In the last few decades, computing and storage have moved from PC-like clients to smaller, often mobile, devices, combined with large internet services. This has led to a huge increase in the amount of data that is generated, and the need to store and analyze it. Also, traditional enterprises shifted to cloud-based services as a base for their IT infrastructure. This shift brings several improvements:
- for the user experience: the user can access the data from anywhere, at any time, and from any device, with no need to backup the data
- for the vendor experience: the vendor can provide software-as-a-service (SaaS) solutions allowing faster application development, deployment, easier maintenance and support. Improvements and fixes in the software are easier inside their DC, because instead of updating the software on every client’s device, that may vary in terms of hardware and software specs, the DC offers a single infrastructure to update and new features will be available to everyone. The hardware deployment is restricted to a few well-tested configurations, and the vendor can provide better service to the customer.
- for the IT department: there is a fast introduction of new hardware solutions (for example, new hardware accelerators) and the application can runs at a very low cost per user
Some workloads require so much computing capability that they are a more natural fit in datacenter, and not in client-side computing, because they require a lot of data to be processed and analyzed. Some examples are search engines, social networks, machine and deep learning.
The trends toward server-side computing and widespread internet services created a new classes of computing systems: warehouse-scale computers (WSCs).
Definition
A warehouse-scale computer (WSC) is a massive-scale computing system that is built from many small servers, networked together to provide a single computing resource.
The program running in a warehouse-scale computing system is an internet service that may consists of tens or more individual programs; such programs interact to implement complex end-user services such as email, search, social networking, and so on.
Initially designed for the online data-intensive web workloads, WSCs also now power public clouds computing systems, like Amazon Web Services, Google Cloud Platform, and Microsoft Azure. Such public clouds do run many small applications, like a traditional data center, like Gmail, Google Search, and Google Maps. These applications rely on Virtual Machines (or containers), and they access large, common services for block or DB storage, load balancing, and so on, fitting very well in the WSC model.
The software running on these systems executes on clusters of hundreds to thousands of individual servers (far beyond a single machine or a single rack) and is designed to scale horizontally across many servers. The machine is itself this large cluster or aggregation of servers and needs to be considered as a single computing unit.
Difference between Data Center and Data Warehouse
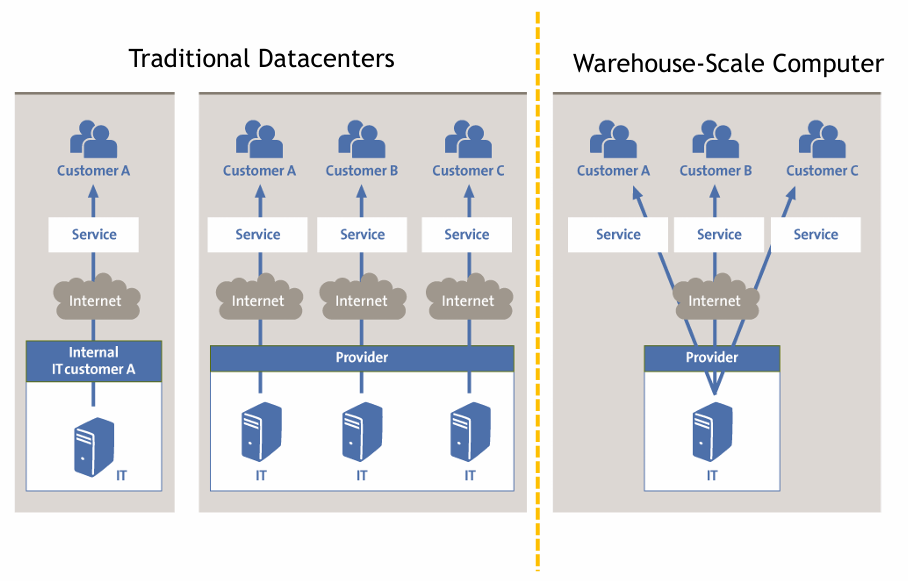
Data centers are buildings where multiple servers and communication units are co-located, because of their common environmental requirements and physical security needs, and for ease of maintenance. Traditional data centers typically host a large number of relatively small o medium sized applications, each running on a dedicated hardware infrastructure that is de-coupled and protected from other systems in the same facility. Applications in DC tend not to communicate with each other, and the data they generate is stored in separate databases. Those datacenters host hardware and software solution for multiple organizational units or even different companies.
Warehouse-scale computing solutions belong to a single organization, use a relatively homogeneous hardware and software platform, and share a common systems management layer. WSCs run a smaller number of very large applications (or internet services). The common resource pool allows significant deployment and operational flexibility. This kind of computing infrastructure, however, needs an homogeneity in the hardware and software platform, a single-organization control, and a cost-effective management layer; these necessities motivate designers to take new approaches to the design of the hardware and software infrastructure.
Other solutions
Another possible solutions is the use multiple data centers located far apart, that are (in some cases) replicas of the same service; this reduce user latency (because the user can access the nearest data center) and improve the service reliability (because the service is replicated in multiple data centers). A request is typically fully processed in the data center where it arrives, but a data center may need to communicate with other data centers to complete the request.
From an hierarchical point of view, the world is divided into:
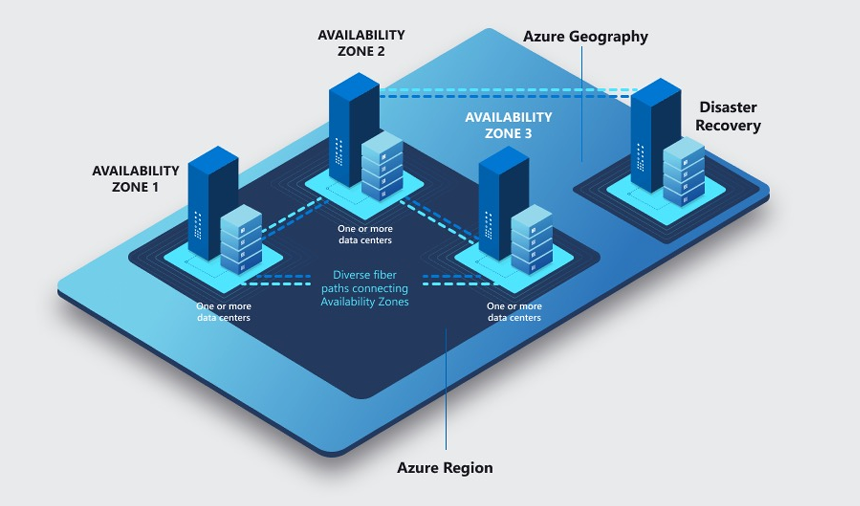
- Geographical regions (GAs): defined by geopolitical boundaries (or country borders), determinate mainly by data residency and legal requirements. In each GA, there are at least two data centers, to provide redundancy and fault tolerance.
- Computing regions (CRs): customers see regions as the finer grain discretization of the infrastructure. Multiple DCs in the same region are not exposed to the customer, and the customer sees the region as a single entity. Latency in the region is a defined parameter (2ms latency for the round trip time). Each DCs in the region is about 100 miles apart from the others, with different flood zones in order to provide fault tolerance on natural disasters. This distance between two DCs is too much for synchronous replication, so the data is replicated asynchronously.
- Availability zones (AZs): are the finer grain location within a single computing region, allowing customers to run mission critical applications with high availability and fault tolerance to datacenter failures. Fault-isolated locations with redundant power, cooling, and networking. Each AZ is a separate failure domain, and the failure of one AZ does not affect the other AZs in the same region. From the application-level perspective, the AZs allow synchronous replication of the data, because the distance between two AZs is less than 1ms. In each quorum (a set of AZs), there are at least three AZs, and the data is replicated synchronously in two of them, and asynchronously in the third one.
Availability
Services provided through WSCs must guarantee high availability, typically aiming for at least 99.99% uptime (this means that the service is down for less than 1 hour per year). Some examples of numbers:
- a 99.90% on a single instance of VMs with premium storage for an easier lift and shift of the application
- a 99.95% VM uptime SLA (Service Level Agreement) for a web application that needs to be protected from hardware failures
- a 99.99% VM uptime SLA through Availability Zones for an application that needs to be protected from datacenter-level failures
Achieving such fault-free operation is difficult when a large collection of hardware and software is involved, and the system is exposed to a wide range of failure modes. The WSCs workloads must be designed to gracefully tolerate large numbers of components faults with little or no impact on service level performance and availability.
Architectural overview of warehouse scale computers
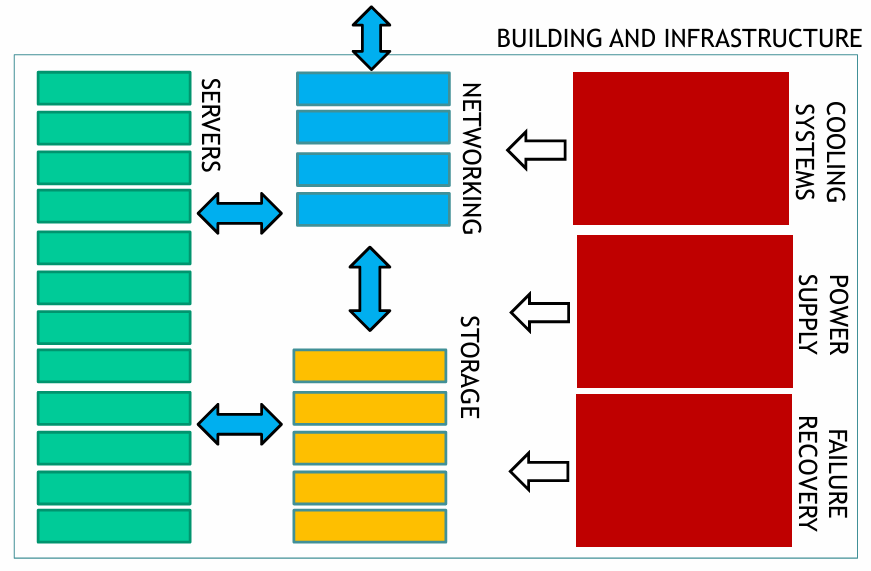
The hardware implementation of WSCs might differ significantly each other, but the architectural organization of these systems is relatively stable. The main components of a WSC are:
- Servers: the basic building block of a WSC is a server, a computer that runs a server operating system and provides services to other computers on the network. Servers are typically rack-mounted, and they are connected to a network switch that provides connectivity to other servers in the WSC.
- Network: the network is the communication fabric that connects the servers in the WSC. The network is typically a high-speed, low-latency network that allows servers to communicate with each other quickly and efficiently. The network is typically organized as a fat-tree topology, with multiple levels of switches that connect servers together.
- Storage: the storage system is the system that stores data for the WSC. The storage system is typically a distributed file system that allows servers to access data stored on other servers in the WSC. The storage system is typically organized as a distributed system that provides high availability and fault tolerance.
- Cooling systems, power supply and failure recovery systems: the WSC is a large collection of servers that generate a lot of heat and consume a lot of power. The WSC must be equipped with cooling systems and power supplies that can handle the heat and power requirements of the servers. The WSC must also be equipped with failure recovery systems that can recover from hardware failures quickly and efficiently.
Servers
Servers are the basic building block of a WSC. They are like ordinary PC, but with a form factor that allows to fit them into the racks. The most common form factor is the 1U server, which is 1.75 inches high and 19 inches wide, the blade enclosure, and the classic tower server.
They may differ in terms of CPU, memory, storage, and network connectivity. The number of CPUs, the amount of available RAM, the number and the type of storage device attached to the server, and other specific hardware components (GPUs, accelerators, etc.) are the main factors that determine the performance of the server.
Storage
Disks and flash SSDs are the building blocks of today’s WSCs storage systems. These devices are connected to the data center network and managed by sophisticated distributed systems that provide high availability and fault tolerance.
Examples of storage systems are:
- Direct Attached Storage (DAS): storage devices are directly attached to the servers, and they are managed by the server operating system. DAS is the simplest and cheapest storage solution, but it does not provide high availability and fault tolerance.
- Network Attached Storage (NAS): storage devices are connected to the network and managed by a dedicated storage server. NAS provides high availability and fault tolerance, but it is slower than DAS.
- Storage Area Network (SAN): storage devices are connected to the network and managed by a dedicated storage server. SAN provides high availability and fault tolerance, and it is faster than NAS.
- RAID controllers: storage devices are connected to the server and managed by a dedicated RAID controller. RAID provides high availability and fault tolerance, but it is slower than SAN.
Network
Communication equipment allows network interconnections among the devices in the WSC. The typical network devices are:
- Hubs: devices that connect multiple devices in a network. Hubs are simple devices that broadcast data to all devices connected to them.
- Routers: devices that connect multiple networks together. Routers are intelligent devices that can route data between networks based on the destination address.
- DNS or DHCP servers: devices that provide name resolution or IP address assignment services to other devices in the network.
- Load balancers: devices that distribute incoming network traffic across multiple servers. Load balancers are used to improve the performance and reliability of network services.
- Firewalls: devices that protect a network from unauthorized access. Firewalls are used to secure network services from external threats.
- Switches: devices that connect multiple devices in a network. Switches are intelligent devices that can route data between devices based on the destination address.
Building and Infrastructure
WSC has other important components related to power delivery, cooling, and building infrastructure that also need to be considered. Usually, the typical size of a WSC is with up 110 football-fields, the power consumption is between 2 and 100s MegaWatts (the largest WSCs consume as much power as a small city) and the typical uptime is 99.99% (less than 1 hour of downtime per year).