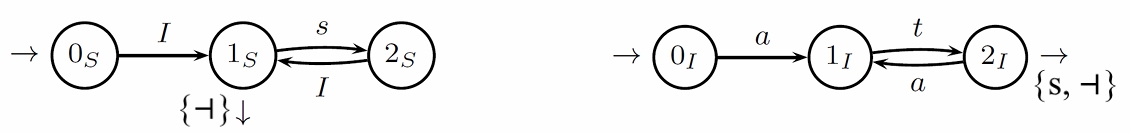In bottom-up syntax analysis, or shift-reduce parsing, we analyze a string by incrementally building a parse tree from the “leaves” (the input tokens) up toward the root (the start symbol). This approach is helpful in syntactic parsing because it allows us to effectively determine when to transition between states (shift operations) and when to recognize a complete phrase or expression (reduce operations) based on the structure of the input and specific sets known as follow sets.
Defining Look-Ahead and Decision-Making
For a non-terminal in a grammar, the follow set—often called the look-ahead or prospect set—plays a crucial role in guiding the parsing process. The follow set of a non-terminal symbol (like or ) includes all symbols that can appear immediately to its right in the derivations. These sets allow us to:
Determine when to continue with a shift operation, where an automaton transitions to analyze the next input symbol, effectively moving forward in the parse.
Decide when to perform a reduction, grouping a set of symbols and recognizing a non-terminal. This reduction creates a sub-tree in the parse tree, moving the analysis closer to establishing the overall structure.
Given the simple grammar rules:
the symbol represents a regular language that can be defined by a regular expression. By using follow sets, we can effectively decide whether to shift (continue scanning) or reduce (group symbols according to a rule).
Parsing Trace Example for String x = atasat ┤
Let’s consider the parsing trace for the string to see how shifts and reductions are determined. Initially, we start with a macro-state that contains the initial states for the non-terminal symbols and . The parsing of the axiom starts by examining with an -move, referred to as a closure or completion move.
Steps
The following steps outline the process:
Shift on ‘a’: Since from state there exists an arc labeled ‘a’, and the current character () is ‘a’, a shift occurs.
Shift on ‘t’: From state , there is a transition on ‘t’, and with , another shift takes place.
Shift vs. Reduce Decision: As , and ‘a’ is not in the follow set of , we continue with another shift.
Shift on ‘t’: From state , another transition on ‘t’ with prompts a shift.
Reduce Decision: Upon reaching , which is in the follow set of , a reduction is made. The parser scans back in the stack to locate the initial state , removing the explored section and recognizing .
This reduction creates a non-terminal, represented by the newly formed sub-tree for , after which the parser continues with further shifts and reductions until it reaches , which is in the follow set of , indicating an acceptance of the parsed structure.
In some cases, it is difficult to determine the exact reduction without examining the input string over a longer segment, as shown in the following example using a different grammar.
Example
Consider the grammar
graph
subgraph 1[ ]
S((S)) --> 0s((0s)) -- a --> 1s((1s)) -- E --> 2s(((2s)))
0s -- E --> 2s
end
subgraph 2[ ]
E((E)) --> 0e((0E)) -- a --> 1E((1E)) -- a --> 2E(((2E))) -- a --> 1E
end
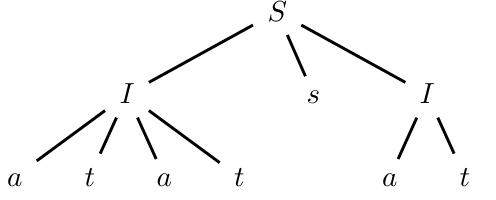
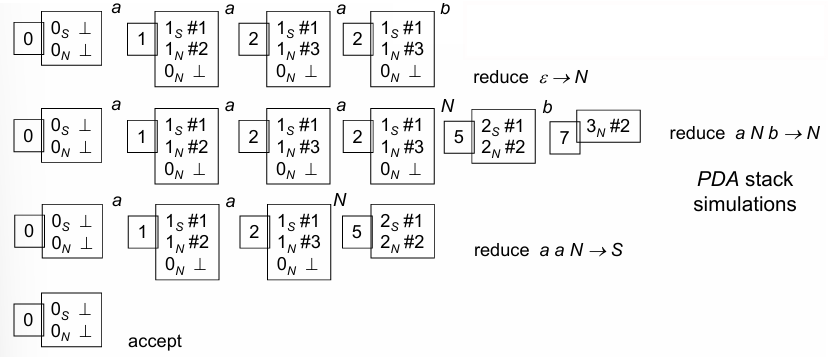
For languages such as of even length strings and odd length strings with an extra ‘a’ , the parser must handle derivations differently based on whether the input length is even or odd. For instance, with the input string “aaa,” the parser must decide whether to interpret “aaa” as an even or odd-length structure.
To keep track of the parsing history and aid in making accurate decisions, we use a stack that stores backward-directed pointers. These pointers are represented by bounded integers, maintaining a finite stack alphabet for the Pushdown Automaton (PDA). For example, with the input “aaa,” the stack in the second macro-state holds a record of computations, tracing transitions that clarify whether to reduce based on even or odd parsing interpretations:
Using the backward pointers, the parser decides which reduction to apply by examining the reachable states in the stack. For instance, a reduction might be executed from the state set , confirming an even-length interpretation for “aaa,” or from , which would signify an odd structure.
This history-based tracking in the stack is essential for languages with context-sensitive aspects, where deriving the correct structure may not be immediately apparent. Thus, bottom-up parsing not only requires look-ahead through follow sets but also benefits from stack-based history to disambiguate multiple parsing paths, providing an effective method for syntactic analysis in complex grammars.
Systematic Construction of the Bottom-Up Syntax Analyzer
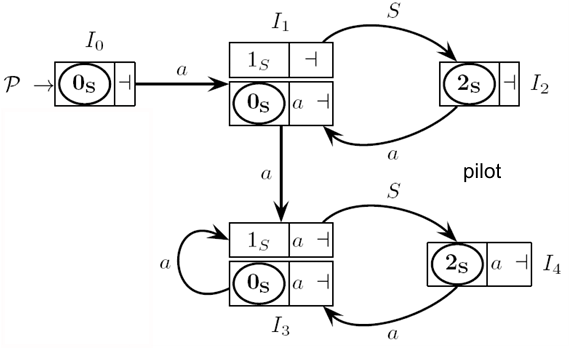
The systematic construction of a bottom-up syntax analyzer, also known as a Pushdown Automaton (PDA), involves a structured approach that ensures efficient parsing of input strings within a formal language. At the core of this construction is the pilot graph, a critical structure that guides the PDA’s operations.
Definition
The pilot graph directs the PDA’s movement through various states based on the input symbols it processes. In each of these states, called macro-states or -states, the pilot encapsulates information about all potential phrase forms that could reach that state.
This preemptive structuring helps the PDA anticipate and handle a range of parsing situations systematically.
Each -state within the PDA is composed of several machine states, each designed with a specific look-ahead mechanism. Look-ahead is a predictive capability allowing the PDA to foresee the input symbols expected at reduction points, that is, when the parser concludes that a certain input string segment matches a known pattern or rule. This look-ahead aligns with the “follow” sets of grammar elements, where each set determines which symbols are allowed to appear after a given non-terminal in the input string. By maintaining this look-ahead information, the PDA is better equipped to make informed parsing decisions, especially during complex reductions.
To construct the PDA’s parsing strategy, the system relies on a collection of analysis threads built within the stack. These threads represent potential derivations or paths the PDA could take as it attempts to match the input string to the grammar’s syntax rules. Each thread corresponds to a computational pathway in the underlying machine network, where the parsing process can be visualized as paths or arcs. These arcs, marked by transitions labeled with scanned input strings, are traversed based on parsing decisions.
Notably, -arcs are used to signify transitions where the PDA moves between states without consuming an input symbol, enabling flexibility in handling non-terminal symbols or empty transitions.
To ensure that the PDA can operate deterministically—that is, without ambiguity or conflict—the system must verify specific determinism conditions within the pilot graph. There are three primary types of conflicts that could disrupt determinism and need to be carefully checked:
Shift-Reduce Conflict: This conflict occurs when the PDA faces ambiguity in choosing between shifting (i.e., reading the next input symbol) and reducing (i.e., recognizing a phrase).
Reduce-Reduce Conflict: Here, two or more reductions are possible simultaneously, leading to ambiguity as the PDA cannot decide which phrase to reduce.
Convergence Conflict: This rarer conflict arises when two or more parsing paths merge into the same state with overlapping look-ahead sets, making it unclear which path to follow.
Once the pilot graph passes the determinism tests and confirms that no conflicts are present, the PDA can proceed to analyze strings deterministically. This deterministic mode ensures that each input string has a unique, conflict-free parsing path, allowing the PDA to efficiently recognize whether the string conforms to the grammar.
Set of Initials
The concept of the Set of Initials () is a systematic method for identifying the set of characters that could appear at the beginning of any string derivable from a given state in the machine within a network of machines . This set resembles the Berry-Sethi initial set but incorporates unique logical cases for computing initials based on specific transitions in the automaton.
Definition
To formally define this set, the initials represent all characters in the alphabet that, when followed by any string in , intersect non-trivially with the language at state . Mathematically, this is expressed as:
The initials can be determined under three distinct cases, defined as follows:
Direct Transition: if there exists a transition arc . This implies that can appear directly from as it has an immediate transition labeled .
Indirect Transition through Another Machine: if there exists an arc and , where is the initial state of a submachine . This condition implies that if has a transition to another machine and is in the initials of ‘s starting state, then is also in .
Nullable Transition: if there exists an arc , the language (for the start state of ) is nullable, and . Here, “nullable” indicates that can accept the empty string, allowing the initials to include as if starting directly from .
Example
The given grammar consists of the following production rules:
Here, we have the start symbol , and non-terminal symbols , , and . Terminal symbols are , , and , where represents an empty string, allowing and to produce an empty output.
Production for : The rule indicates that can produce the non-terminal followed by the terminal . This suggests that any derivation from must end in once has been expanded.
Production for : The rule allows to be decomposed into followed by . Given that both and can independently produce either a terminal or , this structure implies that might resolve to an empty string if both and derive .
Production for : The rule allows to be either the terminal or , meaning that can either contribute to the string or be skipped over in derivations.
Production for : Similarly, indicates that can produce either or , offering flexibility in the formation of strings from .
The grammar’s states can be visualized in a transition system with designated initial states and transitions between them based on symbol productions. Each non-terminal, starting from an initial state, undergoes transitions until reaching terminal states or looping back, depending on the production rules. Here’s how each non-terminal behaves under transitions:
Transitions: starts at and moves through state when is produced, then advances to on producing . This path implies will always end with in any derivation.
Transitions: begins at , transitions through upon producing , and completes its path to after producing . This sequence reflects that is built by combining the productions from both and .
and Transitions: Both and have simpler structures. Starting at and respectively, each non-terminal transitions to a terminal state upon producing or , or remains at the initial state if is derived.
To determine the set of initial symbols (denoted ) that can appear at the start of each production sequence, we analyze whether the language derived from each non-terminal can be nullable (i.e., produce an empty string) or contains specific terminals.
Calculating :
Since , the initial symbols for must include those that could initiate since is followed by . This makes , where must be analyzed further because could produce if both and derive .
Calculating :
For , the initial symbols of include those that can appear at the beginning of . Therefore, . Since can produce or , we add to .
Calculating :
After , the initial symbols for determine . Thus, . With , provides for .
Combining Results:
Now that includes the initial symbols from and , we obtain:
Items (or Candidate)
Definiton
The Items (or Candidates) in this system are expressed as pairs , where represents the set of states, and includes the alphabet plus a designated end-marker symbol .
When multiple items share the same state, they can be grouped into a single item to simplify analysis.
For example:
This grouping reduces redundancy and improves parsing efficiency. An item associated with a final state in a machine is known as a reduction item, which signals the end of a derivation.
Closure
To compute the closure of a set of items with look-ahead, we use the Closure Function (). This function recursively applies closure rules to expand the set until reaching a fixed point, where no further items can be added.
Closure Operation
The closure operation is described by the following recursive clause:
In essence, this closure function builds upon existing items in by considering transitions in the machine network that introduce new look-ahead possibilities. When a candidate item exists in , the closure function explores transitions , where additional items may be included if is part of the initials derived from concatenated with .
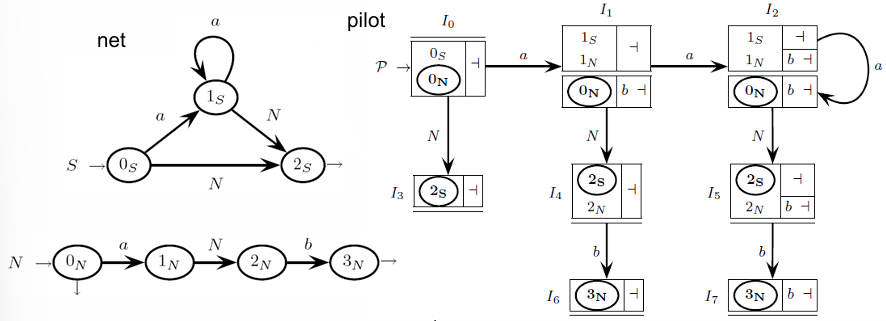
Example
Consider the grammar defined by the following sets:
Alphabet (): This consists of the terminal symbols , , and .
Variables (): The grammar uses two non-terminal symbols: and .
Production Rules ():
The first rule states that can be expanded to zero or more occurrences of , denoted as .
The second rule defines as either a parenthesized expression or a terminal .
This structure allows for the creation of nested and sequential expressions of the form specified in the sample strings.
The sample strings that can be generated from this grammar include:
These strings exemplify the grammar’s ability to create combinations of the terminal symbols, including empty strings, nested parentheses, and concatenated terminal symbols.
In the context of the pushdown automaton (PDA) parsing this grammar, each machine state is represented as and is associated with a look-ahead set . This set contains the terminal symbols that could potentially follow a string generated by the non-terminal .
When parsing, the PDA employs items of the form to keep track of the states and the look-ahead sets. The look-ahead indicates what symbols are expected next based on the grammar’s rules. When the PDA reaches the end of a string generated by the machine , it performs a reduction based on the current character , verifying that belongs to the look-ahead set .
The closure function is crucial in determining the transitions between states and identifying the derivations possible from a given state. The closure operation essentially expands the set of items to include all items that can be derived from the non-terminals in .
function
Here are two specific examples of closures:
Closure of :
Starting with , the closure function identifies that from state , the grammar can transition to the states with look-ahead . This indicates that after , the PDA may expect to see , a left parenthesis, or the end of input (denoted by ).
Closure of :
For , the closure expands to include and . This indicates that after generating , the PDA expects to either see an followed by a closing parenthesis or another preceded by the look-ahead symbols .
Shift Operation θ
The shift operation, often represented by the symbol , is a key component in defining the construction of a pilot graph for certain computational models, particularly in parsing and automata theory. The purpose of this operation is to manage transitions within a machine, , guiding the process of moving from one state to another based on the input symbol and the defined production rules.
Definition
Formally, the shift operation is defined for a pair and a symbol , where represents a state with current position and context , and is the next input symbol. The operation is mathematically specified as follows:
In other words, takes a transition from state to state labeled by the symbol , provided such a transition is defined. If no transition is available for from , the result of is the empty set, indicating that no shift can occur in this context.
The shift operation plays a significant role in parsing within the context of a Pushdown Automaton (PDA). Specifically:
if the symbol is a terminal symbol (i.e., a character directly from the input), then the shift operation reflects a move that reads this character, thus advancing the parsing process.
if is a non-terminal symbol (a construct that can be expanded further by production rules), the shift operation represents an -move, which does not consume any input.
This non-terminal shift occurs after a reduction step in which a substring has been derived to the non-terminal . This is crucial in managing grammar-based transitions, where the machine processes transitions labeled by non-terminals to recognize derived structures.
The shift operation is also extended to sets of items, or “-states,” which are collections of possible configurations that the machine can be in at any given time.
Definition
For a set of candidate items, the shift operation on the set with respect to symbol is defined as the union of the individual shifts for each candidate in :
This extension allows the algorithm to manage multiple potential paths and parse tree configurations simultaneously, making it suitable for handling ambiguous or complex grammars efficiently. In practice, this formulation enables the machine to systematically recognize and transition through various states based on input patterns, maintaining flexibility and precision in parsing operations.
Pilot Graph
Building the pilot graph involves defining a deterministic finite automaton (DFA) called , which is used to control the operations of a pushdown automaton (PDA) rather than recognize strings. The process relies on constructing and updating macro-states (-states), where each -state is a set of items representing possible positions within a grammar rule. This approach ensures efficient tracking of parsing states and grammar symbol transitions.
Definition
The pilot DFA, , is formally defined by several key entities:
Set of -states, : This is a collection of -states, each representing a unique configuration of items. Items in this context indicate positions within the grammar that the parser may reach.
Pilot Alphabet, : The alphabet is the union of terminal symbols (set ) and nonterminal symbols (set ), which collectively form the symbols in the grammar that the pilot will use to define transitions between states.
Initial -state, : The starting point is derived by applying a closure operation to the initial item , effectively representing the beginning state in the pilot graph.
State Transition Function, : The function is computed incrementally, beginning from the initial -state . This function governs the transitions between -states based on the symbols from the grammar.
The construction of the pilot graph is incremental, meaning that the process continues to add new states and transitions until no further changes occur. This procedure ensures that the set of states and transition function are complete and stable by the end of the process. Additionally, the pilot graph itself does not have a final state, as it does not recognize strings directly but rather supports the PDA in parsing.
Each -state is composed of two parts:
Base items: Represent items obtained following a shift operation, defining non-initial states.
Closure items: Represent items obtained after applying a closure operation, often associated with initial states.
In -state terminology, the kernel of an -state consists of items in without considering look-ahead symbols. This is essential for constructing the DFA states without premature input dependencies.
Algorithm for Building the Pilot Graph
The algorithm below outlines the incremental construction of the pilot graph, which involves computing and updating -states and their transitions:
Algorithm
R':={ I0 } // prepare the initial m-state I// loop that updates the m-state set and the state-transition functiondo R:= R' // loop that computes possibly new m-state and arcs for (each m-state I ∈ R and symbol X ∈ Σ ∪ V) do // compute the base of a m-state and its closure I':= closure (θ(I,X)) // check if the m-state is not empty and add the arc if ( I' ≠ ∅) then add the arc I --X→ I' to the graph of θ // check if the m-state is a new one and add it if ( I' ∉ R ) then add m-state I' to the set R end if end if end forwhile (R ≠ R')
Initialize the Set of States: Begin with , where is the initial -state obtained by the closure of .
Update Loop: Continue updating until no new states or transitions are added. Set .
Compute New -states and Transitions: For each -state and each symbol :
Compute the base items of by shifting with and apply the closure to derive a new -state , where .
If is non-empty, add the transition to the graph.
If is a new -state (i.e., ), add to .
Repeat Until Stable: Continue this process until the set of states stabilizes, meaning that no new states or transitions are added in the most recent iteration.
The iterative approach ensures that every possible state and transition for the grammar symbols is explored, leading to a complete pilot graph for the DFA . By the end of the algorithm, the pilot graph will include all necessary -states and transitions to support the PDA in controlling parsing actions, enabling effective handling of grammar constructs through the shift and closure operations defined in each state.
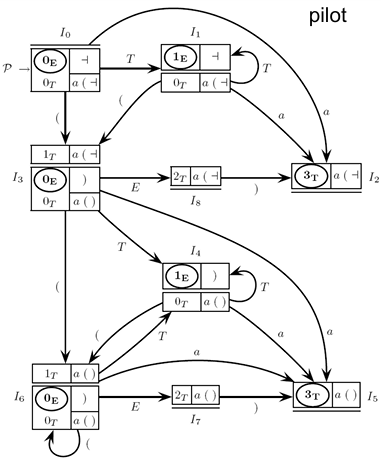
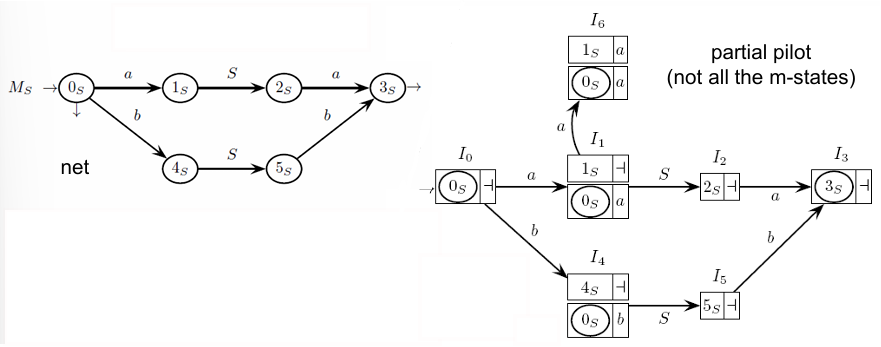
Example
In this example, we explore the construction and behavior of the first three machine states (-states) of a parsing automaton based on a grammar where
Each -state is generated through closure and shift operations, and connections between -states form the foundation of a parsing structure capable of handling the given language.
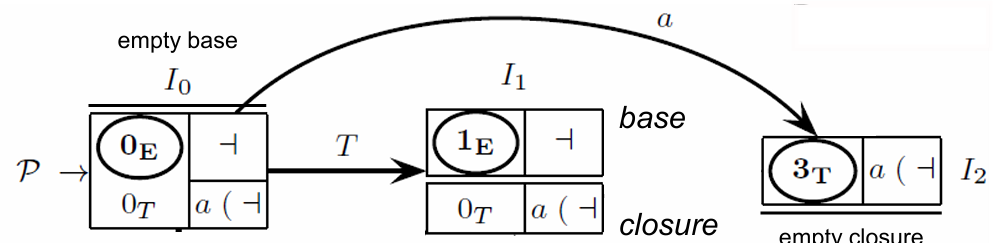
Starting from :
The initial -state is derived by computing the closure for the item , where represents the end of input marker. The closure operation adds items for all possible productions that could follow the non-terminal . As a result, we have:
This set, , now consists of:
, representing the initial state of .
, indicating that after , any of , , or might follow.
Shift Operation:
For the item in , we compute a shift on the non-terminal , leading to a new item . This operation adds a new -state with a corresponding transition arc from to via -arc:
Closure of :
Next, we compute the closure for to complete :
The new -state thus includes:
to maintain the transition of via ,
, allowing further transitions for items produced by .
Transition on Terminal :
For the item in , we perform a shift operation on terminal , resulting in the item . This shift generates a new -state and an -arc connecting to :
Closure of :
The closure of produces no additional items, so is simply:
With this, we conclude the structure of , a state that does not expand further since its closure is empty.
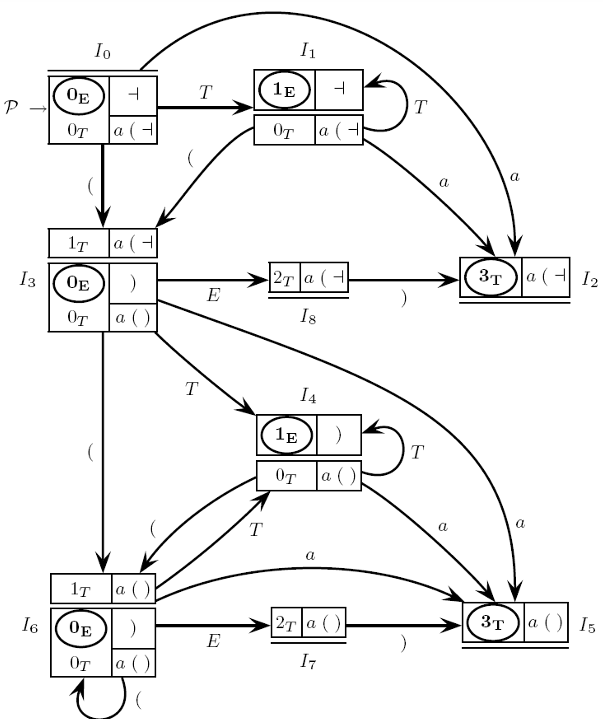
Kernel-Equivalent State Pairs
Kernel-equivalent states are pairs of -states with identical base items (kernels) but possibly differing closures. These pairs allow the parser to consolidate similar states and streamline parsing. The kernel-equivalent pairs for this grammar are:
These pairs highlight the points where the parsing process might encounter similar parsing configurations with different look-ahead scenarios.
For any -state containing an item in a final state, the PDA performs a reduction when the current input character matches a symbol in the look-ahead set of that item. If belongs to the look-ahead set, the PDA makes a reduction; otherwise, it either shifts based on or halts if no valid transition exists.
Condition ELR (1)
The ELR(1) condition is a structural criterion that allows for deterministic parsing by ensuring that the Pushdown Automaton (PDA) can operate without ambiguity in its shift and reduction decisions. This condition is essential in controlling how the PDA executes under the guidance of the pilot graph, providing a clear path for each input without conflicts that would otherwise prevent determinism.
The ELR(1) condition consists of several parts that prevent conflicts, ensuring the determinism of the parsing process:
No Shift-Reduce Conflicts: In an -state, a shift-reduce conflict occurs if there is a reduction item (an item ready to reduce a substring to a non-terminal) that has look-ahead symbols overlapping with terminal symbols on outgoing arcs. This means that the PDA cannot decide whether to shift (i.e., move to the next input) or reduce (i.e., apply a production rule). To meet ELR(1), no -state should have any shift-reduce conflicts, allowing the PDA to make a clear choice between shifting and reducing.
No Reduce-Reduce Conflicts: A reduce-reduce conflict arises if an -state contains two or more reduction items with overlapping look-ahead symbols. In this scenario, the PDA would face ambiguity, being unable to decide which reduction rule to apply. To satisfy the ELR(1) condition, no -state should have more than one reduction item with overlapping look-ahead, ensuring that only one reduction is possible at any given point.
Definition
An -state is said to have multiple transitions if it contains at least two items and such that their respective transitions, and , are defined for the same symbol , whether is terminal or non-terminal.
Multiple transitions become problematic if these paths converge with conflicting look-aheads.
Convergent Multiple Transition: A convergent multiple transition occurs when the two paths and lead to the same next state, i.e., .
Conflict in Convergent Transitions: Even if the transitions converge to the same state, a conflict arises if the look-ahead sets overlap (i.e., ). This overlap means that two paths merge into one state, leaving the PDA unable to choose a single reduction.
Pilot Graph and PDA Control Mechanism
The PDA operates by scanning the input string and executing a series of shift and reduction moves, all while being controlled by the pilot graph, which provides the necessary guidance on state transitions.
Shift and Reduction Moves: As the PDA scans the input, it alternates between shift moves (to read and advance the input) and reduction moves (to apply grammar rules and reduce the parsed string according to the grammar’s productions).
Structure of -state Items in PDA: Each item in an -state becomes a 3-tuple by including a backward-directed pointer. This pointer is used to trace back and reconstruct different parsing paths generated in parallel. This structure supports the PDA in tracking its parsing states and enables it to maintain coherent parsing threads.
Decision-Making Using Look-Ahead Symbols: The PDA’s shift or reduction decision depends on the look-ahead information provided in the pilot graph. The pilot graph offers a prediction mechanism that helps the PDA decide on the next move based on anticipated input, preventing incorrect paths and ensuring efficient parsing.
Deterministic Parsing with ELR(1): If the condition ELR(1) is fully satisfied—meaning no shift-reduce or reduce-reduce conflicts, and no convergent multiple transitions with overlapping look-ahead—the PDA can operate deterministically. This determinism ensures that the PDA can make each shift or reduction move without ambiguity, following a unique parsing path for each input string, ultimately improving the parsing speed and efficiency by eliminating the need for backtracking or alternative parsing routes.
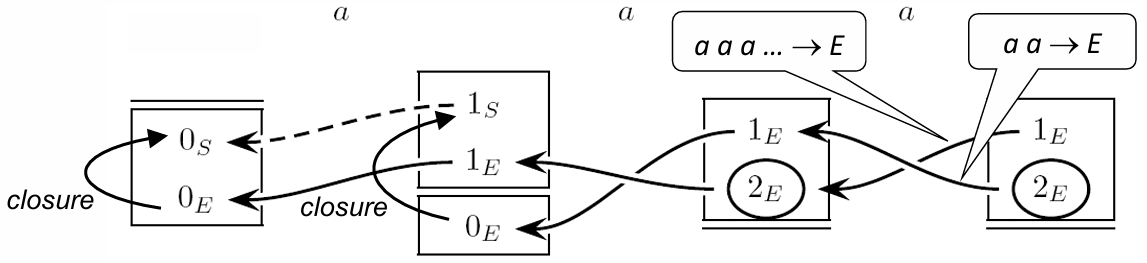
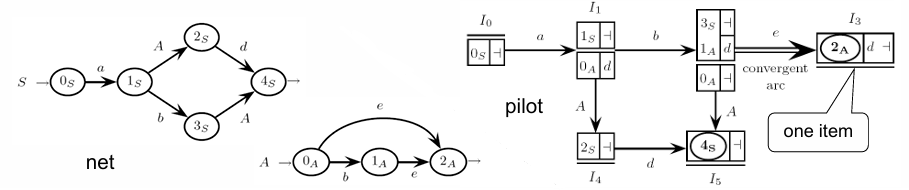
Example
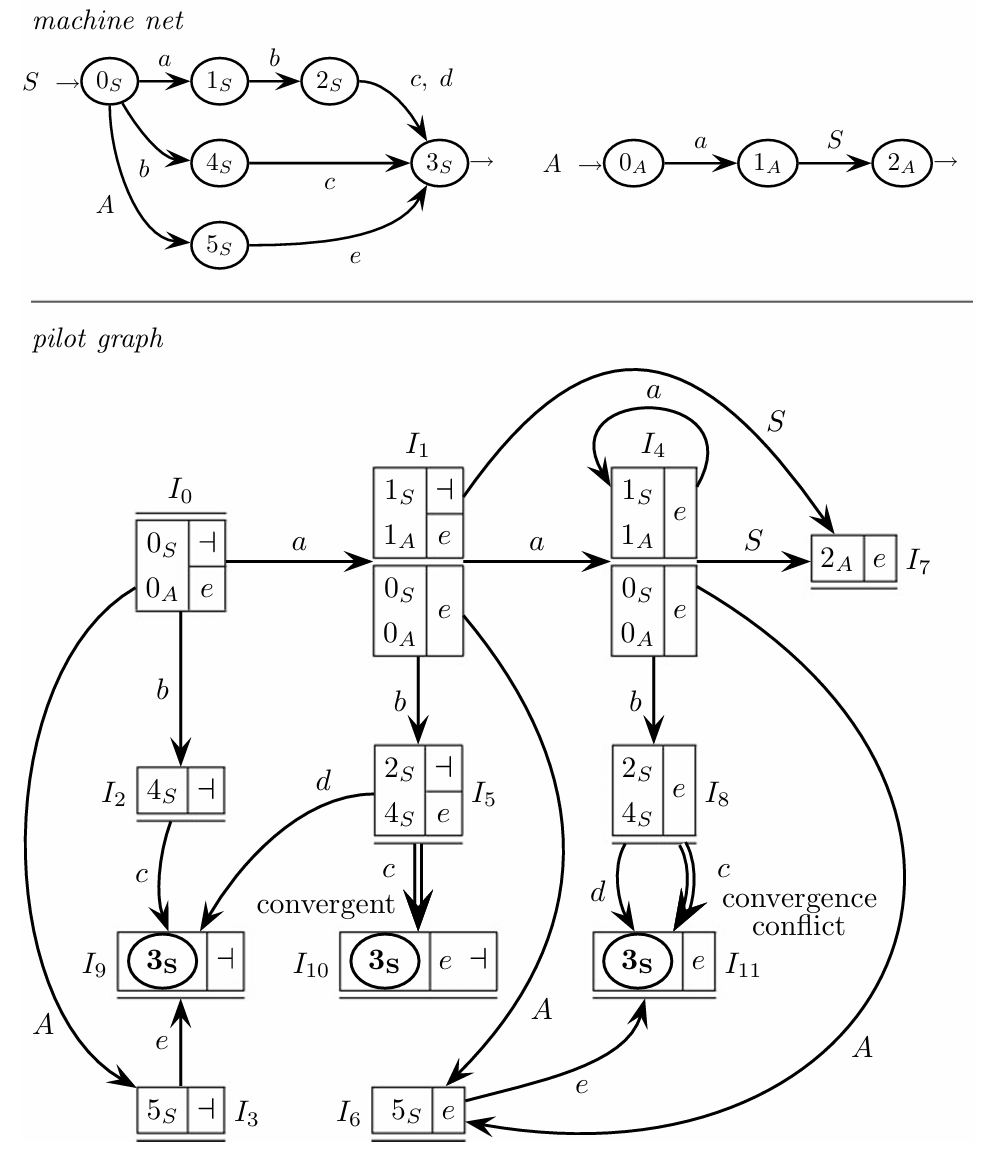
Consider the following grammar:
In the pilot graph, convergence happens when multiple paths from different states lead to the same macro-state. Convergence is either conflict-free or conflicting, depending on the look-ahead sets for these paths.
Conflict-Free Convergence: Macro-State
Macro-state satisfies the multiple-transition property (MTP) because it has two distinct transitions, and , both present in the machine net. In the pilot graph, these transitions are fused into a single arc , making the transition convergent. However, this convergence is conflict-free because the look-ahead sets associated with the paths are disjoint—meaning the look-ahead symbols do not overlap. This absence of overlapping look-ahead symbols allows the parser to make a unique decision based on the input without ambiguity.
Convergence Conflict: Macro-State
In contrast, -state also satisfies the MTP but introduces a convergence conflict. Here, the transition paths that converge to share the same look-ahead symbol, specifically . This overlap creates ambiguity because the parser cannot distinguish between the two paths based solely on the look-ahead symbol , resulting in a convergence conflict. Convergence conflicts violate the Extended Left-to-Right (ELR(1)) parsing condition, which requires that each state be deterministically resolved with a single look-ahead symbol.
Conflict Types in Parsing and ELR(1) Violation
Although this pilot graph does not exhibit shift-reduce or reduce-reduce conflicts, which are common issues in parsing, the presence of a convergence conflict is significant. The ELR(1) condition demands that no convergence conflicts exist, meaning each state transition must be unambiguously determined by a unique look-ahead symbol. Thus, the conflict at renders the pilot graph non-compliant with ELR(1) requirements.
Multiple Paths for String Generation
The pilot graph demonstrates that multiple net computations can produce the same string with identical look-ahead symbols. For instance, the string “a a b c” can be generated through two distinct paths that both lead to the same -state, with the same look-ahead, reinforcing the presence of convergence in the graph structure.
This observation underscores the complexity of ensuring unambiguous parsing in cases with convergent transitions, as managing look-ahead symbols becomes crucial to maintain determinism.
Determining the Reduction Handle Length with Pointers
In parsing with a Pushdown Automaton (PDA) controlled by a pilot graph, a critical detail is the length of the reduction handle that must be popped from the stack during a reduction. Unlike fixed-length handles in simpler parsing models, the length here is dynamic, as grammar rules may contain operators like or , allowing phrases of unbounded length. Consequently, the reduction handle length is determined dynamically at the moment of reduction by examining backward pointers stored within the PDA’s stack.
To find the reduction handle’s length, the PDA uses a series of backward-directed pointers, which link stack items back through the parsing path. This pointer chain enables the PDA to trace back to the start of the specific analysis thread that corresponds to the handle being reduced:
Starting Point of Threads: Each item in the PDA’s stack includes a pointer. An item with a pointer value ”⊥” denotes the beginning of a new analysis thread. All closure items are assigned the value ”⊥” by default, making them the root of new threads in the parsing structure.
Continuing Threads: For items that continue a previously started thread, the pointer value is represented by , where refers to the position of the target item from the top of the previous stack element. This structure allows the PDA to follow a chain of pointers backward, effectively “rewinding” the parsing path until it reaches the thread’s start point.
This mechanism ensures that, regardless of handle length, the PDA can dynamically determine where each reduction should start, adapting to phrases of variable or unbounded length.
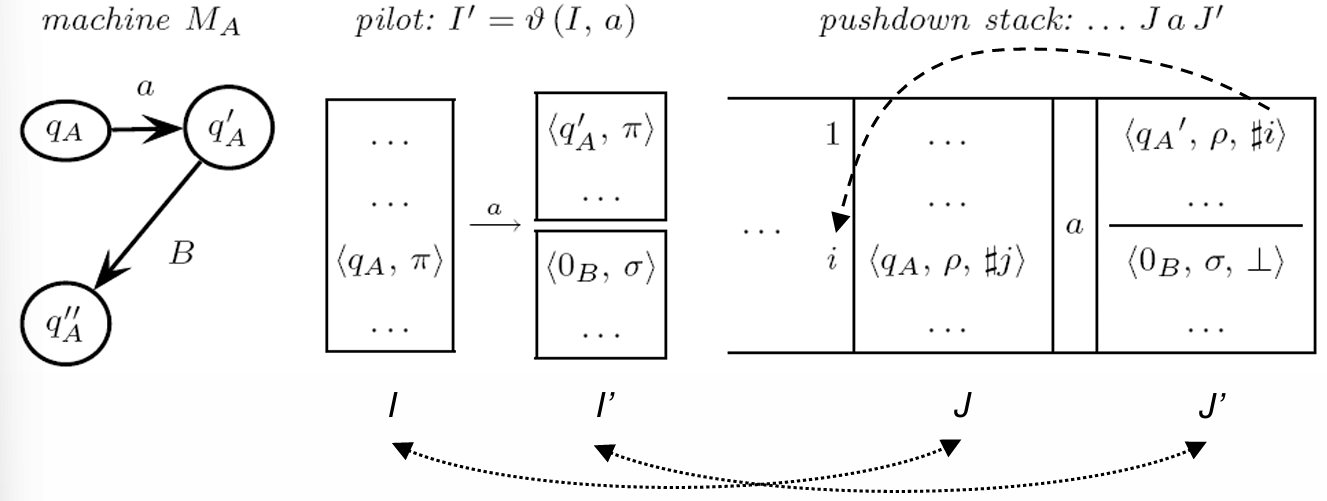
Shift Move Explained: Correspondence Across Stack, Pilot, and State Transitions
The shift move in a PDA involves three main levels of correspondence: the stack -states, the pilot -states, and the transitions between states. Each component plays a role in advancing the parsing process in a coordinated manner.
Stack and Pilot -states: When shifting, the stack -states (denoted as and ) reflect the corresponding pilot -states and but with added pointers. These pointers allow the stack items to track backward links, necessary for reduction operations.
Look-Ahead Differences in Stack and Pilot Items: Despite the correspondence between stack and pilot -states, the look-aheads (symbols used for making parsing decisions) in each may differ. For example, let’s denote the look-aheads in the stack as and , which could vary from those in the pilot items. This difference occurs because stack items may be derived by splitting a pilot item. Splitting happens in cases where transitions converge, meaning multiple paths merge into a single state. This convergence will lead to instances where the stack and pilot -states are structurally aligned but hold distinct look-ahead sets.
This layered correspondence allows the PDA to use the pilot graph’s structure as a guide for state transitions while managing the complex parsing paths and dependencies required by dynamic handles. The pilot graph thus provides a deterministic framework that ensures the PDA can follow accurate and conflict-free parsing paths even in cases of unbounded rule lengths, as long as ELR(1) conditions are met.
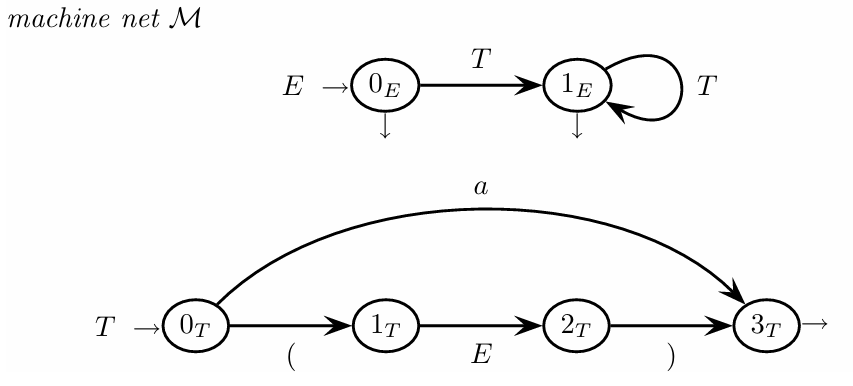
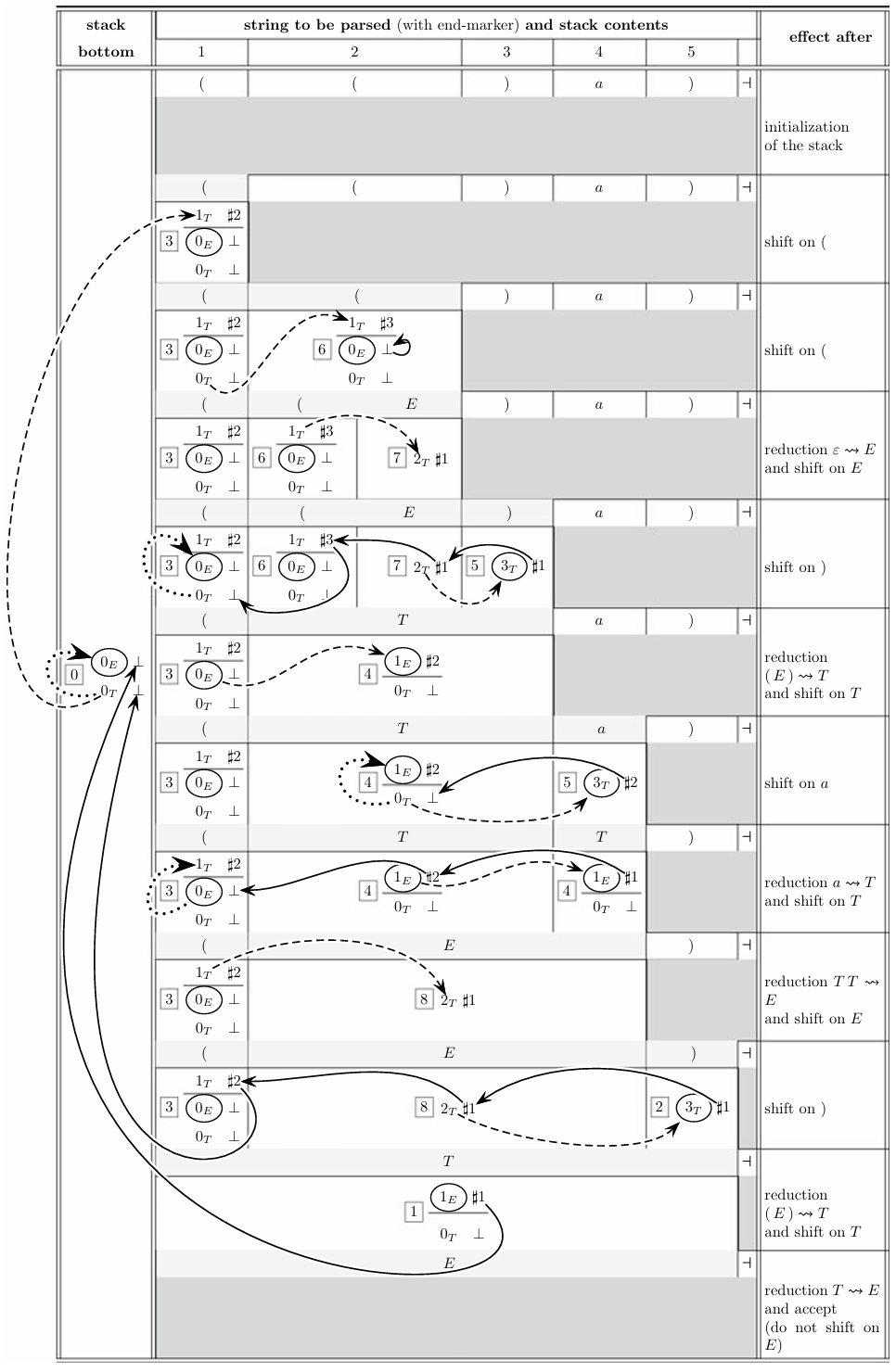
To parse the string ”(()a)” using the grammar rules and , we follow a step-by-step parser trace that shows the string’s progress through each parsing state. The grammar rule means that can expand into one or more symbols, while can be either a sequence in parentheses or simply the terminal symbol . This recursive structure allows both nested expressions and simple terminals to be parsed.
The parser trace contains two main parts: the input string and the stack. As the parser reads the input, it progressively replaces parts of the string with nonterminal symbols, pushing these onto the stack. Each stack entry holds an -state, reflecting the parser’s position and status, and the suffix of the input yet to be scanned is shown to the right. The stack thus retains a sequence of terminals and nonterminals, representing both what has been parsed and what remains.
Each stack element, labeled as , contains a 3-tuple for tracking references between elements. These references, known as the cid field, allow each stack element to link to earlier configurations, helping the parser manage rule compliance and initiate reductions when needed.
Each stack element includes a framed -state identifier, such as (represented as 0), showing the parser’s readiness for shift or reduction actions. Final reduction candidates are encircled, like , showing the resulting nonterminal after reductions.
Shift and Reduction Steps in Parsing
Shift operations, shown with dashed arrows, move symbols from the input to the stack. For example, the first terminal shift occurs on ‘(’, moving the parser from state to . A nonterminal shift occurs when the parser identifies a larger structure, such as , which leads to a move from to after an empty reduction .
Reductions, shown by solid backward arrows, link stack entries that match a production rule. For instance, when the expression is reduced, the parser follows pointers through elements 1, 1, and 3, forming a handle to reduce into . The bottom-most pointer then remains, allowing the parser to revert to a known state.
Some stack entries use dotted arrows to mark null reductions like , which modifies the stack without popping any elements. This null reduction simplifies the structure when the parser encounters a parenthesis.
Managing Grammar Symbols in Parsing
The parser retains symbols on the stack to ensure it can correctly apply reductions when needed. As it processes the input, previously scanned symbols remain in the stack, allowing the parser to determine the appropriate rule to apply, especially when multiple options are possible.
In this example, reductions follow this order:
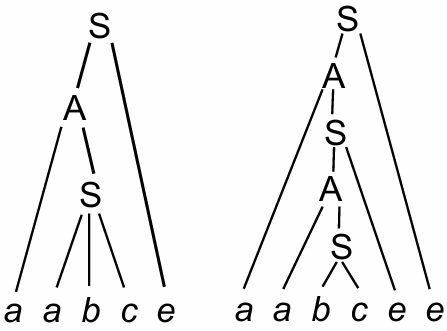
This sequence follows a rightmost derivation (deriving from the rightmost leaf of the syntax tree) but in reverse, as reductions are applied after parsing each input segment.
Convergent Arcs and Conflict-Free Parsing
In more complex grammars, look-ahead sets and convergent transitions introduce conflict-free arcs that the parser can manage. As shown stack elements linked by a cid chain can map to -states with a common machine state. These configurations may have a broader look-ahead set than the stack candidate’s look-ahead . If no convergent transitions are needed, and are identical, simplifying parsing. An ELR(1) grammar, which supports these arcs, provides an efficient approach for managing such transitions.
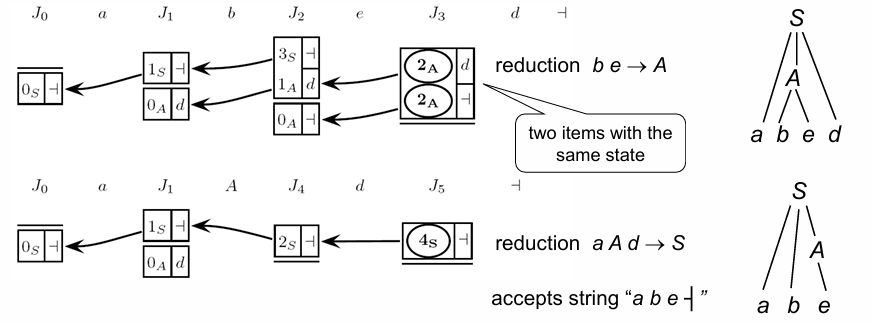
Example: Convergent Transitions in the Pilot Graph and PDA Stack
When the pilot graph exhibits a convergent transition, the PDA stack may include multiple items with the same state due to the merging paths.
For instance, in analyzing a string such as “a b e d ┤”, the analysis can lead to a stack state where multiple items share the same state, say, state . In such cases, each item points back to a prior item using specific markers, represented as arrows rather than traditional pointer notation , to indicate backward references. The look-ahead symbol becomes crucial here for determining the correct reduction, as it allows the PDA to select the proper reduction path despite having multiple items in the same state.
Recognizing Viable Prefixes
The purpose of the pilot graph is to control the PDA’s parsing path by recognizing partial strings or segments in the input, which are referred to as viable prefixes (or handle prefixes). These viable prefixes include all substrings derived from either scanning or reduction actions that appear in the stack, representing configurations that the parser can encounter while processing valid grammar constructs.
For example, consider the string ” “. As the PDA processes this string, it constructs viable prefixes at each parsing step, representing segments of the input that fit within the grammar’s rules. The viable prefixes for this example would be constructed as:
Each prefix is derived through shifts or reductions and reflects an intermediate parsing state that aligns with the grammar’s structure. These prefixes are essential for guiding the parsing process by indicating where reductions or shifts can legally occur in the stack.
Computational Complexity of PDA Analysis
When parsing a string with length , the computational complexity of the PDA operations can be analyzed in terms of the number of moves required for complete parsing.
Number of Stack Elements: The stack size never exceeds elements during the analysis.
PDA Moves: The PDA executes moves based on shifts and reductions. We define three types of moves:
: The number of terminal shifts, which equals because each terminal symbol corresponds to a shift move.
: The number of non-terminal shifts.
: The number of reductions. Each reduction is followed by a non-terminal shift, so .
Consequently, the total number of PDA moves is .
Reduction Analysis: Reductions can be categorized based on the number of terminal symbols involved:
Reductions with one or more terminals (e.g., , , or ) are bounded by , as each terminal in the input requires a corresponding reduction.
Reductions of type (null) or (copy) are linearly bounded by .
Reductions without any terminals (e.g., ) are also linearly bounded by .
These bounds ensure that reductions stay within manageable limits as parsing proceeds.
Time Complexity: The overall time complexity of parsing is linear, given by , where and are constants that depend on the grammar and implementation specifics.
Space Complexity: The space complexity is determined by the maximum stack size, which equals . Notably, space complexity is always upper-bounded by time complexity, ensuring that parsing can be conducted efficiently within the linear bounds.
Sample Grammars and Analysis with Pilot Graphs
Exploring grammars with pilot graphs helps illustrate how parsing processes work under different conditions, including grammars that support deterministic analysis and those that introduce complexity or non-determinism.
Grammar with Multiple Items in the -state Bases
This grammar generates the deterministic language , which allows for sequences where the number of s is at least as many as the number of s.
In this grammar, -states in the pilot graph can have two or more items, leading the PDA to carry out multiple analysis threads in parallel. However, the ELR(1) condition is satisfied, allowing the PDA to ultimately resolve all threads into a single, deterministic reduction. This configuration ensures that no parsing conflicts arise and that a unique reduction sequence is reached.
To understand this process, consider parsing sample strings like , , , , and . Each string will demonstrate the PDA’s handling of parallel paths and final reductions to recognize correct strings in this language.
For a more complex example like ” ┤,” all transitions (arcs) in the pilot graph are utilized, emphasizing the parallel parsing approach without violating determinism.
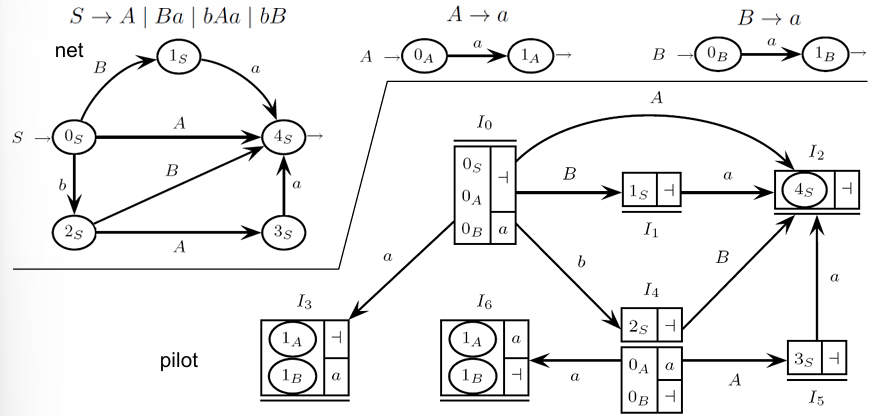
Grammar with Two Reductions in an -state but No Reduce-Reduce Conflict
This example involves a finite language, where the grammar is non-recursive and thus limited to a fixed set of strings:
Grammar rules:
Here, the pilot graph includes -states (specifically and ) that contain two reduction items. Although these -states might seem to violate the ELR(1) condition, they do not cause any conflicts. This is because these -states lack outgoing arcs, so there are no shift-reduce conflicts. Additionally, the reduction items in and have distinct look-aheads, which prevents any reduce-reduce conflicts. The PDA can therefore handle reductions in these states without ambiguity, supporting deterministic parsing despite having multiple reduction items.
Ambiguous Grammar Violating ELR(1)
An example of a grammar that inherently violates the ELR(1) condition is:
In this grammar, the language is ambiguous, meaning multiple parsing paths are possible for certain strings, leading to nondeterminism. In the pilot graph, -states such as , , and exhibit shift-reduce conflicts. For instance, the look-ahead includes the character in the reduction items and , as well as on an outgoing arc. This overlap prevents the PDA from deterministically choosing between shifting or reducing, as both operations could be valid based on the current look-ahead.
One way to resolve ambiguity is to redefine the grammar with rules that meet the ELR(1) condition. In this case, the language is regular and can be represented by a simplified grammar:
This modified grammar satisfies the ELR(1) condition by ensuring no conflicts in look-aheads and by structuring the rules to permit only a single valid parsing path.
Consider a grammar that generates palindromic strings:
In this grammar, the language strings are palindromic, meaning they are symmetrical around a center. However, the PDA cannot deterministically identify this center, leading to an intrinsic non-determinism. Specifically, in -state (and , though not explicitly shown), the PDA faces a shift-reduce conflict. After shifting a character , the PDA must decide whether to:
Reduce, if it has reached the center of the palindrome.
Continue shifting, if it is not yet at the center.
Unfortunately, without further information, the PDA cannot determine the center’s location, as it depends on the entire string’s structure. This makes the language inherently non-deterministic, and no ELR(1) grammar exists for it. Therefore, even with modifications, the PDA would still face ambiguities in parsing palindromic languages.
Implementing a PDA Using a Vectored Stack
In practical applications, implementing a Pushdown Automaton (PDA) with a vectored stack can be highly efficient and allows for direct access to stack elements beyond the top one. This approach can be applied in languages like C, where it’s possible to access specific stack elements without extensive backtracking. The vectored stack approach uses pointers within each stack item to streamline parsing and make the PDA more practical for real-world applications.
In a traditional PDA, the stack holds symbols that represent various parsing states and positions. However, in a vectored stack implementation, each stack item contains an additional integer pointer, which directly points to the index of the stack element marking the beginning of the analysis thread. This technique replaces the typical sequential backtracking in parsing with direct access to specific elements in the stack, thus optimizing the analysis process.
Integer Pointer for Direct Access:
The third field in each stack item is used as an integer pointer, directly linking back to the position in the stack where the current parsing thread began. This pointer allows the PDA to “jump” to the initial position of a thread without sequentially scanning each element backward.
Handling Base and Closure Items:
Closure Item: For closure items (those representing the start of a new thread), the current stack element index is recorded in place of the initial ”⊥” value. This marks the beginning of a new parsing path.
Base Item: For base items, the index of the preceding stack item is copied, allowing a clear link back through the parsing history. This linking mechanism means that the PDA no longer needs to scan backward through all previous elements to locate the beginning of a handle.
Infinite Stack Alphabet:
Due to the pointers, the stack alphabet becomes effectively infinite since each stack item can now contain unique values representing specific positions in the parsing process. This modification moves the PDA beyond the traditional finite stack alphabet model but is manageable within typical analyzers and has minimal impact on computational costs.
This vectored stack design is computationally efficient because it reduces the need for repetitive scans during reductions. Instead, the PDA can immediately access any element in the stack via direct pointers, which speeds up the analysis process. In practice, this approach parallels the efficiency found in the Earley Algorithm, which also optimizes parsing through direct lookups and structured parsing states.
To illustrate, let’s consider the vectored stack PDA parsing the string ”(( ) a )“. The PDA processes each symbol by shifting it onto the stack or reducing based on the grammar rules. Throughout this trace:
Each element in the stack contains a pointer to its original position, so upon reaching a reduction, the PDA doesn’t need to sequentially trace back but rather can “jump” to the relevant stack index directly.
The vectored stack’s design thus supports efficient handling of nested structures and look-ahead parsing, ensuring that reductions are completed with minimal computational overhead.
This implementation approach is highly suitable for complex parsing tasks, where performance and optimization are critical, as it avoids the limitations of traditional PDA backtracking.