LSTMs have proven to be incredibly powerful, leading to their use in various applications such as translation, summarization, and dialog systems. Leveraging LSTMs, we can train two distinct RNN models:
- The Encoder is responsible for processing the input text and producing a representation for the entire sequence.
- The Decoder takes the output from the Encoder and generates new text by serializing it one word at a time.
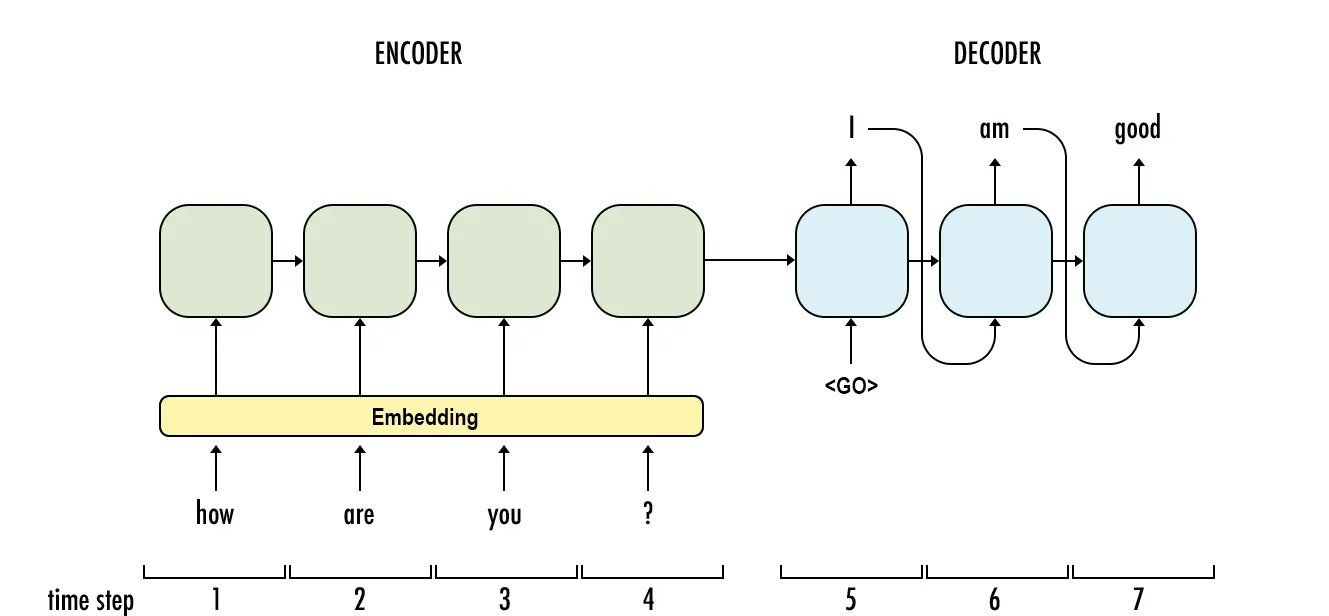
RNN-based sequence-to-sequence (seq2seq) models have significantly advanced the field of natural language processing across various tasks. For instance, in question answering, instead of training a model to predict answers from a predefined set of options, we can train a model to generate text that can encompass any possible answer.
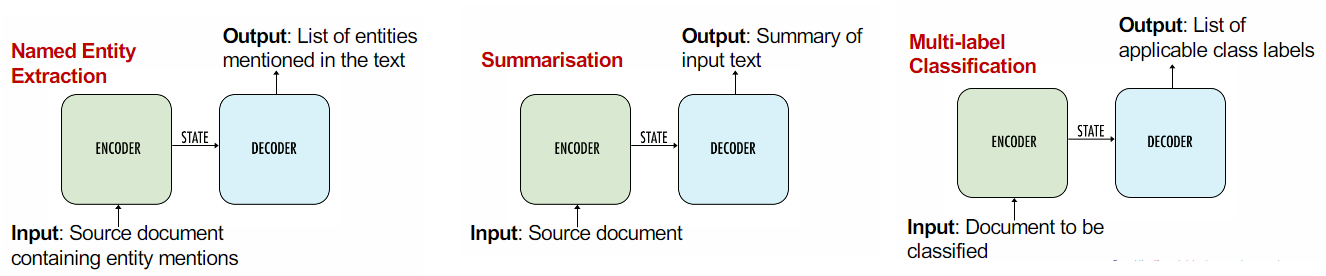
Almost all NLP tasks can be framed as seq2seq problems, including named entity extraction, question answering, and spelling correction, among others.
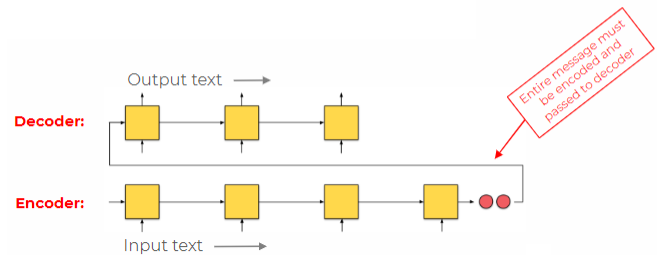
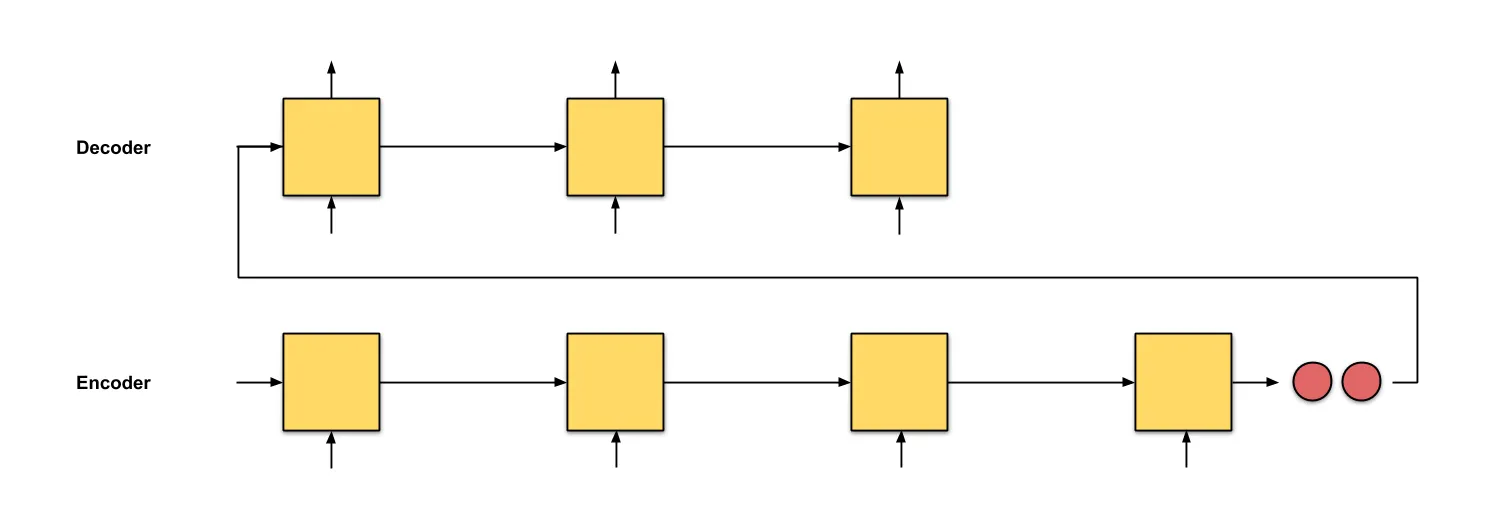
Take the task of sentence translation as an example. In order to start translating, you need to wait for the entire sentence to be read. This is similar to the challenge faced by the encoder-decoder architecture, where passing all the information to the decoder becomes difficult. It would be more convenient for the decoder to have access to the notes of the encoder.
Attention mechanism
Definition
Attention plays a vital role in modern image and text processing. In natural language processing (NLP), attention mechanisms enable models to focus on specific parts of the text, such as important words, when making predictions. This can be used to classify sentiment by paying attention to sentiment-bearing words or to extract the named entity that answers a question.
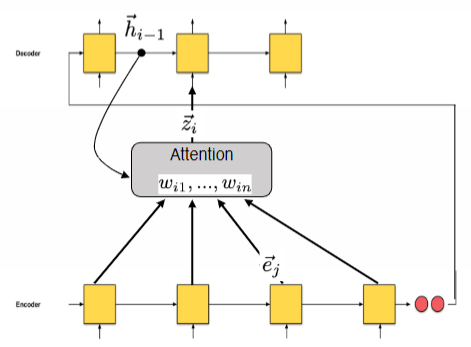
The similarity between the encoder state and the output embedding is calculated for each term in the input sentence.
where
is the decoder state at position and is the encoder embedding at position . The similarity function can be additive or multiplicative. The soft-attention produces a weighted average over the input embeddings, which is then used to compute the context vector.
Attention models enable the decoder to access the encoded input and establish a direct pathway for information to transfer from the input to the output. Instead of directly mapping input words to output words, attention models account for variations in the number of tokens required to convey the same concept across languages, as well as differences in word order.
Example
Consider the following examples:
- In English, the phrase “apple tree” is translated to “apfelbaum” in German, where the noun comes before the adjective.
- In English, the phrase “United Nation General Assembly” is translated to “Assemblea Generale delle Nazioni Unite” in Italian, where the noun comes after the adjective.
Producing the correct output word often necessitates considering more than just the current input word. In fact, it may require knowledge of a future word in the sentence, such as determining the gender of a determiner.
To facilitate the transfer of information from the input word embeddings to the corresponding output words, we require a mechanism that is influenced by the previous state of the decoder and the attention mechanism. Attention provides a direct route for information to flow from the input to the output, allowing the model to focus on specific parts of the input when making predictions. What information flows into the decoder is controlled by the previous state of the decoder and the attention mechanism.
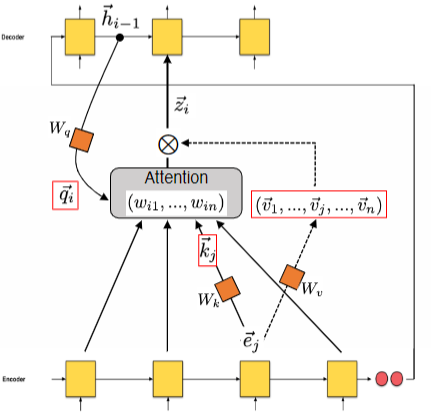
Calculating similarity
In additive attention, the similarity between the decoder state and the encoder embeddings is calculated by passing them through a feed-forward neural network (
On the other hand, in multiplicative attention, the similarity is computed as the dot product between the decoder state and the encoder embeddings:
where,
Once the similarity weights at position
In the case of multiplication attention, the weights are computed as:
We can generalize the notation to speak of:
- Query: what is being searched for (e.g. need adjective that describes a person)
- Key: the index of what to find (e.g. have adjective that describes people and animals)
- Value: the stored information at key (e.g. the word is “friendly”, which in Italian could be translated as “amichevole”)
where the query, key and values are usually transformed by a linear transformation:
- Query:
- Key:
- Value:
where
Deep Learning
Deep Neural Networks (DNN), also known as Neural Networks with multiple layers, offer significant improvements in performance by automatically learning a hierarchy of useful features. However, training deep networks requires abundant training data and substantial computational resources, such as GPUs. It can also be challenging and time-consuming.
In recent years, deep learning has gained immense popularity due to its exceptional performance, particularly with complex data types like images and text. It simplifies the training process and enables transfer learning across different tasks. This popularity can be attributed to advancements in hardware, such as GPUs for efficient matrix multiplication, the availability of large datasets for learning complex tasks, innovative architectures, improved training techniques, and user-friendly toolkits and libraries like TensorFlow and PyTorch.
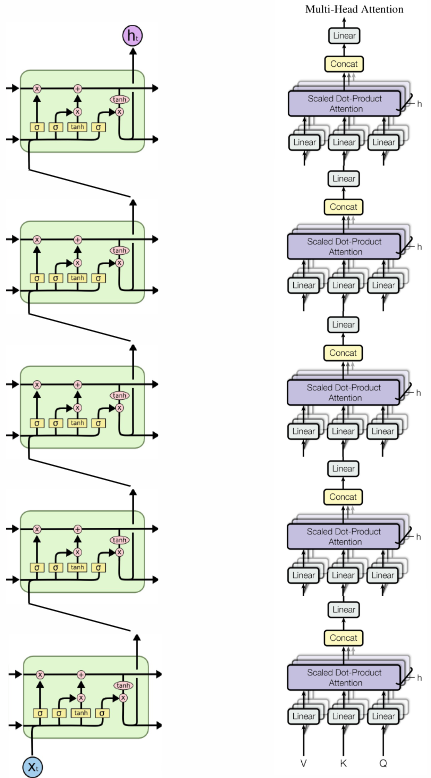
Deep learning plays a crucial role in text processing tasks, offering state-of-the-art performance in areas such as classification, summarization, generation, and translation. Previously, deep architectures involved stacking multiple layers of LSTMs. However, in 2017, a new architecture called the Transformer was introduced in the paper “Attention Is All You Need”. The Transformer utilizes a stack of self-attention networks to process sequences, eliminating the need for recurrent connections.
Slow training of RNNs
The challenge with training RNNs is that generating a prediction requires information to flow from the first position of the encoder to the last position of the decoder. Additionally, gradient information needs to propagate back along the entire sequence to update parameters. Since this calculation is sequential, it cannot be parallelized, resulting in training time that is linear in the length of the text (
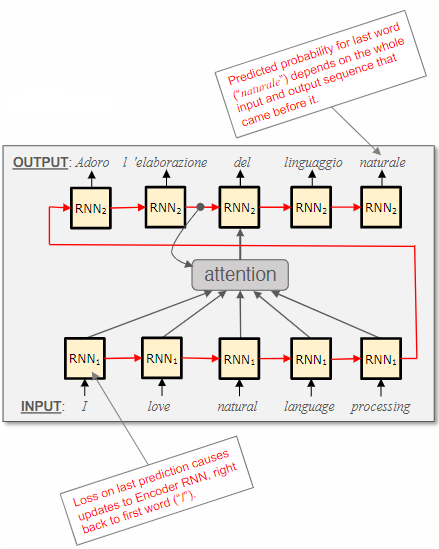
However, during training, we already have knowledge of the desired output and utilize an attention mechanism that allows information to be directly passed from the input to the output.
IDEA
If we remove the recurrent links from the encoder and decoder, it raises two challenges:
- Determining what to use as the query.
- Losing information about the word order.
Possible solutions to these challenges include:
- Using the current output of the encoder as the query instead of the decoder’s context.
- Incorporating position information directly into the encoder’s data, such as using learned embeddings to represent different positions.
The self-attention mechanism addresses these challenges by utilizing word embeddings vectors to generate updated word embedding vectors. Each higher-level embedding is calculated as a weighted average of the underlying word embeddings, with the weights determined by the similarity between embeddings in their respective positions. The model parameters govern this process, learning the optimal way to compute the weights.
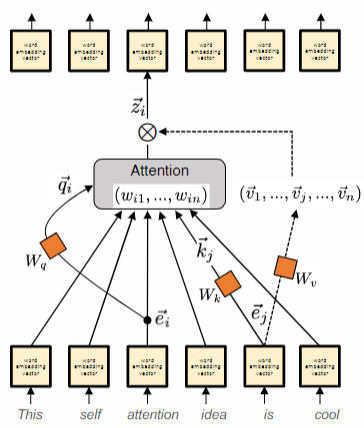
Self-attention is a mechanism that updates a sequence of embedding vectors by taking the weighted average of incoming embedding vectors.
- query linear transform of embedding at position
: - key linear transform of embedding at position
: - value linear transform of embedding at position
:
Self-attention models are trained for two main tasks:
- Filling in missing words in the input text using the surrounding context. This is commonly done in tasks like Masked Language Modeling (MLM), where certain tokens in the input text are randomly masked.
- Predicting the next word in the text based on the previous words.
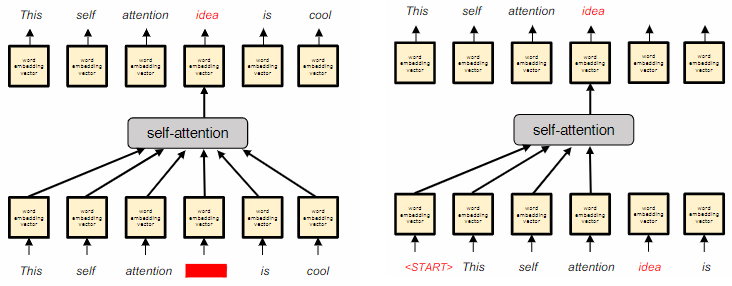
Self-attention is a valuable tool for language models because it allows words to have different meanings depending on their context. The attention mechanism enables the representation to depend on the context, learning a weighting function over lower-level embeddings of context terms. Multiple layers of self-attention can effectively handle complex tasks like coreference resolution.
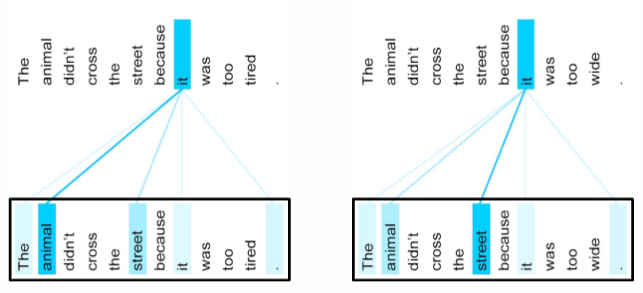
Complicated tasks, such as coreference resolution, can be effectively addressed by utilizing multiple layers of self-attention.
Example
Let’s examine the reference of the pronoun “it” in the following two sentences:
Note that in the first sentence, more attention is given to the word “animal,” while in the second sentence, more attention is given to the word “street”. This is possible because the embedding for the word “it” in the lower layer already incorporates some of the embedding for the word “tired.” As a result, the similarity between the embedding of “it” and the embedding of “animal” is higher than the similarity between the embedding of “it” and the embedding of “street.”
References
- NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
- Attn: Illustrated Attention. Attention illustrated in GIFs and how…
- Sequence to sequence model: Introduction and concepts | by Manish Chablani | Towards Data Science
- Understanding LSTM Networks — colah’s blog
- Attention Is All You Need
- Transformer: A Novel Neural Network Architecture for Language Understanding