In language processing, as what happen in speaking/writing, the word order is extremely important for interpreting the meaning of the sentence. And meaning is important for classifying the sentence. Negation is a good example of how the word order is important. For example, in the sentence “I do not like this movie”, the word “not” is negating the word “like”. If we change the order of the words, the meaning of the sentence changes. For example, “I like not this movie” is not the same as the previous sentence.
While
-grams can indeed be used to capture word order, we can never quite make them long enough to capture all the information we need.
Sequence labelling
Definition
Sequence classification task takes as input an ordered sequence of tokens
, and gives as output a prediction for the entire sequence.
In contrast, sequence labelling tasks take as input an ordered sequence of tokens
, and gives as output a prediction for each token in the sequence.
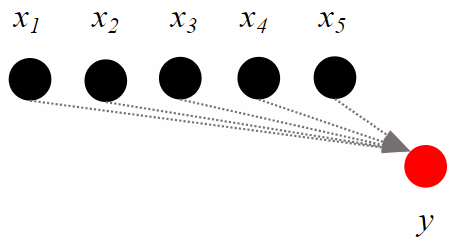
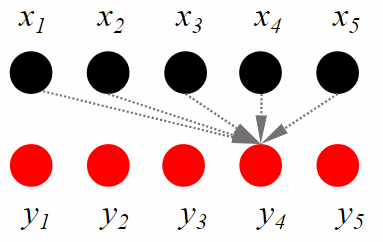
The prediction for
Traditional methods used for sequence labelling tasks include Hidden Markov Models (HMMs) and Conditional Random Fields (CRFs).
-
Hidden Markov Models (HMMs) can be seen as a variation of Naive Bayes applied to sequences. They consist of hidden states and observed words. The states are not directly observable, while the words are. HMMs assume that the states follow a Markovian property, meaning that the probability of transitioning to a new state depends only on the current state. Additionally, the model assumes that the probability of observing a word depends solely on the current state. Training HMMs involves estimating the transition probabilities and the emission probabilities.
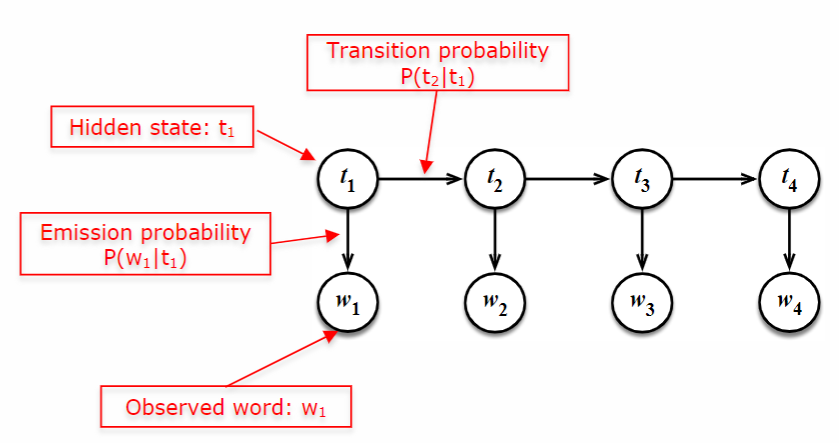
-
Conditional Random Fields (CRFs) can be thought of as a variant of logistic regression applied to sequences. Instead of using transition and emission probabilities, CRFs utilize undirected potentials, denoted as
and .
Recently, deep learning models have been used for sequence labelling tasks. These models include Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Gated Recurrent Units (GRUs). These models are able to capture long-range dependencies in the sequence.
Recurrent Neural Networks (RNNs)
Word embeddings allow us to represent words in a semantic space, but we still need to aggregate information over long contexts.
RNNs provide a general way to accumulate information by combining context from previous words with the embeddings of the current word. The RNN is a simply model which:
- takes two vectors as inputs:
- produces two vectors as outputs:
They can be used to process arbitrary long input contexts, like encoding a sequence of text to a single embedding.
Long Short-Term Memory (LSTM)
LSTMs are a type of RNN that excel at capturing long-range dependencies and contextual information. They achieve this through the use of gating mechanisms, such as the ability to retain or forget information at each timestep.

One of the strengths of LSTMs is their ability to handle nested contexts, which is particularly valuable in NLP. They can effectively handle complex sentence structures with pronouns, changing subject genders, and switching between different sentence and negation contexts.
There are many applications for LSTMs, like:
- part-of-speech tagging
- named entity recognition
- entity linkage
- relation extraction
- dependency parsing
- co-reference resolution
Part-of-Speech Tagging (POS)
Definition
A word class, or part of speech (POS), is a category of words with similar grammatical properties.
In the 1st century BCE, Dionysius Thrax, a Greek grammarian, introduced the concept of word classes. He identified eight parts of speech: noun, pronoun, verb, adverb, participle, conjunction, preposition, and interjection. Modern grammar categorizes word classes into two major groups:
- Open classes: nouns, adjectives, adverbs
- Closed classes: pronouns, prepositions, conjunctions, determiners, auxiliary verbs, particles, interjections
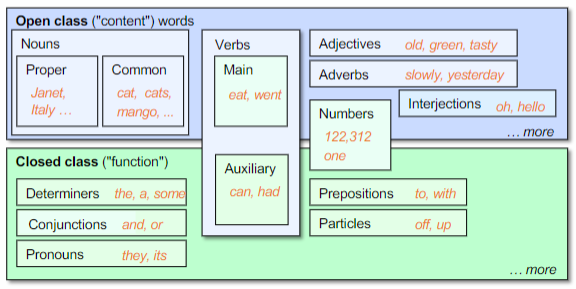
Definition
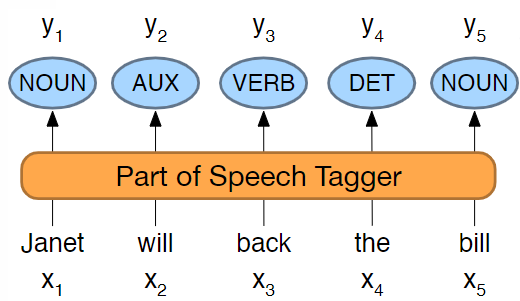
Part-of-speech tagging is the process of assigning to each token in a sequence a part-of-speech (POS) tag, which indicates the word class of the token.
For example, the sentence “I like this movie” would be tagged as “PRON VERB DET NOUN”.
Part-of-speech labels serve various purposes, including:
- Enhancing feature development for tasks like authorship attribution, especially when limited training data is available.
- Reducing ambiguity in bag-of-words representations by appending a POS tag to disambiguate terms with multiple meanings depending on the context.
- Serving as an initial step for other NLP tasks and linguistic analysis, such as syntactic parsing, text-to-speech conversion, and studying linguistic changes like the creation of new words or shifts in meaning.
| Class | Tag | Description | Example |
|---|---|---|---|
| Open Class | ADJ | Adjective: noun modifiers describing properties | red, young, awesome |
| ADV | Adverb: verb modifiers of time, place, manner | very, slowly, home, yesterday | |
| NOUN | Words for persons, places, things, etc. | algorithm, cat, mango, beauty | |
| VERB | Words for actions and processes | draw, provide, go | |
| PROPN | Proper noun: name of a person, organization, place, etc. | Regina, IBM, Colorado | |
| INTJ | Interjection: exclamation, greeting, yes/no response, etc. | oh, um, yes, hello | |
| Closed class | ADP | Adposition (Preposition/Postposition): marks a noun’s spacial, temporal, or other relation | in, on, by, under |
| AUX | Auxiliary: helping verb marking tense, aspect, mood, etc. | can, may, should, are | |
| CCONJ | Coordinating Conjunction: joins two phrases/clauses | and, or, but | |
| DET | Determiner: marks noun phrase properties | a, an, the, this | |
| NUM | Numeral: one, two, first, second | one, two, first, second | |
| PART | Particle: a preposition-like form used together with a verb | up, down, on, off, in, out, at, by | |
| PRON | Pronoun: a shorthand for referring to an entity or event | she, who, I, others | |
| SCONJ | Subordinating Conjunction: joins a main clause with a subordinate clause | that, which | |
| Other | PUNCT | Punctuation | ; . ( ) |
| SYM | Symbols or emoji | $, % | |
| X | Other | asdf, qwfg |
Approximately 85% of English vocabulary terms are clear in meaning, but the remaining 15% are ambiguous and quite common. This means that around 60% of the tokens in English text are ambiguous. The accuracy of part-of-speech (POS) tagging for English is typically around 97-98%. This accuracy has improved in recent years with the use of techniques such as Hidden Markov Models (HMMs), Conditional Random Fields (CRFs), and BERT models. The accuracy of POS tagging is comparable to human accuracy.
POS tagging relies on various sources of evidence to determine the correct POS tag for a word. These sources include the probability of the word given the tag (e.g., “will” is usually tagged as an auxiliary verb), the context provided by neighboring words (e.g., the presence of the word “the” suggests that the next word is unlikely to be a verb), and the morphological form of the word.
Example
Consider the following example sentence: “Janet will back the bill.” When determining the part-of-speech (POS) tags for each word, several sources of evidence can be used.
- Prior probabilities of word/tag combinations can provide valuable information.
- The identity of neighboring words can also be helpful.
- Additionally, the morphology and word shape of a word can provide clues. For instance, prefixes like “un-” often indicate an adjective, while suffixes like “-ly” can indicate an adverb. Capitalization, such as in the name “Janet,” can indicate a proper noun.
Named Entity Recognition (NER)

Definition
Named entity recognition is the task of identifying entities that are mentioned in a text and can be treated as a sequence labelling task. This is often the first step in extracting knowledge from text.
A named entity is a real-world object that is assigned a name. Named entities can be classified into different categories, such as: PER (person), ORG (organization), LOC (location), GPE (geo-political entity)… Often, multi-word phrases are considered named entities, such as “New York”. This operation is also extended to things that are not named entities, like dates, times, and numerical values.
The difference between GPE and LOC is that GPE is a country, city, or state, while LOC is a mountain, river, or lake.
The goal of NER is to identify the boundaries of the named entities and to classify them into the correct category.
NER is traditionally performed for:
- sentiment analysis
- information extraction
- question answering
- de-identification of personal information
It can be challenging to accurately identify named entities due to segmentation errors. For example, “New York” should be recognized as a single entity, but it may be mistakenly segmented into “New” and “York”. Additionally, there can be ambiguity in the type of entity, such as “Apple” being interpreted as either a company or a fruit.

An alternative approach to named entity recognition (NER) is the BIO (Begin-In-Outside) tagging scheme. In this scheme, tokens are labeled with B (beginning), I (inside), or O (outside) tags to indicate the boundaries of named entities:
- B: tokens at the beginning of a named entity span
- I: tokens inside a named entity span
- O: tokens outside of any named entity span
Entity linkage
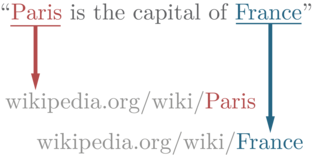
Definition
Entity linkage, also known as entity linking, refers to the process of connecting mentions of entities in text to a knowledge base, such as Wikipedia. This step typically follows named entity recognition and plays a crucial role in extracting knowledge from textual data.
Determining the mention of a named entity in text is typically just the initial step in the process. The subsequent step involves identifying the specific real-world entity being referred to. Linkage techniques rely on the relative significance of entities and the context within the text.
While the ontology or knowledge base used is often Wikipedia, it is important to note that not all individuals or objects have a Wikipedia page. Therefore, custom ontologies are necessary to handle such cases.
Relation extraction
Definition
Relation extraction refers to the process of identifying relationships between entities mentioned in text. It is typically the third step in extracting knowledge from text, following named entity recognition and entity linkage.
Once entity mentions have been linked to specific entities, relationships between these entities can be discovered and used to populate a knowledge graph.
In relation extraction, the goal is to predict missing links in a graph. Entity embeddings can be utilized for this task, as they naturally encode relationships through spatial translations.
Parse tree
Definition
Parse trees provide a visual representation of the syntactic structure of a sentence. They are commonly used in natural language processing to analyze the grammatical structure of sentences. By examining the relationships between words in a sentence, parse trees help us infer the intended meaning (semantics) of the sentence.
Formal grammars are used to define the rules of a language for generating valid text.
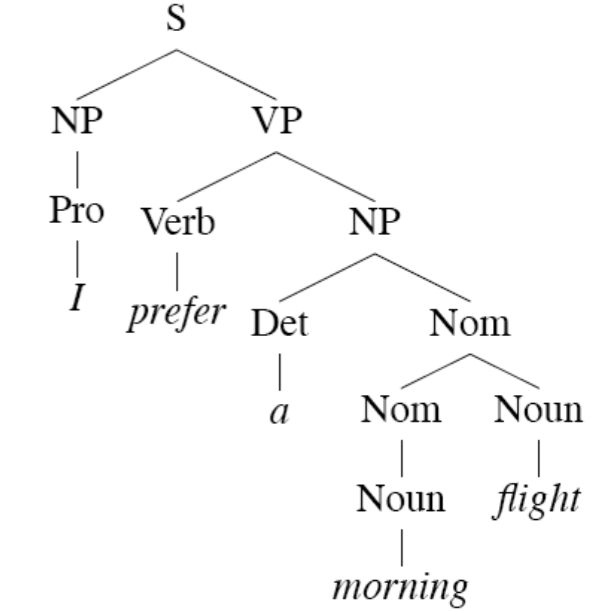
Given a piece of text, we can reverse the process (parse the text) to determine which rules have been applied, and in which order, to create it. The recursive application of rules results in a tree structure for each sentence.
In theory, we don’t need machine learning for parsing text, but in practice, formal grammars are brittle and natural language can be ambiguous, so we need to use machine learning to extract parse trees.
Parsing trees are useful for understanding the meaning of a sentence in order to populate a structured database with information contained in the text or generate a valid text sentence in the story that is consistent with them. To do that, we need to know who did what in the sentence. This relationship information is found in the parse tree.
The Penn Treebank is a widely recognized dataset that consists of sentences along with their corresponding parse trees. It encompasses a vast collection of words extracted from the Wall Street Journal (WSJ), making it a valuable resource for natural language processing tasks. With its millions of words, the Penn Treebank provides a rich source of linguistic information and serves as a benchmark for various language processing techniques. Researchers and practitioners often rely on this dataset to develop and evaluate algorithms for tasks such as parsing, syntactic analysis, and semantic understanding.
Co-reference resolution

Definition
Co-reference resolution is the task of determining which words in a text refer to the same entity. This is often the fourth step in extracting knowledge from text, after named entity recognition, entity linkage, and relation extraction.
Co-reference resolution plays a crucial role in understanding the meaning of a text by identifying the entities referred to by pronouns and other words. In terms of the order of pronouns and referents, the pronoun usually follows the referent, but there are cases where the pronoun precedes the referent.
The resolution of co-references to entities mentioned earlier or later in the text is necessary for tasks such as information extraction, comprehension of statements about those entities, and the functioning of chatbots.
Various types of reference phenomena exist, including
- pronouns: “I saw no less than 6 Acura Integra today. They are the coolest cars.” where “they” refers to “Acura Integra”
- non-pronominal anaphora: “I saw no less that 6 Acura Integra today. I want one.” where “one” refers to “one Acura Integra”
- inferable anaphora: “I almost bought an Acura Integra today, but the engine seemed noisy.” where “the engine” refers to the engine of the Acura Integra
- demonstratives: “I bought an Integra yesterday, similar to the one I bought five years ago. That one was nice, but I like this one even more.” where “that one” refers to the Integra bought five years ago and “this one” refers to the Integra bought yesterday
Taxonomies and ontologies
Definitions
- Taxonomy is a hierarchical classification of entities, where each entity is a child of a parent entity. Taxonomies are used to organize information in a structured way, making it easier to navigate and understand.
- Ontology is a more general term that refers to a formal representation of knowledge, including taxonomies. Ontologies are used to define the relationships between entities and their attributes, allowing for more complex reasoning and inference.
Many ontologies are composed of:
- classes: set of objects with a type
- individuals: objects that belong to a class
- attributes: properties with primitive data types allowing for restrictions on values
- relations: characterization of relationships among classes or individuals
- logical rules: constraints on the ontology
The relationships between entities in an ontology can be displayed as a graph, where nodes are entities and edges are relationships between entities.
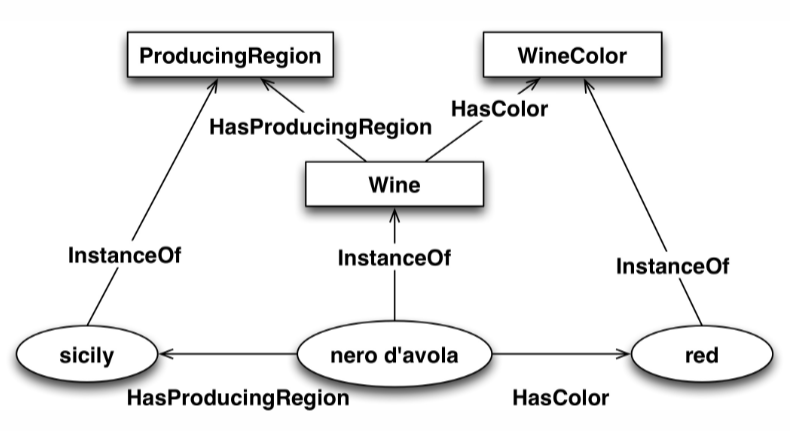
OWL (Web Ontology Language) is a standard for representing ontologies on the web, and it is based on RDF (Resource Description Framework) and uses SPARQL query language to allow inference over KB. Knowledge base have open world semantics, meaning that any statement that is non known to be true is considered unknown, as opposed to closed world assumption used in databases where any statement that is not known to be true is considered false.