Dynamic analysis and testing are critical techniques in software engineering, designed to examine a program’s behavior during execution. These methods rely on executing the program with specific inputs to assess whether it behaves as expected. Properties of the software are often encoded as executable oracles, which act as mechanisms to verify desired conditions, expected outputs, or assertions.
One of the defining characteristics of dynamic testing is its reliance on a finite set of test cases. Unlike exhaustive verification, which aims to prove correctness across all possible inputs, dynamic testing only evaluates the program under specific scenarios. When a failure occurs, it is always accompanied by the concrete input that triggered it, providing actionable insights for debugging. While the program’s execution and failure detection are automated, defining the test cases and oracles typically requires manual intervention.
The overarching goal of testing is to identify failures in the program. By uncovering these failures, testing contributes to the improvement of software quality and reliability. Beyond this primary purpose, testing also serves several additional roles:
Maximizing Code Coverage: Testing aims to exercise different parts of the code, ensuring that as much of the program as possible is executed and evaluated.
Ensuring Component Interaction: In integration testing, testing validates the interactions between various components of the program, verifying that they work together as intended.
Supporting Debugging: Testing provides valuable data to localize faults and remove errors, simplifying the debugging process.
Preventing Regression: Regression testing ensures that bugs fixed in earlier versions of the software do not reappear in future iterations.
It is crucial to recognize the inherent limitations of testing.
Quote
“Program testing can be used to show the presence of bugs, but never to show their absence!”
Edsger W. Dijkstra
What is a Test Case?
Definition
A test case is a well-defined construct consisting of specific inputs, execution conditions, and a clear pass/fail criterion that determines whether the program behaves as expected. The process of running a test case typically involves three main stages:
Setup: Preparing the program by setting it to an initial state that fulfills the execution conditions.
Execution: Running the program with the defined inputs.
Teardown: Recording the program’s output, the final state, and any observed failures based on the pass/fail criterion.
To enhance testing comprehensiveness, multiple test cases are often grouped into a test suite. Each test case specification defines the requirements to be met by one or more test cases. For instance, a specification might state that “the input must be a sentence composed of at least two words.” A corresponding input satisfying this requirement could be, “this is a good test case input.”
Test cases form the foundation of dynamic analysis and testing. They enable developers to systematically evaluate a program’s behavior, detect issues, and ensure that the software evolves without introducing new defects. By understanding the nuances of test case design and execution, software engineers can optimize the testing process to achieve higher reliability and maintainability in their programs.
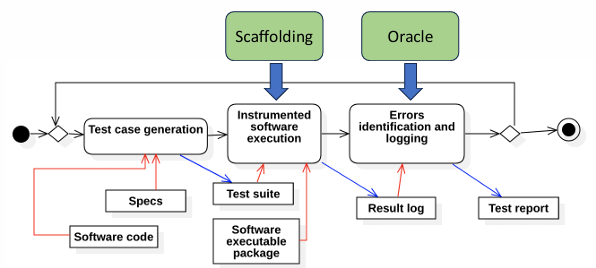
The Testing Workflow
The diagram represents the workflow of a software testing process, detailing the steps and components involved in ensuring the program behaves as expected under various scenarios. The workflow can be divided into three main stages: Test Case Generation, Instrumented Software Execution, and Errors Identification and Logging. Each stage is supported by auxiliary components such as Scaffolding and Oracle, which facilitate and validate the process.
Definition
Scaffolding: Provides the infrastructure and tools to create a controlled testing environment. It ensures the program is executed in conditions that replicate real-world usage while maintaining consistency across test runs.
Oracle: Acts as a benchmark for correctness, comparing actual program outputs with expected results. Oracles automate the identification of failures, simplifying the error detection process.
Test Case Generation:
The process begins with the generation of test cases. This step involves creating a set of inputs and execution conditions based on the software specifications and source code. The resulting test cases are organized into a test suite, which serves as a structured collection of inputs designed to evaluate the program’s behavior comprehensively. These test cases form the foundation for subsequent testing stages.
Instrumented Software Execution:
Once the test cases are generated, they are executed on the software executable package in an instrumented environment. Instrumentation involves enhancing the software to collect runtime data during execution, such as tracking code coverage or monitoring state transitions. This step relies on scaffolding, which provides the necessary infrastructure to simulate the testing environment, ensuring the software is tested under controlled and reproducible conditions.
Errors Identification and Logging
During execution, the system evaluates the software’s behavior against predefined oracles, which represent the expected outputs or conditions for correctness. The oracle identifies any discrepancies between the actual and expected outcomes, logging errors and failures in a result log. These discrepancies are crucial for pinpointing faults in the software.
Test Reporting
At the end of the process, the information collected in the result log is compiled into a test report. This report summarizes the outcomes of the testing process, detailing any errors detected and providing insights for debugging and error correction.
The workflow incorporates feedback mechanisms to improve the testing process iteratively:
The test suite and specifications may be updated based on findings from error identification.
Information from the result log may guide refinements in test case generation or adjustments to the software code.
Test Case Generation: Purpose and Techniques
The process of test case generation is fundamental to ensuring the effectiveness of software testing. Its primary purpose is to define high-quality test sets that maximize the chances of identifying errors, cover a sufficiently broad set of cases, and remain practical within computational and time constraints. Test case generation must balance thoroughness and sustainability, as exhaustive testing is infeasible in practice due to the infinite number of potential inputs.
A well-designed test set exhibits several desirable characteristics:
High error-detection probability: Test cases should be designed to uncover faults in the software as efficiently as possible.
Adequate coverage: The test set should evaluate a wide range of input scenarios, ideally covering all relevant paths, conditions, or specifications.
Feasibility: The generation process must remain manageable in terms of resources, ensuring that the number of test cases is sufficient but not excessive.
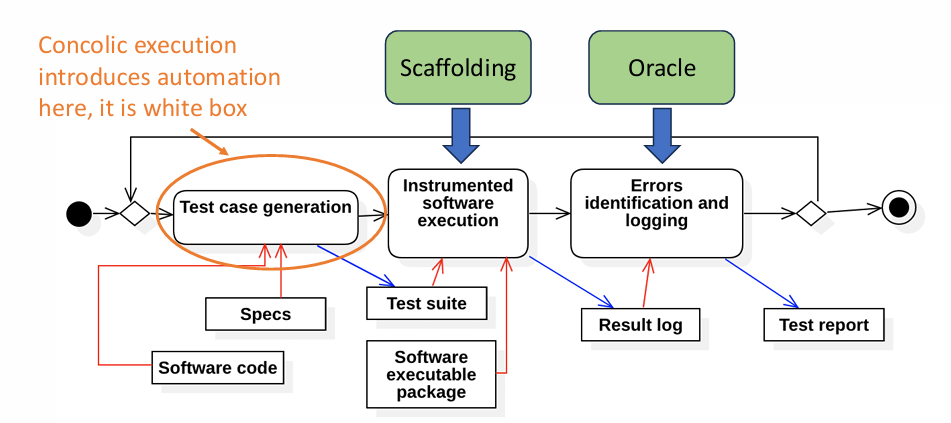
Black Box and White Box Approaches to Test Case Generation
Test cases can be generated using two primary methodologies: black box testing and white box testing, which differ in their basis for case selection.
Definition
White Box Testing: Test case generation is based on the internal structure of the code. This involves analyzing the program’s control flow, decision points, or data flow to ensure that all paths or branches are evaluated. Techniques such as branch coverage, path coverage, or data flow analysis are typically employed.
Black Box Testing: In this approach, test case generation is based on the external specifications of the software without considering its internal implementation. Test cases are derived by examining requirements, use cases, or expected functionality to verify that the software meets its intended purpose.
Manual and Automated Test Case Generation
Test cases can be generated either manually or automatically, with the latter becoming increasingly common due to advancements in automation tools and techniques.
Manual Test Case Generation: This involves human effort in analyzing requirements, specifications, or code to design test cases. While it can produce high-quality cases tailored to specific needs, it is time-consuming and may lack scalability.
Automated Test Case Generation: Automation leverages algorithms and tools to create test cases, improving efficiency and scalability. Various methods exist for automated test generation:
Combinatorial Testing: This technique systematically enumerates all possible input combinations within certain constraints or policies. For instance, inputs may be varied from simpler to more complex cases. However, this method can be computationally expensive and is not covered in this context.
Symbolic Execution: This involves analyzing the program with symbolic inputs rather than concrete ones, generating test cases that satisfy specific path conditions.
Concolic Execution: A hybrid approach combining concrete execution with symbolic analysis. Pseudo-random inputs are generated and refined based on symbolic properties of the program’s paths.
Fuzz Testing (Fuzzing): This method generates a wide variety of inputs, including unexpected or invalid ones, to identify vulnerabilities or edge cases.
Search-Based Testing: This approach uses optimization techniques to explore the input space, aiming to maximize certain metrics such as code coverage, input diversity, or error-detection effectiveness.
Symbolic Execution for Test Case Generation
Symbolic execution is a particularly powerful technique for automated test case generation. Instead of executing the program with concrete inputs, symbolic execution analyzes the program using symbolic variables that represent a range of potential inputs. The key steps in symbolic execution are:
Identify a set of target locations or execution paths in the program.
Perform symbolic execution to explore these paths.
For each path condition determined to be satisfiable (SAT) with respect to a target, generate one or more assignments that satisfy the condition. These assignments serve as test cases.
Repeat this process for all identified paths to construct a comprehensive test suite.
While symbolic execution offers significant advantages in generating precise and targeted test cases, it is not without limitations. It struggles with challenges such as path explosion (the exponential growth of possible paths to analyze) and constraints involving complex or undecidable conditions.
Concrete-Symbolic (Concolic) Execution
Concolic execution, short for concrete-symbolic execution, is a hybrid testing technique that combines the strengths of both symbolic and concrete execution.
Its primary goal is to systematically explore multiple paths within a program by alternately using symbolic reasoning and concrete input execution.
This method helps mitigate the limitations of symbolic execution, such as path explosion and undecidable constraints, by leveraging concrete inputs to guide the exploration process.
In concolic execution, the program’s state is represented by two parallel components:
Symbolic State: Tracks the program’s behavior using symbolic variables that represent sets of potential input values. This symbolic part enables the exploration of alternative execution paths.
Concrete State: Utilizes specific, concrete input values to ensure the program progresses during execution, particularly when symbolic reasoning encounters challenges (e.g., unsupported operations or undecidable conditions).
By combining these two states, concolic execution systematically explores program paths while maintaining practical progress in execution.
Key Steps in Concolic Execution:
Concrete-to-Symbolic Transition: As the program executes with concrete inputs, the symbolic state is updated to reflect the symbolic constraints associated with the explored path. These constraints form the path condition, a logical formula representing the conditions required for the program to follow the observed path.
Symbolic-to-Concrete Transition: To explore new paths, the current path condition is modified by negating one of its conditions, effectively generating a new branch to explore. The modified condition is then solved to produce new concrete inputs that satisfy it, enabling the execution to proceed along the new path.
Example: Path Exploration in a Procedure
To illustrate concolic execution, consider the following simple procedure:
0: void m(int x, int y) {1: int z := 2 * y;2: if (z == x) {3: z := y + 10;4: if (x <= z)5: print("Log message.");6: }7: }
The goal is to explore all possible paths within this procedure.
First Path:
Starting with a concrete input, {x=22, y=7}, the procedure executes and follows the path <0,1,2,6,7>.
The symbolic path condition derived from this execution is 2y ≠ x. This means that for the given inputs, the condition z == x (line 2) was false.
To explore another path, we negate the current path condition: ¬(2y ≠ x) or 2y = x.
Second Path:
Solving the modified path condition (2y = x) produces new input values {x=2, y=1}. With these inputs, the procedure executes the path <0,1,2,3,4,5,6,7>.
The new path condition is 2y = x ∧ x ≤ y + 10, meaning that both conditions at lines 2 and 4 were satisfied.
To explore additional paths, the path condition is further modified. Negating the second part (x ≤ y + 10) results in 2y = x ∧ x > y + 10.
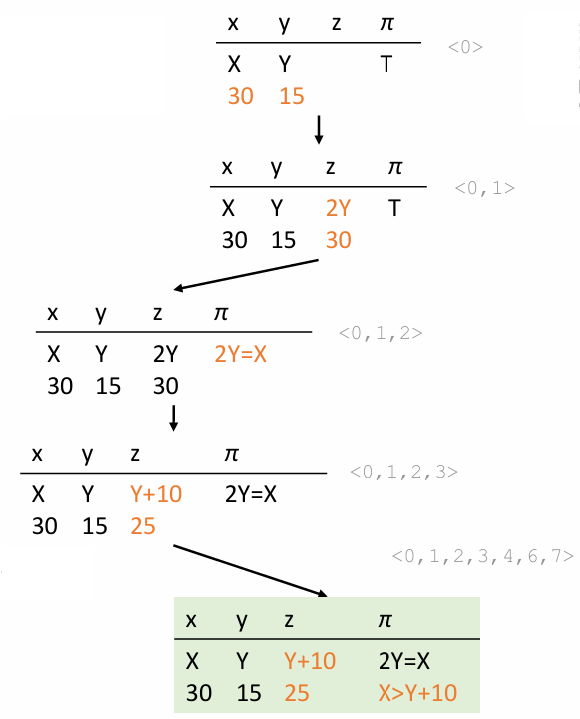
Third Path:
Solving this new condition, we derive {x=30, y=15} as the next input. Executing the procedure with these inputs explores the path <0,1,2,3,4,6,7>.
The corresponding path condition reflects the decisions at each branch.
Using concolic execution, we systematically covered all paths in the procedure with the following test cases:
<0,1,2,6,7>: {x=22, y=7}
<0,1,2,3,4,5,6,7>: {x=2, y=1}
<0,1,2,3,4,6,7>: {x=30, y=15}
Each test case represents a unique sequence of branch decisions, ensuring thorough path coverage.
Example 2: Handling Black-Box Functions
Concolic execution can face additional challenges when programs include black-box functions, which are functions whose internal logic is unknown or inaccessible during symbolic reasoning. To illustrate this, consider a new procedure, m2, where the function bb(y) represents a black-box operation.
0: void m2(int x, int y) {1: int z := bb(y); // Black-box function2: if (z == x) {3: z := y + 10;4: if (x <= z)5: print("Log message.");6: }7: }
The goal is to explore all execution paths of this procedure systematically. However, since the behavior of bb(y) is unknown, symbolic execution alone cannot reason about its output, making it necessary to incorporate concrete execution.
Challenges with Black-Box Functions
Initial Exploration:
Start with a concrete input, for example, {x=22, y=7}.
During execution, bb(y) is evaluated concretely. For this input, assume bb(7) returns 14.
With the concrete result (z = 14), the symbolic condition is updated to reflect the path condition: ¬(bb(y) ≠ x).
However, solving this path condition symbolically is not possible because bb(y) is a black-box function. For instance, solving ¬(bb(y) ≠ x) symbolically requires knowledge of bb(y)’s internal behavior, which is unavailable.
Concrete-to-Symbolic Transition:
To continue exploration, the condition is concretized. Using the concrete result of bb(7) = 14, the symbolic condition becomes ¬(14 ≠ x) or 14 = x.
This enables the exploration of a new execution path with inputs that satisfy x = 14.
Let’s now proceed with the exploration using concrete values.
First Path:
Input {x=14, y=7}.
The execution follows path <0,1,2,6,7>.
The updated path condition is bb(y) = x. For this specific input, bb(7) = 14, which satisfies the condition.
New Path Exploration:
To explore additional paths, the next condition is negated. For instance, if the current condition is bb(y) = x ∧ x ≤ y + 10, negating the second part gives: bb(y) = x ∧ ¬(x ≤ y + 10) or bb(y) = x ∧ x > y + 10.
Solving this condition symbolically is again not possible due to the black-box nature of bb(y).
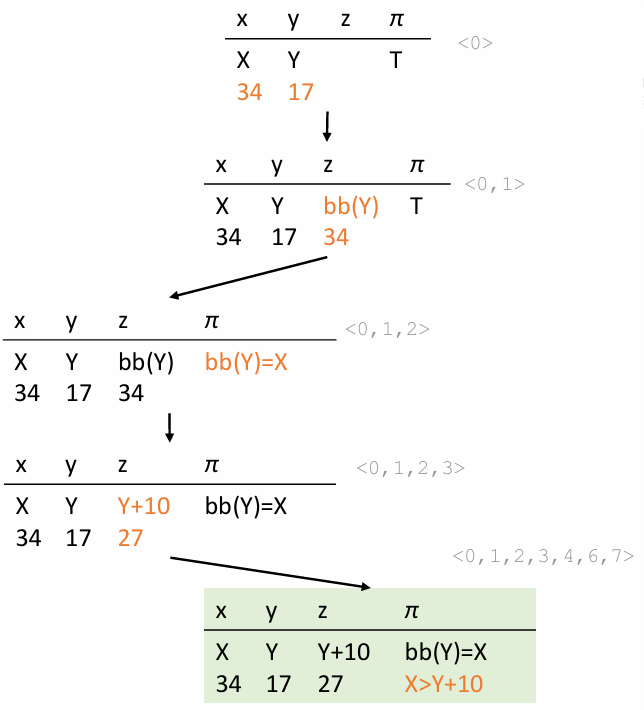
Concretization for Further Exploration:
To proceed, new values for y are chosen randomly, and the black-box function is executed concretely. For instance:
Choose y = 17. Suppose bb(17) = 34.
The condition bb(y) = x ∧ x > y + 10 becomes 34 = x ∧ x > 27.
Solving this yields x = 34, which satisfies the condition.
In cases where black-box functions are involved, concolic execution alternates between symbolic reasoning and concrete execution to explore paths:
The black-box function is executed with specific inputs to produce concrete results, which are used to update the symbolic state.
New paths are explored by negating parts of the symbolic path condition and using concrete values to resolve constraints that cannot be symbolically solved.
By repeating this process, concolic execution systematically explores all feasible paths.
Concolic execution: pros and cons
Advantages
Limitations
Can deal with black-box functions in path conditions (not possible with symbolic execution)
Finds just one input example per path, however… Failures typically occur with certain inputs only
As symbolic execution, can generate concrete test cases automatically
If failures are rare events, it’s unlikely to spot them with concolic execution number of paths explode due to complex nested conditions → large search space
Does not guide the exploration, it just explores possible paths one by one as long as we have budget (e.g., time, number of runs)