Definition
RAID (Redundant Array of Independent disks) is a technology that uses multiple disks to provide fault tolerance, improve performance, increase storage capacity, and introduce redundancy in the storage system.
A simple set of independent HDDs will be red as a single, large, high performance logical disk; this is in contrast with the JBOD (Just a Bunch Of Disks) approach, where each disk is a separate device with a different mount point.
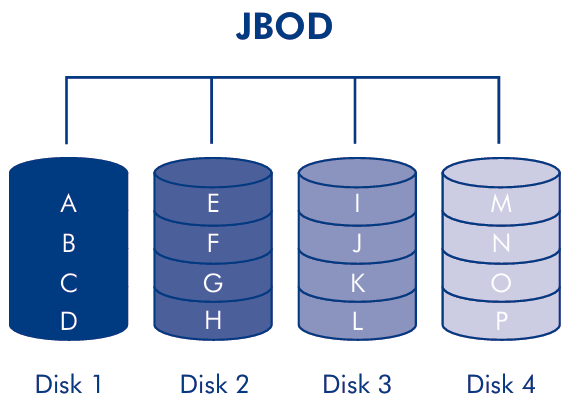
The data are stripped across multiple disks and accessed in parallel, which introduce high data transfer and I/O rates and load balancing across the disks. There are two techniques: data striping and redundancy.
Data Striping
Definition
Data striping is the process of writing data sequentially in units of a stripe across multiple disks according to a cyclic algorithm, like the Round Robin.
The stripe unit is the dimension of the unit of data that are written on a single disk before moving to the next one. The stripe width is the number of disks in the array.
In order to access a file, the system could perform multiple independent I/O requests, that will be executed in parallel by several disks, decreasing the queue length and the response time. Or, the system could perform a single multiple-block I/O request, that will be executed by multiple disks in parallel increasing the transfer rate of the single request.
The more physical disks in the array, the larger the size and the performance gains, but the larger the probability of failure of a disk. This is the main motivation for the introduction of redundancy.
Definition
Redundancy is the process of storing additional information to recover the data in case of a disk failure. The redundant information can be stored in the same disk of the data or in a dedicated disk.
Since the write operations must update also the redundant information, the write performance is worse than the one of the traditional writes. There are two main techniques to perform data reconstruction:
- data duplication: the data are written on multiple disks, so that if a disk fails, the data are still available on the other disks
- data reconstruction: the data are written on multiple disks, and the redundant information is used to recover the data in case of a disk failure
RAID
Hard drivers are great devices, relatively fast with persistent storage, but they are not perfect. They can fail, due to mechanical or electronic problems, or the sectors can become unreadable. Also, the capacity of a single disk is limited, and the performance are not always the best.
RAID use multiple disks to create the illusion of a large, faster, more reliable disk. Externally, RAID looks like a single disk (it’s transparent to the OS and to the user), the data blocks are read/written as usual and there is no need for software to explicitly manage multiple disks or perform error checking/recovery. Internally, RAID is a complex computer system, with disks managed by a dedicated CPU and software components, RAM and non-volatile memory for caching. All these components are placed in a single box, called RAID controller.
There are several RAID levels, each with different characteristics in terms of performance, fault tolerance, and capacity. The most common are:
- RAID 0: data striping without redundancy (high performance, low reliability)
- RAID 1: data mirroring without striping (high reliability, low performance)
- RAID 4: block interleaving with a dedicated parity disk (rotary parity)
- RAID 5: block interleaving with distributed parity (rotary parity)
- RAID 6: block interleaving with double distributed parity (double rotary parity)
The choice of the RAID level depends on the requirements of the system, like the performance, the fault tolerance, and the capacity needed. The RAID level can be selected at the time of the creation of the array, but it can be changed later only by destroying the array (losing all the data stored) and creating a new one.
RAID 0
Definition
RAID 0 is a configuration that uses striping across multiple disks without any redundancy.
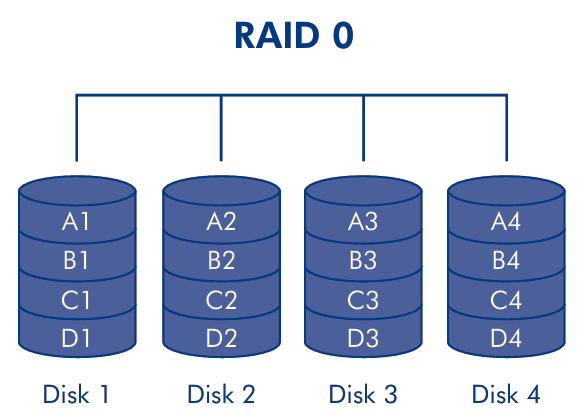
RAID 0 is the simplest RAID level, it uses striping to write data across multiple disks. The data are written on a single logical disk and splatted in several blocks distributed across the disks according to a stripping algorithm. This configuration is used where performance and capacity, rather than reliability, are the primary concerns. To create a RAID 0 array, the disks must have the same capacity and the same speed and require a minimum of two disks, but it can use more disks to increase the capacity and the performance.
RAID 0 is a low cost solution because it doesn’t employ redundancy, no error-correcting codes are computed and stored. The write performance are higher, because it doesn’t need to update redundant data and it’s parallelized across multiple disks. However, a single disk failure will cause the loss of all the data in the array.
Definition
Stripping is the process of writing data sequentially in units of a stripe across multiple disks.
To access to a specific data block in a RAID 0 array, we select the disk and the disk offset. The disk is
while the disk offset is
Example
If we have a set of 4 disks in a RAID 0 array and we want to write a block of data at the logical block number 11, the disk will be the disk number
and the disk offset (physical block) will be .
The chunk size is the size of the stripe unit, it’s the dimension of the unit of data that are written on a single block before moving to the next one. Smaller chunk sizes are better for random access, while larger chunk sizes are better for sequential access. Typical arrays use a chunk size of 64 KB.
Analysis of RAID 0
| Parameter | Capacity | Reliability | Sequential read | Sequential write | Random read | Random write |
|---|---|---|---|---|---|---|
| Value |
where
The FR (Fault Rate) is the probability that a disk fails in a given period of time. The FR of the RAID 0 array is
RAID 1
Definition
RAID 1 is a configuration that uses mirroring to provide redundancy.
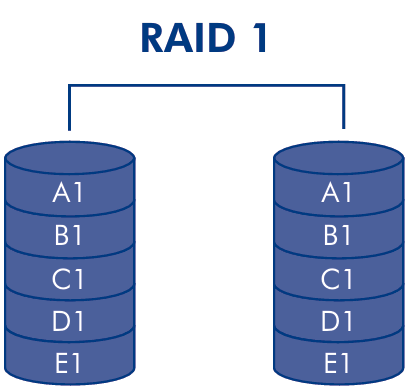
This solution provides high reliability, because the data are duplicated on multiple disks; so, when even a single disk fails, the data are still available on the other disks. Data can be retrieved from any of the disks, and the system can choose the disk with the lowest load to guarantee the best performance. The writing process is reasonably fast, because there is no need to compute error correcting codes, but it’s still slower than standard disk due to duplication. However, this solution is high cost, because it requires twice the number of disks to store the same amount of data.
Definition
Mirroring is the process of writing data on multiple disks to provide redundancy.
RAID 1 can mirror the content over more than one disk. This gave resiliency to errors, even if more than one disks break. It allows, with a voting mechanism, to identify errors not reported by the disk controller.
If several disk are available, RAID 1 couples the disks in pairs, and the data are written on both disks of the pair. This means that the total capacity is halved, because each disk has a mirror.
The mirroring writes should be atomic, so that the data are written on both disks or none (and not only on one disk, because the other disk is failed or slow). This is a difficult process to guarantee, because there are many factors that can cause a failure in the writing process (like power loss, disk failure, etc.). The RAID controller includes a write-ahead log (with a battery backed and non-volatile storage of pending writes) to recovery procedures to ensure recovery of the out-of-sync mirrored copies.
Many RAID system include an hot spare disk, a disk that is not used in the array, but it’s ready to replace a failed disk. When a disk fails, the hot spare disk is automatically added to the array and the data are copied from the other disks. This process is called rebuilding.
RAID can be implemented in hardware and software.
- Hardware RAID is implemented in a dedicated controller, that is a separate device with its own CPU, RAM, and non-volatile memory, providing better performance and reliability, but very limited possibility to migrations.
- Software RAID is implemented in the OS, that uses the CPU and the RAM of the host, providing more flexibility and scalability, but lower performance and reliability.
Analysis of RAID 1
| Parameter | Capacity | Reliability | Sequential read | Sequential write | Random read | Random write |
|---|---|---|---|---|---|---|
| Value |
where
RAID 0+1
RAID levels can be combined to obtain the best of both worlds. RAID
Definition
RAID 0+1 (may be also called RAID 01) is a configuration that use a group of striped disks (RAID 0) that are then mirrored (RAID 1).
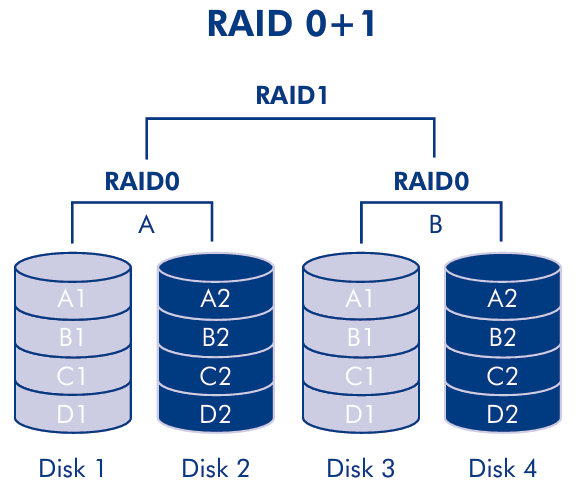
RAID 0+1 requires a minimum of four disks, because it needs 2 disks for the RAID 0 and 2 disks for the RAID 1. After a fail of a single disk, the RAID 0+1 array can still work as a simple RAID 0 array, but the data are not mirrored anymore.
The FR of a RAID 0+1 array is
RAID 1+0
Definition
RAID 1+0 (may be also called RAID 10) is a configuration that use a group of mirrored disks (RAID 1) that are then striped (RAID 0).
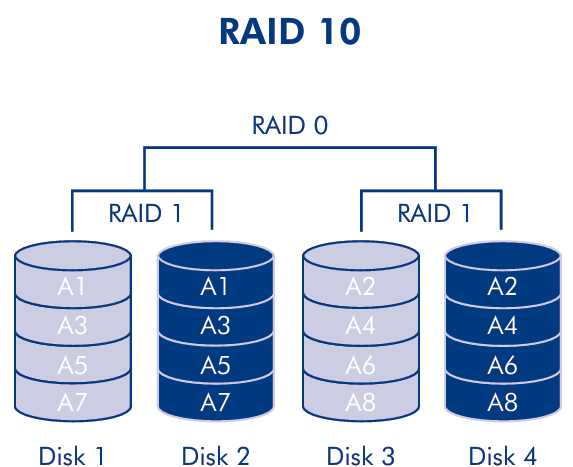
RAID 1+0 requires a minimum of four disks, because it needs 2 disks for the RAID 1 and 2 disks for the RAID 0. This particular configuration is used in databases with very high I/O rates.
The performance of RAID 1+0 and RAID 0+1 are similar, even the storage capacity is the same. The difference is the fault tolerance level: RAID 1+0 can survive the failure of a single disk in each group, while RAID 0+1 can survive the failure of a single disk in each pair. So, the fault tolerance of RAID 1+0 is higher than RAID 0+1.
The FR of a RAID 1+0 array is
RAID 4
Definition
RAID 4 is a configuration that uses one disk of the array to store the parity information, while the other
disks store the data.
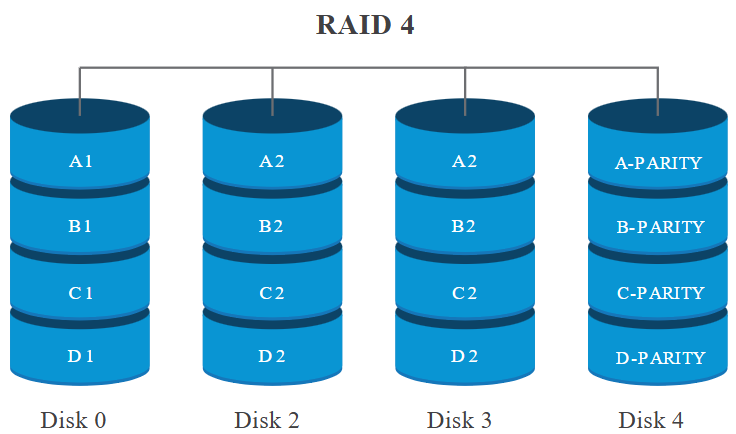
RAID 4 is a configuration that uses striping across multiple disks with a dedicated parity disk. The parity disk stores the parity information of the data blocks stored in the other disks and the parity information is used to recover the data in case of a disk failure. The parity is computed using the XOR operation between the data blocks.
where
- Additive parity: the parity block is the sum of the data blocks modulo 2. This is the simplest way to calculate the parity, but it’s not the most efficient.
- Subtractive parity: the parity block is the difference of the data blocks modulo 2. This is the most efficient way to calculate the parity, because it requires only the XOR operation.
When we want to write a block of data in a RAID 4 array, we write the data blocks on the data disks and the parity block on the parity disk. Using the additive parity, the paritiy is calculated by reading the data blocks and the update the parity block. Using the subtractive parity, the parity is calculated by reading the old parity block and the new data block.
Reads (serial or random) are not a problem in RAID 4, because the data blocks are read in parallel from the data disks (a small performance penalty is paid to read the parity block). Serial writes has the same performance of the reads, because all writes on the same stripe update the parity block once. Random writes are slower (due to the parity drive), because we have to:
- Read the target block and the parity block
- Use substractive parity to calculate the new parity block
- Write the target block and the parity block
Analysis of RAID 4
| Parameter | Capacity | Reliability | Sequential read | Sequential write | Random read | Random write |
|---|---|---|---|---|---|---|
| Value |
where
RAID 5
Definition
RAID 5 is a configuration that uses a block in each disks to store the parity information of the other blocks (rotary parity).
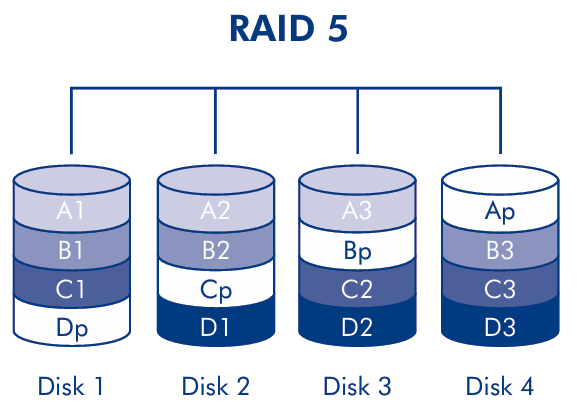
RAID 5 is a configuration that uses striping across multiple disks with distributed parity. The parity information is distributed across all the disks of the array, so that the parity block of a stripe is stored on a different disk. This configuration is used to avoid the bottleneck of the parity disk in RAID 4. Random writes in RAID 5 need to:
- Read the target block and the parity block
- Use substractive parity to calculate the new parity block
- Write the target block and the parity block
Thus, 4 total operations (2 reads and 2 writes) across all drives.
Analysis of RAID 5
| Parameter | Capacity | Reliability | Sequential read | Sequential write | Random read | Random write |
|---|---|---|---|---|---|---|
| Value |
where
The
RAID 6
Definition
RAID 6 is a configuration that uses two blocks in each disks to store the parity information of the other blocks (double distributed parity).
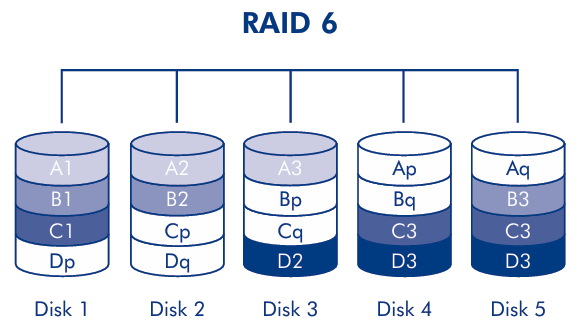
RAID 6 is a configuration that uses striping across multiple disks with double distributed parity. This configuration is used to provide a higher level of fault tolerance, because it can survive the failure of two disks in the array. The parity information come from the Solomon-Reed codes, that are used also in the CDs and DVDs, with two redundancy schemes
This configuration required a minimum of 4 disks. There is an high overhead for writes, because each writes require 6 disk access due to the need to update both the
The
This RAID level is used in critical applications, where the data are very important and the probability of a disk failure is high. In standard applications, RAID 6 is an overkill, because the probability of a disk failure is very low to justify the high cost of the RAID 6 array and the low performance.
Comparison
Given
| RAID 0 | RAID 1 | RAID 4 | RAID 5 | |
|---|---|---|---|---|
| Capacity | ||||
| Reliability | ||||
| Sequential read | ||||
| Sequential write | ||||
| Random read | ||||
| Random write | ||||
| Read latency | ||||
| Write latency |
Reliability calculations
Let’s assume a constant failure rate, an exponential time to failure and the case of independent failures.
Definition
The Mean Time To Failure (MTTF) is the expected time until a system fails. It’s the reciprocal of the failure rate.
The MTTF of the disk array can be calculated as
Without any fault tolerance approach, large disk arrays are too instable to be used. Disks do not have very large MTTF since is highly probable that will be replaced in short-time.
RAID 0 has no redundancy, so
where
Definition
The Mean Time To Repair (MTTR) is the expected time to repair a system after a failure.
MTTF of RAID 1
With a single copy of each disk, 1 drive can fail. If you are lucky,
where
MTTF of RAID 0+1 and RAID 1+0
When 1 disk in a stripe group fails, the entire group fails.
where
For RAID 1+0, the failure of the system happens when the same copy of both groups has to fail, so multiple failures can be tolerated.
where
MTTF of RAID 4 and RAID 5
To fail, in both RAID 4 and RAID 5, two disks have to fail before the replacement.
where
MTTF of RAID 6
In RAID 6, even if two disks fail, the system can still work. The probability of a third disk failure is very low.
The
The probability of a second disk failure is
Comparison of MTTFs
| RAID level | MTTF |
|---|---|
| RAID 0 | |
| RAID 1+0 | |
| RAID 0+1 | |
| RAID 4 | |
| RAID 5 | |
| RAID 6 |
where