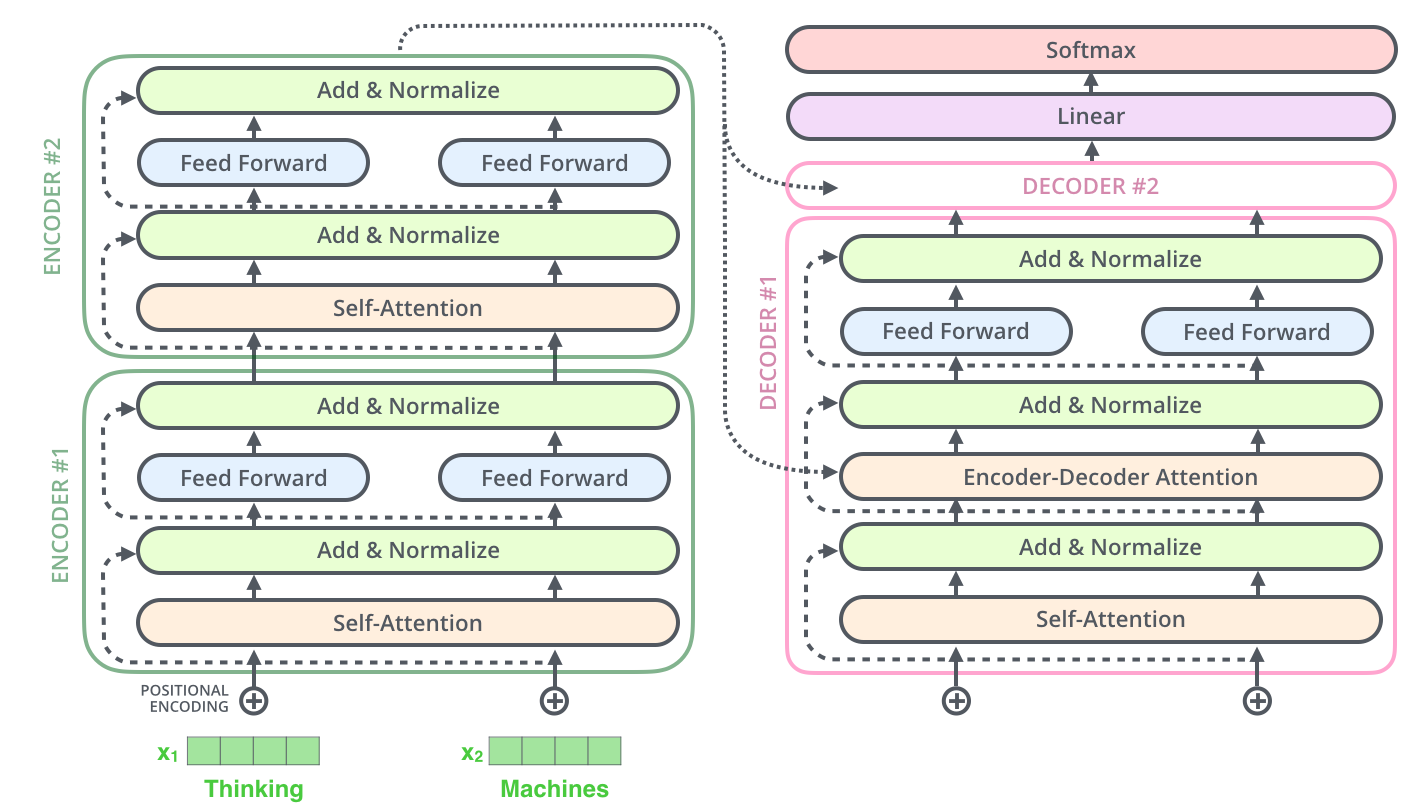
The Transformer model was introduced in the paper Attention is All You Need by Vaswani et al. in 2017. It was brilliant, but looked rather complicated because it contained both an encoder and a decoder, and it was hard to understand how it worked. However, the internal architecture is actually surprisingly simple. Basic self-attention module contains:
- multiple attention heads working in parallel
- feedforward network, with residual connections and normalization
The architecture of the Transformer model is designed to be agnostic to the position of words. To address this, positional encoding is added as an additional input to the bottom layer.
Three components of self-attention are involved in the Transformer model:
- The query represents the word in the current position and is obtained by embedding it.
- The key represents the other words in the series and is obtained by applying a linear transformation.
- The value represents the word that will be updated and is obtained by embedding it.
Each of these components is derived from the original embedding through a linear mapping (reduction).
The attention score is calculated using the formula:
Internals of the Transformer Architecture
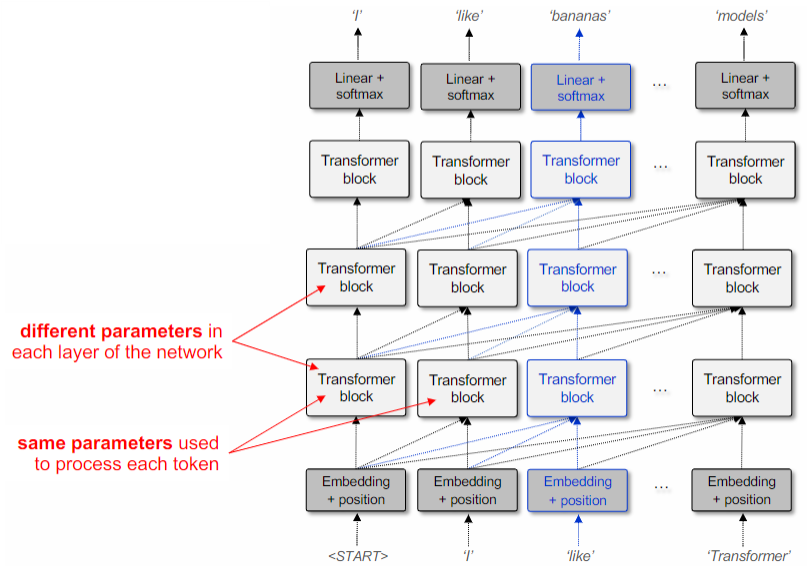
The Transformer model is composed of three main components:
- The input module, which generates the initial embedding for each token.
- Multiple transformer blocks that are stacked on top of each other. These blocks modify the embedding at each position.
- The output module, which predicts the word based on the modified embedding.
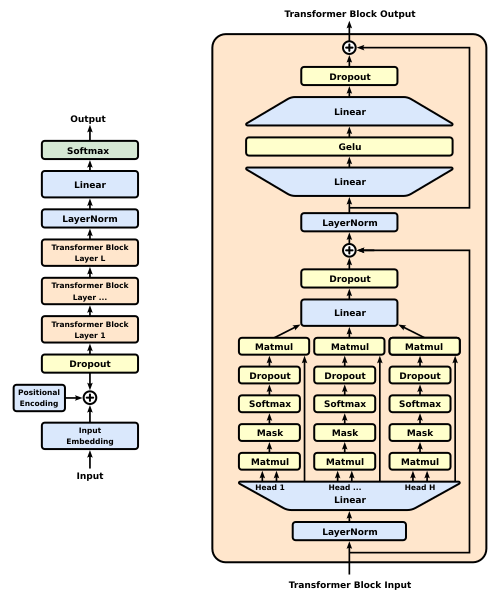
Each Transformer block updates the input embedding by incorporating information from a self-attention block and a Feed-Forward Neural Network (FFNN). The self-attention block consists of multiple self-attention heads, each operating on an embedding of size
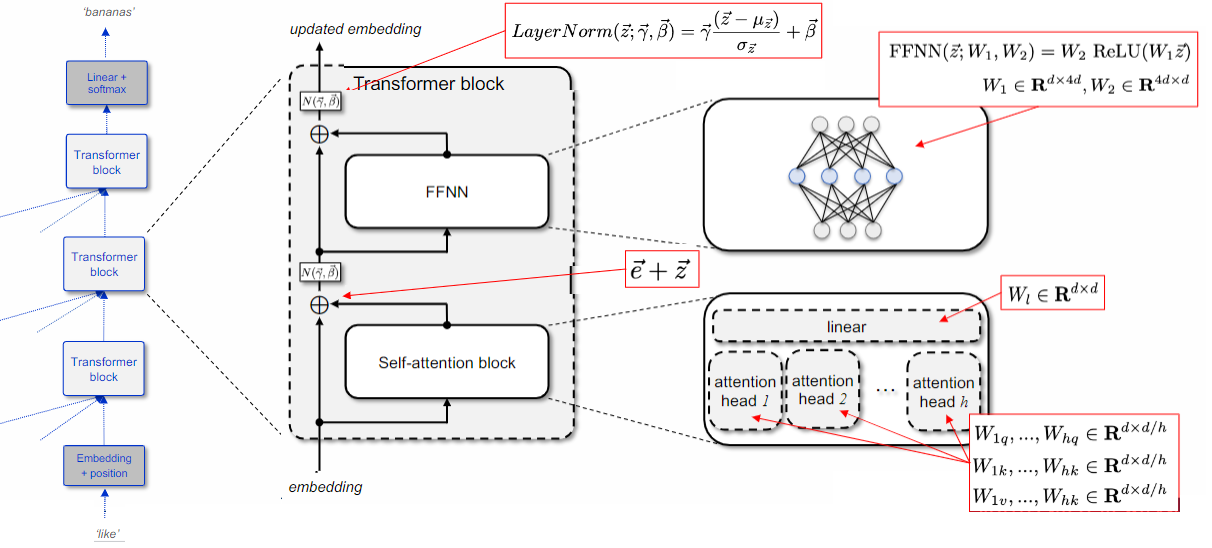
Calculations for a single layer of self-attention is just a series of matrix multiplications/manipulations in which all token positions are updated in parallel and all attention heads are computed at same time. Steps:
- calculate
, and matrices - multiply
and matrices; for autoregressive model, multiply also by masking matrix to set similarity with future token positions to zero - apply
to rows of resulting matrix - multiply attention weights by
matrix - for multi-head attention, concatenate each head output and multiply by output matrix
The self-attention module in the Transformer is repeated multiple times, allowing the meaning of each token to accumulate over multiple steps.
Transformers are much faster to train compared to stacked RNNs, as the gradient does not need to be iterated back along the sequence in Transformers.
Generating Input
Tokenizing Text for Transformers
When deciding whether to use word-level or character-level representations in a model, it is important to consider computational trade-offs. The choice depends on the balance between the expressivity of the sequence and the length of the sequence, which affects inference complexity. Additionally, the choice may also depend on the language being used.
EXAMPLE
Chinese language uses logograms at the syllable level rather than the character level (unless converted to pinyin). Similarly, DNA and protein sequences have few characters and no word spaces.

When using words as tokens, the number of tokens generated is much larger, such as 1 million tokens for English Twitter, and even more for multilingual text. However, this approach does not make use of or explicitly model morphological information. On the other hand, using characters as tokens results in longer sequence lengths. This puts a burden on the model to learn and reason over word structures, as the embeddings contain a lot of disjointed information. Additionally, using characters as tokens makes the model much less interpretable.
To break up words into sub-word tokens, we can utilize the data by following these steps:
- Perform byte-pair encoding to identify frequent character sequences.
- Iteratively replace the most common consecutive characters with new characters.
though they think that the thesis is thorough enough
th -> θ:
θough θey θink θat θe θesis is θorough enough
ou+g+h -> ə:
θə θey θink θat θe θesis is θorə enə
θe -> ψ:
θə ψy θink θat ψ ψsis is θorə enəIn this way, common prefixes/suffixes become vocabulary elements, and the model can learn to generalize over them.
Example
Embedding Positional Information
The Transformer architecture is designed to be symmetric, meaning it is agnostic to the ordering of input features. However, in natural language processing, the meaning of text often depends on the order of words. Therefore, it is important to provide the model with information about the order of words in the text. We need to inform the model about the order of words in the text
- “I want my mommy” ⇒ (“I”, 1) (“want”, 2), (“my”, 3), (“mommy”, 4)
- Embedding [“my”,3] = embedding[“my”] + embedding[3]
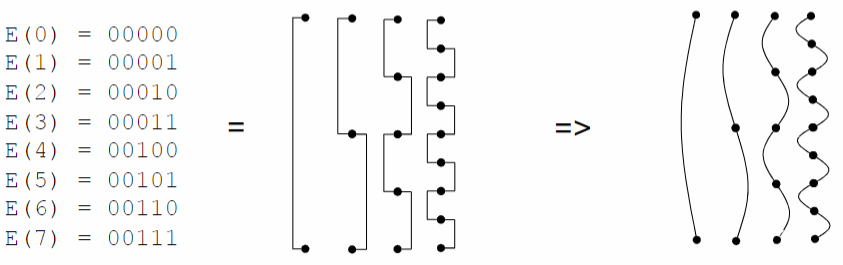
The most straightforward approach to achieve this is by utilizing a binary encoding of the position. However, considering that the embedding vector consists of floating-point values, it is more logical to encode positions using sinusoids.
The Transformer model has proven to be highly successful in natural language processing tasks. One of the reasons for its success lies in its ability to learn complex language relationships and build dependency parse trees over concepts in the text. Through self-attention, the model can identify patterns and extract meaningful information from the input text, such as identifying noun phrases that correspond to named entities. Additionally, the feed-forward layer in the Transformer acts as a key-value memory, allowing the model to retrieve relevant facts for entities. This combination of self-attention and feed-forward layers contributes to the Transformer’s impressive performance in language understanding and generation tasks.
BERT (Bidirectional Encoder Representations from Transformers)
BERT, introduced in a 2019 paper by Devlin et al. from Google, is a groundbreaking model designed to improve the representation of text for various natural language processing tasks. Unlike many models that process text in one direction, BERT is bidirectional, allowing it to consider the context from both sides of a word simultaneously.
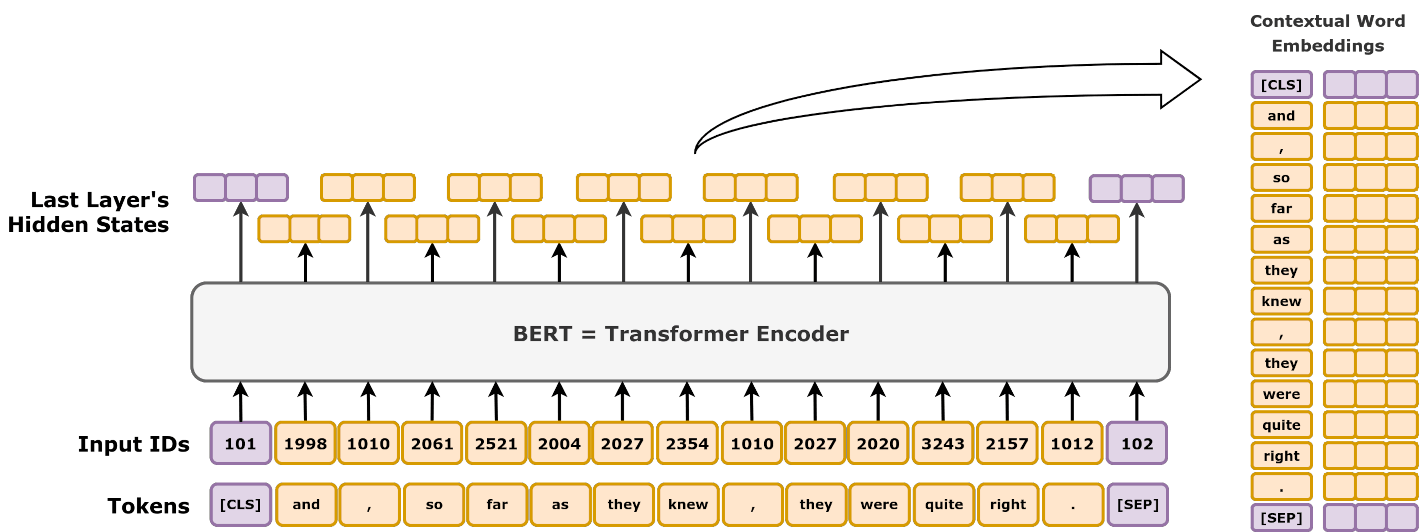
This model operates as an autoencoder: text is input at the bottom, and the same text emerges at the top after processing. The training process involves masking random words in the input using a special [MASK] token, with the model learning to recover these masked words. This method ensures that BERT develops a deep understanding of language context, making it particularly effective for tasks such as text classification.
BERT was trained on a vast corpus that includes Wikipedia and a collection of books, resulting in robust language representations. The base model of BERT contains 110 million parameters, while the larger version includes 340 million parameters. Numerous variants of BERT have been developed to enhance its capabilities further.
| Variant | Description |
|---|---|
| RoBERTa | Facebook’s version of BERT, modifies slightly training objective, trained on more data with larger batches |
| XLNet | BERT with some GPT-2, introduces autoregressive modelling (GPT-2) into BERT training, was quite hyped for a while |
| DistilBERT | A distilled version of BERT, designed to be smaller (40%) and faster (60%) to fine-tune, while retaining 97% of accuracy |
These variants, along with many others, are pretrained for specific text domains or fine-tuned for particular tasks such as question answering.
GPT (Generative Pretrained Transformer)
GPT, particularly known through its second version, GPT-2, introduced in a 2019 paper by Radford et al. from OpenAI, represents a significant advancement in text generation capabilities. Unlike BERT, GPT is an autoregressive model where the input text is processed sequentially, predicting the next token by shifting the text one position to the left.
The training of GPT involves a mask matrix that hides future words, allowing the model to generate coherent and contextually appropriate text by predicting the next word in a sequence. GPT-2 was trained on an extensive dataset of 40GB of web text curated based on high ratings by Reddit users. This vast and diverse dataset enables GPT-2 to generate high-quality text across various topics.
The largest GPT-2 model boasts 1.5 billion parameters and a vocabulary of 50,257 tokens, illustrating its substantial capacity for nuanced text generation. Both BERT and GPT-2 leverage the transformer architecture, with varying numbers of self-attention layers, embedding sizes, and parallel attention heads, which contribute to their performance and computational requirements.
While BERT excels in tasks requiring deep understanding and representation of text, GPT is unparalleled in its ability to generate coherent and contextually appropriate text. Both models adhere to the principle that the quality of the output is heavily dependent on the quality of the input data, leading to their training on extensive, high-quality text corpora.
| Characteristic | BERT | GPT |
|---|---|---|
| Model Type | Bidirectional model | Autoregressive model |
| Context Consideration | Considers context from both sides of word | Processes text sequentially |
| Training Data | Trained on vast corpus | Trained on curated web text |
| Language Understanding | Deep understanding of language context | Generates coherent and contextually appropriate text |
| Task Suitability | Suitable for text classification tasks | Ideal for text generation tasks |
Usage of Transformers
Text Classification with BERT
Transformers enable transfer learning in text by leveraging pre-training on large amounts of data. This allows the model to be fine-tuned on specific tasks with limited training data. Transfer learning in text can greatly improve performance, even with small training corpora, as the model retains knowledge from unsupervised pre-training and preserves word order. Multilingual BERT, for example, has been pre-trained on 104 languages, making it possible to train a classification model on English documents and apply it to Italian ones. This opens up incredible possibilities for resource-constrained languages.
In traditional text classification, the initial step is to determine the types of features to extract from the text (such as
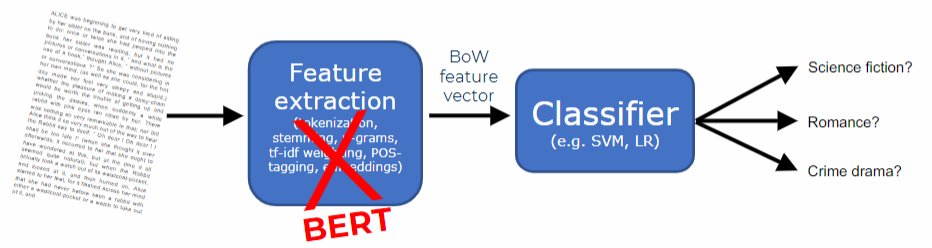
To implement BERT in practice, follow these steps:
- Download a pre-trained BERT model that suits your needs, such as type, lowercase, or multilingual.
- Determine the size of the model that you want to use.
- Fine-tune the model using your labeled training data for your specific task.
- Spend time adjusting the learning rate to ensure that the model is effectively learning without collapsing or overfitting to the training data.
Compared to training simpler text classifiers like logistic regression or an SVM, there are some drawbacks to using Transformers:
- There is a limit on the length of the text, usually less than 1000 tokens, which may require breaking the text into smaller chunks.
- Training the model requires fast hardware, such as GPUs, which may not be readily available on laptops.
- Training the model takes longer and requires more effort.
- The model itself will be larger, requiring more memory and potentially slowing down predictions.
- Predictions from the model are less interpretable, although techniques like LIME can help explain them.
- On the positive side, there is no need for feature engineering, such as choosing to run stemming or using n-grams.
When fine-tuning BERT, a special [CLS] token is added to the beginning of the text. Instead of predicting a word in that position, the model is trained to generate the class label. This approach allows BERT to be fine-tuned for a variety of tasks, including single text classification, text pair classification, question answering, and sequence labeling.
Text Generation with GPT
GPT-2 is an impressive text generator that can produce highly believable and creative content when conditioned on a large piece of text. However, it is important to note that the generated content may sometimes lack common sense or contradict reliable sources of factual information.
While newer and larger models like GPT-3 and GPT-4 have reduced the number of nonsensical statements, they still have the potential to generate untruths, similar to how humans can sometimes make mistakes. The appropriateness of these untruths depends on the specific task at hand.
Text generation plays a crucial role in various applications, ranging from question answering to chatbots. In recent years, it has been applied to even more tasks, such as classification and data integration. Therefore, the development of models that significantly improve text generation performance is a significant advancement in the field.
Overall, GPT-2 and its successors have revolutionized text generation capabilities. While they have their limitations, they offer immense potential for enhancing various natural language processing tasks and opening up new possibilities in the realm of automated content generation.
References
- The Illustrated Transformer – Visualizing machine learning one concept at a time.
- Transformers: a Primer
- Attention in transformers, visually explained - YouTube
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)