Automata serve as a robust model for recognizing, accepting, translating, and computing languages. These computational structures operate by processing input strings in various manners, transforming them based on defined rules and mechanisms. When we delve into generative models, we encounter grammars that play a crucial role in producing or generating strings of a language. The concept of grammar or syntax is foundational in linguistics and computer science, encompassing the alphabet and vocabulary of a language. At its core, grammar consists of a set of rules that dictate how phrases (or strings) of a language are constructed. This definition applies broadly, extending to any form of language in the widest sense.
A formal grammar generates strings of a language through a systematic process of rewriting, akin to conventional linguistic mechanisms. This process typically starts with a “main object,” which can represent various constructs such as a book, a program, a message, or a protocol. Each main object is broken down into its composing elements, referred to as components such as subject, header, and declarative part. These components are subsequently refined by replacing them with more detailed objects, continuing the process until we arrive at a sequence of base elements, which could be bits, characters, or other foundational units. Notably, the rewriting operations can vary in their alternatives; for instance, a subject could be represented as a noun, a pronoun, or another form, while a statement may take the shape of an assignment or an input/output operation.
Definition
A grammar can be represented as
In this notation:
refers to the nonterminal alphabet or vocabulary, which encompasses symbols that can be expanded into other symbols. signifies the terminal alphabet or vocabulary, which includes symbols that represent the basic units of the language and cannot be further expanded. - The combined set
is defined as , which represents the complete alphabet of the grammar. identifies a specific element within the nonterminal vocabulary, referred to as the axiom or initial (start) symbol, from which the generation of strings commences. is the set of rewriting rules, also known as productions, expressed mathematically as In simpler terms, this notation defines a relationship where a sequence of nonterminal symbols can be rewritten as a sequence composed of terminal and/or nonterminal symbols: .
Example
Consider a nonterminal vocabulary
and the terminal vocabulary . In this case, the starting symbol is part of the nonterminal vocabulary. The set of production rules is defined as
Here, the rule
indicates that the nonterminal can be replaced by the sequence , while the other rules further illustrate how different nonterminals can be rewritten or transformed into terminal strings or other nonterminals.
Relation of Immediate Derivation ⇒
The relation of Immediate Derivation denoted by
Definition
Given two strings
and , we say that immediately derives (i.e., ) if and only if there exist substrings , , and such that: where
is a production rule in the set of productions of the grammar. In other words, is rewritten as in the specific context of (the portion of the string before ) and (the portion after ).
Example
Let’s consider the rule
from the previously defined grammar
Applying this production rule to the string
. The transformation is as follows: Here, the substring
is rewritten as , leaving the surrounding context and unchanged.
The reflexive and transitive closure of
- Reflexivity:
(a string can derive itself in zero steps). - Transitivity: If
and , then (a string can derive another through multiple rewriting steps).
In essence,
Language Generated by a Grammar
Definition
The language generated by a grammar, denoted as
, is defined as:
This expression represents the set of all strings
The derivation process is not guaranteed to always produce terminal strings. Some derivations may get “stuck,” meaning that the process halts at a point where no further rules can be applied, yet the string is not composed entirely of terminal symbols. Moreover, some derivations may be “never-ending,” where the rewriting continues indefinitely without ever reaching a terminal string.
Example 1
Consider the grammar
where the set of production rules is given by: Let’s look at some derivations in this grammar:
In this case, the start symbolis directly rewritten as the terminal symbol , yielding a valid terminal string.
Here,is first rewritten as . Then, is replaced with , and finally, is rewritten as , producing the terminal string .
Following a similar pattern,is rewritten as , then as , and is eventually replaced with , resulting in the string .
In this case, multiple applications of the production rules lead to the derivation of the terminal string. By analyzing the derivation patterns, we observe that the strings generated by the grammar
are composed of pairs of either ’s or ’s followed by the terminal symbol . This leads to the following general form of the language:
Example 2
Consider the grammar
In this grammar, the nonterminal symbol is
, and the terminal symbols are and . The set of production rules includes two possibilities: , where is rewritten as , and , where is replaced by the terminal string . Starting with the initial symbol , we can derive various strings by applying these rules. Let’s examine some derivations:
Here, the second rule is applied directly, producing the string , which consists of terminal symbols. First, we apply , introducing another occurrence of within the string. Next, the rule is applied, resulting in the string . In this case, the rule is applied twice, adding two more instances of , followed by to produce the final string . A generalization of these derivations leads to the observation that the language generated by
consists of strings with an equal number of ’s followed by an equal number of ’s. Thus, we can express the language as:
If we modify the production rule
and replace it with (where denotes the empty string), we obtain a new language: This version of the language allows for the empty string (i.e.,
) as a valid string in the language.
Example 3
Now consider the more complex grammar
, defined as follows: Let’s analyze some of the possible derivations:
In this sequence, is eliminated using the rule , and the string is transformed into using the rule . Eventually, all nonterminal symbols are rewritten, producing the terminal string .
In this case, the derivation gets “stuck,” as it fails to produce a valid terminal string.
This longer derivation eventually leads to the terminal string , after numerous rewritings of nonterminal symbols. In this grammar, the production rules involving
and generate the sequence . The nonterminal symbol disappears only when it encounters the symbol, which generates a and a . The interaction between and ensures that the ’s and ’s must switch positions to allow all the ’s to reach . This results in the transformation . Thus, the language generated by
is:
Practical Use of Grammars
This exploration of grammars naturally leads to some important questions about their utility and the types of languages they can generate:
-
What is the practical use of grammars (beyond simple examples like
)?
Grammars play a crucial role in defining the syntax of programming languages. They serve as formal systems for describing the structure of valid expressions and statements in a language, ensuring that code written by developers conforms to a well-defined set of rules. -
What languages can be generated through grammars?
Grammars can generate a wide variety of languages, ranging from simple regular languages (like sequences of terminal symbols) to more complex languages that involve recursive structures, such as context-free languages. They can model the syntax of natural languages, programming languages, and even specialized technical languages. -
What is the relation between grammars and automata?
Grammars and automata are dual concepts in the theory of computation. While grammars generate languages, automata recognize and accept them.
For example, in language compilation, the grammar defines the syntax of the source code, while an automaton (such as a parser or a finite state machine) processes and validates the input, ensuring that it adheres to the grammar’s rules.
Classes of Grammars
Grammars are fundamental tools in formal language theory and serve to generate languages by defining sets of rules. There are various types of grammars, each with specific constraints on how the rules can be applied. These constraints determine the complexity and expressive power of the languages they can generate.
| Class of Grammar | Definition | Automaton Equivalent | Example |
|---|---|---|---|
| Context-Free Grammar (CFG) | For every production rule | Pushdown Automaton (PDA) | |
| Regular Grammar | Every production rule | Finite State Automaton (FSA) | |
| Monotonic Grammar | Every production rule | Linear Bounded Automaton (LBA) | |
| General Grammar | No restrictions on the production rules. | Turing Machine (TM) |

Context-Free Grammars (CFGs)
Definition
A Context-Free Grammar (CFG) is defined by the property that for every production rule
, the left-hand side of the rule is a single nonterminal symbol, i.e., , meaning that is an element (the set of nonterminal symbols).
The term “context-free” refers to the fact that the rewriting of
Context-free grammars are widely used in computer science, particularly for defining the syntax of programming languages. For example, Backus-Naur Form (BNF), which is commonly used to specify programming language grammars, is essentially a form of CFG.
Grammars
Regular Grammars
A Regular Grammar is a more restricted form of a context-free grammar.
Definition
For a grammar to be regular, every production rule must have the form
, where and . This means that the right-hand side can either be a terminal symbol followed by a nonterminal symbol, or just a terminal symbol.
Regular grammars are strictly simpler than context-free grammars, and as such, they can only generate regular languages, which are recognized by finite state automata (FSA).
Regular grammars are a subset of context-free grammars, meaning all regular grammars are context-free, but not all context-free grammars are regular.
Example
For example,
is a regular grammar, whereas is not because its rules do not fit the regular grammar constraints.
Monotonic Grammars
Definition
A Monotonic Grammar is characterized by production rules of the form
, where . This means that when rewriting a nonterminal symbol, the length of the string is either preserved or increased, but never decreased.
Monotonic grammars allow for the generation of languages that require specific contextual dependencies, hence they are also referred to as context-sensitive grammars. However, for the empty string, we require a special rule
Regular grammars are inherently monotonic, as their rules always produce strings of equal or greater length. However, context-free grammars are generally not monotonic because they can include rules that decrease the length of the string, such as
Example
For example, a rule like
can be transformed into a set of monotonic rules by replacing it with several alternatives: In this way, monotonic grammars avoid rules that reduce string length.
Relation Between Grammars and Automata
The relationship between grammars and automata is a fundamental topic in the theory of computation. Automata serve as recognition devices for languages, while grammars serve as generation devices. Different classes of grammars correspond to different types of automata.
- Regular Grammars and Finite State Automata (FSA): Regular grammars generate the same languages that finite state automata accept. This equivalence can be demonstrated by transforming an FSA into a regular grammar, and vice versa.
NOTE
Given an FSA
, we can construct a regular grammar as follows:
- Let
(the nonterminal symbols are the states of the automaton). - Let
(the terminal symbols are the input alphabet). For each transition
, introduce a production rule . If , add the rule to account for accepting states.
- Context-Free Grammars and Pushdown Automata (PDA): Context-free grammars correspond to PDA, which are a more powerful class of automata that can make use of a stack. PDAs can handle recursive structures and nested dependencies, which regular FSAs cannot. A context-free grammar can be converted into a PDA, and vice versa, although the resulting automaton will often be nondeterministic.
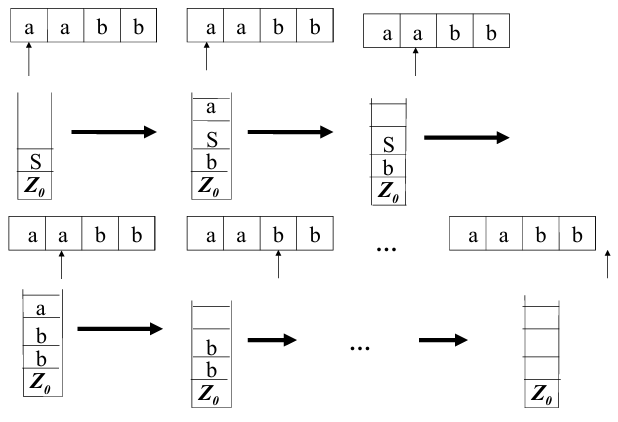
Example: Pushdown Automata for Context-Free Language
Consider the grammar
, which generates strings with equal numbers of ’s followed by ’s. This grammar can be represented by a pushdown automaton that pushes an onto the stack for every occurrence of in the string and pops it when encountering a . Here is an intuitive representation of how the automaton processes the string:
graph LR q0((q0)) q1((q1)) q2((q2)) q3(((q3))) q0 -- a Z0 | S Z0 --> q1 q1 -- a S | SS --> q1 q1 -- b S | ɛ --> q2 -- b S | ɛ --> q2 q2 -- ɛ Z0 | Z0 --> q3In this diagram, the pushdown automaton processes strings by pushing symbols onto the stack when reading an
and popping them when reading a , ensuring that the number of ’s and ’s match.
General Grammars and Their Equivalence to Turing Machines
General grammars, which impose no specific restrictions on their production rules, are equivalent in power to Turing machines (TM). This means that any language that can be generated by a general grammar can also be recognized by a Turing machine, and vice versa. This equivalence is crucial for understanding the computational power of grammars, as Turing machines are a model of computation that can simulate any algorithm or computational process.
Constructing a Nondeterministic TM from a Grammar
Given a grammar
Steps
- Input on the Tape: The input string
is initially placed on the TM’s input tape. - Memory Tape: The TM has a memory tape that, at any given point, contains a string
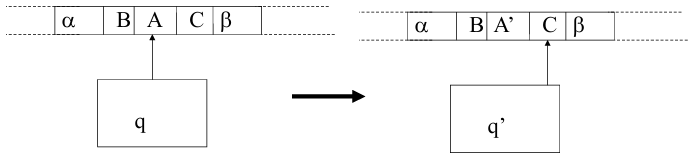
(a string composed of terminal and nonterminal symbols). The goal of the TM is to rewrite this string according to the rules of the grammar. - Looping Process:
- The TM scans the memory tape, looking for a substring
that matches the right-hand side of some production rule . - Once it finds such a substring—choosing nondeterministically among possible matches—the TM substitutes
with the left-hand side .
- Acceptance: If, after applying the production rules, the memory tape contains the start symbol
, then the input string is accepted. In formal terms, follows the derivation relation in reverse, transforming the input string into the start symbol.
This method mimics the derivation process of the grammar but operates nondeterministically, meaning the TM explores multiple paths simultaneously. If any path leads to the start symbol
The TM operates under the condition that it may never terminate if
Constructing a Grammar from a TM
Conversely, we can also construct a grammar
Steps
- Generating Strings with a Special Marker: First,
generates strings of the form X x \in V_T^* X x x = aba G aba$ABA$. - Simulating TM Configurations: The grammar
is then designed to simulate the successive configurations of the TM, using the part of the string to the right of the marker $$$. - Derivation Corresponding to TM Moves: For each move of the TM, there is a corresponding derivation in the grammar. The grammar is structured so that if the TM accepts the string
, then there will be a derivation that reduces X x$.
Example
Consider the following grammar designed to simulate the behavior of a TM for strings
X {a, b}$: This grammar simulates the operations of the TM by rewriting the symbols to match the TM’s transition rules. For example, if the TM is in state
and reads symbol , the grammar rewrites according to the transition function of the TM.
The general idea is to represent the configuration of the TM as a string on the grammar’s tape. Each derivation step of the grammar simulates a move of the TM, ensuring that the string is accepted by the grammar if and only if it is accepted by the TM.
- Transition Rules: Each transition function
of the TM is mirrored by a corresponding rule in the grammar.
For example, if
, the grammar includes a rule like , indicating that the TM moves to state , writes symbol , and moves the tape head to the right.
- Handling the End of the Tape: The grammar includes rules that handle special cases, such as when the TM reaches the end of the tape or when it enters the final state
. In these cases, the grammar deletes any symbols to the right of the marker $$$, ensuring that the string is properly reduced to a terminal form.
Monotonic Grammars and Linear Automata
For monotonic grammars, where every production rule lengthens or preserves the length of the string, the simulation of the TM is even simpler. In such cases, the grammar does not need additional memory cells beyond what is originally occupied by the input string, except for handling the empty string.
A linear automaton can simulate the behavior of monotonic grammars. Linear automata are a restricted form of Turing machines where the tape length is bounded, reflecting the monotonic nature of the grammar.
One important distinction when simulating TMs with grammars is the issue of non-termination. A nondeterministic TM may continue exploring derivation paths indefinitely if the input string is not in the language