Modern data-driven applications operate in an increasingly complex and dynamic environment characterized by diverse and challenging data sources. These sources are often heterogeneous, encompassing a wide range of structures and formats. For instance, databases may include traditional relational systems or object-oriented ones, while semi-structured data might take the form of XML or HTML documents enriched with various markup languages. Additionally, unstructured data sources such as plain text, multimedia content, and sensor-generated streams further complicate the landscape. These data sources frequently employ different terminologies and operate within distinct contexts, making their integration a non-trivial task.
Another critical feature of modern data is its time-variant nature. Many datasets, such as those on the web, evolve rapidly over time. Moreover, certain data sources may be mobile or transient, further exacerbating the challenges associated with accessing and processing them consistently.
The Nature and Challenges of Uncertain Data
Traditional database systems are built upon the assumption of certainty, adhering to the Closed World Assumption (CWA). Under this assumption, a tuple present in the database is considered unequivocally true, while any tuple absent is assumed to be false. However, real-world data rarely conforms to such rigid certainty. Uncertainty is an intrinsic aspect of many domains. For example:
- Sensor readings, while valuable, may be unreliable due to device limitations or environmental factors.
- Decisions or observations captured in data may reflect incomplete or undecided states, as in cases where a person has not yet made a definite choice.
To address such scenarios, uncertain databases have been developed. These systems model data that reflects varying degrees of uncertainty, often using probabilistic or fuzzy techniques. For instance, in a probabilistic database, tuples might be assigned probabilities to indicate the likelihood of their validity. The collection of all possible configurations of such tuples constitutes a set of possible worlds, each representing a valid interpretation of the data. However, it is worth noting that these models often do not account for tuple correlations, limiting their ability to represent interdependencies effectively.
Uncertainty also arises prominently in the domain of data integration, where disparate datasets must be reconciled into a unified framework. This process involves several sources of approximation and uncertainty:
- Uncertain Data Sources: When data originates from unreliable or noisy sources, the information itself may be ambiguous or incomplete.
- Approximate Mappings: Data integration often relies on techniques like automatic ontology matching, which may produce mappings that are not entirely precise.
- Reconciliation Challenges: Combining data from heterogeneous sources frequently requires creating a mediated schema, which might itself be approximate due to mismatched terminologies or conflicting structures.
- Imprecise Queries: Users often interact with integrated systems through queries that are inherently approximate, such as keyword-based searches, which do not guarantee precise results.
These uncertainties collectively challenge the creation of a coherent and reliable integrated system.
The Semantics of Uncertain Databases
Uncertain databases operate within a framework where ambiguity is modeled and quantified. Depending on the adopted semantics, uncertainty may apply to various levels of the data structure:
- A value within a tuple might be uncertain, such as an attribute with a probability distribution over possible entries.
- An entire tuple might carry a probability, representing its likelihood of existence.
- In some cases, uncertainty may extend to a table, capturing more complex scenarios.
A common approach in probabilistic databases is to assign a probability to each tuple. The probability of a particular possible world (a coherent set of tuples) is then computed as the product of the probabilities of the tuples it contains. However, such models often fail to account for correlations between tuples, which can be crucial for certain applications. For instance, two tuples might represent related events whose probabilities are not independent, but traditional probabilistic databases may lack the mechanisms to capture these interdependencies.
Entity Resolution
Entity Resolution (ER) refers to the process of identifying and consolidating multiple, differing, or even contradictory representations of the same real-world entity within datasets. This problem is a cornerstone in data management and has been studied under various names, including merge/purge, deduplication, and record linkage.
The need for ER arises due to noise and inconsistencies in data. Noise introduces small, often typographical errors, such as misspelling “Peter” as “Peters.” Meanwhile, inconsistencies involve conflicting or varied values for the same attribute or relation of an entity, such as two records providing different addresses for the same individual.
Despite its significance, researchers continue to explore efficient solutions for detecting duplicates in datasets. A commonly used approach is rule-based ER, where predefined constraints determine whether two records are considered identical. For example, if two records are sufficiently similar in properties
However, rule-based ER faces several challenges:
- Complexity of Rule Definition: Designing accurate and generalizable record-matching rules is difficult, especially for diverse datasets.
- Approximate Similarity: Defining and handling approximate matches for data properties is non-trivial.
- Scalability: Pairwise record matching is computationally expensive, often requiring a quadratic number of comparisons as dataset size grows.
To mitigate these issues, techniques like blocking are employed. Blocking partitions datasets into smaller, more manageable groups where records are likely to match. These subsets are then processed for linkage, significantly reducing computational overhead.
Data Provenance: Capturing the Origin and History of Data
Data Provenance, also referred to as data lineage or data pedigree, focuses on understanding the origin and production history of data. Provenance information answers critical questions about a dataset, such as:
- Who created it?
- When it was created?
- How it was created—whether as a direct database entry, the result of a computation, or output from a sensor.
The importance of data provenance lies in scenarios where data reliability and authority are crucial. For instance, if one source is known to be more authoritative or an information extraction tool is known to be unreliable, provenance helps assess data quality and credibility. The database community models provenance in terms of how a data item was derived from its source. However, additional domain-specific details are often left to the application context.
Data provenance can be represented from two primary viewpoints, both of which are equivalent and convertible as needed:
- Provenance as Annotations on Data: This approach treats provenance as metadata—annotations describing the origin and production history of each data item. These annotations can be attached at the level of tuples or individual values.
- Provenance as a Graph of Data Relationships: Here, provenance is modeled as a (hyper)graph. Tuples act as vertices, while hyperedges connect source tuples to derived tuples, representing the direct derivations.
Both models are widely used, and their equivalence means that developers and researchers can switch between them to suit specific tasks. Provenance data serves multiple purposes in database management and analytics:
- Explanations: Helps users understand the origin and transformation of data, providing transparency.
- Quality Assessment: Assists in evaluating the reliability and quality of data sources.
- Source Influence: Tracks how different data sources affect one another, aiding in decision-making and source prioritization.
The interplay between data uncertainty, provenance, and cleaning is an active area of research. By leveraging provenance and user feedback, systems can better assess uncertainty and automate data-cleaning processes. This involves:
- Developing formalisms and data models to capture uncertainty semantics.
- Designing query primitives to propagate and manage uncertainty effectively during data transformations.
The Role of Crowdsourcing in Data Integration
Crowdsourcing offers a compelling solution for addressing some of the most challenging aspects of data integration. Tasks that are simple for humans but difficult for computers, such as understanding image contents or extracting meaningful information from web content, can be effectively outsourced to crowds. Platforms like Amazon Mechanical Turk exemplify how large groups of distributed individuals can collectively tackle these problems. Wikipedia, as another example, serves as a form of crowdsourced knowledge base, aggregating information from numerous anonymous contributors.
In the realm of data integration, crowdsourcing proves particularly valuable for tasks such as verifying schema mappings, validating record matches, and improving wrappers for extracting data from diverse formats. By leveraging the collective intelligence of humans, traditionally hard problems in data integration can be approached with greater efficiency and accuracy.
Building Large-Scale Structured Web Databases
The integration of heterogeneous data sources has paved the way for creating large-scale structured databases across diverse domains. Prominent examples include:
- Google Scholar, which aggregates bibliographic records to construct a comprehensive citation database encompassing millions of publications.
- Scientific Communities, such as physicists, who seek to consolidate experimental results into unified databases.
- Biomedical Researchers, who integrate resources like PubMed, clinical trial data, and grant information to establish databases that support medical advancements.
- Corporate Applications, where businesses compile product information for analysis, marketing, and search optimization.
Despite its potential, building these databases involves tackling significant challenges:
- Pre-Cleaning vs. Post-Cleaning: Should data be cleaned at the source level before integration, or should cleaning occur after schemas have been merged?
- Schema Merging: When source schemas are available, merging them requires reconciling structural and semantic differences.
- Entity Identification and Navigation: Integrated systems must manage entity identifiers and ensure seamless navigation, often without a uniform query language for manipulating objects.
- Incremental Updates: As new data sources emerge, systems must adapt incrementally, incorporating updates and leveraging human feedback to refine the integration process.
Lightweight Data Integration
Many integration scenarios are transient, requiring quick, ad-hoc solutions that can be executed by non-experts. A prime example occurs in disaster response, where data from multiple field reports must be integrated and verified to disseminate accurate information to the public. In such cases, lightweight data integration becomes indispensable.
Key Challenges of Lightweight Integration:
- Data Source Discovery: Quickly identifying relevant data sources amidst a flood of information is critical.
- Source Quality Assessment: Ensuring the credibility and reliability of data sources before integration.
- Semantic Clarity: Helping users understand the meaning and context of disparate data elements.
- Supportive Integration: Providing intuitive tools and methodologies that facilitate efficient data integration for users without technical expertise.
Machine learning plays a transformative role in lightweight integration. Techniques such as semi-supervised learning can amplify human efforts by combining small amounts of labeled data with large volumes of unlabeled data to train robust integration systems. This approach enables scalable, adaptive integration processes while reducing the burden on human contributors.
As the field of data integration evolves, the interplay between human intelligence and automated systems continues to grow in importance. Crowdsourcing provides the nuanced decision-making capabilities of humans, while machine learning offers scalability and speed. Together, they form a hybrid approach that addresses both the transient and large-scale challenges of integrating heterogeneous data sources. By refining methodologies and leveraging human feedback effectively, the future of data integration promises increased efficiency, accuracy, and adaptability.
In the digital world, the term mashup has become widely recognized as a method for integrating multiple components into a single application.
Definition
A mashup is essentially an application that combines two or more distinct components, which may include data sources, application logic, or user interfaces (UI). These components are often brought together to interact with each other, creating a more comprehensive and valuable experience.
Integration is the core value added by a mashup, as it connects disparate systems or services, enhancing the overall functionality and user experience.
Example
For example, housingmaps.com is a well-known mashup that integrates housing listings from Craigslist with geographical data from Google Maps. The platform allows users to explore housing offers on a map, providing synchronized data from these two sources. Here, the integration lies in the seamless presentation of data from Craigslist alongside interactive maps, which enhances the user’s ability to explore housing options.
Key Elements of a Mashup
- Mashup Components: These are the building blocks of any mashup. They can include data, application logic, or user interface elements. A mashup component is typically reusable and accessible either locally or remotely.
For example, Craigslist and Google Maps can both serve as mashup components in the housingmaps.com example, providing valuable content that can be integrated into an application.
- Mashup Logic: This refers to the internal workings of the mashup. It governs how the components are invoked, how data flows between them, how transformations occur, and how the user interface is structured. The mashup logic is what ties the components together, ensuring they work harmoniously within the integrated application.
The added value of a mashup comes from the integration itself—bringing together information, functions, or visualizations from different sources to create a cohesive user experience that wasn’t possible when the components were used separately.
The concept of a mashup can be defined in several ways, depending on the perspective:
- According to Abiteboul et al. (2008), mashups are “web-based resources consisting of dynamic networks of interacting components.” This definition emphasizes the dynamic and interactive nature of mashups, where various components work together in real-time.
- Ogrinz (2009) refers to mashups as “API enablers,” highlighting their role in creating an API when one does not exist. This enables the integration of different services that may not have been designed to work together initially.
- Yee (2008) describes mashups as “a combination of content from more than one source into an integrated experience.” This definition underscores the focus on combining diverse content to provide a unified and enriched experience for the user.
Types of Mashups
Mashups can be classified into four primary types based on the layer of the application they integrate:
- Data Mashups: These mashups fetch data from multiple sources, process the information, and then present an integrated result. The focus here is on data integration, ensuring that different datasets are combined in a meaningful way to create new insights or enhance existing ones.
- Logic Mashups: These mashups integrate functionalities provided by different logic or data components. For example, a mashup might take advantage of data processing logic from one system and combine it with business logic from another, creating a new service or capability.
- User Interface (UI) Mashups: UI mashups focus on combining the user interfaces of multiple components into a unified interface. The various UIs from different systems may be synchronized to allow users to interact with different services seamlessly within one cohesive interface.
- Hybrid Mashups: Hybrid mashups span across multiple layers of the application stack. They integrate components from the data layer, logic layer, and user interface layer, creating a rich and interconnected application. Integration occurs at more than one level, combining different types of mashup components to provide a more sophisticated solution.
Data Mashup vs. Data Integration
While both data mashups and data integration serve to combine disparate data sources, they differ significantly in their scope, complexity, and purpose.
Data mashups are a lightweight, web-based approach to data integration, designed to address very specific needs. They are typically used for quick, ad-hoc data analyses or reports that provide situational data for short-term needs. Unlike traditional data integration, which often involves more complex processes and aims to ensure consistency and thoroughness across systems, mashups focus on non-mission-critical tasks. For example, a mashup might be used to combine data from multiple sources to create a custom report for a specific event or to visualize data in a particular way, such as integrating a map with location data.
Mashups are particularly useful in situations where the goal is not long-term data consistency but rather immediate access to relevant information. They can handle the “long tail” of data integration requirements—those niche or specific needs that don’t justify the overhead of full-scale integration projects. This makes them ideal for scenarios where quick, low-cost, and non-critical integration is sufficient.
In contrast, data integration typically involves more structured processes and is often mission-critical, aiming to create a unified and consistent data model across multiple systems. Data integration is about ensuring the smooth flow of data between systems, often focusing on long-term data consistency and quality. It involves detailed processes for mapping, transforming, and cleaning data from various sources to create a cohesive data set that can support enterprise applications, analytics, or business operations.
Mashups in Relation to Other Integration Practices
Mashups introduce a form of integration primarily at the presentation layer. This means that mashups focus on combining various data and components in a way that enhances the user experience, often through visual or functional integration at the front end. Mashups generally deal with integrating data or services at the UI level, as opposed to more complex data integration solutions that work on the backend systems.
The focus of mashups is typically on non-mission-critical applications. For example, while data integration might be essential for maintaining a unified business database or supporting business intelligence operations, mashups are more concerned with creating lightweight solutions that meet immediate, often situational needs. This makes mashups ideal for applications like custom reports or integrating multiple data sources to visualize specific datasets without requiring long-term support or infrastructure.
Study on Mashup Practices
A study conducted on the large online repository of mashups published on programmableweb.com highlights the variability in how mashups are defined and used. The study found that 29% of the mashups analyzed used only one API—often a map—without truly integrating multiple components. This suggests that many so-called “mashups” are not complex enough to be considered true component-based applications or composite applications. For a mashup to be meaningful, it should integrate at least two different components in a way that creates added value for the user. Simply embedding a map to show an address, for instance, does not qualify as a mashup by the standards of this definition.
Mashups’ Positioning in the Context of Integration Practices
Mashups can be positioned within the broader landscape of integration practices. They sit between data integration and application integration, focusing on integration primarily at the presentation layer. While data integration handles the back-end processes necessary for unifying and processing data from various sources, and application integration coordinates and links the functional aspects of different applications, mashups address the user-facing layer. This is where data and functionality from disparate sources are combined in an intuitive and often real-time way to deliver an enhanced user experience.
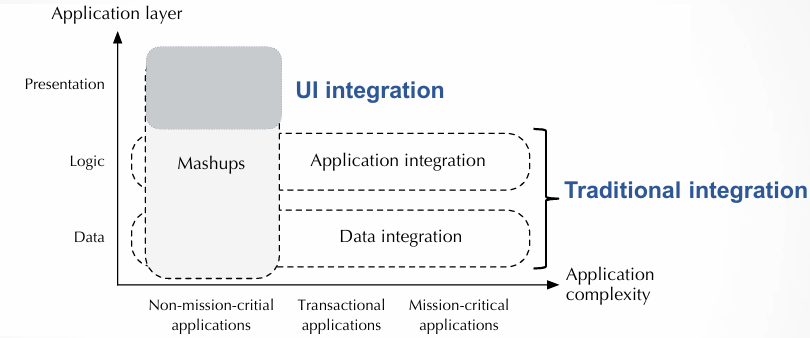
Mashups are positioned closer to data integration because they frequently involve combining data from various sources, but they differ in that they focus on simple, user-friendly integration at the presentation level, rather than the complex, back-end integration that traditional data integration practices typically require. Additionally, mashups tend to focus on non-mission-critical scenarios, such as ad-hoc reports or specific situational data needs, making them ideal for lightweight integration in dynamic and short-term contexts.
Pay-as-You-Go Data Management
Pay-as-you-go data management refers to an approach where data integration and management are done dynamically and on-demand, with minimal upfront investment. This contrasts with traditional data integration systems that require significant initial setup, such as creating a unified schema and describing the data sources.
In pay-as-you-go systems, the goal is to provide immediate and useful services across heterogeneous data sources, without the need for extensive preparation or a predefined structure.
This approach is particularly useful when integrating data from diverse and constantly changing sources, as it focuses on flexibility and efficiency, reducing the effort required to establish a centralized system before data can be accessed and analyzed.
Dataspaces
Dataspaces are an emerging concept designed to address the challenges of heterogeneous data integration in a pay-as-you-go model. Two basic principles underlie the dataspace approach:
-
Keyword Search and Visualization: Dataspaces enable users to search for data using keywords, similar to how search engines work, and provide effective data visualization tools. These allow users to interact with the data more intuitively without needing to know the underlying schema.
-
Enrichment with Automatic Techniques: Dataspaces can be enriched with techniques such as automatic schema matching, instance matching, and metadata extraction. These techniques help organize and relate data without requiring upfront schema design, enabling better interoperability between diverse data sources.
In practice, dataspace technologies aim to simplify data integration and access, allowing users to explore and analyze data in a more flexible, low-effort manner. They support schema mappings, reference reconciliation, and automatic data extraction to improve the usability and quality of the data.
Data Lakes
Data Lakes represent a practical application of dataspace principles, especially in environments dealing with large-scale and heterogeneous data sources. They offer a framework for managing massive volumes of data with diverse formats, which is essential for big data analytics.
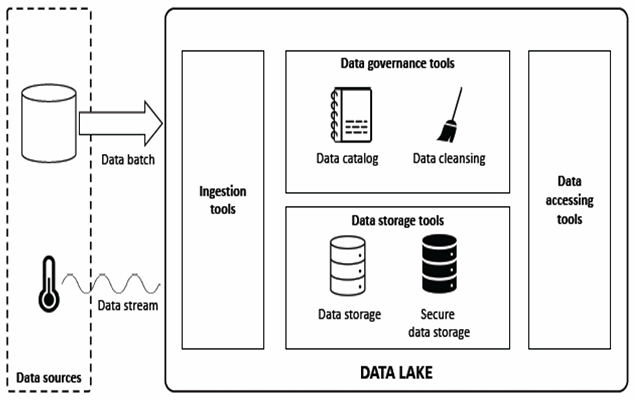
Key features and requirements for data lakes include:
- Handling Big Data: Data lakes are designed to manage vast amounts of data in various formats, including structured, semi-structured, and unstructured data.
- Self-Service Analytics: They provide an environment where analysts and data scientists can easily access and analyze data using advanced analytics, machine learning, and statistical tools.
- Connectivity and Integration: Data lakes must support the integration of diverse data sources, ensuring connectivity between the various systems involved.
- Scalability and Storage: Data lakes need robust storage solutions capable of handling large-scale data, including sensitive data, with proper security and privacy policies.
- Data Processing: They must support tools for data ingestion, processing, and analysis, such as data mining and machine learning.
Data Lake Minimal Toolset
To meet the requirements of managing and analyzing big data, data lakes require a specific set of tools and capabilities:
- Data Ingestion: Tools for loading data from various sources (batch or streaming). These tools are necessary to bring data into the lake from different data formats and sources.
- Data Governance: Tools to ensure data quality, security, and compliance. This includes maintaining a data catalog for tracking metadata, establishing data quality standards, and ensuring that privacy and security policies are followed.
- Data Storage: Systems designed for scalable, cost-effective storage of large volumes of data. This includes both traditional and more advanced storage solutions for sensitive data (e.g., encryption or compliance-focused storage systems).
- Data Access: Solutions to allow end-users, such as business analysts or data scientists, to query, retrieve, and interact with the data. This could include search tools, APIs, or user-friendly interfaces that facilitate exploration and analysis of the data stored in the lake.
To effectively implement and manage data lakes, several research challenges need to be addressed:
- Fast and Controlled Data Ingestion and Storage: The infrastructure must support the rapid ingestion of data from a variety of sources while ensuring that data is stored efficiently and securely.
- Data Reconciliation and Integration: Models and tools are needed to handle the merging and resolution of different data sources, ensuring consistency and compatibility between them.
- Data Catalogue for Search and Integration: A robust cataloging system must be developed to describe data sources, making it easier for users to search, explore, and integrate data across the lake. This involves capturing metadata and relationships between datasets.
- Security and Privacy Management: With large and often sensitive datasets, it is crucial to implement policies for managing security and privacy requirements, ensuring that data access and use comply with relevant standards and regulations.
Pay-as-You-Go Approach in Data Lakes
In a traditional data integration system, queries often require reformulation, which involves several steps:
- Identifying Necessary Datasets: The system first determines which datasets are needed to answer the query.
- Predicate Application: If multiple datasets are involved, the system determines which predicates (conditions) apply to specific datasets and which must be evaluated across all involved datasets.
- Combining Datasets: Predicates that span multiple datasets can only be evaluated when those datasets are properly combined.
However, in a data lake, the approach differs significantly:
- No Predefined Schema or Relationships: Unlike traditional systems that require the creation of a unified schema and permanent relationships, data lakes operate in a pay-as-you-go fashion. Instead of enforcing permanent links, temporary links based on metadata are used to handle queries dynamically.
- Temporary Links and Metadata: Rather than resolving and merging data sources upfront, the system relies on temporary metadata links, which are used to combine and query the data when needed. This allows for greater flexibility and minimizes the upfront effort required.
Basic Tools for Data Lakes
To support the pay-as-you-go model and enable effective management of data lakes, several basic tools are necessary:
- Keyword Search: Enabling users to search for data using keywords is a fundamental tool in a data lake. This search functionality allows users to explore data quickly without needing to know the specific structure or schema of the data.
- Effective Data Visualization: Coupled with keyword search, data visualization tools help users interpret and analyze the data in a more intuitive and meaningful way, particularly when dealing with large, complex datasets.
- Improving Metadata: As data lakes rely on metadata for linking and reconciling data, enhancing and maintaining high-quality metadata is crucial. This includes improving metadata for schema and instance validation, reference reconciliation, and ensuring that data from different sources can be combined meaningfully.
Addressing the Challenges in Data Lakes
How does the Data Lake ‘put together’ all the data related to a specific query?
A data lake handles the dynamic nature of data integration by relying on temporary metadata links rather than predefined schemas. When a query is submitted, the system utilizes the metadata to identify relevant datasets based on their content and characteristics. These datasets can then be combined on the fly to answer the query, even if they come from different sources or formats. The use of metadata allows the system to dynamically determine which datasets are needed, which predicates apply, and how to combine the data in real-time. This avoids the need for rigid upfront integration, offering a flexible and scalable approach to querying large and diverse data sources.
How do we compare data of any kind (e.g., text, images, time series, etc.) to derive similarities and differences?
- Text: Natural language text can be compared using semantic techniques such as ontologies (especially in specialized domains like health) or by using machine learning (ML) tools like word and sentence embeddings. These techniques help identify semantic similarities between text snippets by capturing contextual meaning beyond simple keyword matching.
- Images: For image comparison, the system can use keyword search based on image features or metadata to retrieve images with similar characteristics. Additionally, services that calculate image similarity based on content (e.g., comparing visual features) can be used.
- Time Series: Time series data can be compared by using specialized similarity measures (e.g., Dynamic Time Warping, correlation) that consider the temporal relationships in the data, identifying patterns or trends across different series.
In a data lake, these different data types can be linked and analyzed by leveraging their metadata and relevant similarity measures, creating a unified experience for querying and exploring data with varying formats and structures.
Data Catalogs and Metadata in Data Lakes
Data catalogs play a crucial role in managing a data lake’s contents. They serve as a centralized inventory that organizes and describes the data, making it easier for users to access, explore, and discover datasets. Some key functions of data catalogs include:
- Understanding Raw Data: Raw datasets may have strange field names, be unstructured, or semi-structured, making it difficult for users to interpret the data. A data catalog provides annotations that explain the content of the dataset, improving accessibility.
- Consistency Across Datasets: Different datasets may use different field names for the same data. A data catalog can standardize these field names using consistent business terms, making the data easier to compare and understand.
- Metadata: A data catalog contains important metadata, which provides detailed information about the datasets, such as:
- Content: Describes what the dataset represents and the types of data it contains.
- Quality: Information about the completeness, accuracy, and reliability of the data.
- Provenance: The history and origin of the data, helping users understand how and where it was collected.
- Trustworthiness: Indicates the credibility of the dataset, which is essential for users to assess its reliability for decision-making.
By organizing and annotating datasets in a catalog, data lakes enable users to search, query, and update data efficiently, even if the datasets come from heterogeneous sources and formats.
Metadata in Data Management
Metadata is essential for the efficient management and use of data in systems like data lakes, providing structure and context that make data discoverable, interpretable, and usable. The key types of metadata include:
-
Descriptive Metadata Describes the content of the data, answering questions like who created the data, what it is about, and what it includes. This metadata can be enhanced using semantic annotations, such as linking to knowledge graphs or ontologies, to provide additional context and meaning to the data.
-
Structural Metadata Provides information about how data elements are organized and their relationships. It explains how different parts of the data are connected or structured (e.g., hierarchical relationships, data formats, and relationships between tables).
-
Administrative Metadata Contains information about the data’s origin, its type, and access rights. This metadata helps manage and control access to the data, ensuring it is used properly. It also includes details on data ownership and access control policies.
-
Semantic Metadata Interprets the meaning of data through references to concepts, typically using ontologies or knowledge graphs. This type of metadata allows for semantic integration, enabling better understanding and use of the data by associating it with domain-specific terms.
Metadata can be classified into two broad categories based on the level of granularity:
- Technical Metadata: Refers to the profile of the dataset, including attributes, data types, statistical information, and other technical characteristics. It describes the structure of the data and how it can be processed or analyzed.
- Business Metadata: Provides a domain-aware description of the dataset, often tied to specific business processes or requirements. This helps to connect data to specific business needs, facilitating its use for decision-making.
Metadata for Quality and Trust in Data Sharing
For data sharing to be effective, it requires trust between parties. This trust is built through enriching the dataset descriptions with detailed metadata that highlights data quality and provenance:
- Descriptive and Administrative Metadata: Help track the origin and history of the data, providing transparency about who created the data, what operations were performed on it, and when. This allows data scientists to assess whether the data is trustworthy and reliable, ensuring proper data provenance.
- Structural and Semantic Metadata: Aid in data integration and assess the quality of data. The quality dimensions (completeness, consistency) can be included, and additional properties can identify errors or biases within datasets. However, these dimensions were initially designed for structured data, so there is a need to adapt them for different types, like text and images.
- Security and Privacy: Metadata should also describe the security and privacy requirements to ensure that data is handled according to the appropriate policies and regulations.
- Human-in-the-loop Tagging: Tagging data with relevant metadata should ideally involve human input, especially at the data ingestion stage, to improve accuracy and relevance.
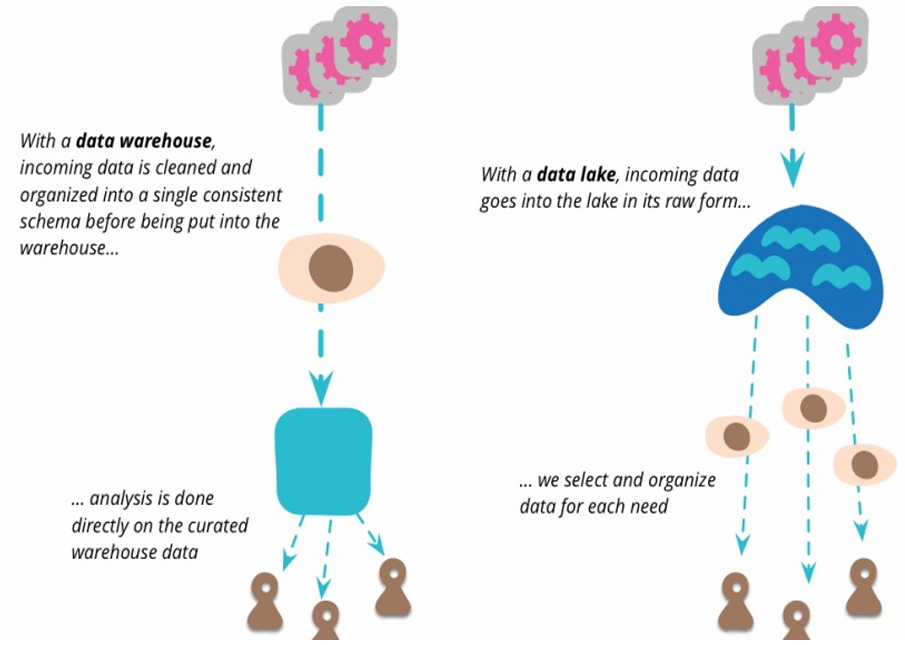
Data Warehouses vs. Data Lakes
Data warehouses and data lakes represent different approaches to managing large datasets, with key distinctions in terms of structure, data management, and integration:
Aspect Data Warehouse Data Lake Technology Usually relational DBMS Often HDFS/Hadoop Data Type Data of recognized high value Candidate data of potential value Data Format Aggregated data Detailed source data Data Conformity Data conforms to enterprise standards Fidelity to original format (transformed on demand) Data Entities Known entities Raw material (metadata to discover entities) Data Integration Data integration up front Data integration on demand Schema Schema on write Schema on read Key Differences:
Data Warehouse: Typically uses structured data that has already been cleaned, transformed, and aggregated to fit within a predefined schema. Data integration is done up front, ensuring it conforms to enterprise standards.
Data Lake: Stores raw, unstructured data and applies transformation and integration processes only when needed (on demand). This approach retains the original format and is more flexible, accommodating large volumes of diverse data sources and types.
Data Lake Federation: Node Level and Federation Level
Data Lake Federation is an architecture that connects multiple data lakes or repositories, allowing for decentralized data storage and access while ensuring that data can be shared securely and efficiently.
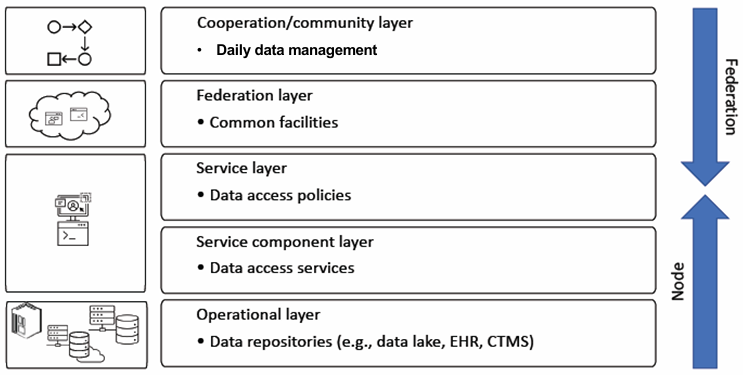
At the Node Level, each organization or data repository has its own data lake or storage solution. This layer supports the different systems and services required for data management and access:
- Operational Layer: This represents the data repositories deployed either on-premises or in the cloud, possibly in the form of a data lake or another organizational storage system. It may also involve hybrid solutions where data is spread across various platforms.
- Service Component Layer: This layer is responsible for exposing the datasets from the node to other systems. It offers different types of services depending on the data and the node’s configuration. Examples of services could include simple FTP connections or more sophisticated REST APIs.
- Service Layer (Middle Layer): This layer handles the policies governing access to the data exposed through the services. It ensures that access control is properly enforced, specifying who can access what data and under which conditions. Additionally, it may define transformations to be applied to the data, such as anonymization, before it is made available to the requester.
At the Federation Level, the goal is to create an ecosystem where data from multiple nodes can be shared, integrated, and accessed efficiently.
- Federation Layer: This layer facilitates infrastructure and application services that allow different nodes in the federation to communicate and share data. It helps establish a community cloud where nodes can temporarily store data to improve performance or share resources. Additionally, it includes a distributed monitoring system to ensure that data-sharing policies are being adhered to and that access controls are respected.
- Cooperation/Community Layer: This layer provides the tools necessary for managing operations that span across multiple nodes, where data may reside on more than one node. It allows for the management of multi-centric operations, enabling seamless data sharing and collaboration across different data sources.
Service Metadata: Creating a Service Catalog
In the context of data lake federation, Service Metadata plays a crucial role in defining and managing the services that expose data from different nodes. A service catalog is needed to maintain metadata about each service, enabling users to understand its functionality and access rules. Key aspects of Service Metadata include:
- Descriptive and Administrative Metadata: Metadata that describes who created the service, what it does, and what types of data and formats it supports. It also includes rights information, such as who can access the service and under what conditions.
- Computation Metadata: This metadata adds information about the computations and analyses supported by the service. It may include details on the types of data analysis available and how these analyses can be executed. This helps determine if the analysis should occur locally at the requesting node or remotely on another node.
The challenge in data lake federation is to identify a minimal yet sufficient set of computation-related metadata that allows the system to make decisions about how and where to execute data analysis, including considerations for code mobility and resource allocation.
Infrastructure for Data Lakes and Analysis
The infrastructure required for handling large-scale data can be divided into several components, each serving a specific function. Depending on the type of data and the processing needs, computational resources may need either CPU or GPU support. CPU resources are typically sufficient for handling general-purpose tasks, while GPUs are designed for parallel processing and are essential for handling complex computations such as those required in machine learning, image processing, and other data-intensive tasks. The choice between CPU and GPU depends largely on the nature of the data and the computational demands of the analysis.
Another critical component of the data infrastructure is storage. The data should be organized into two categories: Hot Storage and Cold Storage. Hot Storage is used for data that requires quick access, often in real-time or near-real-time scenarios, such as data that is actively being used for analytics or user-facing applications. This storage is typically implemented using high-performance systems like Solid-State Drives (SSDs) to facilitate fast data retrieval. On the other hand, Cold Storage is designed for less frequently accessed data, such as archived datasets. It is typically slower and more cost-effective than Hot Storage, often using cheaper storage technologies like hard disk drives (HDDs) or cloud-based storage solutions.
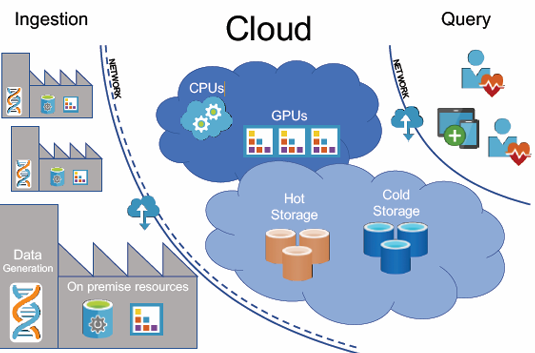
Data analysis can be performed in two main environments: on-premises or on the cloud. On-premises infrastructure refers to the organization’s own servers and storage systems, typically housed in data centers. While on-premises systems offer full control over the infrastructure, they also require significant upfront investment and maintenance. In contrast, cloud computing offers scalability, flexibility, and cost-effectiveness. Cloud-based analysis allows for the rapid provisioning of computational resources, which is especially beneficial when dealing with large datasets or fluctuating processing demands.
The network infrastructure is another vital component, supporting the ingestion and querying of data. Data ingestion refers to the process of transferring data into the system, which often requires large amounts of bandwidth and storage capacity. Querying, on the other hand, involves retrieving data from storage for analysis, which also requires a fast and reliable network to ensure performance. In many cases, the resources required for data ingestion far exceed those needed for querying, as the former involves the large-scale transfer of data from various sources into the system.
Collaborative Data Management
In the realm of data management, many individuals are attempting to access the same data sources and perform similar tasks. For example, when someone extracts a structured dataset (such as from an Excel file or database) from semi-structured data, it indicates that the data is relatively easy to structure. This process often involves copying column names and organizing the data into a more usable format. Similarly, when two datasets are manually combined, it may suggest that they are related and should be integrated, such as by performing a join on columns that are similar in both datasets. These activities are not only common but can be automated or assisted through cloud-based tools for data management.
Cloud-based platforms offer significant advantages in this context, as they allow the logging of user activities. By tracking the actions performed by many users on the same datasets, it becomes possible to identify common patterns and best practices, making data management more efficient. However, this also raises concerns regarding privacy, as tracking user activity may involve sensitive data. Care must be taken to ensure that privacy is maintained, and that data is handled in compliance with relevant regulations.
Visualization of Integrated Data
As datasets are integrated from multiple sources, visualizing the data can provide valuable insights into the relationships between the data elements. Rather than presenting users with an overwhelming number of rows and columns, visualization helps to highlight important patterns and discrepancies between datasets. For example, during the integration process, discrepancies in how data is structured or reconciled can be immediately identified, allowing for quicker resolution. This is especially useful when working with large, complex datasets, as it enables analysts to focus on the most relevant aspects of the data.
During integration, it can also be helpful to display a subset of the data that has not been reconciled correctly. This allows users to investigate specific issues and make adjustments before proceeding with the full integration process. Additionally, when browsing through different datasets to be integrated, visualizing search results and their relevance to the specific integration task can enhance the decision-making process.
Another crucial aspect of data visualization is the representation of data provenance, or the history of how a particular dataset has been modified or transformed over time. By visualizing data provenance, users can trace the lineage of the data, which adds a layer of transparency and trust to the process. This is particularly important in environments where data integrity and accuracy are critical, such as in scientific research or regulatory compliance.
Challenges in Integrating Social Media Data
Integrating data from social media platforms presents unique challenges due to the nature of the data itself. Social media data is often noisy, meaning it contains a significant amount of irrelevant or low-quality information, such as spam or meaningless posts. Additionally, social media data is transient, with user behaviors and trends changing rapidly. This makes it difficult to maintain the relevance of data over time, as older posts may lose their significance, and new ones may emerge as more important.
Another challenge is that social media data often lacks context. Posts on platforms like Twitter, Facebook, or Instagram may be short and may not provide enough information to understand the full meaning behind them. As a result, interpreting social media data can be difficult without additional context, such as user metadata or external sources of information.
Furthermore, social media platforms generate vast amounts of data in real time. This high-speed, continuous stream of data requires fast processing capabilities, as traditional methods may not be able to keep up with the volume and velocity of incoming information. To address these challenges, specialized tools and technologies are required to process and analyze social media data effectively.
Cluster- and Cloud-Based Parallel Processing
Many traditional query engines, schema matchers, and data storage systems were developed with the assumption that they would operate on a single server or a limited number of servers. However, the scale of modern data processing often exceeds the capabilities of these single-server systems. As a result, algorithms and systems need to be redesigned to operate in a parallelized and scalable manner, leveraging the power of large clusters and cloud-based infrastructure.
For tasks like schema matching, entity resolution, data cleaning, and indexing, traditional approaches are based on the assumption of limited scale, often relying on main memory or small datasets. To handle larger datasets, these algorithms must be adapted to run efficiently on distributed systems, such as those found in cloud computing environments. This often involves breaking down tasks into smaller sub-tasks that can be processed concurrently across multiple nodes in a cluster.
By exploiting the power of large clusters, data processing tasks can be completed much more quickly, allowing organizations to scale their operations without being constrained by the limitations of individual servers. However, redesigning existing systems to work in parallel requires careful consideration of factors such as data partitioning, load balancing, and fault tolerance to ensure optimal performance across the distributed system.
In conclusion, the infrastructure needed for modern data management and analysis is complex and multi-faceted, requiring a combination of computational resources, storage systems, and network infrastructure. Effective data management also requires the integration of various data sources, which can be facilitated through visualization techniques and collaborative tools. However, the process comes with challenges, especially when dealing with noisy, transient data sources like social media. To address these challenges, data systems must be redesigned to leverage the capabilities of cloud-based clusters and parallel processing.