A Pushdown Stack Automaton (PDA) is a theoretical computational model equipped with an auxiliary memory structure organized as an unbounded stack of symbols. This stack operates on a Last-In-First-Out (LIFO) principle, which means that the most recently added symbol is the first to be removed. The stack is crucial to the automaton’s functioning, as it helps manage additional information that the finite state automaton alone cannot store, allowing the PDA to recognize a broader class of languages, specifically context-free languages.
The stack in a Pushdown Automaton is conceptually visualized as follows:
In this representation,
The input string, or source string, is a sequence of characters fed into the PDA:
In this notation,
The Pushdown Automaton is equipped with a limited set of operations that it can perform on the stack:
Operations
Push Operation: The automaton can push one or more symbols onto the stack, extending the contents of the stack. For instance, the operation
adds the symbol to the top of the stack, while adds multiple symbols to the stack in the same order. Pop Operation: The automaton can pop the top symbol from the stack, provided the stack is not empty. This operation removes the top symbol, from the stack. If the stack is empty, the automaton reads the bottom symbol without removing it.
Stack Emptiness Test: The automaton can check whether the stack is empty. This test returns true if there are no symbols on the stack (except for the bottom symbol ); otherwise, it returns false.
At any point in its computation, the Pushdown Automaton’s configuration can be described as a triple:
This triple represents the automaton’s current state, the character from the input string it is reading, and the current contents of the stack. This configuration evolves as the automaton processes the input and manipulates the stack.
Moves in a PDA
A move in a Pushdown Automaton occurs based on the following factors:
- Reading the input string: The automaton reads the current input character and shifts the input head to the next character. In some cases, the automaton can also make spontaneous moves, where it transitions between states without shifting the input head.
- Interacting with the stack: Depending on the stack’s state, the automaton reads and removes the top symbol. If the stack is empty, it reads the bottom symbol
, but does not remove it. - State transitions: Based on the current input character, the current state, and the symbol on the top of the stack, the automaton transitions to a new state. During this transition, it may perform a stack operation, pushing one or more symbols onto the stack, or leaving the stack unchanged.
Definition
Formally, a pushdown automaton
is defined by a tuple:
: A finite set of states representing the different modes or conditions of the control unit. : A finite input alphabet from which the input string’s characters are drawn. : A finite stack alphabet containing the symbols that can be stored in the stack. : A transition function that dictates how the automaton moves from one state to another based on the current input, the stack’s top symbol, and possibly a spontaneous move. : The initial state, which is the starting point of the automaton’s operation. : The initial stack symbol, placed at the bottom of the stack, ensuring that the stack is never entirely empty. : A finite set of final states. If the automaton reaches one of these states, the input string is considered accepted. The transition function
of a pushdown automaton is a mapping that defines how the machine changes its configuration based on its current state, the current input character, and the symbol at the top of the stack. This function operates within the domain: where,
represents a spontaneous move where no input character is consumed. The image of the function is the set of all possible moves, which includes the next state and the updated contents of the stack:
Reading Move
When the automaton is in a state
Steps
- Pop: Removes
from the stack. - Push: Places a string
(possibly empty) onto the top of the stack.
The transition for a reading move is represented as:
Spontaneous Move
In a spontaneous move (or
Non-Determinism in PDA
Pushdown automata are often nondeterministic, meaning that for a given configuration (state, input character, stack top), there may be multiple possible transitions. This non-determinism allows the automaton to explore multiple computational paths simultaneously.
In essence, the automaton does not deterministically decide which transition to take; instead, it explores all valid transitions in parallel.
Instantaneous Configuration and Transitions
Definition
An instantaneous configuration of a pushdown automaton is a snapshot of its current state at any moment in the computation. It is represented as a triple:
where:
is the current state of the automaton. is the part of the input string that remains to be read. is the current contents of the stack.
The initial configuration of a PDA is
A transition between configurations is written as:
This means that, starting from the configuration
| Current configuration | Next configuration | Applied move |
|---|---|---|
| reading move | ||
| spontaneous move |
Accepting an Input String
An input string
where
Palindromes of Even Length
Consider the language
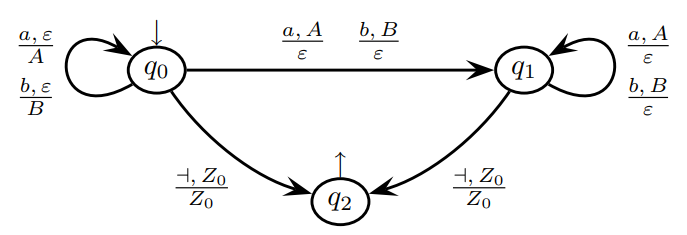
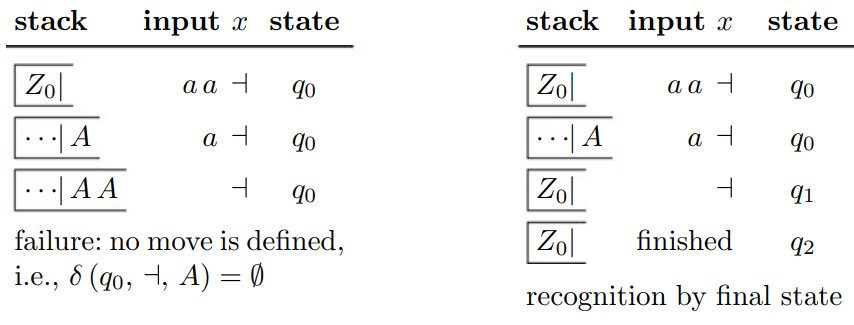
, where strings are palindromes of even length. A non-deterministic pushdown automaton can be used to recognize such strings by ensuring that the automaton pushes the first half of the string onto the stack, then pops the stack as it compares the second half to the first in reverse order.
The input string
is accepted because it leads the automaton to a final state. Similarly, the empty string is accepted through a transition from the initial state directly to the final state .
- Input:
- Step 1: Push the first
onto the stack. - Step 2: Read the second
and pop the stack, comparing it with the first . - Result: The automaton reaches a final state, meaning the input is accepted.
- Empty String: The automaton transitions from
to , immediately accepting the empty string.
From Grammar to Pushdown Automaton
A context-free grammar can be converted into a pushdown automaton, where grammar rules function as instructions. This transformation is intuitive because the automaton uses its stack to simulate the derivation process specified by the grammar rules.
- Initial Configuration: The automaton starts with the axiom
(the start symbol) and the initial stack symbol on its stack. The input head is positioned at the beginning of the input string. - Grammar Rules as Automaton Moves: Each grammar rule can be interpreted as an instruction for the pushdown automaton. The automaton non-deterministically chooses one of the applicable rules at each step, pushing and popping stack symbols based on the rules and input characters.
- Stack Symbols: The stack symbols are either terminal or non-terminal symbols from the grammar. At each step, the automaton executes the rule associated with the stack’s top symbol. If the stack contains
, the automaton first processes by attempting to derive a substring from it, shifting the input head accordingly. - Recursive Sub-actions: If the automaton needs to recognize a non-terminal
, it may require recognizing other symbols first. For instance, if derives from other non-terminals, the automaton must first recognize these subcomponents before completing the recognition of .
Automaton Moves Based on Grammar Rules
For a given grammar
| Grammar rule | Automaton move | Comment |
|---|---|---|
| if | To recognize | |
| if shift reading head | Character | |
| if | The empty string deriving from | |
| for any character | if shift reading head | Character |
| acceptance condition | if halt | The input string has been entirely scanned, and the agenda has no goals |
Example
The predictive language recognizer for the language
is a pushdown automaton designed to analyze strings of the form , where and are integers such that . This automaton simulates the leftmost derivations of a grammar that generates this language, utilizing a set of moves and grammar rules to interpret each character in the string based on the current state and stack content. This process inherently involves non-determinism, meaning that the automaton may explore multiple computational paths simultaneously, choosing different derivations based on the input it encounters. The main goal of the automaton is to determine where the pattern
transitions from the sequence of -symbols to the sequence of -symbols. To do this, it needs to correctly handle two primary cases: when an input symbol needs to be shifted or when it should initiate a shift to a suffix starting with . The automaton’s moves can be summarized as follows:
# grammar rule automaton move 1 if and then pop;
push; shift 2 if then pop;
push3 if and then pop;
push;
shift4 if and then pop;
push;
shift5 if and then pop;
shift6 if and the stack is empty the accept;
haltOne of the key characteristics of this automaton is its non-deterministic nature. Non-determinism appears in the choices between moves, specifically between moves 1 and 2, and moves 3 and 4. For instance, while encountering an
-symbol with on top of the stack, the automaton may either choose to push again (rule 1) or switch directly to (rule 2). Similarly, within , it can opt to either expand into (move 3) or directly transition to (move 4). This non-deterministic selection allows the automaton to “guess” the boundary between the prefix and the suffix , then later decide where the sequence of -symbols concludes, and the matching sequence of -symbols begins. To analyze a string
, the automaton effectively divides the string into segments , deciding the point where the suffix commences. This is achieved by probabilistically selecting moves until the complete sequence is recognized. If the automaton reaches the end of the input with an empty stack and finds no mismatches, the string is considered successfully recognized.

Grammar-Automaton Equivalence and Ambiguity
A fundamental property of this automaton is its equivalence to the grammar that generates the language
For every successful recognition path taken by the automaton, a corresponding grammar derivation exists, and vice versa.
This establishes that the automaton accurately simulates leftmost derivations from the grammar.
However, due to its non-deterministic choices, the automaton can sometimes recognize the same string through multiple computational paths, a property that corresponds to ambiguity in the grammar itself.
If the grammar is ambiguous, the automaton will accept a string through two or more distinct computational sequences.
Interestingly, it is possible to reverse the construction process, meaning that one can derive the grammar rules starting from a pushdown automaton, provided that the automaton is a one-state pushdown automaton. This observation is crucial as it implies that the family of languages recognized by one-state pushdown automata is equivalent to the family of languages generated by context-free grammars. However, this equivalence does not generally extend to multi-state pushdown automata; for multi-state automata, more complex concepts and proof techniques are required to establish the language recognition capabilities.
Computational Complexity and Efficiency
The non-deterministic nature of the pushdown automaton introduces significant computational complexity. In the worst case, the automaton must explore all possible moves at each step, leading to an exponential time complexity with respect to the input string length. This exponential complexity arises because each decision point adds potential branches to the computation, requiring the automaton to test multiple hypotheses about where transitions between sequences occur. More efficient algorithms exist to recognize languages like
Varieties of Pushdown Automata
The pushdown automaton (PDA) discussed earlier differs from the one directly derived from the grammar in two notable ways: it may have multiple states, and it uses a distinct acceptance condition. Specifically, instead of relying on an empty stack to signal acceptance, this automaton accepts by entering a designated final state. Both multi-state configurations and acceptance methods significantly affect how PDAs recognize languages and the kinds of languages they can accept.
Pushdown automata have several modes of acceptance that determine how they conclude that a given string belongs to the language. These modes influence the operational mechanics of the automaton and can affect its efficiency. The primary modes of acceptance include:
- Acceptance by Final State: In this mode, the PDA accepts a string when it reaches a predefined final state, regardless of the contents of the stack. The state itself acts as the signal of acceptance.
- Acceptance by Empty Stack: Here, the automaton accepts a string when the stack is completely emptied during the process. This mode is independent of which state the PDA is in at the time the stack becomes empty.
- Combined Acceptance (Final State and Empty Stack): A combination of both methods where the PDA must reach a final state and also empty its stack to accept the input.
For non-deterministic pushdown automata with multiple states, these three acceptance modes are equivalent.
This equivalence means that any language recognized by a PDA in one of these modes can also be recognized by a PDA using the other modes. Consequently, the family of languages recognized by PDAs remains the same, irrespective of the specific acceptance condition employed.
Operation Without Spontaneous Loops and On-Line Processing
In a more generic configuration, a pushdown automaton may execute moves without consuming any input character. These moves are termed spontaneous moves or epsilon transitions. A PDA can theoretically enter an infinite sequence of spontaneous moves, forming a loop where it never progresses by reading the next input character. Such behavior is undesirable for two primary reasons:
- It may prevent the PDA from completely reading the input string, leading to indeterminate outcomes.
- It could cause the PDA to execute an infinite series of moves before making a decision, either accepting or rejecting the string.
To prevent these issues, an equivalent PDA can always be constructed that eliminates spontaneous loops. By doing so, the automaton will avoid any situations where it could enter an infinite loop without reading input, thereby ensuring it evaluates input strings in a more controlled and practical manner.
Another practical approach for pushdown automata is to operate in on-line mode. In on-line mode, the automaton makes a decision about accepting or rejecting a string as soon as it reads the last character of the input. After this point, the automaton does not execute any further moves. This behavior is advantageous in real-world applications, where it is inefficient for an automaton to continue processing after the input has been fully consumed. Like the elimination of spontaneous loops, it is possible to construct an equivalent PDA that operates in on-line mode, ensuring it halts immediately upon reading the final input character.
Free Languages and Pushdown Automata
A language accepted by any pushdown automaton (PDA) is known as a free language, indicating that it belongs to the family of context-free languages (CF).
Every context-free language, regardless of complexity, can be recognized by a non-deterministic PDA with only one state.
This property establishes an important theoretical equivalence between context-free languages and the capabilities of one-state non-deterministic pushdown automata.
-
Equivalence with One-State PDAs: The family of context-free languages (CF) includes exactly those languages that can be recognized by one-state non-deterministic pushdown automata. This means that the complexity of language structure does not demand more than a single state in the automaton, though non-determinism may still be necessary.
-
Equivalence with Unrestricted PDAs: Any unrestricted PDA, whether multi-state or non-deterministic, can also recognize all context-free languages. Thus, PDAs, by their design, align with the family of free languages, making them essential tools for recognizing context-free grammars in various applications.
Deterministic Pushdown Automata and Deterministic Languages (DET)
Deterministic pushdown automata (DPDAs) play a critical role in contexts where efficiency and predictability are essential, such as in compiler design.
Definition
A PDA becomes deterministic if its transition function
is one-valued, meaning there is only one possible transition for each input configuration. Specifically:
- if
is defined, then is undefined, - if
is defined, then is undefined for every .
In this configuration, if a transition depends on reading an input symbol, it cannot also rely on spontaneous moves (i.e., transitions without reading an input symbol,
It is important to note, however, that a DPDA can still include spontaneous moves, as long as these moves do not conflict with transitions based on input symbols.
This constrained use of spontaneous moves supports efficient, clear language recognition.
Deterministic context-free languages, the subset of context-free languages that DPDAs recognize, form a strictly contained family within the broader CF family.
Example: Non-Deterministic Union of Deterministic Languages
Consider the union of two languages:
: the language where each is matched by a corresponding . : the language where each is matched by two ‘s. The union of these two languages
is a non-deterministic language, meaning it cannot be recognized by a DPDA. A DPDA would not know whether to pop one symbol for each or two ‘s for each without trying both approaches. However, both and individually are deterministic, as they can each be recognized by a DPDA. This example demonstrates that while and are within , their union is not. From this, we conclude:
Thus, the family
This distinction highlights that while deterministic PDAs are efficient and widely useful, they cannot recognize all context-free languages. Non-deterministic capabilities expand the recognition power of PDAs, allowing them to handle more complex language structures at the cost of efficiency.