Information Retrieval
Definition
Information Retrieval is the task of finding content, which could be documents, images, videos, etc., that is useful to user’s information needs.
When we have information needs, we identify the keywords from the query and search for documents that contain those keywords. We then prioritize and rank those documents based on their relevance to the query.
Typically, adults have a vocabulary range of 20,000 to 30,000 words. However, web documents are usually much shorter, with less than a thousand words. This means that the vocabulary used in each document is a subset of the vocabulary used in the entire collection. As long as the vocabulary is evenly distributed across different documents, text retrieval can be efficiently performed through vocabulary matching. To enable this, fast indexes containing selected keywords are necessary.
In case of no document contains all the query keywords, or many documents contain all of them, we need to perform some specific task:
-
Assign a score to the importance of different keywords, because some of them are more often discriminative than others; so we need to weight them up. This is done by Term Weighting techniques
-
Expand documents representation to include more information, such as include Anchor Text from incoming links, or metadata (data very important in Web Search). This is done by Index Structures techniques
-
Try to train a Machine Learning model to predict relevance of documents to a query. The Machine Learning solution for this problem consists of two components:
- The Features used are the concatenation of the query and document, represented as
<query_terms, document_content>. - The Prediction involves calculating the probability that the user finds the document relevant to the query.
- The Features used are the concatenation of the query and document, represented as
A simple linear model cannot be used in this case because it does not consider the interaction between query terms and document content. Instead, a more complex model, such as a quadratic model, is needed to capture all the pairwise interactions between query and document terms. However, this solution poses a challenge due to the large number of parameters required. For a vocabulary of <query, document, relevance> would be necessary.
Term Weighting
All terms have meaning, but certain terms are more informative than others, making them more valuable for identifying relevant content. When searching for documents, it is important to prioritize the informative terms and downplay the less useful ones.
Example
For example, imagine searching for the name of a unique frog you encountered in the forest. You enter the query “giant” + “tree” + “frogs”, but no Wikipedia document contains all three keywords. So, you try removing one keyword from the query:
- Many documents contain “giant” and “tree”.
- A few documents contain “giant” and “frogs”.
- Only a handful of documents contain “tree” and “frogs”.
In general, the set of documents containing the fewest query terms will be the most specific and relevant to the topic.
There are many heuristics for term documents based on query terms they contain, such as:
IDF (Inverse Document Frequency)
To rank documents for a query, one approach is to perform searches over all possible subsets of query terms and rank the returned documents based on the size of the returned sets, with the smallest set being considered the most relevant. However, this method can result in a significant amount of wasted computation, as many subsets may not return any results.
Idea
A more efficient approach is to estimate the likelihood of a random document containing all the query terms by multiplying the number of documents in the collection, denoted as
, by the probability of the query terms appearing in a random document, denoted as .
Our aim is to rank documents, so we can ignore

TIP
Assuming that terms are independent of one another, the probability that a randomly chosen document would contain a set of keywords
is:
where
is the document frequency of the term in the collection, this means that it’s the number of documents in the corpus containing the term ; and is the total number of documents in the collection.
We wish to rank document by how unlikely they are, so score by the inverse of the probability of seeing the query terms in the document:
Definition
The Inverse Document Frequency (IDF) simply weights each term by the negative-log probability of finding term in random document:
The formula commonly used in Information Theory is
There are alternative variations of the Inverse Document Frequency, including one that relies on the log-odds of the term appearing in the document instead of the negative log-likelihood:
which results in the following document score:
Small amount of smoothing has been applied (
There is little distinction between the negative-log-likelihood and log-odds formulations when dealing with terms that are very common, with a document frequency (
) close to or greater than half of the total number of documents ( ). In such cases, the log-odds formulation yields negative values, while the negative-log-likelihood formulation yields positive values. In this scenario, the negative-log-likelihood is more intuitive as it ranks the document as more relevant when the term is more common.
TF-IDF (Term Frequency - Inverse Document Frequency)
IDF assigns weights to vocabulary terms, but a document contains more information than just its vocabulary. In some cases, a document may include the same query term multiple times, indicating a higher likelihood of relevance to the query. This additional information should be taken into account when evaluating document relevance. Simplest option to include this term count information is to directly weight score by it:
where
we estimate the chance that the next token is
where
Computing the product over all the query terms and taking logarithm to produce additive score, we get
Replacing the collection frequency (
The TF-IDF score, commonly employed to assign weights to query terms, demonstrates good performance in practice. However, it assumes a linear relationship between term frequency and document score, which is not always the case. Additionally, the score is not additive across terms and lacks normalization, resulting in longer documents receiving higher scores compared to shorter ones.
Length Normalization - Cosine similarity
To account for the length of the document, we need to normalize it. This is because larger documents tend to have a larger vocabulary and are more likely to contain the query terms. However, it doesn’t necessarily mean that they are more useful to the searcher. Therefore, shorter documents with the same term count should be prioritized.
To normalize the length of the document, we can divide the score by the length of the document (the most common normalization uses
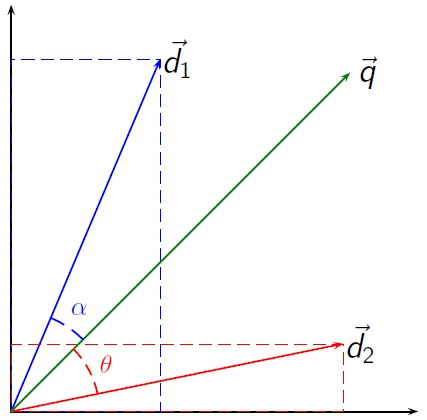
Similarly between query and document computed based on angle between vectors, actually cosine of angle is used, since it gives similarity values in range
where
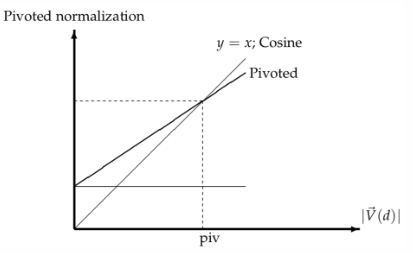
Pivoted Length Normalization
There have been many studies over the years into other types of normalization, such as Pivoted Length Normalization (PLN).
Definition
Pivoted Length Normalization (PLN) is a parameterized form of normalization developed specifically for retrieval. The basic idea behind this technique is that generally longer documents do contain more information than shorter ones, so could be more useful to the searcher.
However, the normalization process loses all the length information, so instead parameterize
where
BM25
The Okapi BM25 ranking formula is derived from pivoted length normalization, which has been widely used in information retrieval. The formula is as follows:
In this formula,
BM stands for Best Matching, and 25 was literally the 25th attempt to improve the formula. BM25 is the GOTO (Generalized Okapi Text Object) method for term-based text retrieval. The formula stood test of time, with lots of competition along the way.
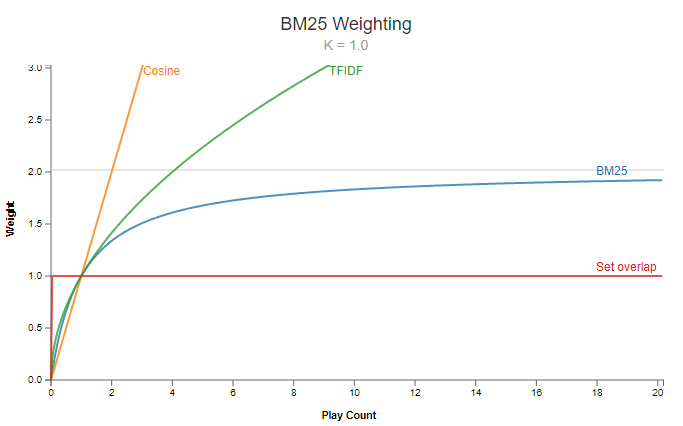
Properties of BM25:
- The importance of a term asymptotes to a maximum value, so the score does not go to infinity regardless of how many times the term appears in the document.
- The parameters
and control the dependence on the document length. The default values for these parameters are and . However, they are typically tuned to improve performance on a validation set.
Index Structures
Search engines are designed to respond quickly because time is crucial on the internet, where attention is valuable. To achieve this, search engines utilize index structures, which are data structures that enable efficient retrieval of documents containing specific terms. By using an index structure, search engines can quickly locate and present relevant information to users.
The primary goal of index structures is to optimize search speed. These structures allow search engines to perform fast lookups, ensuring that search results are delivered within fractions of a second. By organizing and storing data in a way that facilitates rapid retrieval, search engines can provide users with timely and accurate search results, enhancing the overall user experience.
(Inverted) Index
Definition
An Inverted Index is a data structure that maps terms to the documents in which they appear. It is used by search engines to quickly locate documents containing specific terms.
In search engines, inverted indices serve as the foundation. They consist of Posting Lists, which are straightforward mappings from TermIDs to DocumentIDs. The design of inverted indices prioritizes speed, achieved through compression algorithms that reduce memory usage, efficient decompression, and block-based organization for easy access. These indices also consider text statistics to optimize performance.
Computing the retrieval function requires identifying the documents that contain a specific set of terms. The posting list entries are sorted in descending order based on the importance of the documents (determined by the term count). This sorting enables early termination of the computation process:
- Calculate score bounds for document calculation.
- Discard lower-ranked documents as quickly as possible.
- Utilize index pruning techniques to eliminate documents that would never be retrieved for a particular query.
Positional Index
Proximity plays a crucial role in determining the relevance of terms within a document to a query. This is especially evident in cases like Named Entities, where the order of terms in bigrams/trigrams is significant.
Indexing systems often store the positions of terms within a document, enabling the computation of term proximity. The position of a term can provide valuable insights, such as the words at the beginning of a webpage or the words in a document’s title or anchor text. By considering the positions of terms within a document, search engines can better understand the context and relevance of the terms to the query.
To facilitate more complex queries, statistically significant bigrams/trigrams identified using pointwise mutual information (PMI) are often indexed separately. This allows for queries that involve finding documents where term
Crawlers
To build an index, search engines traverse the web by following hyperlinks and identifying pages to include. In the past, there was extensive research on efficient web crawling, which was a competitive aspect among search engines. However, nowadays, the focus is on prioritizing URLs effectively and leveraging abundant and affordable computing power.
In the realm of the web, indexes undergo constant updates, and there are numerous parameters that can be configured and learned. These parameters include determining the frequency of revisiting a website and deciding which links should be given priority and which should be disregarded.
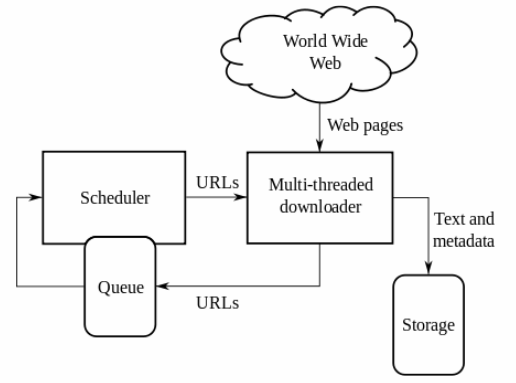
Web scale crawlers must be able to handle various types of content, including dynamically generated pages. In the past, Google had more indexed Amazon pages than Amazon itself because Amazon generated pages on-demand while Google stored them statically in memory. To prevent indexing duplicate pages, content-based duplicate page detection is employed. To avoid crawling the same page multiple times, a distributed crawler architecture with a centralized URL list and distributed workers is utilized.
Crawlers must adhere to the robots.txt file, which is a file located in the root directory of a website. This file specifies the pages that the crawler is allowed or not allowed to access. The robots.txt file follows the standard guidelines for robot exclusion and is a plain text file.
# robots.txt for http://www.wikipedia.org/ and friends
#
# Please note: There are a lot of pages on this site, and there are
# some misbehaved spiders out there that go _way_ too fast. If you're
# irresponsible, your access to the site may be blocked.
#
# Observed spamming large amounts of https://en.wikipedia.org/?curid=NNNNNN
# and ignoring 429 ratelimit responses, claims to respect robots:
# http://mj12bot.com/
User-agent: MJ12bot
Disallow: /
# advertising-related bots:
User-agent: Mediapartners-Google*
Disallow: /
# Wikipedia work bots:
User-agent: IsraBot
Disallow:
User-agent: Orthogaffe
Disallow:
# Crawlers that are kind enough to obey, but which we'd rather not have
# unless they're feeding search engines.
User-agent: UbiCrawler
Disallow: /
User-agent: DOC
Disallow: /
User-agent: Zao
Disallow: /
# Some bots are known to be trouble, particularly those designed to copy
# entire sites. Please obey robots.txt.
User-agent: sitecheck.internetseer.com
Disallow: /
User-agent: Zealbot
Disallow: /
User-agent: MSIECrawler
Disallow: /
User-agent: SiteSnagger
Disallow: /
User-agent: WebStripper
Disallow: /
User-agent: WebCopier
Disallow: /
User-agent: Fetch
Disallow: /
User-agent: Offline Explorer
Disallow: /
User-agent: Teleport
Disallow: /
User-agent: TeleportPro
Disallow: /
User-agent: WebZIP
Disallow: /
User-agent: linko
Disallow: /
User-agent: HTTrack
Disallow: /
User-agent: Microsoft.URL.Control
Disallow: /
User-agent: Xenu
Disallow: /
User-agent: larbin
Disallow: /
User-agent: libwww
Disallow: /
User-agent: ZyBORG
Disallow: /
User-agent: Download Ninja
Disallow: /
# Misbehaving: requests much too fast:
User-agent: fast
Disallow: /
#
# Sorry, wget in its recursive mode is a frequent problem.
# Please read the man page and use it properly; there is a
# --wait option you can use to set the delay between hits,
# for instance.
#
User-agent: wget
Disallow: /
#
# The 'grub' distributed client has been *very* poorly behaved.
#
User-agent: grub-client
Disallow: /
#
# Doesn't follow robots.txt anyway, but...
#
User-agent: k2spider
Disallow: /
#
# Hits many times per second, not acceptable
# http://www.nameprotect.com/botinfo.html
User-agent: NPBot
Disallow: /
# A capture bot, downloads gazillions of pages with no public benefit
# http://www.webreaper.net/
User-agent: WebReaper
Disallow: /
#
# Friendly, low-speed bots are welcome viewing article pages, but not
# dynamically-generated pages please.
#
# Inktomi's "Slurp" can read a minimum delay between hits; if your
# bot supports such a thing using the 'Crawl-delay' or another
# instruction, please let us know.
#
# There is a special exception for API mobileview to allow dynamic
# mobile web & app views to load section content.
# These views aren't HTTP-cached but use parser cache aggressively
# and don't expose special: pages etc.
#
# Another exception is for REST API documentation, located at
# /api/rest_v1/?doc.
#
User-agent: *
Allow: /w/api.php?action=mobileview&
Allow: /w/load.php?
Allow: /api/rest_v1/?doc
Disallow: /w/
Disallow: /api/
Disallow: /trap/
Disallow: /wiki/Special:
...The Dark Web is an important aspect to mention as it is a part of the internet that is not indexed by search engines. It operates through the TOR (The Onion Router) gateway, which is a network of servers that enables anonymous browsing and access to a wide range of content. Crawling the Dark Web poses challenges due to the absence of DNS linking URLs to IP addresses behind TOR and the lack of indexing by search engines.
Learning to Rank
We also need to rank various items in different systems:
- candidate documents in a retrieval system
- candidate products in a recommendation system
- candidate answers in a question answering system
- candidate translations in a machine translation system
- candidate transcriptions in a speech-to-text system
In all the cases, we want to evaluate the system in terms of ranking produced. Each ranking task comes with many indicative features. For a web search, relevance indicators include:
- multiple retrieval functions like BM25, embeddings-based, BERT…
- different document parts/views like title, anchor-text, bookmarks…
- query-independent features like PageRank, HITS, spam scores…
- personalized information like user click history
- context features like location, time, previous queries…
Search engines, such as Google, utilize a multitude of signals to determine rankings. These signals include incoming links, page content (keywords, length, comprehensiveness), technical quality (load speed, mobile version), user interactions (click-through rate, bounce rate), and social signals (shares, likes, tweets). With such diverse indicators of relevance, search engines employ advanced techniques to effectively combine these signals and deliver accurate rankings.
Rank learning provides an automated and coherent method: for combining diverse signals into a single retrieval score while optimizing a measure of user care about, like NDCG (Normalized Discounted Cumulative Gain) and ERR (Expected Reciprocal Rank).
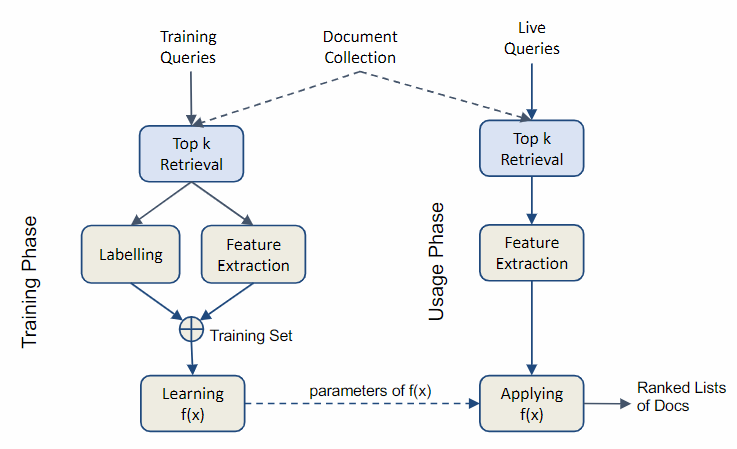
Generating a dataset
To start learning to rank, we need a dataset where performing the ranking. In order to generate a dataset, we need to:
- Begin with a query and a set of documents.
- Generate an initial ranking using a keyword-based ranking function.
- Truncate the ranking at a value of
to create a candidate list for re-ranking. - Calculate the feature values for each candidate document. These features include BM25 scores (for the entire page and for the document only), anchor text relevance, PageRank, etc.
- Normalize the feature values at the query level. This is typically done using min-max scaling to ensure comparability across different queries.
- Provide ground-truth relevance labels for each query-document pair in the ranking during the training phase. These labels are usually binary (relevant or not relevant) but can also be graded (e.g., 1, 2, 3, 4, 5). Human annotators are often used to judge the relevance of the document to the query.
- Repeat this process for a large number of queries and documents.
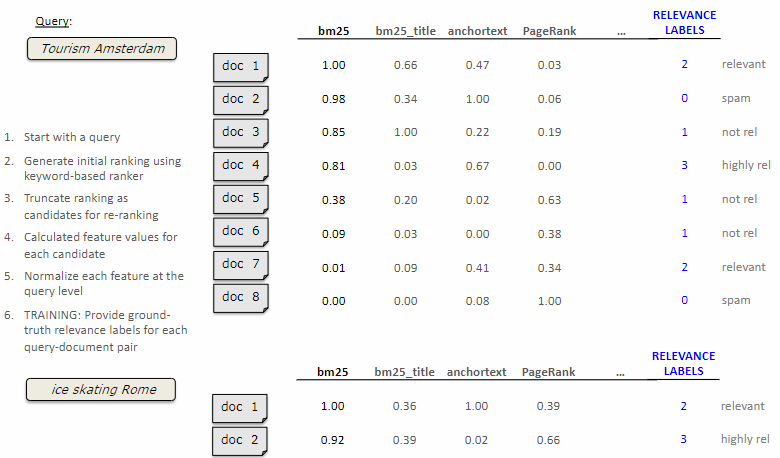
The collection of relevance labels can be a costly and time-consuming process. Search engines often rely on human annotators, such as Google’s Quality Raters, to evaluate the relevance of search results. However, not all organizations have the resources to employ such annotators. As an alternative, some organizations (like Wikipedia) gather user feedback and judgments by tracking their interactions with the search results.
Evaluating search results
There are a lot of different measures for evaluating retrieval results. Traditional measures include:
- precision at depth
(P@k): the proportion of relevant documents in the top documents: - recall at depth
(R@k): the proportion of relevant documents in the top documents: - F-measures: the harmonic mean of precision and recall:
is usually the most important measure for retrieval.
Frequently used evaluation functions:
-
MAP (Mean Average Precision): it’s the average over queries of “average precision” (AP), which is the average of P@k values over all rank positions containing relevant documents. The average precision estimates the area under the precision-recall curve
where
is the precision at rank , and is the relevance of the document at rank . -
NDCG@k (Normalized Discounted Cumulative Gain): it’s the measure to care about by default because is more faithful to user experience by discounting lower ranked documents. It’s normalized at query level, so it’s comparable across different queries.
where
is the set of queries, is the rank position, and is the relevance of the document at rank .
Other common evaluation functions:
- ERR@k (Expected Reciprocal Rank): especially useful for task with only one correct answer
- ER@k (Expected Rank): the expected rank of the first relevant document. If know how frequently user bother to read second search result, we can use ERR to evaluate the ranking. Use that probability to weight succesful retrieval at that position. Is similar to NDCG, but with empirical probabilities for discounting the importance of lower ranked documents.
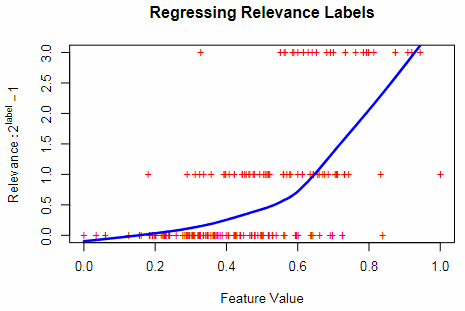
Treat rank learning as a regression problem
We can approach rank learning as a regression problem, aiming to predict the relevance label using feature values. Standard regression techniques such as linear regression, logistic regression, or SVM can be employed for this purpose.
During the learning process, we can use a loss function that can be defined in three ways:
-
pointwise (like MSE - Mean Squared Error): the loss is calculated for each query-document pair, and the model is trained to minimize the loss for each pair
where is the predicted score, is the feature vector, is the relevance label, and is the number of queries. -
pairwise (like the number of incorrectly ordered pairs): the loss is calculated for each pair of documents in the ranking, and the model is trained to minimize the number of incorrectly ordered pairs
where are the predicted score and are the relevance label. -
listwise (like NDCG): the loss is calculated for the entire ranking, and the model is trained to maximize the NDCG
where
are the predicted score and are the relevance label.
LambdaMART
Definition
LambdaMART is a learning-to-rank algorithm that uses boosted regression trees to optimize the ranking of documents for a given query. It is based on the LambdaMART algorithm, which combines the LambdaRank algorithm with MART.
The name LambdaMART is derived from “Lambda,” which represents an approximation of the loss gradient, and “MART,” which stands for Multiple Additive Regression Trees. This approach has demonstrated excellent performance in real-world scenarios.
For IR (Information Retrieval) ranking problems we would like to set the loss function to maximize the evaluation measure of choice.
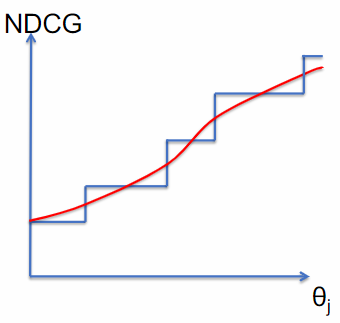
The problem of this approach is that the ranking loss function are non-differentiable (or flat) with the respect to parameters of retrieval function. This means that we can’t use gradient-based optimization techniques to optimize the ranking function.
Taking, for example, NDGC: this is not a function of scores assigned to documents, but a function of sorted order induced to them; so, if parameter values change only by a small amount, scores for document will also move a little and ranking of the document likely won’t change at all.
Example
Consider a scenario where you have a ranking of 5 documents for a query. The documents are initially ordered based on their predicted scores, and only four of them are relevant to the query. Now, imagine that you modify the parameters of the ranking function in such a way that the score for document 4 increases, while the scores for the other documents remain unchanged.
Initially, there is no change in the order of the documents, and consequently, there is no change in the evaluation measure. However, as the score for document 4 surpasses the score for document 3, the order of the documents will change. This change in order will then lead to a change in the evaluation measure, but the change will be sudden and discontinuous. This poses a challenge when using gradient-based optimization techniques to optimize the ranking function.
This phenomenon results in a loss function that is piecewise-flat, lacking gradient information to guide the learner in updating the parameters. LambdaMART offers a solution to this problem.
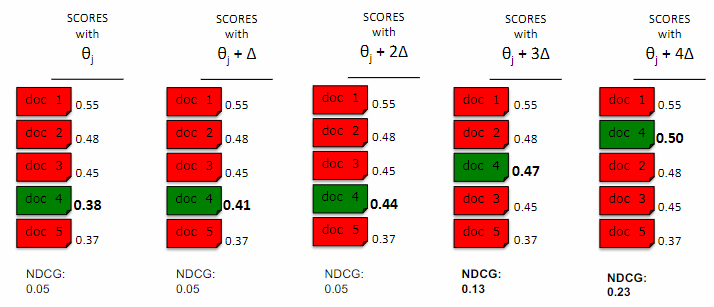
LambdaMART focuses on the ranking of documents 3 and 4. The model’s scores are approximate representations of the document quality. The actual quality of the document may be higher or lower than the predicted score. The likelihood of a swap in document order can be estimated using a logistic curve, which considers the difference between the scores of the two documents.
where
If two documents did swap, would effect the evaluation measure for ranking, increasing or decreasing it by
So, we have the pairwise gradient
and a new regression tree is fit to these values and added to the ansemble