As we saw, a datatcenter is composed by four major components: servers, storage, networking, and building infrastructure.
Server
Servers hosted in individual shelves are the basic building blocks of a warehouse scale computer. They are interconnected by hierarchies of networks, and supported by the shared power and cooling infrastructure.
Unlikely ordinary computers, servers are designed with a form factor that allows to fit them into the shelves. The most common form factors are the Rack (1U or more), the Blade enclosure, and the Tower. Independently from the form factor, the server is composed by a motherboard, at least one CPU, memory and storage devices, and network interface cards (like any other normal computer).
The motherboard provides sockets and plug-in slots to install CPUs, memory modules (DIMM slots), local storage (e.g., SSDs, HDDs), and network interface cards (NICs) to satisfy the wide range of requirements of the applications running on it. The motherboard also provides the power supply unit (PSU) to power the server and the cooling system to keep the components at the right temperature. WSCs use a relatively homogeneous hardware and system software platform. The number of and type of CPUs (from 1 to 8, from Intel Xeon to AMD EPYC and other), the amount of available DIMM slots (from 2 to 192) for the memory, the number of drive bays (from 1 to 24), the type of storage device (from HDD to SSD), the connection protocol (SATA, SAS, NVMe), and other special purpose device, like GPUs (from 1 to 20 per nodes), TPU, FPGAs, etc. are the main parameters that can be customized to meet the specific requirements. Even the physical form factor can be customized, with the most commons being the

Tower Servers
Towers are the most common form factor for servers for small and medium businesses. They are designed to be placed on the floor, to be easy to install and maintain. They are usually equipped with a single or dual CPU, a limited number of DIMM slots, and a limited number of drive bays. They are usually equipped with a single or dual power supply, and they are designed to be used in a single server configuration.
Pros:
- scalability and ease of upgrade allows to customize the server to the specific needs of the business
- cost-effective: they are probably the cheapest of all the form factors, making them the ideal solution for small and medium businesses
- it is easy to cool, since it has a low overall component density and a lot of empty space inside the case to allow the air to flow
Cons:
- this type of form factor consumes a lot of space and are difficult to manage physically
- they provide a basic level of performance and are not designed to be used in a datacenter environment
- the cable management can be a problem since all the cables are connected to the back of the server
Rack Servers
Racks are special shelves that accomodate all the IT equipment and allow their interconnection. Shelves are used to store these rack servers, which are designed to be installed one on top of the other. The advantage of using these racks is that it allows designers to stack up other electronic devices along with the servers, such as switches, routers, and other networking equipment.
Server racks are measured in rack units (U), which are the standard unit of measure for server height. A single rack unit (1U) is equal to 1.75 inches (44.45 mm) in height. The IT equipment must conform to specific size to fit into the rack shelves. The most common rack servers are 1U, 2U, 4U, and 8U.
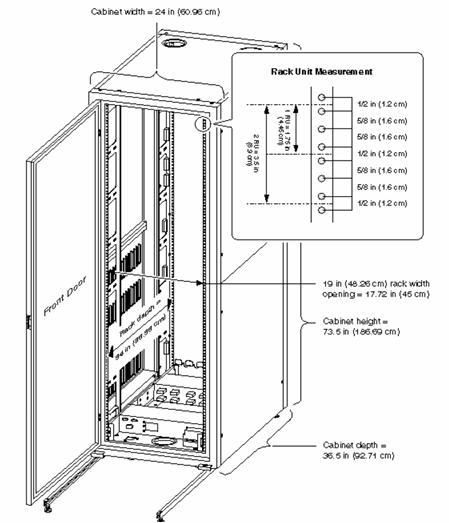
A rack server is designed to be positioned in a bay, by vertically stacking servers one over the another along with other devices (storage units, cooling systems, network peripherals, batteries)
Pros:
- failure containment: very little effort to identify and replace a failed component in a rack server
- simplified cable management: all the cables are connected to the back of the rack, so it is easy to manage them and to keep the server room clean
- cost-effective: computing power and efficiency are maximized in a small space and at relatively low cost
Cons:
- power usage: needs of additional cooling systems due to their high overall component density, thus consuming more power
- maintenance: since multiple devices are placed in rack together, maintaining them gets considerably tough with the increasing number of racks
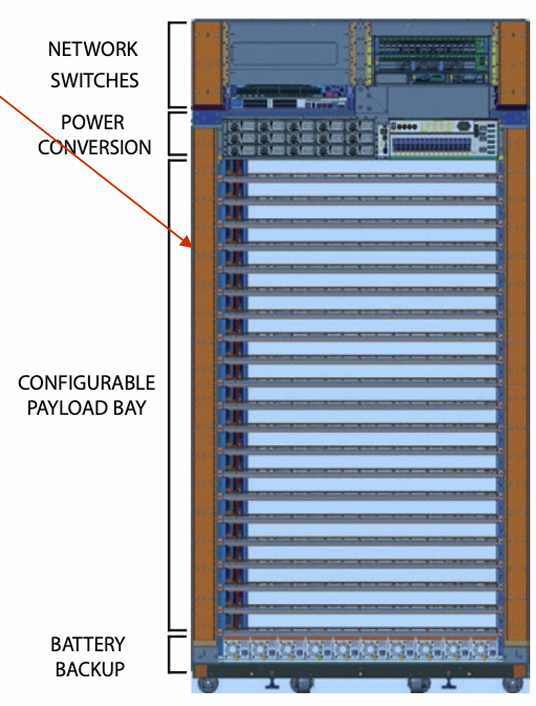
The rack is not only a physical structure: it holds tens of servers together, handles the shared power infrastructure, including the power delivery, battery backup, and power conversion units, and it’s often convenient to connect the network cables at the top of the rack. Such a rack-level switch is appropriately called a Top-of-Rack (ToR) switch.
Blade Servers
Blade servers are the latest and the most advanced type of servers in the market. They can be termed as hybrid rack servers, in which servers are placed inside blade enclosures, forming a blade system. The biggest advantage of blade servers is that these servers are the smallest types of servers available at this time and are great for conserving space. They can also be installed in the shelve, increasing the overall density of the rack.
NOTE
A blade system also meets the IEEE standard for rack units and each rack is measured in the units of “U’s” (1U = 1.75 inches) as the rack servers.
Pros:
- Load balancing and failover: thanks to its much simpler and slimmer infrastructure, load balancing among the servers and failover management tends to be much simpler.
- Centralized management: in a blade server, you can connect all the blades through a single interface, making the maintenance and monitoring easy.
- Cabling: blade servers don’t involve the cumbersome tasks of setting up cabling. Although you still might have to deal with the cabling, it is near to negligible when compared to tower and rack servers.
- Size and form-factor: they are the smallest and the most compact servers, requiring minimal physical space.
Cons:
- Expensive configuration: although upgrading the blade server is easy to handle and manage, the initial configuration or the setup might require heavy efforts in complex environments. Also, the cost of blade servers is higher than the other types of servers.
- HVAC (Heating, Ventilation, and Air Conditioning): blade servers are very powerful and come with high component density. Therefore, special accommodations have to be arranged for these servers in order to ensure they don’t get overheated. Heating, ventilation, and air conditioning systems must be managed well in the case of blade servers
Accelerated Components
Most of the task in a WSC are compute-bound, meaning that they require a lot of computational power and special hardware to be executed. The most common hardware used in WSCs are GPUs, TPUs, and FPGAs. It seams that the complexity of the task is doubling every 3.5 months, and the computational power is doubling every 3 months, mush faster than the Moore’s Law prediction.
Deep learning models began to appear and be widely adopted, enabling specialized hardware to power a broad spectrum of machine learning solutions. Since 2013, AI training compute requirements have doubled every 3.5 months, resulting in a 300,000x increase in compute requirements. To satisfy the growing compute need for deep learning, WSCs deploy specialized accelerator hardwares, such as GPUs, TPUs, and FPGAs.
GPUs
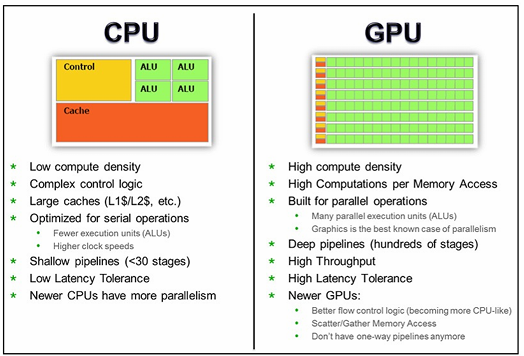
GPUs are the most common accelerator hardware used in WSCs. They are capable of performing data-parallel computations, allowing the same program to be executed on many data elements simultaneously in parallel, at much higher speeds than CPUs. A specific use case for GPUs are the scientific codes that can be parallelized (such as matrix operations) and mapped onto the matrix operations that GPUs are optimized for. To perform these operations, developers use libraries like CUDA, OpenCL, and OpenACC.
The performance of such a synchronous parallel computation is limited by the slowest learner and slowest messages through the network. Since the communication phase is in the critical path, an high performance network can enable fast reconciliation of parameters across learners, and thus reduce the time to solution.
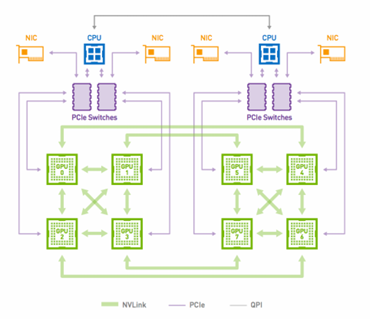
GPUs are configured with a CPU host connected to a PCIe-attached accelerator tray with multiple GPUs. GPUs within the tray are connected using high-bandwidth interconnects, such as NVLink or PCIe. The most common GPU in WSCs are the NVIDIA Tesla V100 (about
TPUs
While suited to ML, GPUs are still relative general purpose device. In recent years, designers further specialized the to ML-specific hardware, with custom-built integrated circuit developed specifically for machine learning and tailored for TensorFlow. These are called Tensor Processing Units (TPUs) and power Google Datacenters since 2015 as well as CPUs and GPUs.
Definition
A Tensor is a mathematical object analogous to but more general than a vector, represented by an
-dimensional matrix; it’s the basic unit of operation in with TensorFlow.
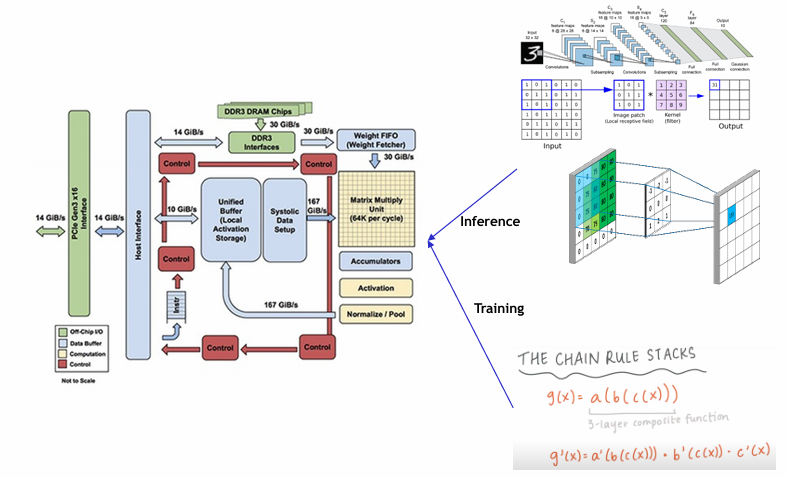
TPUs are used for training and inference of ML models. They are designed to be fast at performing dense vector and matrix computations, and are specialized on running very fast programs based on TensorFlow.
- TPUv1 is an inference-focused accelerator connected to the host CPU through PCIe links, mainly used as generic accelerator for inference tasks.
- TPUv2 is a training-focused accelerator connected to the host CPU through a high-bandwidth network, mainly used for training tasks.
- TPUv3 is a supercomputing-class accelerator connected to the host CPU through a high-bandwidth network, mainly used for large-scale ML models.
Each Tensor Core has an array for matrix computations (MXU) and a connection to high bandwidth memory (HBM) to store parameters and immediate values during computation. The MXU is capable of performing
TPUv2 are characterized by 8 GB of HBM for each core, one MXU per core, 4 dual-core chips. In a rack, multiple TPUv2 accelerator boards are connected through a custom high-bandwidth network to provide 11.5 petaflops of ML compute. The high bandwidth network enables fast parameter reconciliation with well-controlled tail latencies. TPUv2 in rack are usually called Pods; typically a pod has 64 units, with 512 total TPU cores and 4 TB of total memory.
TPUv3 is the first liquid-cooled accelerator in Google’s data centers. It’s 2.5x more powerful than TPUv2. Such supercomputing-class computational power is suitable for large-scale ML models, such as BERT, GPT-2, and ResNet-50. The v3 Pod provides a maximum configuration of 256 devices for a total of 2048 TPUv3 cores, 100 PFlops and 32 TB of HBM.
FPGAs
Definition
A Field Programmable Gate Array (FPGA) is an integrated circuit designed to be configured by a customer or a designer after manufacturing – hence the term “field-programmable”. The FPGA configuration is generally specified using a hardware description language (HDL), similar to that used for an application-specific integrated circuit (ASIC).
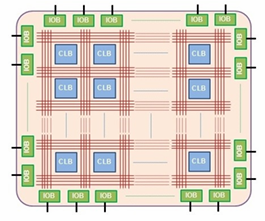
The array is carefully designed and interconnected with digital subcircuits that efficiently implement common functions offering very high levels of flexibility. The digital subcircuits are called configurable logic blocks (CLBs). The CLBs are interconnected by a matrix of programmable routing resources, which allow the CLBs to be interconnected in almost any configuration. The FPGA also contains I/O pads that allow it to be connected to other devices.
Languages like VHDL and Verilog are used to “describe” the hardware. HDL code is more like a schematic that uses text to introduce components and create interconnections.
Comparison
| Advantages | Disadvantages | |
|---|---|---|
| CPU | - Easy to be programmed and support any programming framework - Fast design space exploration and run your applications | - Most suited for simple AI models that do not take long to train and for small models with training set |
| GPU | - Ideal for applications in which data need to be processed in parallel like the pixels of images and videos | - programmed in languages like Cuda and OpenCL and therefore provide limited flexibility compared to CPUs |
| TPU | - Very fast at performing dense vector and matrix computations and are specialized on running very fast program based on TensorFlow | - For applications and models based on the TensoFlow - Lower flexibility compared to CPUs and GPUs |
| FPGA | - Higher performance, lower cost and lower power consumption compared to other options like CPUs and GPUs | - Programmed using OpenCL and High-level Synthesis (HLS) - Limited flexibility compared to other platforms. |