A Multi-Issue Processor is a type of processor architecture designed to improve performance by exploiting instruction-level parallelism (ILP). Unlike traditional single-issue processors that fetch and issue one instruction per clock cycle, multi-issue processors are capable of fetching and issuing multiple instructions during the same cycle. The way these instructions are issued depends on the scheduling strategy employed by the system, which can be either dynamic or static.
In dynamic scheduling, the processor’s hardware makes decisions at runtime regarding how many and which instructions to issue in a given cycle. This approach relies heavily on complex control logic to analyze dependencies and resolve hazards in real time. In contrast, static scheduling shifts this responsibility to the compiler.
Definition
A compiler is a special program that processes statements written in a particular programming language and turns them into machine language or “code” that a computer’s processor uses.
In static scheduling, the compiler analyzes the instruction stream ahead of time and determines which instructions can be issued in parallel, inserting them into the machine code accordingly. If sufficient parallelism is not detected due to data dependencies or resource constraints, the compiler inserts NOPs (No Operation instructions) to maintain correct program behavior.
The compiler plays a crucial role in exploiting ILP in statically scheduled systems. It uses advanced techniques such as dependency analysis and instruction reordering to determine which instructions can safely execute in parallel. The compiler must ensure that no hazards—such as read-after-write (RAW), write-after-read (WAR), or structural hazards—compromise the correctness of the program. If parallel execution is not feasible, NOPs are introduced to fill the unused instruction slots, which reduces performance but preserves correctness.
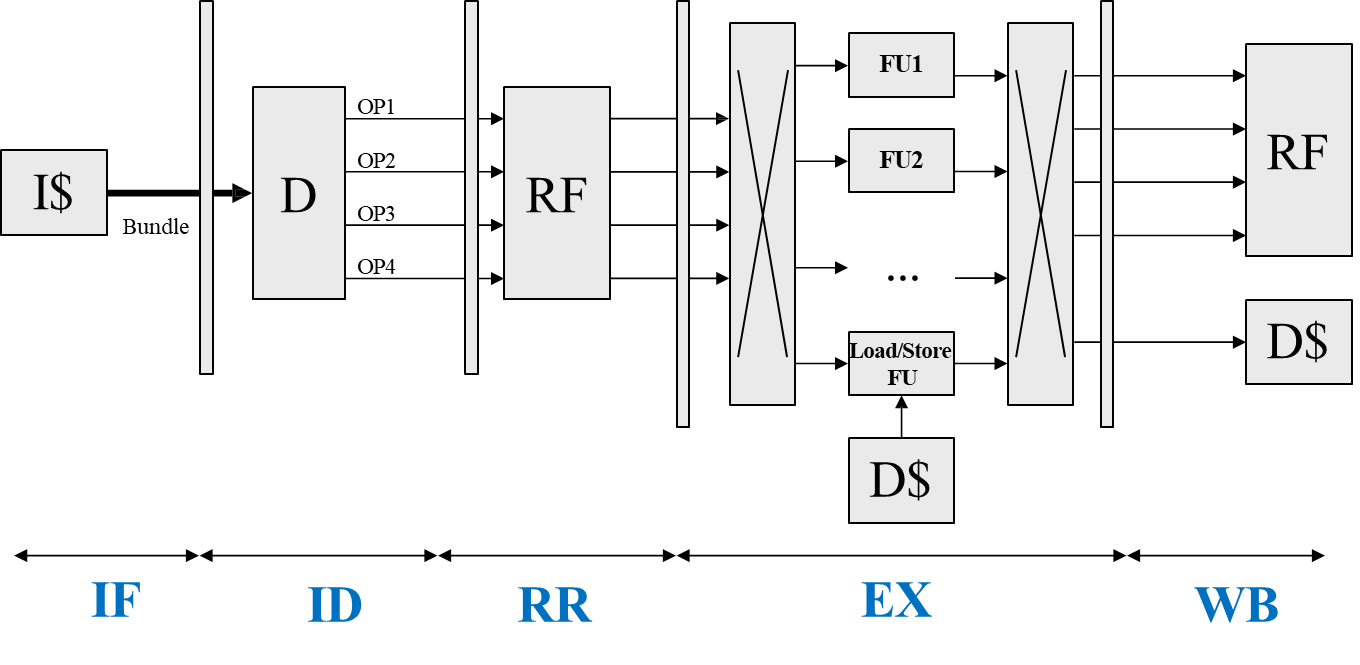
A Very Long Instruction Word (VLIW) processor is a specific category of statically scheduled multi-issue processors. In VLIW architectures, the task of identifying parallel instructions is delegated entirely to the compiler. The compiler bundles multiple independent operations together into a single wide instruction—referred to as a long instruction word (or bundle). Each operation in the bundle is intended to be executed in parallel by a different Functional Unit (FU) within the processor.
The long instruction word typically contains multiple slots, with each slot corresponding to a specific type of operation or a specific FU.
Example
For example, a 4-issue VLIW processor has a bundle comprising four slots, each capable of holding an operation.
These operations are executed in parallel during a single cycle, provided there are no data or resource conflicts. If the compiler cannot find four parallel operations due to program structure or dependencies, it fills the unused slots with NOPs.
In VLIW systems, the compiler is responsible for detecting and resolving structural hazards (contention for hardware resources) and data hazards (conflicts involving data dependencies) during compile-time. This shifts the burden away from hardware, allowing the processor to be simpler, more power-efficient, and less costly in terms of area. However, it also places significant pressure on the compiler to generate high-quality code.
The VLIW philosophy assumes either complete independence between operations within a bundle (a pure VLIW approach), or it allows the compiler to explicitly annotate dependencies within the bundle—this hybrid model is referred to as EPIC (Explicitly Parallel Instruction Computing). EPIC architectures allow some flexibility by permitting dependences to be encoded explicitly, enabling the hardware to manage limited forms of parallelism checks without full dynamic scheduling.
Microarchitecture of VLIW
In VLIW processors, there is a single PC to fetch a long instruction (bundle) and only one branch for each bundle to modify the control flow. There is a Shared Multi-ported Register File, where if the bundle has 4 slots, we need () read ports and 4 write ports to read 8 source registers per cycle and to write 4 destination registers per cycle. To keep busy the FUs, there must be enough parallelism in the source code to fill in the available 4 operation slots; otherwise, NOPs are inserted.
The typical VLIW processor pipeline is composed of five stages:
Instruction Fetch (IF): Retrieves the entire instruction bundle from memory using a single Program Counter (PC).
Instruction Decode (ID): Decodes the wide instruction bundle, preparing individual operations for execution.
Register Read (RR): Accesses a shared, multi-ported Register File (RF) to read the source operands. For a processor with 4 slots, this usually requires 8 read ports and 4 write ports to support parallel access.
Execution (EX): Each FU executes its assigned operation. Dedicated units may exist for specific tasks such as load/store, with access to the Data Cache (D$) for memory operations.
Write Back (WB): Each FU writes its results back to the register file. For load/store operations, the result is written back either to the register file or memory depending on the instruction.
This structure ensures that each instruction bundle is processed efficiently, with minimal control overhead. The decode stage in a VLIW processor is particularly straightforward when each slot is dedicated to a specific FU type. In such cases, the decoding logic simply routes each operation to its corresponding unit. However, when there are more FUs than issue slots or when FUs are not fixed, the processor requires a dispatch network to dynamically direct operations and their operands to the appropriate execution units.
Data Dependencies
In VLIW processors, handling data dependencies is one of the compiler’s primary responsibilities. Dependencies such as true dependencies (RAW: Read After Write), anti-dependencies (WAR: Write After Read), and output dependencies (WAW: Write After Write) are resolved statically during compile time by analyzing the program’s instruction sequence and the latency of each operation. The compiler ensures that instructions are reordered when possible, to avoid data hazards without violating program correctness.
In VLIW systems, where operations within a bundle are executed in parallel, the compiler must carefully schedule operations to prevent such hazards. If an instruction produces a result that another operation needs, the compiler will either reorder independent instructions between the two or insert NOPs (no-operations) to delay execution until the result is available.
Example
Suppose a multiplication operation has a latency of 2 cycles; the compiler might insert a NOP to account for this delay:
I [C = A * B, ....] # Latency: 2 cyclesI+1 [NOP, ....] # Compiler-inserted delayI+2 [X = C * F, ....] # Safe to use C now
If NOPs are not inserted or operations are not reordered appropriately, incorrect results may occur due to premature usage of yet-to-be-written values.
On the other hand, WAR and WAW hazards are handled through register renaming or by carefully allocating temporal slots during instruction scheduling. This avoids cases where instructions improperly overwrite or reuse registers still in use by other operations. Because structural hazards (such as contention for the same hardware resources) are predictable at compile time in VLIW architectures, the compiler also accounts for these by ensuring that the same resources are not scheduled for use by multiple operations in the same cycle.
Another important aspect is branch prediction. While most of the control logic in VLIW systems is handled statically, the compiler may provide branch prediction hints to assist hardware during execution. However, since branch outcomes are inherently dynamic, a mispredicted branch cannot be handled statically. In such cases, the hardware must flush the pipeline of speculatively executed instructions and resume execution from the correct path.
To maintain in-order execution, all operations within a bundle must reach the Write Back (WB) stage simultaneously. This constraint prevents structural hazards in the Register File (RF) and ensures that WAR and WAW hazards do not arise due to overlapping register writes. The overall execution time of a bundle is therefore determined by the operation with the highest latency in the group. If this rule is not enforced, out-of-order effects may occur, which would compromise program correctness and require additional hardware for hazard checking and correction—defeating the purpose of the VLIW’s simplicity.
Register Pressure
Definition
Register pressure refers to the increasing demand for physical registers caused by the parallel execution and multicycle latency of operations.
In VLIW architectures, multiple instructions are issued simultaneously, and many of these can have long execution times. As a result, the destination registers of these operations remain occupied for several cycles and cannot be reused for other instructions during that time.
Example
For instance, if a bundle contains 2 floating-point operations, each with a latency of 5 cycles, the destination registers will be locked for the duration of those cycles. During this period, the register file must sustain the parallel demands of subsequent bundles.
With a 4-issue VLIW processor issuing four operations per cycle, this quickly multiplies: over five cycles, the processor would have issued 20 operations, each potentially requiring its own register for either source or destination operands.
This accumulation of register usage leads to high register pressure, and the situation is exacerbated by the register renaming technique used to avoid WAR and WAW hazards. By allocating unique physical registers for logically identical variables to maintain independence, renaming increases the number of registers required simultaneously. Consequently, compilers targeting VLIW architectures must implement efficient register allocation strategies to mitigate this pressure, especially in loops and high-parallelism segments of code.
Dynamic Events at Runtime
Although VLIW compilers are responsible for most of the scheduling and hazard resolution, some runtime events cannot be predicted or resolved at compile time. These dynamic events introduce uncertainties that the hardware must manage.
One common event is the Data Cache Miss, where a load operation cannot retrieve the requested data from the cache. While the compiler might know the potential latency of a cache miss, it cannot determine at compile time whether a specific memory access will result in a hit or a miss. When a miss occurs, the processor must stall the corresponding functional unit or the entire pipeline until the data is fetched from main memory.
Another unpredictable event is branch misprediction. Although the compiler can annotate likely branches or use profile-guided optimizations to estimate control flow, the actual path taken during execution may vary. When the hardware detects that a speculative branch prediction was incorrect, it must flush the pipeline, discard the incorrectly fetched and partially executed instructions, and resume from the correct branch target.
Example
Consider the following code snippet:
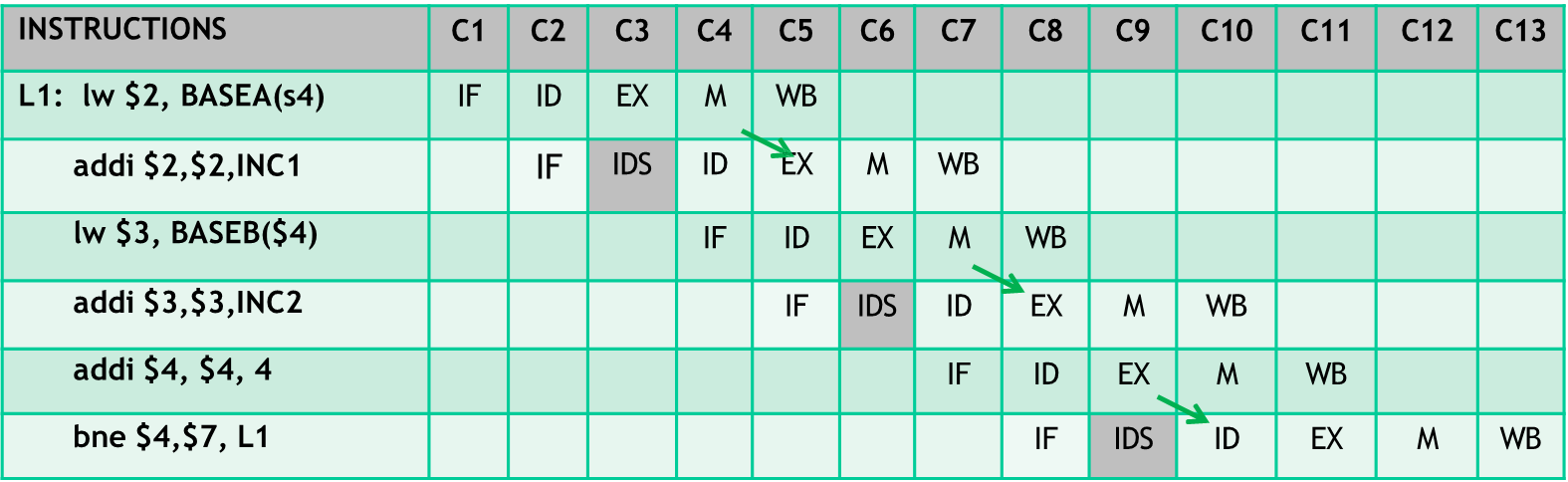
L1: LW $2, BASEA($4) ADDI $2, $2, INC1 ; RAW $2, WAW $2 LW $3, BASEB($4) ADDI $3, $3, INC2 ; RAW $3, WAW $3 ADDI $4, $4, 4 ; WAR $4 BNE $4, $7, L1 ; RAW $4
In a scalar 5-stage MIPS scheduling with forwarding and early branch resolution (in ID stage) and dynamic stalls insertion to resolve hazards, the above code would be executed as follows:
Considering now a 2-issue VLIW architecture, the same code would be executed as follows:
where the 2-issue VLIW architecture with 2 pipelined FUs with:
Slot 1: Load/Store with 2 cycles latency
Slot 2: Integer with 1 cycle latency and Branch with 2 cycle latency
allows the following scheduling:
Slot 1: LD/ST
Slot 2: INT/Branch
1
LW 4)
NOP
2
LW 4)
NOP
3
NOP
ADDI 2, INC1
4
NOP
ADDI 3, INC2
5
NOP
ADDI 4, 4
6
NOP
NOP
7
NOP
BNE 7, L1
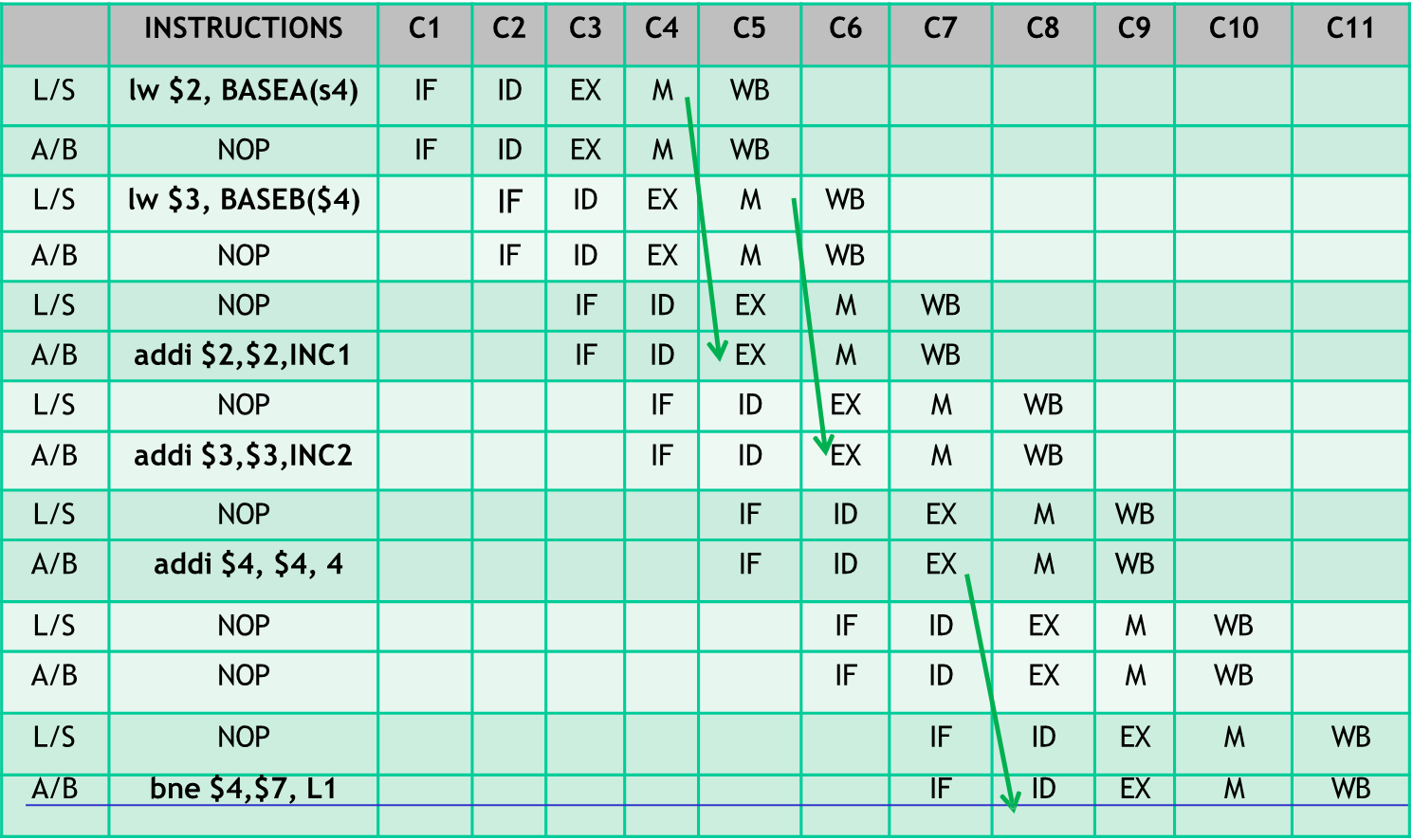
Considering now a 4-issue VLIW architecture with 4 fully pipelined FUs with:
Slot 1: Load/Store with 2 cycles latency
Slot 2: Load/Store with 2 cycles latency
Slot 3: Integer with 1 cycle latency
Slot 4: Integer with 1 cycle latency and Branch with 2 cycle latency
allows the following scheduling:
Slot 1: LD/ST
Slot 2: LD/ST
Slot 3: INT
Slot 4: INT/Branch
1
LW 4)
LW 4)
NOP
NOP
2
NOP
NOP
NOP
NOP
3
NOP
NOP
ADDI 2, INC1
ADDI 3, INC2
4
NOP
NOP
ADDI 4, 4
NOP
5
NOP
NOP
NOP
NOP
6
NOP
NOP
NOP
BNE 7, L1
From a performance point of view, the 4-issue VLIW architecture is better than the 2-issue VLIW architecture, as it allows more instructions to be executed in parallel (higher throughput). However, the 2-issue VLIW architecture is better because it has a lower number of NOPs (lower latency).
From a hardware point of view, the 4-issue VLIW architecture is more complex than the 2-issue VLIW architecture, as it requires more FUs and more ports in the register file. The 2-issue VLIW architecture is simpler and cheaper, as it requires fewer FUs and fewer ports in the register file. This means that the 2-issue VLIW architecture can be implemented in a smaller area and consume less power than the 4-issue VLIW architecture.
Throughput
Latency
Hardware Complexity
Cost
2-Issue VLIW
Low
Low
Low
Low
4-Issue VLIW
High
High
High
High
The choice between the two architectures depends on the specific workload and the balance between throughput and latency requirements.
Statically Scheduled Processors
In statically scheduled processors, the responsibility for instruction scheduling lies with the compiler, which uses advanced algorithms to expose and exploit Instruction-Level Parallelism (ILP). Unlike dynamic scheduling, where hardware makes decisions at runtime, statically scheduled architectures rely on compile-time analysis to organize the sequence of instructions in a way that maximizes parallel execution while avoiding hazards.
A key structure in this context is the basic block, defined as a straight-line sequence of code without branches except at the entry and exit points. This simplicity allows the compiler to apply optimizations more easily within the block. However, one limitation of working only within basic blocks is the limited amount of exploitable parallelism. On average, only about three independent instructions can be executed in parallel within a typical basic block in generic code, primarily due to data dependencies and control flow constraints.
In programs like those written in the MIPS architecture, branches occur frequently, approximately every 4 to 7 instructions, as the branch frequency typically ranges between 15% and 25%. This frequent branching further constrains the size of basic blocks, reducing the compiler’s ability to find independent operations to schedule concurrently.
To significantly improve performance, compilers must perform global scheduling by looking beyond basic blocks and analyzing across multiple blocks, a technique often referred to as loop unrolling, trace scheduling, or superblock formation. These methods aim to break out of the strict limitations of single basic blocks and uncover more ILP by reordering instructions over larger regions of code, often by speculating on branch directions or duplicating code paths.
Strengths and Limitations of the VLIW Architecture
The VLIW architecture is particularly effective when paired with a powerful compiler that can exploit the latent parallelism in software. The compiler statically schedules multiple independent operations into a single wide instruction (or bundle), allowing them to be dispatched and executed in parallel. This approach offers several compelling advantages:
High Performance: The compiler can optimize instruction scheduling and resource allocation, leading to better performance than dynamic scheduling in many cases. By analyzing the entire program, the compiler can identify opportunities for parallel execution that may not be apparent at runtime.
Simplified Hardware Design: VLIW architectures eliminate the need for complex hardware mechanisms like dynamic scheduling, register renaming, and out-of-order execution. This simplification results in smaller, cheaper, and more power-efficient chips.
Scalability: VLIW architectures can easily scale by adding more functional units and increasing the instruction word size. This scalability allows for greater parallelism and improved performance without significant changes to the underlying architecture.
Domain-Specific Optimization: VLIW architectures are well-suited for domain-specific processors, where the workload is well understood and parallelism is abundant. The compiler can be tailored to exploit the specific characteristics of the target application, leading to highly optimized code.
Simplicity of Instruction Decoding: VLIW instructions have a fixed format, making instruction decoding straightforward. Each slot in the instruction word corresponds to a specific functional unit, allowing for deterministic dispatch of operations.
Despite its strengths, the VLIW architecture is not without its difficulties.
Compiler Complexity: The burden of instruction scheduling and hazard resolution falls entirely on the compiler, which must be sophisticated enough to analyze dependencies, manage latencies, and optimize resource usage. This complexity can lead to longer compilation times and increased development effort.
Code Bloat: The fixed-size instruction bundles can lead to code bloat, as unused slots in the instruction word must be filled with NOPs. This can increase the size of the compiled code and reduce cache efficiency.
Register Pressure: The parallel execution of multiple instructions can lead to high register pressure, as many operations may require simultaneous access to registers. This can strain the register file and lead to performance degradation if not managed properly.
Binary Compatibility Issues: VLIW architectures often suffer from poor binary compatibility across different implementations. Variations in the number of functional units, latencies, and instruction formats can make compiled binaries incompatible with different VLIW processors, limiting portability and complicating software distribution. This is particularly problematic in general-purpose computing environments, where software must run on a wide range of hardware configurations.