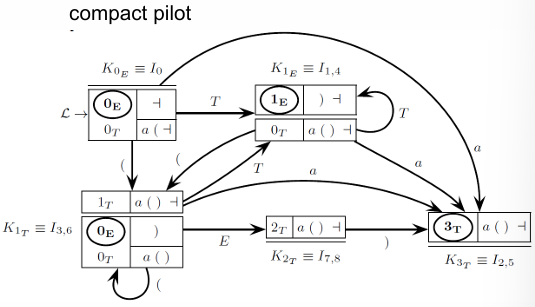
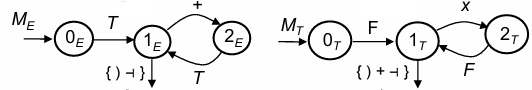In a top-down analysis, the parsing process starts from the highest level of the grammar, working downwards through its rules to match the structure of the given input.
Example
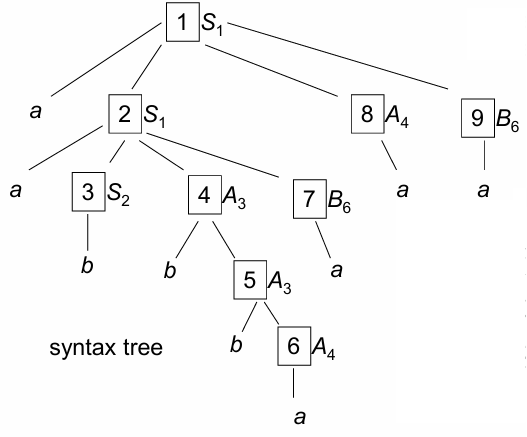
Consider the following the sequence of symbols to be parsed: “.” Here, the numbers next to each grammar rule represent the order in which these rules are applied, while the subscripts on non-terminal symbols indicate which rule produced each component of the syntax tree. Importantly, this analysis is guided by a Backus-Naur Form (BNF) grammar, where each production rule dictates how non-terminals are expanded into sequences of terminals and other non-terminals, strictly in a left-to-right order as the parser proceeds through the string from leftmost symbol to rightmost.
The BNF grammar is as follows:
These rules apply in a leftmost derivation order, meaning each leftmost non-terminal is expanded first, ensuring a top-down, left-to-right build of the syntax tree.
This analysis method, while derived from bottom-up parsing principles, is structured with top-down constraints. These constraints simplify the parsing process by limiting which branches or rules can apply based on specific conditions observed in the input. In this context, the parsing mechanism—often a Pushdown Automaton (PDA)—functions as a self-guided machine that can operate independently without requiring a predefined guide or pilot graph.
The machine network alone directs the syntax analyzer’s decisions, recognizing the appropriate grammar rule to apply as soon as it encounters the first significant character generated by that rule. By operating within these constraints, the top-down parsing process essentially becomes an immediate and efficient recognizer, able to decide on rule applications based on local context.
A critical goal here is to transform the machine network into a "pilot graph" that can autonomously guide the syntax analyzer, though this requires specific annotations to indicate preferred branches in ambiguous cases.
In other words, for cases where multiple options might apply, annotations in the network will signal the correct path, removing the need for external pilot data.
This design aligns well with Extended Backus-Naur Form (EBNF) grammar, which uses constructs such as optional and repeated patterns to concisely describe possible sequences. For instance:
The EBNF grammar here illustrates that expressions () consist of terms () joined by additions, where each term is a factor () potentially multiplied by others. Factors may be atomic symbols like “a” or nested expressions, indicating a recursive structure.
The parser implementation follows this grammar pattern as demonstrated in a procedural example:
procedure T call F while (cc == ‘×’) cc := next call F end if (cc ∈ { ) + - | }) return else error endifend T
This pseudocode demonstrates the recursive call structure, where “T” recursively calls “F” as long as a multiplication operator (“×”) is encountered, advancing the character (cc) and checking for potential error conditions before returning.
In contrast, bottom-up analysis involves a state-driven approach where multiple parsing threads may be active simultaneously.
For example, consider a grammar with multiple transitions, as in the grammar and . This grammar allows transitions across various states (, , , etc.), each with potential concurrent transitions.
Such concurrency leads to what is called the Single Transition Property when absent, a condition ensuring no convergent paths within the pilot structure. This property is essential in top-down analysis, where the absence of multiple transitions guarantees a singular, conflict-free path through the grammar rules.
Leftmost recursion, a form of recursive derivation, poses particular challenges to top-down analysis.
Definition
A derivation is called leftmost recursive if it continually expands the leftmost symbol into another instance of itself (e.g., where ).
For example, the following grammar exhibits leftmost recursion:
Such grammars, particularly those involving nullable non-terminals or direct recursion, prevent a straightforward top-down approach. Top-down parsers require alternative formulations or transformations of recursive rules to ensure that expansions are not left-recursive, allowing the syntax tree to be constructed without infinite regress or cyclic dependencies.
ELL(1) Condition for an EBNF Grammar
To understand the ELL(1) condition for an Extended Backus-Naur Form (EBNF) grammar, we must first recognize what makes a grammar ELL(1). An EBNF grammar, , qualifies as ELL(1) if it meets three specific criteria. These conditions, while interconnected, collectively ensure a streamlined, efficient parsing process:
No Leftmost Recursive Derivations:
In an ELL(1) grammar, derivations that are leftmost recursive are prohibited. Leftmost recursion occurs when a non-terminal symbol in the grammar can expand directly (or indirectly through intermediate rules) to another instance of itself on the leftmost side of a production rule. Eliminating leftmost recursion helps prevent parsing loops and allows the parser to proceed predictively.
ELR(1) Condition in the Pilot Graph:
The pilot graph of the grammar must meet the ELR(1) condition. This means that every parsing decision point in the graph provides a clear and unique path to follow based on the next symbol in the input. By enforcing the ELR(1) condition, ambiguity is avoided, as each state in the parsing process has a distinct outcome.
Single Transition Property (STP):
The pilot graph must have no multiple transitions, satisfying the Single Transition Property (STP). Multiple transitions at a given state could otherwise lead to conflicting paths, as the parser might encounter situations where more than one path could be taken. With STP, each state in the pilot graph has a single, defined transition, allowing the parser to proceed without ambiguity.
Although these three criteria are listed individually, they interact in ways that reinforce each other.
For instance, eliminating leftmost recursive derivations often reduces the chance of multiple transitions, simplifying the overall pilot graph. However, to maintain simplicity in analysis, it’s usually best to uphold each condition independently.
The family of ELL(1) grammars is a subset of ELR(1) grammars, meaning all ELL(1) grammars are also ELR(1). However, not all ELR(1) grammars qualify as ELL(1), as the latter is a stricter classification.
This distinction is important, as it reflects that ELL(1) grammars represent a more narrowly defined class of languages, enabling highly deterministic parsing structures.
Example
Consider the following EBNF grammar:
In this grammar, the non-terminal represents a sequence of terms, while can either be a nested expression or a terminal . This structure aligns with the ELL(1) criteria since it avoids leftmost recursion, maintains a unique path at each decision point, and has no multiple transitions.
Simplified ELL(1) Pilot
The structure of an ELL(1) grammar provides substantial simplifications in the parsing process, making it more efficient and predictive:
Predictive Decision-Making: In ELL(1) parsing, each machine state (-state) is simplified to contain only one item, allowing the parser to immediately identify the correct rule to apply. Unlike bottom-up parsing methods that may require waiting for a reduction step, ELL(1) parsing allows anticipatory decisions, streamlining the process.
No Need for Stack Pointers: Since ELL(1) parsing inherently limits the parser to a single analysis thread, there’s no need to track or store alternative parsing paths. This single-threaded approach negates the need for stack pointers, as only one rule application sequence is followed at any time.
Stack Contraction: With only one active analysis thread, the parser stack only needs to track the sequence of machines followed, rather than each state traversed. This simplifies memory usage and improves efficiency, as redundant state tracking is avoided.
To further optimize the pilot graph, specific restructuring techniques are applied:
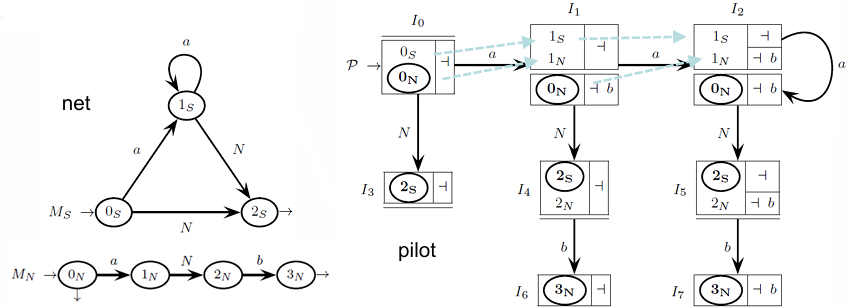
Closure State Separation: Initial states of machines, known as closure states, are separated. This separation results in a pilot graph that closely mirrors the machine net, with additional arcs, called “call arcs,” linking various states.
Call Arcs: A call arc exists between two states if the machine associated with the source state has a transition leading to the target state. Specifically, a call arc from to will be created only if there’s a transition in machine from to some state involving . When two or more initial states are present within a closure state, this structure can initiate a chain of calls.
The process relies on the kernel-identity relation, an equivalence relation that groups states with the same kernel—those with equivalent look-ahead items. By merging states in this way, transitions with the same label from kernel-identical states proceed to corresponding kernel-identical destination states. This simplification means that the -state bases, which only contain non-initial states (a result of satisfying the Single Transition Property), are mapped in a one-to-one correspondence with the non-initial states of the machine net. Consequently, the pilot graph starts to resemble the machine net closely, making the structure more efficient and reducing redundancy.
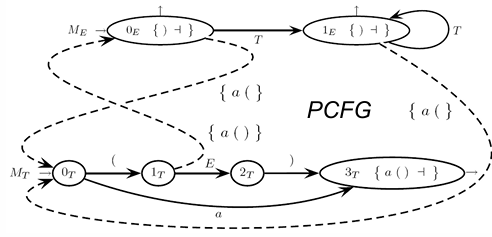
The Parser Control Flow Graph (PCFG)
The Parser Control Flow Graph (PCFG) becomes the core control unit of the ELL(1) syntax analyzer. It governs the parsing decisions within the ELL(1) framework, handling transitions with precision by incorporating guide sets, which are the sets of expected characters that guide decision-making. In the PCFG:
Prospect Sets: These are look-ahead sets included only in the final states, determining whether the machine should terminate a parse sequence or continue to another transition.
Call Arcs: Represented by dashed arcs, these arcs are marked with guide sets that specify the anticipated input characters following the call. Guide sets on call arcs help the parser choose among potential actions, including scanning a terminal, initiating a specific call transition, or exiting if the machine is in a final state.
Guide Set Conditions: For every call arc originating from the same state, guide sets must be mutually exclusive, meaning they must not overlap. This mutual exclusivity also applies to any scan arcs emanating from the same state, ensuring that the parser’s choices are deterministic. For example, in a final state containing an item , the guide set , which indicates the expected characters when the machine terminates.
In a PCFG, each type of arc represents specific parsing instructions:
Terminal Arcs: An arc labeled executes if the current input character . Terminal arcs serve as conditional transitions triggered only by specific characters.
Call Arcs: A call arc operates if the current character matches one of the characters in the guide set . This ensures that call transitions occur only when the appropriate input is encountered.
Exit Arcs (Darts): An exit arc from a final state containing executes if , allowing for clean exits from a machine based on anticipated look-ahead.
Non-Terminal Arcs: A non-terminal arc functions as an unconditional return from a machine, enabling smooth transitions without requiring specific input conditions.
The disjoint guide set requirement ensures that in bifurcation states, where multiple transitions might otherwise be ambiguous, each possible transition has a distinct guide set. This criterion is central to the ELL(1) condition, as it guarantees unambiguous parsing by ensuring that no guide set overlaps with others. Thus, by upholding these conditions, ELL(1) parsing becomes both efficient and deterministic, with each parsing decision clear and well-defined.
Implementing the Parser by Means of Recursive Procedures
In the implementation of an ELL(1) parser using recursive procedures, the goal is to model the parsing process through a set of procedures, each corresponding to a non-terminal in the grammar. These procedures control the flow of the parser, ensuring that parsing decisions are made based on the current input symbol and the predicted set of valid next symbols. This approach is also known as recursive descent parsing, where each non-terminal in the grammar is represented by a recursive function, and transitions between grammar rules are implemented as function calls.
Steps
The parser operates by defining a set of procedures, one for each non-terminal in the grammar. These procedures are structured as follows:
Call Move: This corresponds to calling a procedure for a non-terminal.
Scan Move: This corresponds to scanning the next input symbol using a lexical analyzer (often represented as a function next).
Return Move: This corresponds to returning from a procedure when a rule has been successfully applied.
The Parser Control Flow Graph (PCFG) becomes the underlying control structure for the recursive procedures. It governs which procedure (non-terminal) to call and when to transition between states based on the look-ahead characters, as specified by the guide sets and prospect sets.
Recursive Descent Parsing: Example
Consider the running example, we can define the following procedure:
program ELL_PARSER cc = next {Initialize current character from input} call E {Call procedure E to start the parsing} if cc ∈ {⊣} then accept {Accept if the end-of-input symbol ⊣ is reached} else reject {Reject if parsing fails} end ifend programprocedure E{Optimized procedure for E} while cc ∈ { a, ( } do call T {Call procedure T while the current character is either 'a' or '('} end while if cc ∈ { ), ⊣ } then return {Return if the current character is either ')' or end-of-input symbol ⊣} else error {Throw an error if no valid symbol is found} end ifend procedureprocedure T {Procedure for T (state 0T)} if cc ∈ {a} then cc = next {If the current symbol is 'a', scan the next symbol} else if cc ∈ { ( } then cc = next {If the current symbol is '(', scan the next symbol} {State 1T: Proceed if the next symbol is 'a' or '('} if cc ∈ { a, ( } then call E {Call procedure E} else error {Throw an error if the symbol does not match} end if {State 2T: Proceed if the next symbol is ')'} if cc ∈ { ) } then cc = next {Scan the next symbol (closing parenthesis)} else error {Throw an error if no ')' is found} end if else error {Throw an error if no valid symbol is found for T} end if {State 3T: Return if we encounter 'a' or closing parenthesis at the end} if cc ∈ { a, (), ⊣ } then return {Return to the calling procedure} else error {Throw an error if no valid end symbol is found} end ifend procedure
Main Program (ELL_PARSER):
The parser starts by calling the E procedure, which corresponds to parsing the start symbol of the grammar. It initializes the current character (cc) by calling the next function, which scans the next input symbol. If the input character is the end-of-input symbol (denoted as ⊣), the parsing is successful and the program accepts the input. If parsing fails at any point, it is rejected.
Procedure E:
The procedure for E checks if the current symbol is either a or an opening parenthesis (. It repeatedly calls the T procedure while either of these symbols is found. If the current symbol is either ) or ⊣ (end-of-input), the procedure successfully returns, indicating that parsing of E is complete. Otherwise, an error is thrown.
Procedure T:
The procedure for T handles different parsing scenarios:
State 0T: If the current symbol is a, it scans the next symbol. If the symbol is an opening parenthesis (, it moves to state 1T.
State 1T: If an opening parenthesis was encountered, it expects either a or another opening parenthesis ( and calls E recursively. If this condition is met, it continues to state 2T.
State 2T: After processing an E procedure call, it expects a closing parenthesis ) and proceeds accordingly.
State 3T: Finally, if the current symbol is a, ), or ⊣, the procedure successfully returns.
Direct Simplified Construction of the PCFG
The Direct Simplified Construction of the PCFG involves directly annotating the machine net with the necessary control flow (i.e., call arcs) and look-ahead information (i.e., prospect and guide sets) without constructing the full ELR(1) pilot graph. This approach simplifies the process by directly integrating the necessary information into the parsing machine.
Steps
Direct Annotation of the Machine Net:
Instead of building the complete ELR pilot graph and then deriving the PCFG from it, the call arcs are directly added to the machine net. The machine net is then annotated with prospect sets and guide sets.
Prospect Set Computation:
The prospect sets are computed using a recursive approach. These sets represent the characters that are expected in the input soon after a particular machine state is reached. The prospect set for a state is influenced by the rules already encountered in the parsing process, leveraging previously computed look-ahead sets for ELR(1) analysis. However, for the ELL condition, only the prospect sets in the final states (those with a final dart) are considered.
For an initial state , the prospect set is computed as:
In this equation:
refers to a transition in the grammar.
represents the look-ahead set for the rule .
is the condition that checks if the set can lead to a nullable state (a state that can derive the empty string).
The prospect set is then updated by combining the look-ahead sets of any rules that lead from to , but only if the nullable property applies.
For any other state , the prospect set is computed as:
This recursive rule means that for each state , the prospect set is the union of the prospect sets of the states that transition to via a non-terminal .
Initialization:
The prospect set of the initial state of the axiomatic machine is initialized with the look-ahead set of the start symbol.
All other prospect sets are initialized to the empty set.
Guide Set Computation:
The guide sets are used to guide the parsing process, helping the parser decide which move to make. The guide set for an arc (particularly a call arc) is defined as the set of characters that are expected in the input shortly after the machine makes the transition. These sets ensure that the parser follows the correct path and can resolve ambiguities in the parsing process.
Guide sets are used to determine whether the parser should execute a call move, scan move, or return move. For example:
A call move (such as calling a procedure for a non-terminal) is executed if the current character matches one of the symbols in the guide set.
A scan move (such as scanning the next terminal symbol) occurs when the current character matches a terminal symbol.
A return move is performed when the parser has reached a final state and can return to the calling procedure.
The Role of Final States:
The final states of the machine net play a crucial role in the prospect sets and guide sets. These final states are the only states where the prospect set is directly used for decision-making. Additionally, the guide sets in the final states help determine whether the parser should exit or continue parsing.
where is a final state
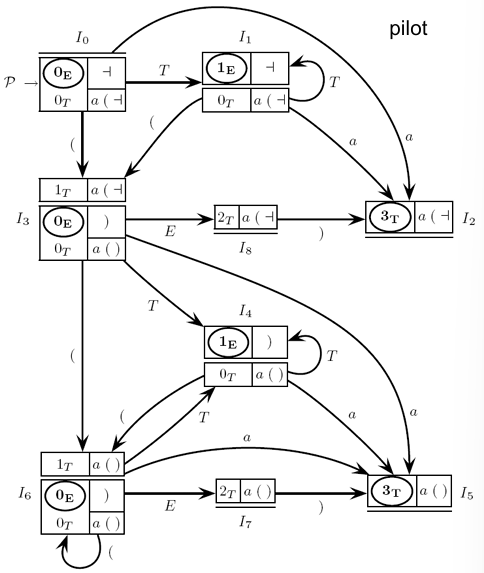
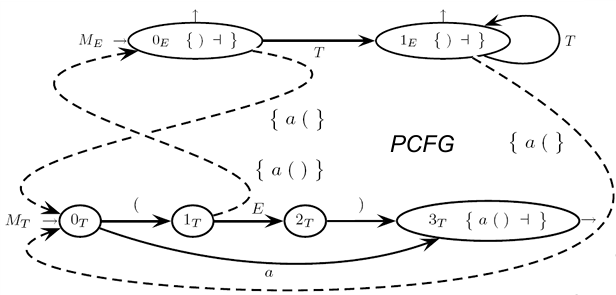
Example (Continue)
In this running example, we follow a clear sequence of steps to iteratively compute the prospect sets and guide sets for the given machine net, which represents a grammar with a recursive structure. The goal is to prepare the Parser Control Flow Graph (PCFG) by determining the characters that guide the parsing process.
Step 1: Iteratively Compute the Prospect Sets
The prospect sets represent the expected look-ahead characters for each state in the parsing process. They are computed iteratively by considering the transitions in the grammar and propagating the expected characters through the machine net.
Computing Prospect Set for :
Transition implies that we add the prospect set of state to the prospect set of state .
The initial set for is , and we add because of the nature of the final state. Therefore:
Computing Prospect Set for :
Transition and lead to the prospect set for state and propagate the prospect set from .
The initial set for is , and we already have from . So, the final prospect set for is:
Step 2: Iteratively Compute the Guide Sets
The guide sets help the parser decide which action to take at each state, whether to scan a terminal, make a call, or return from a procedure. These sets are computed iteratively by considering the possible transitions and the corresponding look-ahead characters.
Computing Guide Set for Transition :
The guide set for this transition is based on the initial set of .
Computing Guide Set for Transition :
Similar to the previous step, the guide set for this transition is based on the initial set of .
Computing Guide Set for Transition :
The guide set for this transition is the union of the initial sets of and (since follows from ), along with the guide set from the transition .
From the earlier steps:
Therefore, the final guide set is:
Lengthening the Prospect for Grammars Not ELL(1)
When a grammar does not satisfy the ELL(1) condition, one alternative is to increase the look-ahead to symbols or tokens. This approach is often necessary when a conflict arises between parsing alternatives, and more context is needed to disambiguate the choices.
If the grammar doesn’t meet the ELL(1) condition, you can attempt to transform it into a ELL(1) grammar or, as a simpler alternative, use a longer look-ahead in the parsing process. By using a look-ahead of length , the analyzer looks at multiple consecutive characters (or tokens) before making a decision. If the guide sets of length on alternative moves are disjoint, then the grammar is suitable for an ELL(k) analysis.
This approach is often used in contexts where the grammar is not naturally left-recursive, or when certain ambiguities can be resolved by looking ahead at a sequence of tokens.
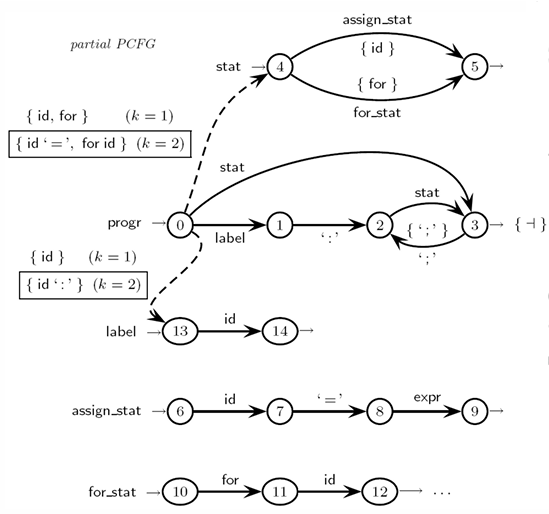
Example with Look-Ahead
Consider the grammar for a simple programming language where there is a conflict between instruction labels and variable names.
The grammar has a potential conflict with the id symbol, which can either be:
A label (when followed by a colon :), or
An identifier for an assignment (when followed by an equals sign =).
To resolve this conflict, we can use a look-ahead of length 2. This means that instead of making a decision based solely on the first token (e.g., id), we look at the next token as well. If we encounter the sequence:
id :, we interpret it as a label.
id =, we interpret it as an assignment statement.
Thus, the look-ahead mechanism helps to disambiguate the alternative rules when encountering id, based on what follows it. By extending the look-ahead to two tokens, we can reliably differentiate between labels and variable assignments.
For the grammar rules, the look-ahead would help identify the appropriate alternative:
Steps
For the label rule:
If we encounter id, the next token (after the id) will determine if it is a label or an assignment.
If the next token is a colon :, the id is interpreted as a label.
For the assign_stat rule:
If we encounter id, the next token will indicate whether it’s part of an assignment.
If the next token is an equals sign =, the id is interpreted as part of an assignment.
The key here is that the guide sets (or look-ahead sets) of length are disjoint:
One set corresponds to labels (id :).
Another corresponds to assignments (id =).
Since these sets are disjoint, we can safely choose between these alternatives based on the two-token look-ahead.