The advent of big data represents a transformative force across diverse domains, reshaping industries, accelerating scientific progress, and significantly altering societal dynamics. The concept of big data is encapsulated in the 5Vs framework, which highlights its defining characteristics: volume (the immense scale of data generated daily), velocity (the speed at which data is produced and processed), variety (the diverse forms data can take, such as text, images, or sensor data), veracity (the importance of ensuring data accuracy and reliability), and value (the potential to derive actionable insights and benefits from data).
The unprecedented capabilities for data collection today stem from widespread digitalization, advanced sensors, and ubiquitous computing. These data streams, when coupled with enormous computational power and massively parallel processing, offer remarkable opportunities. For example, big data analytics can enhance people’s lives through personalized recommendation systems that suggest books, movies, or career opportunities tailored to individual preferences. In the realm of science, big data drives discoveries, especially in fields like medicine, where genomic data analysis enables precision treatments. In technology and innovation, applications like autonomous vehicles exemplify how data-rich environments are leading to groundbreaking advancements. Additionally, big data empowers societal transformation by promoting transparency through open government initiatives and optimizing businesses through highly targeted advertisements.
While the promise of big data is vast, its transformative power is accompanied by significant ethical concerns, particularly in the realm of data management and usage.
The Ethical Dimensions of Data Management
Data has become deeply integrated into nearly every aspect of modern life, influencing personal decisions, societal norms, and organizational strategies. As a result, understanding the ethical implications of data-driven systems is crucial. One pressing concern is how algorithms and systems might inadvertently propagate bias, resulting in discriminatory outcomes. For instance, search and recommendation engines, while useful, have the potential to shape users’ perceptions and opportunities. A glaring example is job recommendation platforms that disproportionately show high-paying roles to specific demographic groups, such as white males, due to biased training data. Such outcomes not only perpetuate inequality but also highlight the systemic challenges of ensuring fairness in algorithm design.
Similarly, the pervasive use of statistical methods in decision-making across sectors such as healthcare, finance, and public policy raises questions about accountability and oversight. Decisions derived from data analysis can have far-reaching consequences, yet ethical considerations often remain secondary to efficiency or profit motives. For instance, critical policy decisions informed by data may neglect the potential social or moral repercussions, leading to unjust outcomes for vulnerable populations.
To reconcile the vast potential of big data with its ethical challenges, stakeholders must adopt a proactive approach. This includes embedding fairness, accountability, and transparency into the design and deployment of data-driven systems. Developing algorithms that are free from bias requires diverse and representative datasets, robust testing frameworks, and ongoing evaluation to identify and mitigate unintended consequences. Additionally, there is a need for interdisciplinary collaboration among technologists, ethicists, policymakers, and industry leaders to establish ethical guidelines and regulatory standards.
A common misconception about big data processing is the belief that algorithms, by virtue of being mathematical constructs, are inherently objective. This assumption overlooks the reality that algorithms are deeply influenced by the data they process, and data itself can carry biases originating from societal, historical, or systemic factors. For instance, biased datasets can skew results, perpetuating or amplifying inequities already present in the real world. Additionally, many algorithms, particularly in complex systems like deep neural networks, operate as “black boxes,” producing outputs through processes that are difficult, if not impossible, to fully explain. This has given rise to the growing field of AI research focused on explainability, which seeks to make these opaque processes more transparent and understandable.
However, technology alone cannot address these challenges. Ethical, legal, and interdisciplinary competence must accompany the development and application of big data systems to ensure their responsible use.
Ethical Responsibility in Data Management
Ethics in data management revolves around the concept of responsibility. Data scientists play a pivotal role in shaping the outcomes of data-driven processes. Their responsibilities include identifying datasets that genuinely address the problem at hand, comprehensively understanding the content and limitations of these datasets, and selecting the most appropriate methods for extracting knowledge—whether through search queries, data analysis, or advanced AI techniques. Each decision made along this chain of actions can significantly influence the results. A poorly chosen dataset or technique may yield biased or misleading outcomes, further emphasizing the critical role of ethical decision-making in this domain.
Moreover, the responsibilities of data scientists extend beyond technical competence. They must actively consider the societal implications of their work, ensuring that processes and results align with ethical principles such as fairness, transparency, and inclusivity. This involves recognizing and mitigating potential biases, designing systems that uphold data protection standards, and fostering diversity in both datasets and decision-making frameworks.
The Role of the AI and Database Communities
The broader AI, database, and computer engineering communities must also address these ethical challenges. Their role is not only to advance technical capabilities but also to embed ethical considerations into the foundations of their disciplines. This raises several critical questions:
- How can these communities ensure that data protection, transparency, diversity, and fairness become integral to the design and operation of their systems?
- Should these principles drive the development of new methodologies, tools, and algorithms?
- What mechanisms can be implemented to enforce these ethical dimensions throughout the lifecycle of data-driven projects?
By placing ethical principles at the core of their work, these communities can foster a culture of accountability and innovation that prioritizes societal well-being.
To achieve these goals, it is essential to develop comprehensive frameworks that integrate ethical and legal considerations into every stage of big data processing. Such frameworks should provide clear guidelines for addressing issues like bias detection, explainability, and equitable representation. Additionally, fostering interdisciplinary collaboration—between technologists, ethicists, policymakers, and sociologists—can create systems that not only advance knowledge but also uphold societal values.
Data Protection
Traditional systems for extracting knowledge, such as database systems, search engines, and data warehouses, historically paid little attention to ethically sensitive aspects of their processes or outcomes. These gaps in consideration, however, are increasingly concerning, particularly when the protection of human rights intersects with the outcomes of data-driven systems. The growing emphasis on data protection reflects broader societal demands for ethical accountability, as seen in corporate codes of ethics, professional guidelines for computer scientists, and legally binding frameworks like the EU General Data Protection Regulation (GDPR).
The GDPR represents a milestone in global data protection efforts. It unifies data protection laws across all EU member states, ensuring consistent safeguards for personal data. This regulation grants EU citizens a comprehensive set of rights over their personal data, ranging from consent and access to the right to be forgotten. It also imposes strict requirements on companies and organizations for the collection, storage, and processing of personal data, emphasizing accountability and transparency. Since its full enforcement in May 2018, the GDPR has reshaped how organizations worldwide approach data ethics, pushing data privacy from a technical afterthought to a central design principle.
Fairness in Data
Definition
The concept of fairness in data is fundamentally about eliminating bias to ensure equitable outcomes.
Its importance has gained increasing recognition in light of troubling consequences stemming from the use of biased datasets to train algorithms. For instance, machine learning models trained on skewed data can perpetuate systemic inequities, such as discriminatory hiring practices or unjust criminal sentencing. These examples underscore the critical need to address fairness in both data collection and processing stages.
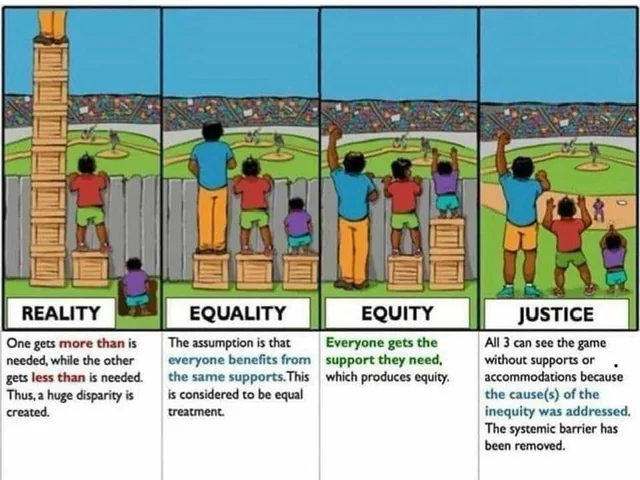
Fairness itself is a nuanced concept, often interpreted differently depending on the context. Two prominent frameworks include equality (treating all individuals identically) and equity (tailoring actions to achieve proportional fairness based on varying needs). Both perspectives hold value, but their application depends heavily on the specific goals and societal contexts of the data-driven system.
Fairness is not a monolithic concept, as it can be understood in multiple ways depending on philosophical, cultural, or domain-specific perspectives. Scholar H. Jagadish highlights this complexity, suggesting that fairness requires careful consideration to align technical practices with broader societal values. Whether the focus is on algorithmic neutrality, representational inclusivity, or outcome equity, fairness remains a critical challenge that must be addressed collaboratively across disciplines.
As society continues to rely on data-driven systems, fairness and data protection must be treated as essential pillars of ethical innovation.
Transparency
Definition
Transparency in data systems refers to the ability to interpret and understand the processes through which information is extracted and analyzed.
It allows stakeholders to identify which aspects of the data contribute to specific outcomes, fostering trust and accountability in data-driven decisions. In this context, transparency can be measured through concepts like:
- Data provenance, which provides insight into the origins and sources of the data used, ensuring traceability and credibility.
- Explanations, which clarify how results were obtained, shedding light on the computational and algorithmic pathways involved.
While transparency is crucial for accountability and trust, it may sometimes conflict with data protection. For instance, disclosing detailed data sources or algorithmic processes could inadvertently expose sensitive information or violate privacy regulations. Striking a balance between these priorities is essential to ensure ethical data practices without compromising user rights.
Diversity
Definition
Diversity measures the extent to which different types of objects or perspectives are represented within a dataset.
This dimension is essential for reducing bias and promoting inclusivity in data-driven systems. For example, a dataset that incorporates diverse demographic, cultural, or situational perspectives is more likely to produce fairer and more equitable outcomes.
Ensuring diversity early in the data collection process can contribute to fairness later on, as it prevents the dominance of narrow or homogeneous viewpoints that may skew results. However, pursuing diversity can sometimes conflict with traditional data quality standards, which prioritize consistency and reliability, often derived from a limited number of high-reputation sources. Balancing these competing demands is a key challenge in creating ethical data systems.
Ethics and Data Quality: A Symbiotic Relationship
Ethical considerations are deeply intertwined with data quality. Trust in information and its outcomes relies heavily on typical data quality attributes such as accuracy, consistency, and reliability. However, an equally important perspective is that ethical standards must be met for data to be deemed of high quality. For instance, even technically accurate data may be considered poor quality if it was obtained unethically, such as through the invasion of privacy or exploitation.
This relationship underscores that meeting ethical requirements—such as fairness, transparency, and diversity—is a prerequisite for asserting the quality of data and its derived results. Responsibility for ensuring these properties rests on both the system designer and the entity commissioning the work, whether an individual, organization, or company. Together, they must ensure that ethical principles are embedded into every stage of the data lifecycle, from collection to analysis.
By embedding ethics into data quality frameworks, we create systems that are not only technically robust but also socially responsible, fostering trust and equity in the increasingly data-driven world.