In real-world applications of data science, machine learning (ML), statistics, and data mining, the actual implementation of the core algorithm typically represents a very small fraction of the total codebase—often less than 5% of the total lines of code. The bulk of the effort, roughly 95% of LOC, is dedicated to various critical data management and preparation tasks. These tasks include:
Data Cleaning & Annotation: Preparing raw data by identifying and correcting errors, handling missing values, and ensuring consistency. Annotation involves adding metadata or labels, which is essential for supervised learning.
Data Extraction, Transformation, and Loading (ETL): Retrieving data from multiple sources, converting it into a usable format, and loading it into systems for further analysis.
Data Integration, Pruning, and Further Cleaning: Combining data from different sources, filtering unnecessary data, and performing additional rounds of cleaning to ensure quality and relevance.
Parameter Tuning: Adjusting the parameters of machine learning models to improve performance.
Model Training & Deployment: Training models on clean, processed data and deploying them in production environments for real-world use.
This demonstrates that much of the development process in a data-centric application involves managing and manipulating data, not just running ML algorithms. The following diagram outlines the various stages of a data science workflow:
graph TB
A[Acquisition]
B[Extraction, Cleaning, Annotation]
C[Integration]
D[Analysis Modelling]
E[Interpretation Visualization]
subgraph DataScience[Data Science]
direction LR
D --> E
end
subgraph Application[Application of Statics/AI/ML]
direction TB
B --> C --> DataScience
end
subgraph "Big Data Management"
direction TB
A --> Application
end
Data Integration and the “Four Vs” of Big Data
When handling large-scale data, data integration—the process of combining data from different sources into a unified view—plays a critical role. Integrating data involves not only merging data but also ensuring that conflicts between similar concepts from different sources are resolved. This often requires detecting correspondences between different entities and dealing with inconsistencies.
A key challenge in data integration is managing the “Four Vs” of Big Data:
Volume: Data sources contain vast amounts of data, and the number of sources globally has grown into the millions, making integration complex.
Velocity: Data is generated rapidly and continuously updated, requiring real-time or near-real-time integration and processing.
Variety: Data is highly heterogeneous, differing significantly in structure and representation even within the same domain. This includes structured, semi-structured, and unstructured data from various systems like relational databases, legacy systems, sensors, and user-generated content.
Veracity: Data quality varies widely between sources, affecting coverage, accuracy, and timeliness. Many business leaders do not fully trust the data they rely on for decision-making.
Challenges Due to Autonomy and Heterogeneity
Data heterogeneity, which complicates data integration, stems from various forms of autonomy across systems:
Design Autonomy: Each system may represent and structure data differently (e.g., different schemas).
Communication Autonomy: Systems may vary in how they handle queries and data retrieval.
Execution Autonomy: Systems may have different operational and algorithmic processes, making it difficult to standardize data integration.
Despite this heterogeneity, there is a strong need for interoperability between software applications, services, and data management systems. Organizations often need to reuse legacy systems and integrate existing data repositories while reconciling the different viewpoints of various stakeholders. The goal of data integration is to enable these different systems to work together efficiently from a data perspective, supporting seamless interoperability while overcoming challenges related to autonomy.
Problems in Data Integration
Data integration is a complex process primarily due to the variety (heterogeneity) that exists across multiple datasets that need to be combined and used together. This heterogeneity arises from differences in technology, structure, and semantics, making it difficult to harmonize and analyze the data effectively. Below are the major problems in data integration caused by heterogeneity:
Problem
Type
Different platforms
Technological heterogeneity: The datasets may reside on various platforms (e.g., different operating systems, database systems, or cloud providers), which complicates integration and requires cross-platform compatibility.
Different data models of the participating datasets
Model heterogeneity: Datasets may use different data models (e.g., relational, NoSQL, object-oriented) that represent information differently, making it difficult to unify their structures.
Different query languages
Language heterogeneity: Different databases or systems may require different query languages (e.g., SQL, XQuery, SPARQL), leading to challenges in extracting and manipulating data uniformly.
Different data schemas and conceptual representations
Schema (semantic) heterogeneity: Each dataset may have a unique schema, with different structures or terminologies for representing similar concepts. This leads to semantic mismatches that need to be resolved for integration.
Different values for the same information
Instance (semantic) heterogeneity: Different datasets may contain conflicting or inconsistent values for the same real-world entity, either due to errors or different interpretations of the data. This makes it difficult to reconcile these instances into a coherent, unified dataset.
Veracity: Data Quality Dimensions
Data veracity refers to the trustworthiness and accuracy of the data, but it also encompasses broader dimensions of data quality. These are the key factors to assess when determining the reliability of integrated data:
Completeness: Whether the data is complete and contains all the necessary information for accurate analysis.
Validity: Whether the data adheres to predefined formats, rules, and constraints.
Consistency: Whether the data across different datasets and systems is uniform and does not conflict with each other.
Timeliness: Whether the data is up-to-date and relevant for the intended analysis or decision-making process.
Accuracy: Whether the data correctly reflects the real-world entities or events it is supposed to represent.
Steps of Data Integration
Definition
Data integration is a process that involves multiple steps to ensure that heterogeneous data sources are unified and made accessible for analysis. Here are the key steps involved:
Schema Reconciliation: This step involves mapping the data structures (if they exist) of different datasets into a common format. Schema reconciliation addresses differences in how each data source structures its data and ensures that the integrated system can interpret the different schemas.
Record Linkage: Once the schemas are aligned, record linkage is the process of identifying and matching records that represent the same entity across different datasets. This step is crucial when data from multiple sources refers to the same real-world entities but may use different formats or identifiers.
Data Fusion: After matching records, data fusion reconciles non-identical or conflicting content. For example, when multiple records have different values for the same attribute, data fusion decides how to merge or prioritize these values to create a unified, consistent representation.
There are two primary approaches to integrating database systems, each with its pros and cons:
Materialized Database Integration:
In this approach, data from different sources are merged into a new, centralized database. This is typically done through Extract-Transform-Load (ETL) systems that periodically extract data from the sources, transform it into a compatible format, and load it into the new database. The most common example of this method is data warehouses, which store integrated data for systematic or ad-hoc analysis.
Advantages
Disadvantages
Centralized data for easy access and analysis.
Data may not be up-to-date, as ETL is done periodically.
Efficient for historical analysis.
Requires significant storage and computational resources.
Virtual (Non-materialized) Database Integration:
In contrast to materialized integration, virtual integration keeps the data at the source and does not create a new physical database. Instead, systems such as Enterprise Information Integration (EII) provide a common interface or front-end for querying the various data sources in real-time. Queries are reformulated to the local formats of the underlying databases, and the responses are combined to provide a fresh, up-to-date answer.
Advantages
Disadvantages
Always returns the most current data.
Real-time queries can be slow, depending on the source systems’ performance.
Avoids the need for large storage resources.
Complex query reformulation is required for heterogeneous sources.
Example of virtual integration
The following diagram illustrates how a virtual integration system works:
graph LR
A[Query]
B[Global Schema]
C[Reformulation Engine]
D[(Source 1 -<br> IMDB)]
E[(Source 2 -<br> Cinemas)]
A --> B --> C --> D
C --> E
In this example, a query is posted to a global schema that represents a high-level view of the underlying data. The query is reformulated into the formats understood by the local databases (e.g., IMDB or Cinema data sources), which return their results to be combined into a single response.
Materialized Integration in Data Warehouses
Materialized integration is frequently used in data warehouses, which are specialized data repositories that allow for extensive data analysis and mining. These systems are fed by ETL (Extract, Transform, Load) processes, which periodically collect data, clean it, and store it in the warehouse. The warehouse supports historical analysis and is useful in environments where data doesn’t need to be continuously updated.
For example, in a data warehouse environment:
graph TB
A[Query]
B[(Data Base)]
C[(Relational DB)]
D[(OO DB)]
E[(Excel sheet)]
A <-- on-line --> B
subgraph "off-line read-only"
C --> B
D --> B
E --> B
end
In this scenario, data is extracted from different sources (Relational DBs, Object-Oriented DBs, Excel sheets), transformed into a unified schema, and loaded into a central database. The data remains static until the next ETL cycle.
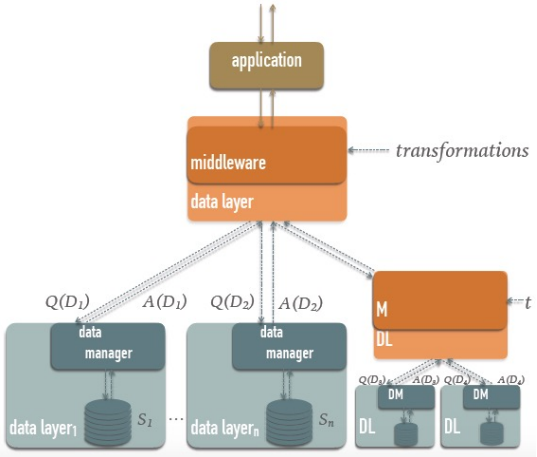
Query Processing in Data Integration
Given a target schema (), a set of source schemas, and a set of mappings that relate to the elements in , a query against the target schema can be evaluated over the set of source instances . The query is reformulated and executed over the local data sources, and the results are combined.
The process can be visualized as:
graph LR
A[Query]
B[(Target DB)]
C[(Source DB)]
A --> B
B -- Reformulated query --> C
C -- answer --> B
where, a query is posted to the target database, which reformulates the query into a format the source database understands. The source database returns the result, which is sent back to the target system.
Rationale for Choosing Virtual Integration
Conventional wisdom often advocates for using data warehousing and Extract-Transform-Load (ETL) products to achieve data integration. While this approach can be effective for historical data analysis, it has significant limitations when it comes to integrating current, operational data.
Consider an e-commerce website that aims to sell hotel rooms online. The inventory of available hotel rooms is stored across various reservation systems managed by major hotel chains like Hilton, Hyatt, and Marriott. If the website employs ETL processes to pull this data into a data warehouse, several issues arise:
Data Staleness: The ETL process typically runs at scheduled intervals (e.g., daily or weekly), meaning that the inventory data becomes outdated quickly. Once the data is extracted, transformed, and loaded into the warehouse, it no longer reflects real-time availability.
Lack of Real-Time Guarantees: If a user makes a booking based on the outdated data, there is no guarantee that the room is still available. Another customer could have already booked the same room during the time it took for the ETL process to run. This discrepancy leads to a poor customer experience and potential financial loss for the business.
Operational Complexity: Maintaining a data warehouse involves additional overhead, including the need for ongoing ETL processes, data management, and storage resources, which can complicate operations.
To address the limitations of traditional ETL and data warehousing methods, businesses needing up-to-date integrated data should consider virtual integration. Here’s why:
Real-Time Data Access: Virtual integration allows queries to be sent directly to the source systems, ensuring that the most current data is retrieved and used. This means that if a hotel room is booked, the availability data is updated in real-time across all platforms.
Reduced Redundancy: By keeping the data at its source and avoiding unnecessary duplication, virtual integration minimizes the storage and maintenance costs associated with data warehouses.
Simplified Querying: Virtual integration systems can present a unified view of disparate data sources, allowing users to query the data as if it were in a single database. This simplifies the process of accessing and analyzing data without the need for complex transformations.
When you need the integrated data to be always up-to-date, USE VIRTUAL INTEGRATION!
This approach will ensure that your business operates with the most accurate and timely information available, ultimately leading to better decision-making and enhanced customer satisfaction.
Example
In this very simple example we don’t have a “transformation” definition: the user sees directly the tables of the sources, therefore the transformations are “the identity mapping”.
Query Execution in the Integration System
Upon receiving a query, the integration system needs to break it down into sub-queries directed at individual datasets. This involves identifying which aspects of the query pertain to specific datasets — those that involve data from a single dataset and those involving data from multiple datasets. The latter can only be processed using integrated data views, while the former can be assessed directly within the respective dataset components.
Query execution example
The join needs to be evaluated at a global level. One of the main challenges in developing virtual data integration systems is to find good strategies of how to decompose and evaluate queries against multiple databases in an efficient manner.
Data integration challenges can arise even in straightforward scenarios, such as when creating a centralized database that merges independently developed databases. The complexity of integration grows significantly in more dynamic situations involving transient and initially unknown data sources.
Why is data integration necessary even within a SINGLE database? Each department within a company may request its own database segment. However, much of this data is shared across multiple departments. If the overall company database consists only of these individual segments, it will lead to significant redundancies, resulting in unnecessary memory usage. More critically, when one instance of these duplicates is updated, the other instances may remain unchanged, creating inconsistencies.
The best approach is to create an integrated, centralized database for the company. Each department will have its own customized view, defined through view definitions.
This method ensures that each data element is stored only once, regardless of which application accesses it. It eliminates unnecessary redundancies, which can cause inconsistencies and inefficient memory usage. Customized views allow for both personalization and access control for each department.
Example
In this example, we are creating a view called CourseCampus that consolidates information from two tables: COURSES and ROOMS.
COURSES: Contains data on courses, including the course name, the teacher, and the room name where the course is taught.
ROOMS: Contains data about rooms, including the room name, building number, and campus name.
Purpose of the View:
The CourseCampus view is designed to provide a simplified representation of the relationship between courses and their respective campuses. By joining the COURSES and ROOMS tables, we can extract relevant information without needing to reference the underlying tables directly.
SQL Query Breakdown:
The CREATE VIEW statement defines the view.
The SELECT clause specifies the columns to include in the view: CourseName from the COURSES table and CampusName from the ROOMS table.
The FROM clause identifies the source tables, while the WHERE clause establishes the condition that links the two tables based on the common attribute RoomName.
Resulting View Schema: The resulting schema of the CourseCampus view will be CourseCampus(CourseName, CampusName), providing users with a straightforward way to access the names of courses alongside their associated campuses without duplicating data.
This view allows for easier queries regarding course locations and ensures data integrity by centralizing information about courses and rooms.
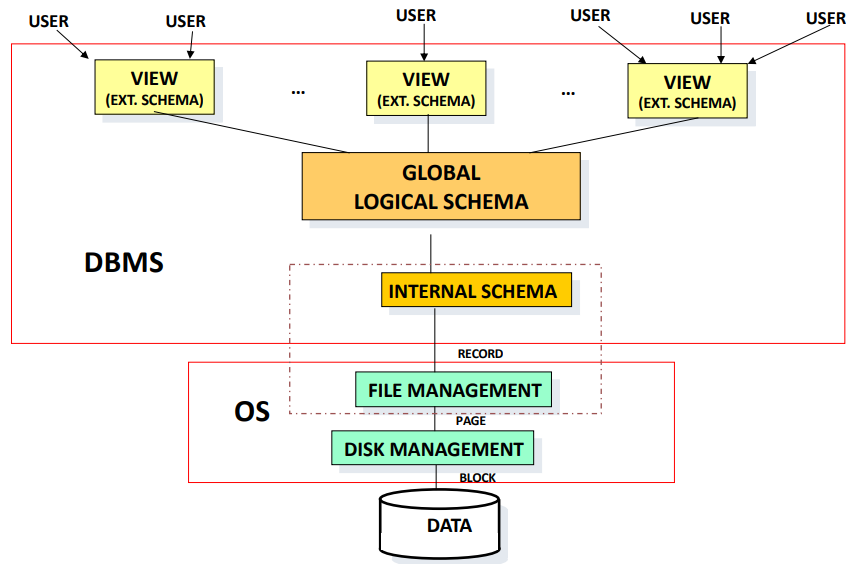
Query Processing in a Centralized DB
User issues query against the user view . Query composition is defined as . Answer is in terms of the base relations (global schema) or of the viewed relations (external schema), depending on how sophisticated the system is.
Data Integration with Multiple Sources
When dealing with the integration of data from multiple sources, several crucial operations need to be executed to ensure effective data integration. These operations include:
Schema Reconciliation: This involves aligning the data structures across different sources to match a centralized schema. It ensures that data elements from various sources are mapped to a common format, facilitating seamless integration and analysis.
Record Linkage: This operation focuses on identifying and matching records across different datasets that refer to the same entity or event. It relies on similarities in data content to establish connections and merge related information.
Data Fusion: Once records are linked, data fusion reconciles conflicting or non-identical information from different sources to create a unified and coherent dataset. This process resolves discrepancies and ensures data consistency across integrated sources.
Integration of data from diverse sources can be achieved using various approaches, each with its advantages and considerations:
Data Conversion (Materialization): Involves converting and consolidating data from multiple sources into a centralized repository, such as a Data Warehouse.
Advantages
Limitations
Provides a unified view of data, simplifies data access, and supports complex queries and analysis.
Potential issues include data redundancy, inconsistency due to delays in updates, and the challenge of reengineering applications if the centralized system changes or is replaced.
Data Exchange (Virtual): Establishes gateways or interfaces between paired systems to enable data sharing.
Advantages
Limitations
Supports direct data access between specific systems without physical data consolidation.
Suitable mainly for pairs of systems and may not scale well for multiple sources. It lacks a unified query interface across all integrated data.
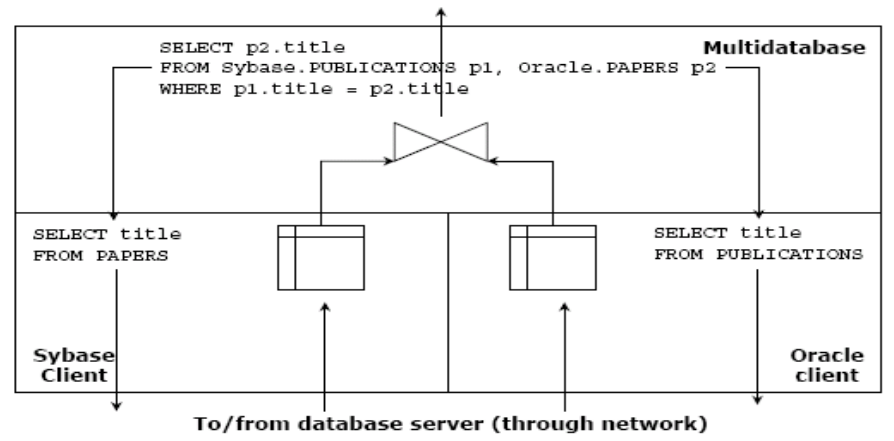
Multidatabase (Virtual): Creates a global schema that provides a unified view of data from multiple sources.
Advantages
Limitations
Enables querying and accessing data across different sources using a standardized schema.
Requires a system capable of translating queries expressed in the global schema into source-specific languages, distributing queries to relevant sources, and aggregating results into a cohesive response.
Achieving effective data integration demands not only understanding these operations and approaches but also implementing robust technical solutions:
Technical Implementation: Systems must support schema mapping, data matching algorithms for record linkage, and sophisticated data fusion techniques.
Query Optimization: Tools and processes for rewriting queries to fit source-specific formats and optimizing query performance across distributed data sources.
Data Consistency and Quality: Mechanisms to ensure data consistency, manage updates, resolve conflicts, and maintain data quality standards throughout integration processes.
Scalability and Performance: Solutions should scale with increasing data volumes and ensure optimal performance for data retrieval and analysis tasks.
There might be several heterogeneities when integrating data from multiple sources, such as:
we might have the same data model but different systems (technological heterogeneity)
we might have different data models (model heterogeneity)
we might have different query languages (language heterogeneity)
we might have semi- or unstructured data (model heterogeneity)
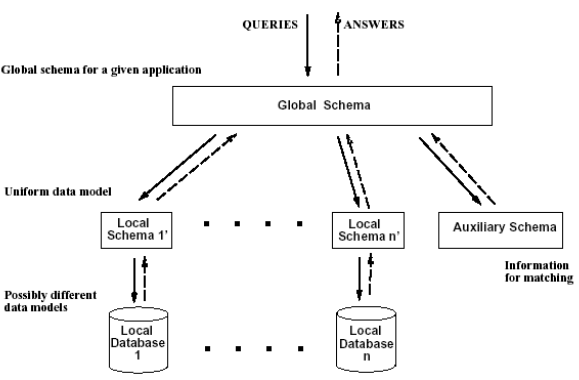
The simplest case is when the data sources have the same data model. In this case, we can adopt a global schema that provides a reconciled, integrated, and virtual view of the different data sources. We also add an auxiliary system that knows the contents of the data sources and integrates them by means of the global schema.
Designing Data Integration in the Multidatabase
In designing data integration within the Multidatabase, we adhere to the following steps:
Identification of Source Schemas: Determine the schemas of the data sources.
Reverse Engineering of Source Schemas: Extract the conceptual schemata from the data sources.
Integration and Restructuring of Conceptual Schemas: Identify related concepts, analyze and resolve any conflicts, and integrate the conceptual schemata.
Translation from Conceptual to Logical Schema: Convert the resulting global conceptual schema into a logical schema.
Mapping the Global Logical Schema to Individual Schemas: Establish the logical view.
Query Response via Data Views: Respond to queries utilizing the data views.
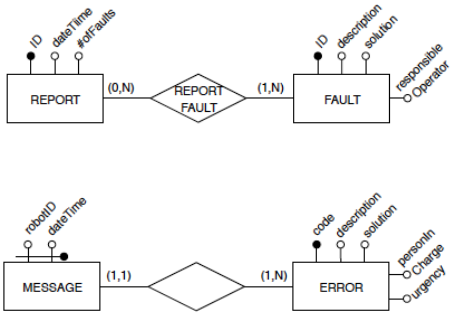
Example
Consider the two following entity sets and keep in mind that PoliRobots has only one robot:
When integrating data from multiple sources with the same data model, we need to perform conflict resolution and reconstruction. This involves identifying related concepts, analyzing and resolving conflicts, and integrating the conceptual schemata. Some common conflicts that need to be resolved include:
Name conflicts: homonyms (attributes with the same name but different meanings) and synonyms (attributes with different names but the same meaning).
Type conflicts: differences in the type of attributes (e.g., numeric, alphanumeric). In a single attribute, different representations of the same concept can lead to conflicts, while in an entity type, different abstractions of the same real-world concept can produce conflicts.
Data semantics conflicts: differences in currencies, measure systems, or granularities.
Structure conflicts: conflicts related to how entities are structured and related to each other, such as attributes that might be represented as entities in different sources.
Dependency conflicts: conflicts related to cardinality or dependency between entities.
Key conflicts: conflicts related to the keys used to identify entities.
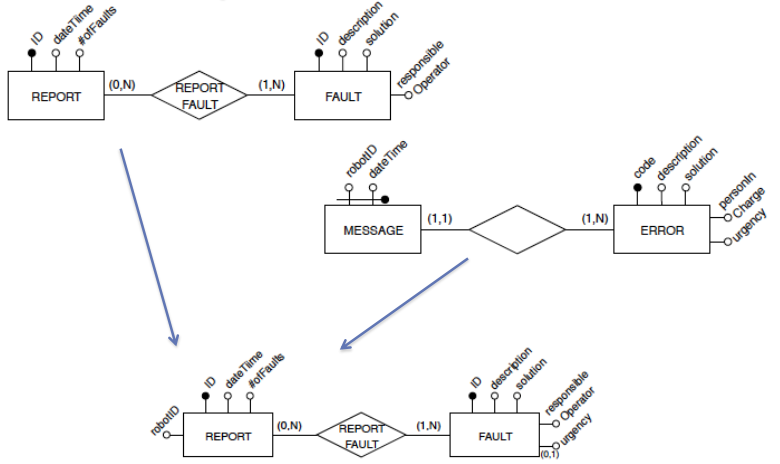
Example
When resolving conflicts and restructuring the conceptual schemata of the PoliRobots and UniPoliRobots data sources, what you obtain is a global conceptual schema that integrates the two sources.
In this case, the global schema is obtained by integrating the two sources and resolving conflicts: we add the robotID attribute to the REPORT entity set from the UniRobots source, we resolve the name conflict between the two keys (ID and code) by keeping only ID and the personInCharge attribute from the UniRobots source becomes the responsiblOperator; we also add the attribute urgency to the FAULT entity set from the UniRobots source, that is an optional attribute.
The new global scheme is transformed into a logical schema, and the logical view is defined as follows:
where KeyGenReport is a function that generates a unique key for the report: the first one is generated by concatenating the ID with the source name, while the second one is generated by concatenating the robot ID with the date and time. The value “R101” is the new ID for the PoliRobots robot (that has only one robot), while other robots are identified by their ID. The value 1 is associated with the urgency of the fault for the UniRobots robot (as it is an optional attribute).