Syntax transduction refers to the formal correspondence established between two distinct formal languages, enabling structured translation from one to the other.
This translation process relies on local transformations, where elements of the source text are systematically replaced by corresponding elements in the target text. The mechanism for this replacement is governed by a predefined table that maps characters or substrings from the source alphabet to the destination alphabet. This systematic approach ensures that the resulting translation adheres to the syntactic rules of the target language.
The process of syntax transduction can be classified into two primary models: regular transduction and syntactic (or free) transduction.
In regular transduction, the process is defined using regular expressions or finite transducers. A finite transducer is essentially a finite-state automaton capable of producing output strings in addition to recognizing input strings. This model is well-suited for tasks involving simple, rule-based transformations.
Syntactic transduction employs a more sophisticated framework, utilizing a free grammar to define both the source and destination languages. The central component in this model is an abstract syntactic transducer, which is essentially a pushdown automaton. Pushdown automata, known for their ability to handle nested structures, leverage algorithms similar to those used in parsing techniques, such as Earley’s algorithm (ELR) and LL parsing (ELL). This model provides a robust foundation for translating complex, context-sensitive structures.
Syntax-Directed Semantic Transduction
Syntax-directed semantic transduction extends the principles of syntax transduction by integrating semantic analysis into the translation process. This approach relies on attribute grammars, which enrich the syntactic rules of a language with additional semantic information. Attribute grammars define, rule by rule, the semantic functions to be applied during the transduction process. These functions facilitate the computation of meaning or execution logic in a compositional manner, ensuring that the translation captures both the syntactic and semantic fidelity of the source text.
One of the key strengths of syntax-directed semantic transduction lies in its application to compiler design. By incorporating attributes and semantic functions into finite transducers, this approach enables advanced tasks such as lexical analysis, type checking, and the handling of conditional instructions. Furthermore, it plays a pivotal role in semantic-directed syntax analysis, where semantic considerations guide the syntactic processing of input text. The systematic documentation of these methods underscores their utility in both theoretical and practical contexts.
Analogies in Formal Language and Transduction Theories
Theories of formal languages and transduction share deep analogies, providing a unified framework for understanding the relationships between languages and their transformations. These analogies can be categorized into three perspectives: set-theoretic, generative, and operative.
From a set-theoretic perspective, a language can be viewed as a set of phrases, and the process of transduction corresponds to a relation between two sets—namely, the set of source phrases and the set of destination phrases. This perspective emphasizes the mathematical foundations of language transformations.
The generative perspective reimagines language grammars as transduction grammars. Instead of generating standalone phrases, these grammars produce pairs of phrases—one from the source language and its corresponding translation in the destination language. This approach highlights the dual generative role of grammar in syntax transduction.
Lastly, the operative perspective focuses on the computational mechanisms underlying transduction. Here, automata used for language recognition, such as finite-state automata or pushdown automata, are adapted to perform transduction tasks. These transducer automata not only recognize input structures but also compute their translations, effectively serving as both recognizers and translators.
Transduction Relation and Transduction Function
In formal language theory, a transduction describes the correspondence between two sets of strings derived from different alphabets, (source alphabet) and (destination alphabet). This correspondence is formally represented as a binary relation between the sets of all possible strings over these alphabets, and . Specifically,
Definition
a transduction relation, , is a subset of the Cartesian product . It consists of pairs , where and , such that is related to by the transduction.
Mathematically, the relation is defined as:
The languages and are the projections of onto the first and second components, respectively:
Definition
Alternatively, a transduction can be represented as a total function, which is generally multi-valued. This function maps each string in to a set of strings in , such that:
where, denotes the power set of , reflecting the potential multiplicity of destination strings for a given source string.
The inverse transduction maps strings in to subsets of as:
Depending on the properties of and , transduction functions can be categorized into several cases:
Total transduction: Every string in is mapped to at least one string in . The image may include multiple strings or even the empty string.
Partial transduction: Some strings in may have no corresponding string in , not even the empty string.
One-valued transduction: Each string in is mapped to at most one string in .
Multi-valued transduction: Some strings in are mapped to multiple strings in , potentially an infinite number.
For total and one-valued transductions, additional classifications are possible:
Injective transduction: Distinct strings in map to distinct strings in , ensuring that no two source strings share the same image.
Surjective transduction: Every string in is the image of at least one string in .
Bijective transduction: A one-to-one correspondence exists between and , making the transduction both injective and surjective. Bijective transductions are invertible, and their inverses are also bijective.
Transliteration: A Simple Character-Based Transduction
Transliteration, also known as homomorphism, represents the most basic form of transduction, where a source string is transformed character by character based on a predefined mapping. In this form of transduction, each character in the source alphabet is transduced into a corresponding character or, more generally, into a string in the destination alphabet . It is also possible for a source character to be replaced by the empty string .
This process is inherently one-valued, as each source character has a single corresponding transformation. However, the inverse transduction of transliteration is not necessarily one-valued.
For instance, if a source character is replaced with the empty string during transliteration, multiple interpretations of the destination string become possible, leading to a multi-valued or even infinitely-valued inverse transduction.
The key feature of transliteration is its locality: each character is transformed independently of the others, with no consideration of the surrounding context. While this makes transliteration efficient and straightforward, it also limits its applicability. Transliteration is insufficient for handling complex language transformations or for tasks such as compiling technical languages, which require more sophisticated models.
Regular (Rational) Transduction
To handle more complex transformations, regular (or rational) transduction extends the concept of transliteration by using regular expressions (regexps). In this model, the regular operations—union, concatenation, and Kleene star—are applied not to individual strings but to pairs of strings (source and destination). This enables the definition of transformations where context and structure are taken into account.
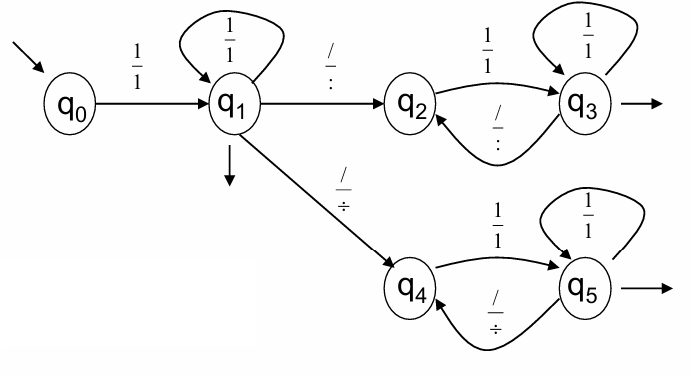
Example: Transliteration of an Operator
Consider a source alphabet and a destination alphabet . The task is to transduce a list of unary integers separated by the operator /. The transformation replaces / with either : or \div, but does not mix these alternatives.
For example:
The transformation can be expressed as:
Here, the regular transduction expression ensures that either all / are replaced by : or all by \div, maintaining consistency.
Definition
A regular transduction expression (regexprt) is a regular expression extended to pairs of strings , where (source string) and (destination string). Such expressions use the operations of union (), concatenation, and star ().
Example
where and . The language generated by includes pairs such as:
Each pair in represents a source string and its corresponding destination string , which can be obtained by projecting a string onto its first and second components, where is the set of pairs defined by .
Properties of Regular Transduction
Regular Source and Destination Languages:
The set of source strings defined by a regular transduction expression forms a regular language.
Similarly, the set of destination strings is also regular.
Limitations:
While both the source and destination languages of a regular transduction are regular, the relation between them (i.e., the mapping) is not guaranteed to be expressible by a regular transduction. This limitation arises from the inherent constraints of regular expressions in representing certain types of complex relations.
Two-Tape Recognizer Automaton
The two-tape recognizer automaton extends the functionality of a traditional finite automaton by operating on two input tapes simultaneously. This model is particularly useful for recognizing transduction relations defined by regular transduction expressions (regexprts). Each tape processes a string: the source string on the first tape and the destination string on the second tape.
A pair is accepted by the two-tape automaton if and only if it belongs to the transduction relation.
For example, the automaton can confirm that the pair is valid while rejecting .
This approach is not only a rigorous method for defining transductions but also provides a framework for constructing both lexical analyzers and syntax analyzers in a unified manner. By thinking of the set of string pairs defined by a regexprt as terminal symbols, a two-tape automaton becomes a natural choice for recognizing and processing these pairs.
Definition
A two-tape automaton has the following components, analogous to a single-tape automaton:
State Set (): A finite set of states.
Initial State (): The starting state.
Final States (): A subset of states where the automaton halts and accepts.
Transition Function (): A function that governs the transitions between states based on the characters read from both tapes:
If , the automaton, when in state , reads character from the first tape and string from the second tape, then transitions to state .
To simplify the behavior of the automaton, each transition is designed to read only one character at a time from one tape while leaving the other tape unchanged. Transitions are represented as:
: Read character from the source tape; no character is read from the destination tape.
: Read character from the destination tape; no character is read from the source tape.
Compound transitions, such as , are decomposed into sequences of simpler transitions:
A key result is that
the family of regular transductions defined by regexprts coincides with those recognized by two-tape automata (even if they are non-deterministic).
This equivalence ensures that any regular transduction can be represented and processed using a two-tape automaton. Given a regexprt, the associated two-tape automaton operates on an alphabet that is the Cartesian product of the source and destination alphabets:
This means that each transition explicitly defines the mapping between source and destination strings.
An alternative approach to defining a two-tape automaton is through a right-linear grammar. This method leverages the correspondence between finite state automata and regular grammars to construct transduction grammars. Such grammars define the transduction relation by specifying rules for transitioning between states while processing input from both tapes.
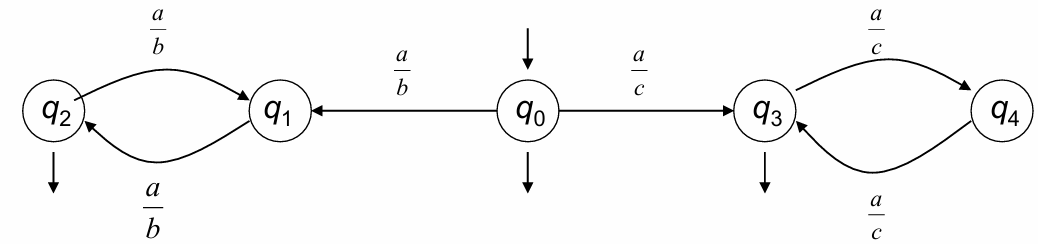
Example: Grammar for a Two-Tape Automaton
Consider a grammar with the following rules:
Here:
is the starting state.
The transitions define how characters are read from the source and destination tapes.
represents a halting condition.
This grammar provides a structured way to design two-tape automata and is particularly useful in syntax transductions, where free grammars play a central role in defining complex language relationships.
Transduction Function and Transducer Automaton
A transducer automaton (or input-output automaton, IO automaton) is an extension of the two-tape automaton designed to compute transduction functions. This automaton reads a string from the input tape and simultaneously writes a corresponding string to the output tape, making it a functional computational model for string transformations.
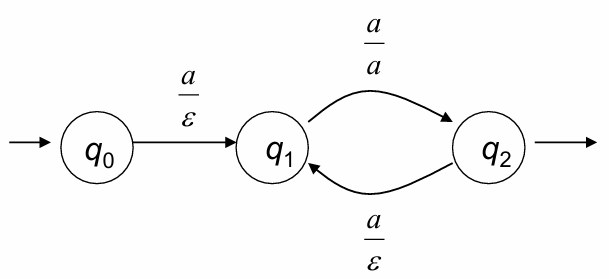
Example: A Non-Deterministic Transduction
Consider the transduction relation:
This corresponds to the transduction function:
This function can be represented by the regexprt:
In this case:
The two-tape automaton can compute deterministically.
However, a deterministic IO automaton cannot compute because admits two possible computations, only one of which is valid:
(valid).
(invalid).
Sequential Finite State Transducer (Deterministic Model)
A finite state sequential deterministic transducer (or deterministic IO automaton) computes a transduction function by sequentially reading the source string on the input tape and writing the destination string on the output tape.
The transducer consists of several fundamental components. It has a finite set of states and operates over an input alphabet and an output alphabet . The computation always starts from a designated initial state , and can terminate in any state belonging to the subset of final states.
Three key functions govern the transducer’s behavior.
The transition function determines the next state based on the current state and input character.
The output function specifies what string should be written to the output tape during each transition.
Finally, the final function computes the final suffix that must be appended to the output string when the transducer reaches a final state.
The transduction function produces its output through a systematic process involving multiple components. Each computation generates a sequence that combines intermediate outputs with a final suffix.
During execution, the transducer generates output in two distinct phases.
First, it accumulates the output strings produced by the output function as it processes each transition.
Then, upon reaching a final state, it appends a suffix determined by the final function .
This process can be expressed formally as:
In the formal representation of transitions, each step is denoted by:
This notation encapsulates four key elements:
The current state ()
The destination state ()
The input symbol read from the source tape ()
The string written to the output tape ()
Distinguishing Deterministic and Non-Deterministic Transducers
In the study of transducer automata, understanding the distinction between deterministic and non-deterministic transducers is crucial for comprehending their computational capabilities and practical applications.
A deterministic transducer exhibits two essential characteristics. First, its underlying input automaton, formally represented as , must operate deterministically, meaning that for each input symbol and state, there is exactly one possible next state. Second, both the output function () and the final function () must be one-valued, ensuring that each input-state combination produces a single, unambiguous output.
A non-deterministic transducer may demonstrate ambiguous behavior even when its underlying input automaton is deterministic. This non-determinism manifests when transitions can generate multiple possible outputs for a single input, represented formally as:
Such transitions indicate that the transducer may choose between different output symbols (in this case, or ) when processing the same input symbol , introducing non-deterministic behavior into the transformation process.
Sequential Function
Definition
A function is sequential if it can be computed by a deterministic sequential finite state transducer.
These functions are efficient to compute since the output is generated as the input string is scanned, without requiring backtracking or global computations.
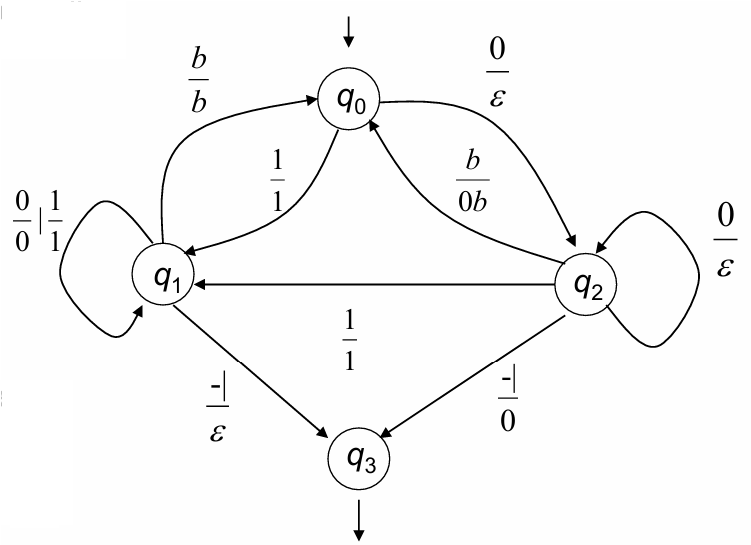
Example: Elimination of Leading Zeros
Consider a binary string transduction that removes leading zeroes from binary integers separated by blanks ():
Input:
States traversed:
Output written:
The transducer:
Skips leading zeroes using .
Retains meaningful digits (like ) and appends separators ().
Properly handles the string termination ().
Example: Parity-Based Character Output
Consider a transduction function that outputs a single character based on the parity of input length:
This transducer demonstrates efficient use of the final function in the sequential transducer model:
The transducer has exactly two states :
: represents even count
: represents odd count
Both states are marked as final
Operating principle:
Transitions between states occur without writing output
When input is exhausted, the final function φ determines output:
This design efficiently tracks parity through state transitions while deferring output until the entire input is processed.
Some transductions, such as converting into if is even, or if is odd, cannot be computed directly by a deterministic IO automaton. However, they can be computed in two passes:
The first transducer scans the input string from left to right and generates an intermediate representation.
The second transducer scans the intermediate string from right to left and computes the final output.
This two-pass approach allows deterministic computation for certain transductions that would otherwise require non-determinism.
Regular vs. Non-Regular Transductions
In the theory of formal languages, transductions can be classified into two fundamental categories based on their memory requirements and computational complexity.
Regular transductions represent the simpler class, as they can be computed through deterministic algorithms utilizing only finite memory resources. These algorithms typically process the input in one or two passes, making them efficient and practical for many applications.
In contrast, non-regular transductions pose more significant computational challenges, as they necessitate storing the complete input string before generating any output. This requirement exceeds the constraints of finite memory systems, making them more complex to implement and process.
The distinction between these two classes is crucial for understanding the practical limitations and theoretical boundaries of formal language processing.
Example: Mirroring a String
Consider the transduction:
This transduction is not regular because:
The entire source string must be stored in memory to produce its reverse .
Deterministic sequential automata with finite memory cannot perform this computation.
By Nivat’s theorem, such transductions can be represented by:
Constructing a relation that combines and (the reverse of transliterated over a distinct alphabet).
Using as the basis for the transduction.
However, the constructed is no longer regular, indicating that this problem exceeds the capacity of finite-state transducers.
Context-Free (Algebraic) Transduction
When the source language is defined by a grammar, a natural approach is to create transductions where syntactic structures are translated individually. This approach ensures that the translation preserves the structural integrity of the source language, aligning it with the rules of the destination language.
Definition
A transduction grammar is a context-free grammar over the terminal alphabet , where each terminal in is a pair of strings over the source () and destination () alphabets.
Where:
: Non-terminal symbols.
: Source alphabet.
: Destination alphabet.
: Set of production rules.
: Start symbol.
: Terminal pairs , where is a source string and is a destination string.
The transduction relation is defined as:
where:
: Language generated by .
: Projection function mapping to its source string over .
: Projection function mapping to its destination string over .
The transduction grammar and the syntactic transduction scheme are equivalent representations, defining the same transduction relation.
Example: Mirroring with Context-Free Transduction
The goal is to compute the mirroring of a source string over into a destination string over , reversing the order of characters.
This grammar generates pairs of strings where the source string is in normal order and the destination string is the reverse.
The transduction scheme consists of:
Source grammar:
Destination grammar:
Step-by-Step Example
Derive a string using the transduction grammar:
Resulting string:
Project over the source and destination alphabets:
: Project source symbols ():
: Project destination symbols ():
The pair belongs to the transduction relation , where the source string is mirrored to produce the destination string .
Transduction of Palindromes
The transduction grammar for palindromes modifies terminal characters in the left and right halves of a string symmetrically.
The grammar for generating palindromes, denoted , defines a symmetric structure in which terminal symbols are paired across the left and right halves of the string. The rules of are as follows:
Rule specifies that the character in the left half must be paired with in the right half.
Rule indicates a similar pairing for and .
Rule serves as the base case, generating the empty string, which is trivially a palindrome.
This grammar enables the construction of palindromes by recursively adding characters to both ends of the string.
To transform palindromes into a specific output format, a transduction grammar maps source characters to corresponding destination symbols. The mapping rules are defined as:
Character Mapping
Source Alphabet
Destination Alphabet
The Nivat theorem for algebraic transductions allows us to express transductions as a combination of:
A free language over a combined alphabet.
Two alphabetic homomorphisms and that extract the source and destination strings from .
Property
The following are equivalent:
A transduction relation is defined by a transduction grammar.
There exists a free language over a combined alphabet and two homomorphisms and :
If and are disjoint, there exists a language over :
Example: Transducing Strings into Mirror Images
To illustrate, consider the task of transducing a string into its mirror image . This transformation can be expressed using the palindrome language:
For instance:
The string represents a palindrome where and .
The homomorphisms for this transduction are defined as:
Symbol
(Source Projection)
(Destination Projection)
Given the string , the homomorphisms produce the following projections:
Source Projection (): Extracts , representing the left half.
Destination Projection (): Extracts , representing the mirrored right half.
Thus, the transduction maps to the string pair , achieving the desired mirroring effect.
Infix (Polish) Notation and Syntax Transduction
The concept of infix or Polish notation plays a central role in syntax transduction, where expressions—arithmetic, logical, or otherwise—are transformed into alternative notations. These notations differ primarily in the placement of operators relative to their operands and the optional use of delimiters, such as parentheses. Polish notation, also known as prefix or postfix notation, eliminates parentheses altogether by enforcing a consistent order for operators.
Operators can vary based on the number of arguments they take, termed their degree. For instance:
Unary operators have a degree of one (e.g., negation).
Binary operators have a degree of two (e.g., addition or multiplication).
Variadic operators can accept a variable number of arguments.
Based on their position, operators are classified as:
Prefix operators: Placed before their operands (e.g., + A B).
Postfix operators: Placed after their operands (e.g., A B +).
Infix operators: Placed between their operands (e.g., A + B).
Mixfix operators: Combine various placements in complex expressions.
Definition
Polish notation, whether prefix or postfix, eliminates the need for parentheses by enforcing a strict ordering of operators and operands. For example:
Infix Notation: requires parentheses or operator precedence rules to ensure clarity.
Prefix Notation: eliminates ambiguity by positioning operators before their operands.
This consistency makes Polish notation especially useful in compiler design, where expressions need to be evaluated efficiently without parsing complex hierarchies of parentheses.
Conversion Between Notations Using Transduction Grammars
The process of converting expressions from one notation to another involves transduction grammars, which map source syntax to a corresponding destination syntax. Consider converting an arithmetic expression from infix to prefix notation:
Here:
represents an expression.
represents a term.
represents a factor.
In the source grammar (), the structure of expressions reflects standard infix notation with parentheses and operator precedence. The corresponding destination grammar () maps these elements to prefix operators (add, mult) while maintaining their semantic meaning.
For example:
Source Rule:
Destination Rule:
This transformation eliminates parentheses by explicitly encoding the hierarchical structure of operations in the sequence of prefix operators.
Ambiguity in Grammars
A grammar is ambiguous if it admits multiple distinct syntax trees for the same string, leading to multiple interpretations. Ambiguity in the source grammar () results in multiple syntax trees and corresponding transduction paths in the destination grammar ().
Ambiguity can also manifest in the form of circular derivations. For example, consider the following ambiguous destination grammar ():
is ambiguous as it admits the circular derivation , so we can have two different transductions:
The presence of such derivations demonstrates the ambiguity of , as the same input may yield distinct outputs, undermining the deterministic nature of the transduction.
Even if the source grammar is unambiguous, the transduction itself may be multi-valued if a single input string maps to multiple outputs.
Example
Here, the transduction grammar maps the string to multiple outputs:
This behavior arises because each instance of the source symbol can independently map to different destination symbols.
Properties of One-Valued Transductions
A transduction grammar is one-valued if:
The underlying source grammar () is unambiguous.
Each rule of corresponds uniquely to a rule of .
These conditions ensure a deterministic mapping from source strings to destination strings. However, if itself is ambiguous, the underlying source grammar () must also be ambiguous. Conversely, the ambiguity of does not necessarily imply the ambiguity of .
Unambiguous Transduction Grammar with Ambiguous Source Grammar
An example of an unambiguous transduction grammar derived from an ambiguous source grammar is given by the following rules:
In this grammar:
The source grammar allows multiple interpretations due to ambiguity in the placement and scope of the else clause.
The transduction grammar introduces unique output symbols (e.g., endif) to resolve ambiguities, ensuring each derivation is uniquely transduced.
This demonstrates that even when the source grammar is ambiguous, the transduction grammar can still yield an unambiguous mapping by carefully structuring the output rules.
In compiler design, multi-valued transduction grammars are avoided because they allow multiple output forms for the same input string, leading to inconsistent and unpredictable behavior. For reliable compilation, transduction grammars should define a one-to-one mapping between input and output strings, ensuring deterministic processing.
Pushdown Transducer Automaton
To compute a transduction defined by a transduction grammar, an unbounded pushdown stack memory is required. The computational model for such transductions is the pushdown transducer automaton, also known as a pushdown input-output (IO) automaton. This automaton extends the functionality of a standard pushdown automaton by incorporating a one-way write head and an output tape.
Definition
A pushdown transducer is formally defined by the following components:
: Set of states.
: Source (input) alphabet.
: Stack (memory) alphabet.
: Destination (output) alphabet.
: Transition and output function.
: Initial state.
: Initial stack symbol.
: Set of final states.
The domain of the transition function is:
The image of is:
This means that: if , the transducer, when in state , reads from the input tape and pops from the stack. It then transitions to state , pushes onto the stack, and writes onto the output tape.
The computation terminates when the transducer either reaches a final state or empties the stack, depending on the specific end condition.
Transduction grammars and pushdown transducer automata are equivalent in terms of expressive power. The grammar represents the generative aspect of the transduction, while the automaton captures its procedural implementation. It is always possible to convert a transduction grammar into an equivalent automaton and vice versa.
Property
A transduction relation is defined by a transduction grammar if and only if it can be computed by a pushdown transducer automaton.
This property ensures that both representations are interchangeable depending on the context of use, such as analysis or implementation.
To derive a predictive pushdown transducer from a transduction grammar, the correspondence between grammar rules and automaton transitions must be formalized.
Construction of the predictive pushdown transducer starting from the transduction grammar
For instance:
: Specifies an output without consuming input.
: Specifies an output while consuming input .
This construction often results in a non-deterministic automaton. In some cases, additional states can be introduced to convert the automaton into a deterministic form, but this is not always feasible.
Inherently Non-Deterministic Transductions
Some transductions are inherently non-deterministic and cannot be computed by any deterministic pushdown transducer automaton. A classic example is:
Here:
The transducer would need to push onto the stack and, after reading the terminator symbol, pop to output its reverse ().
However, this process loses the direct representation of , making it impossible to output in its original order as required.
Such non-deterministic transductions are impractical for real-world applications, where deterministic behavior is essential.
In practical compiler design and formal language processing, deterministic transductions are preferred for efficiency and reliability. Algorithms for analyzing and simplifying transductions focus on identifying cases where determinism can be enforced and ensuring that ambiguous or multi-valued scenarios are avoided. This ensures that compilers and language processors produce consistent and predictable outputs, meeting the demands of high-performance computational systems.
Syntax Analysis and On-Line Transduction
In on-line transduction, the syntax analysis and the transduction are performed simultaneously, allowing for efficient computation without constructing intermediate representations like complete syntax trees.
A syntactic analyzer can be extended to act as a transducer by augmenting it with write actions that produce the desired transduction as the parsing process proceeds. The nature of the transformation depends on the type of parser:
Top-Down Analyzers (LL):
These parsers can always be directly transformed into transducers by integrating write actions into recursive procedures.
As the parser explores each production rule in a top-down manner, it writes the corresponding transduction components in a well-defined order.
Bottom-Up Analyzers (LR):
For LR parsers, the transformation requires the grammar to satisfy a restrictive condition: the output action can only occur at the end of a production when the parser performs a reduction.
This ensures that the transduction aligns with the bottom-up parsing process.
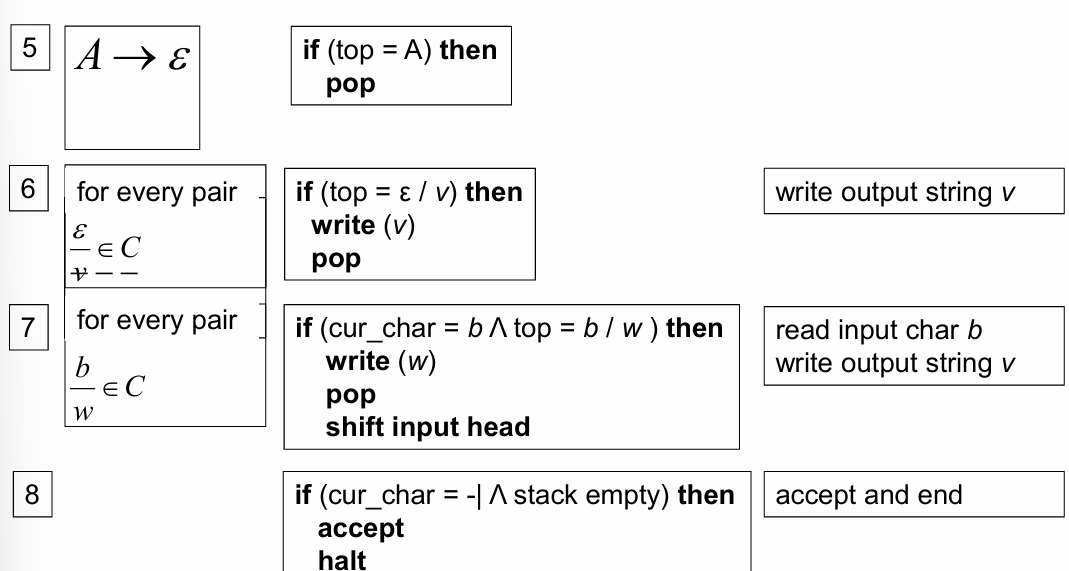
Top-Down Deterministic Transduction
If the source grammar is deterministic and falls within the LL(k) class, it can be extended into a transducer with relative ease. By adding write actions to an LL parser, the corresponding transduction can be computed as the parser executes. For instance:
Recursive parsing functions can include calls to output the transduced symbols.
Lookahead sets and deterministic parsing ensure that each transduction step is uniquely determined.
This approach is particularly useful when the grammar is simple and the transduction requires little reordering of symbols.
Example 1: String to Mirror Image
A source grammar that translates a string into its mirror image is an LL(1) grammar. The transduction rules are defined as:
Here:
Each time the parser encounters an a or b, it delays writing until the recursive call completes.
This ensures that the mirrored characters are written in the correct reverse order.
stack
pop; push ()
pop; push()
pop
write()
write()
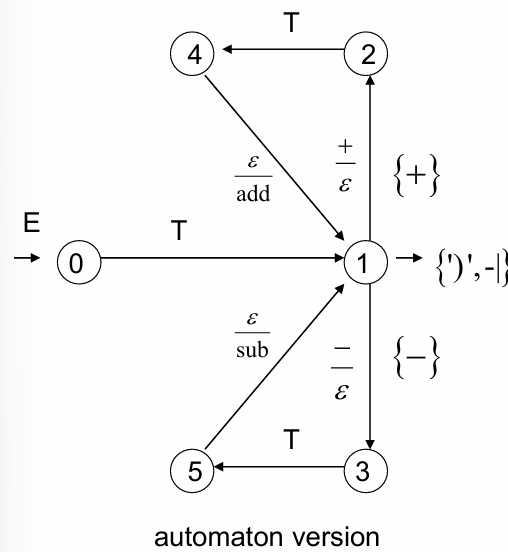
Example 2: Infix to Postfix Transduction
Infix expressions (e.g., arithmetic expressions with parentheses) are converted into postfix (or Reverse Polish Notation, RPN) using a grammar-based transduction. This is a common example in compilers, where postfix notation simplifies evaluation by eliminating the need for parentheses.
The grammar for infix expressions is extended with output actions to produce the postfix form:
Explanation of Rules
Production for :
produces terms and can be followed by operators or , which are replaced with corresponding postfix symbols (add or sub) after processing the second term.
Production for :
produces factors and supports multiplication or division operators, replaced with postfix symbols (mult or div).
Production for :
directly transduces variables (v) or handles parentheses by recursively processing expressions within them.
Recursive Implementation
The corresponding recursive procedure for top-down parsing and transduction might look like this (in pseudocode):
procedure E(): T() while next_token is '+' or '-': operator = next_token consume(operator) T() if operator == '+': write('add') else: write('sub')procedure T(): F() while next_token is '*' or '/': operator = next_token consume(operator) F() if operator == '*': write('mult') else: write('div')procedure F(): if next_token is 'v': write('v') consume('v') else if next_token is '(': consume('(') E() consume(')')