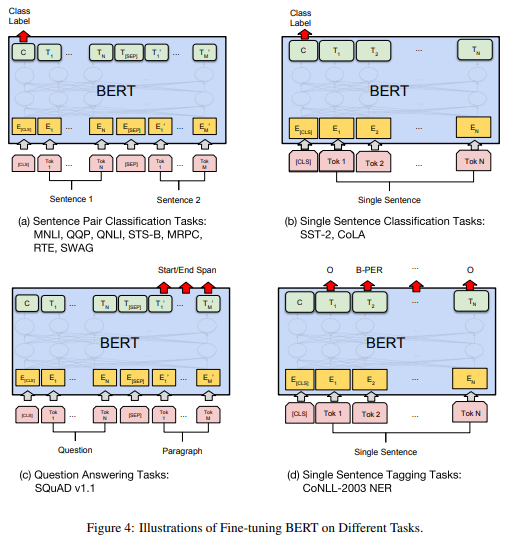
Fine-tuning Transformers to perform other Tasks
Language models offer great flexibility when it comes to fine-tuning BERT for pairwise classification. By incorporating two special tokens, namely [CLS] for the class and [SEP] as a separator, BERT can be adapted for various tasks such as:
- single text classification
- text pair classification
- question answering
- sequence labeling
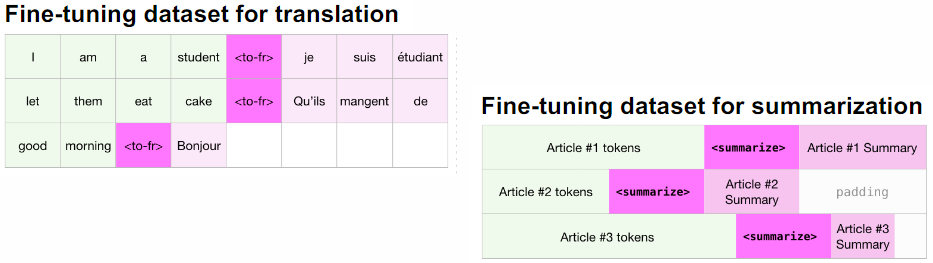
Fine-tuning GPT-2 allows for its use as a text encoder for classification tasks. However, the true power of GPT-2 lies in text generation, making it ideal for tasks like translation, summarization, and dialog. To facilitate fine-tuning, special tokens or text prompts can be introduced to differentiate input from output and specify the desired output type.
Zero, One and Few-shot Learning
GPT can be used effectively without the requirement of fine-tuning. Language models possess the capability to learn comprehensively, regardless of whether they have been fine-tuned or not. The model has already been exposed to numerous instances of one/few-shot learning during its pretraining phase! Zero/few-shot learning is capable of handling a diverse range of tasks. Language models are adaptable learners that can predict text and offer a multitude of functionalities:
- Translation: Provide multiple pairs of source language and target language text, then prompt the model with a sentence to translate.
- Question answering: Simply prompt the model with a question, which can be formulated as a statement. For example, “The height of the Eiffel Tower in meters is…”
- Reading comprehension: Provide text along with examples of questions and answers, then prompt the model with an unanswered question.
- Summarization: Provide the content to be summarized and prefix the response with “tl;dr:” (too long; didn’t read).
Question answering
Language models have the ability to learn facts and provide answers to questions. They store facts in their “parametric knowledge”. While confident predictions from language models are often correct, it is important to note that they are not as reliable as other forms of question answering. It is worth mentioning that the system has not been specifically trained for this purpose.
Reading comprehension
To provide the necessary context for few-shot learning, you can include a document that contains the answers. Additionally, for few-shot learning, you can provide examples of questions and answers. To prompt the model for a new question, simply provide the question and ask the model for an answer.
It’s important to note that this general scheme can be applied to various problems, such as fact checking, where the context is retrieved as potential evidence to support or refute a claim.
Translation
GPT-2, although not specifically trained for translation, surprisingly performed decently as a machine translation system. Despite being trained only on an English corpus, it managed to learn to translate other languages, including French, thanks to the hidden patterns in the training data.
Estimating Similarity between Documents
Learning to rank documents using a BERT-based pairwise text classifier is a powerful technique in web search. The process involves creating a dataset of <query, document, label> triples, where the label represents the relevance of the document to the query (e.g., “highly relevant”, “relevant”, “not relevant”, “spam”). By training BERT to predict the relevance label, we can effectively rank the documents based on their relevance to the query.
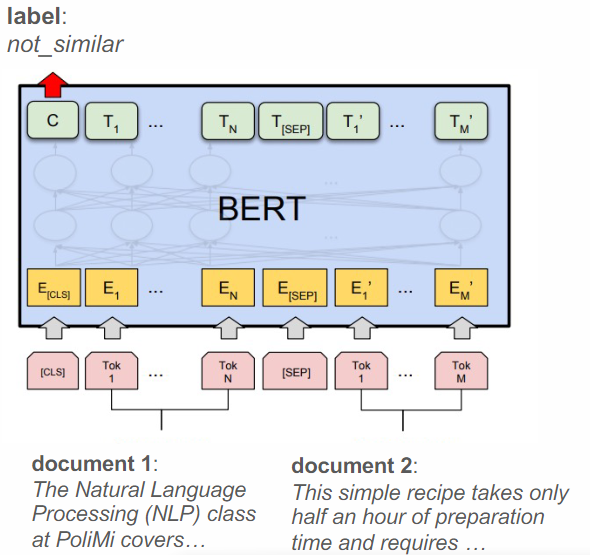
Another application of BERT is estimating the semantic similarity between documents. This can be achieved by training BERT on pairs of similar and dissimilar documents, either as a classification task to identify similar documents or as a regression task to predict the similarity value. Calculating the similarity between documents is crucial for tasks such as document clustering, where grouping similar documents together is essential.
Sentence Transformers
Using pairwise BERT classifier to estimate the relevance of each document for a given query is a powerful technique. It leverages the order of words in the document and the query, as well as the semantics of words using embeddings. However, it can be very costly in terms of computation. BERT performs many matrix multiplications during inference, requiring a GPU to run fast. Even with a GPU, it still takes a considerable amount of time to run, especially when there are a large number of documents to score. For example, if it takes 1ms to compute the score per document and there are a million documents, it would take over 15 minutes to run the query. Is there a way to speed up the computation? Ideally, it would be beneficial to perform as much precomputation as possible, but it is not feasible to precompute the similarity until the query is seen.
Solution 1: Utilize lexical search to identify potential candidates and then apply a fine-tuned pairwise BERT classifier to reevaluate and rank the documents.
First, employ a lexical search engine to swiftly identify a set of candidate documents. Then, utilize a fine-tuned pairwise BERT classifier to reassess and reorder the candidate documents based on their relevance to the query.
By combining the efficiency of lexical search with the accuracy of BERT, you can achieve a final ranking of the documents that best match the query.

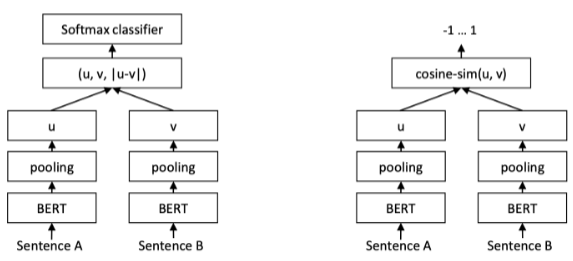
Solution: To compute document embeddings, one approach is to use BERT. The contextual embedding for the [CLS] token in BERT can serve as the representation of each document. By calculating the dot-product between embeddings of different documents, their similarity can be determined. The model can be trained on pairs of similar and dissimilar documents using “contrastive loss” to generate high similarity scores for similar documents and low similarity scores for dissimilar documents. Due to the context length restriction of 500 tokens, it may be necessary to compare sections of the document and aggregate the results.
Another technique called Sentence BERT (SBERT) utilizes the BERT (or RoBERTa) model to learn vector representations for entire documents. It employs a pooling layer to combine the output and applies contrastive learning to create an embedding space where document similarity can be measured.
Vector Databases
Definition
A vector database is a database that stores and indexes objects based on their embeddings in a high-dimensional space. It allows for efficient retrieval of objects based on their similarity to a query object.
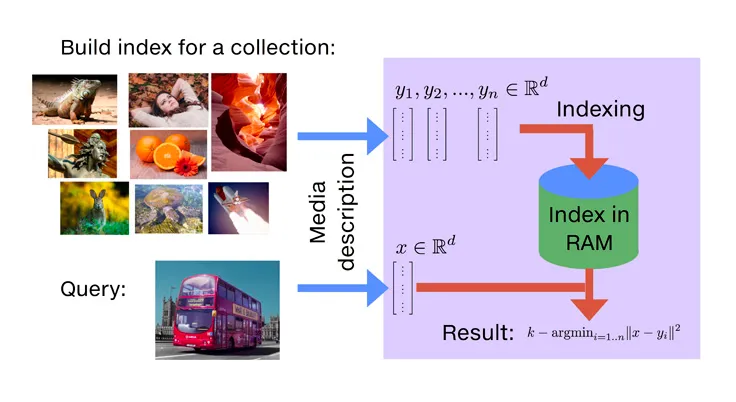
These databases enable fast nearest neighbor search in the embedding space, which can be challenging in high-dimensional spaces where vectors are often at 90 degrees and approximately equidistant from each other. However, clever algorithms have been developed to effectively partition the space into clusters, making nearest neighbor search feasible. One such algorithm is HNSW (Hierarchical Navigable Small Worlds), which creates a hierarchical structure to efficiently navigate the space and find nearest neighbors. With the help of vector databases and algorithms like HNSW, finding the closest objects in high-dimensional spaces becomes much more efficient and practical.
Multimodal embeddings
CLIP (Contrastive Language–Image Pre-training) is a technique that aims to align the embedding spaces of text and images. By generating embeddings for both text using SentenceTransformer and images using models like ResNet or VisionTransformer, we can use contrastive learning to ensure that the two spaces are in agreement.
We take a set of <image, text> pairs, such as images and their corresponding text captions, and train a classifier to identify which piece of text describes which image, and vice versa. It enables semantic image search using text queries, allowing us to find images based on their semantic meaning.
Multi-task Learning
Language models (LMs) are highly versatile models that can be applied to a wide range of tasks. Researchers and practitioners have discovered that training LMs to perform multiple tasks simultaneously often leads to better performance compared to models trained on a single task. In fact, some have even explored the idea of learning the optimal prompt or input format for each specific task, further enhancing the model’s ability to excel in various domains and applications.
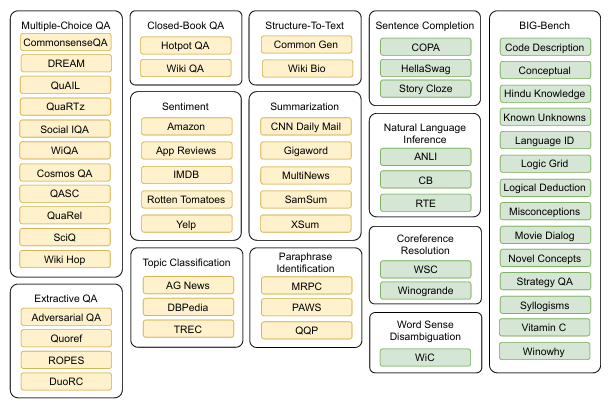
This multi-task learning approach harnesses the power of LMs to tackle multiple tasks efficiently and effectively, unlocking their full potential in the field of natural language processing and beyond.
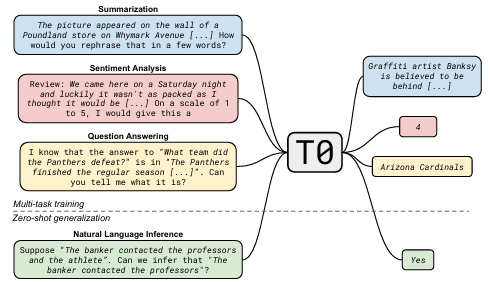
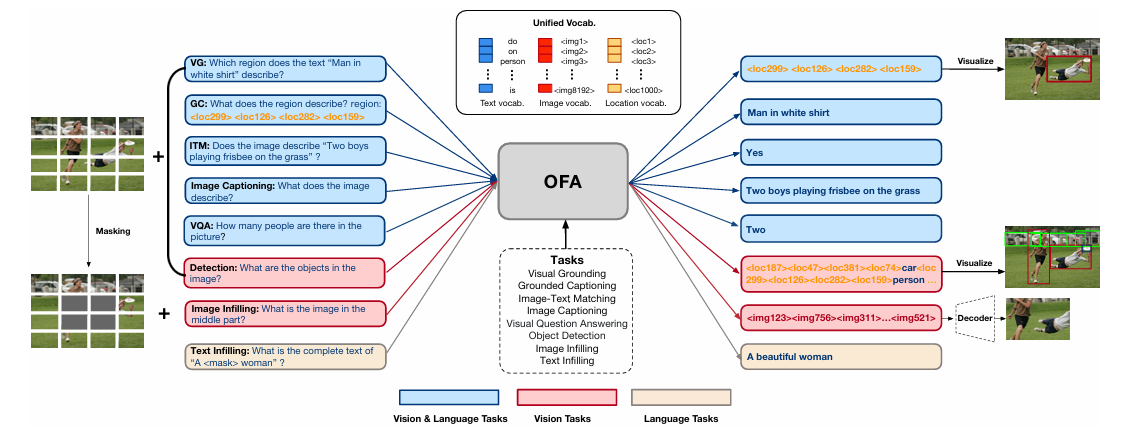
Multi-modal Models
Multimodal learning is an exciting area of research that explores the integration of multiple modalities, such as text and images, to enhance the learning capabilities of models.
The Transformer architecture, known for its flexibility and effectiveness in natural language processing tasks, proves to be highly adaptable in the realm of multimodal learning as well. By extending the traditional text-to-text models to include multimodal inputs, such as combining textual data with accompanying images, the Transformer architecture opens up new possibilities for tackling tasks that involve multiple media types. This allows for the development of models that can learn and understand information from various modalities, leading to improved performance and a deeper understanding of the underlying data.
With the ability to process and analyze both textual and visual information, multimodal Transformers have the potential to revolutionize fields such as computer vision, natural language understanding, and multimedia analysis. By leveraging the power of the Transformer architecture, researchers and practitioners can explore the vast opportunities presented by multimodal learning and pave the way for advancements in cross-modal tasks and applications.
References
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- The Illustrated GPT-2 (Visualizing Transformer Language Models)
- Language Models are Few-Shot Learners
- Faiss: A library for efficient similarity search
- MULTITASK PROMPTED TRAINING ENABLES ZERO-SHOT TASK GENERALIZATION
- OFA: UNIFYING ARCHITECTURES, TASKS, AND MODALITIES THROUGH A SIMPLE SEQUENCE-TO-SEQUENCE LEARNING FRAMEWORK