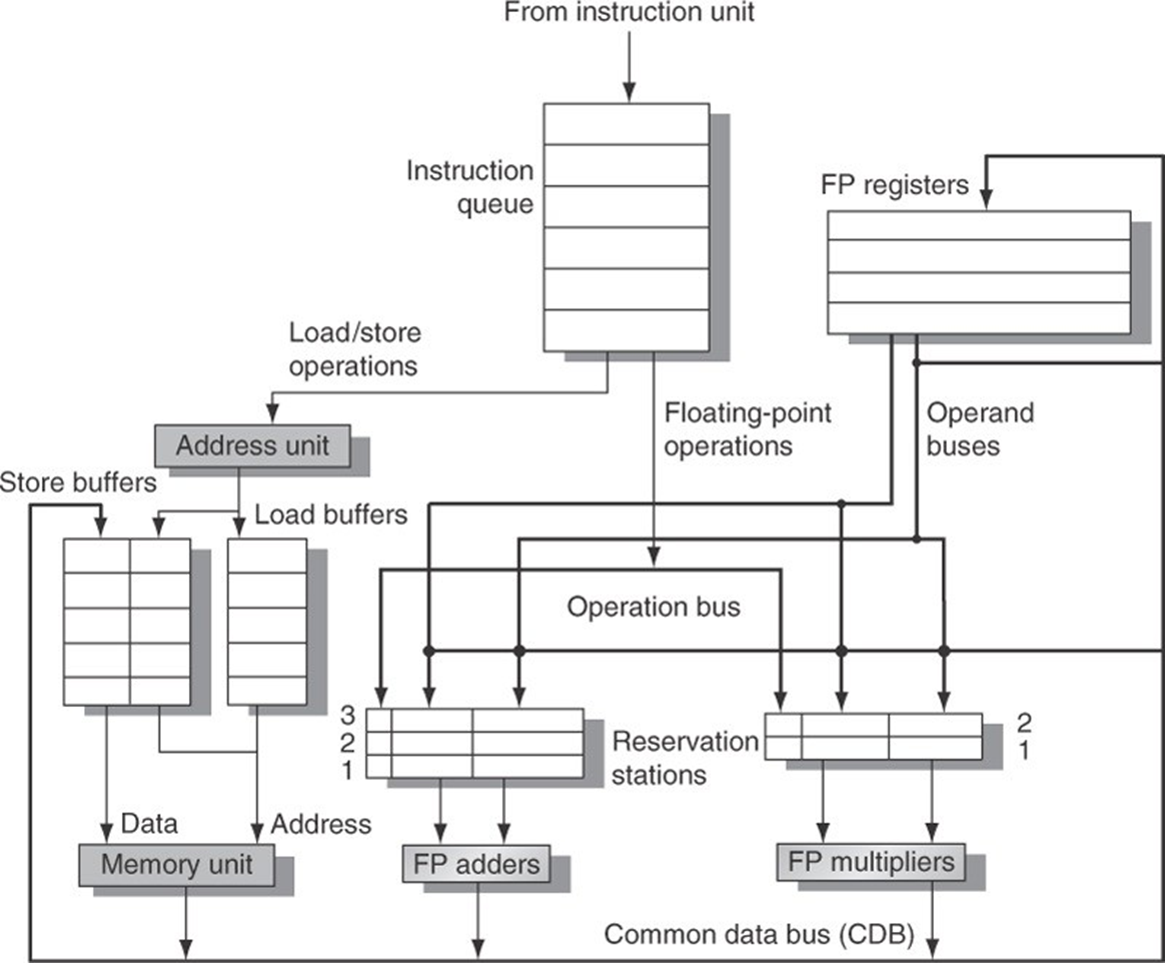
The Tomasulo algorithm uses a sophisticated mechanism called implicit register renaming to address Write After Read (WAR) and Write After Write (WAW) hazards. This form of renaming is implemented using reservation stations, which act as buffers for storing operands and instructions. Instead of directly associating instructions with physical register names, the algorithm dynamically assigns reservation stations to act as placeholders for values. This eliminates false dependencies that often arise from register reuse.
In traditional execution without register renaming, multiple instructions may read from or write to the same register, leading to hazards that can stall the pipeline. In contrast, the Tomasulo algorithm substitutes register names with dynamic “pointers” (or tags) that reference reservation stations. These tags indicate where the actual data resides rather than using fixed register identifiers.
Example
For example, when an instruction issues a read request, it first checks if the data is available in a reservation station. If not, it waits until the data becomes available. Similarly, when an instruction completes its execution, it writes the result back to the Common Data Bus (CDB), broadcasting the tag to notify other instructions waiting for the data.
This tag-based system ensures that instructions are not constrained by the original register names, allowing independent operations to proceed without waiting for previous instructions to complete. Consequently, implicit register renaming helps overcome WAW and WAR hazards by breaking artificial dependencies.
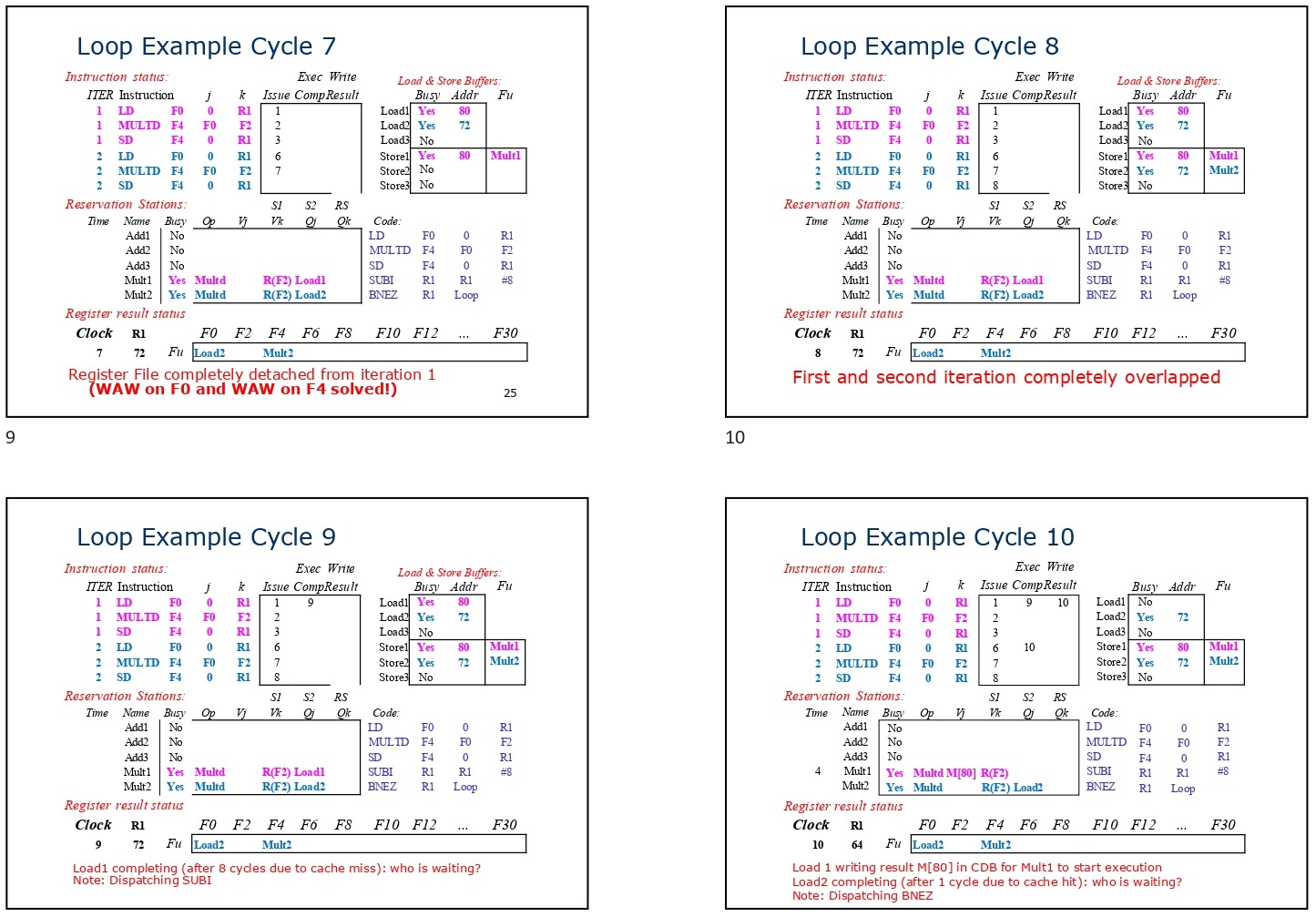
Dynamic Loop Unrolling with Reservation Stations
A significant advantage of implicit register renaming is its ability to perform dynamic loop unrolling. Unlike static loop unrolling, which requires the compiler to rewrite code using additional registers, dynamic loop unrolling is achieved at runtime using reservation stations. Multiple iterations of the same loop can be executed concurrently, with each iteration utilizing a different set of reservation stations.
This effectively expands the number of “available registers” beyond what is physically present in the processor. Since each reservation station acts as a temporary register, the instruction window can accommodate more operations in-flight, maximizing instruction-level parallelism.
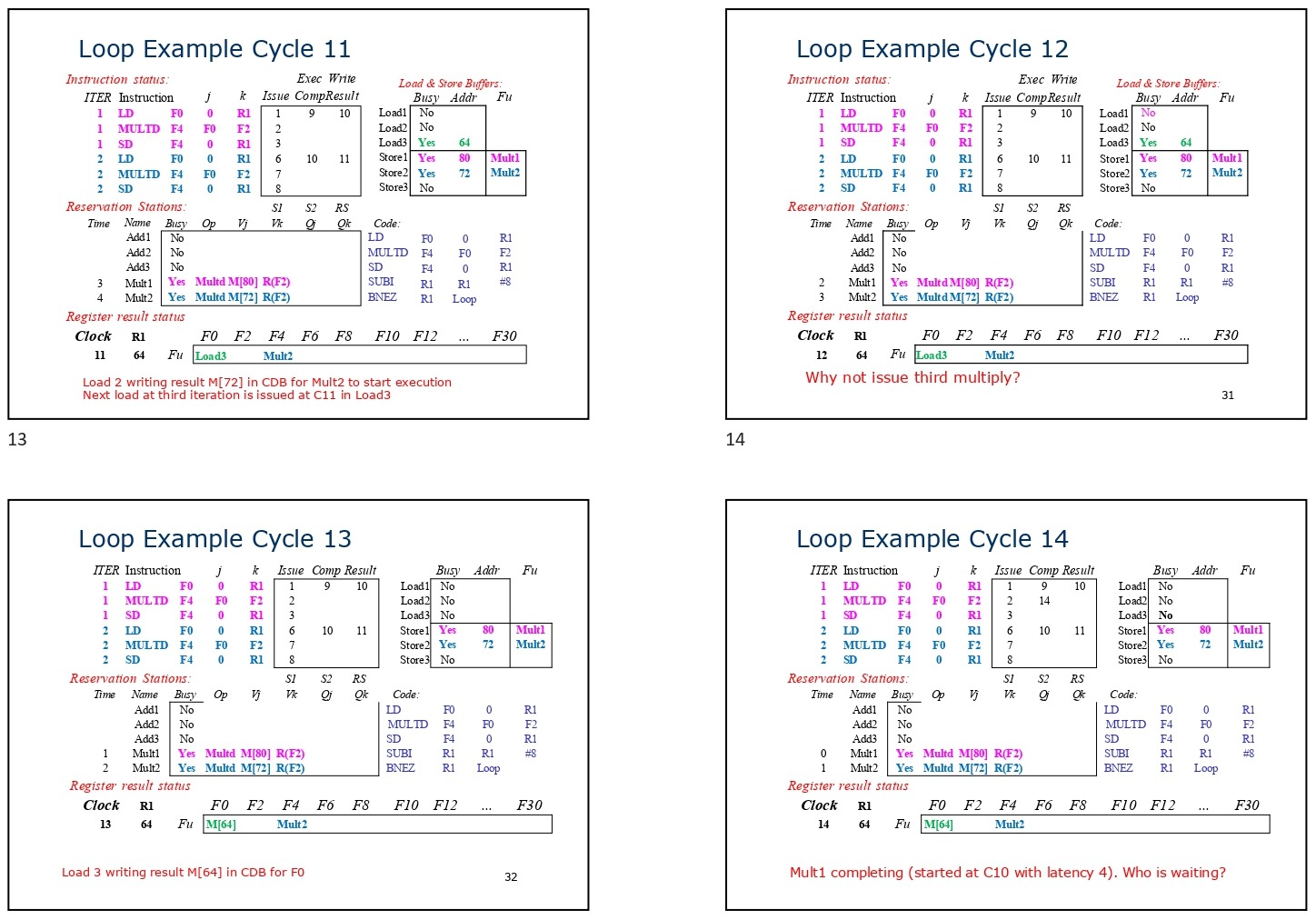
Instruction-Level Parallelism and Branch Prediction
For implicit register renaming to be effective, it is crucial for the integer unit to operate ahead of the floating-point unit. This allows multiple iterations of a loop to be issued in parallel, taking advantage of branch prediction mechanisms. The Tomasulo algorithm relies on branch prediction to speculatively execute instructions beyond conditional branches. By predicting the branch outcome (typically using dynamic branch predictors), the processor continues issuing instructions without waiting for the actual branch result.
This speculative execution further increases instruction throughput by minimizing stalls caused by control dependencies. If the branch prediction turns out to be incorrect, the processor can discard the speculative instructions without affecting program correctness.
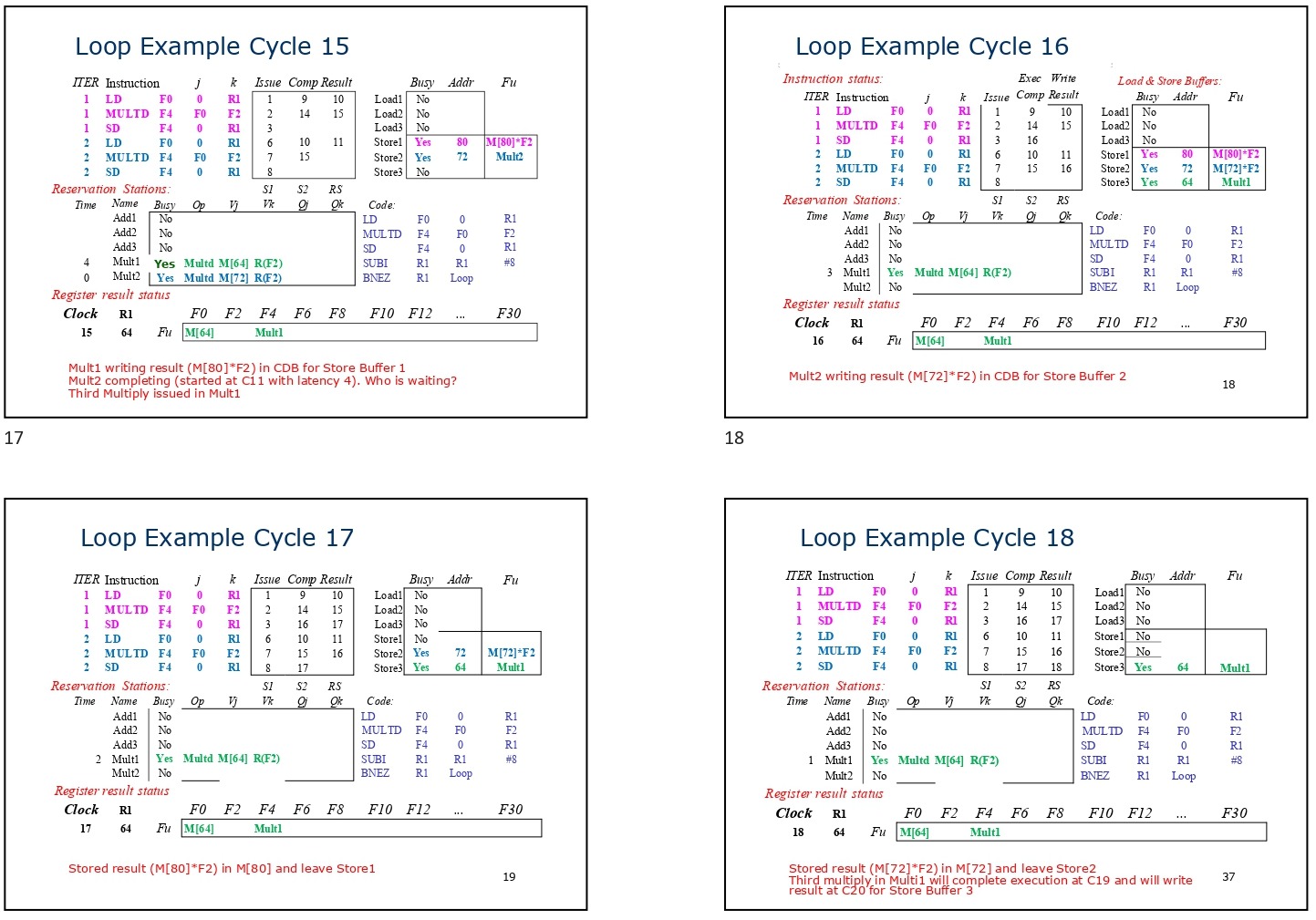
Tomasulo Loop Example