In the realm of data management, semistructured data occupies a unique position. Unlike traditional data formats that exhibit a high degree of structure and uniformity, semistructured data possesses a flexible organization that allows for variability in its format. This flexibility makes it less prescriptive and regular, enabling it to adapt to diverse data sources and structures. Examples of semistructured data include web data, which often contains a mix of structured and unstructured information, XML data that provides a framework for encoding documents in a format that is both human-readable and machine-readable, and data that results from the integration of heterogeneous sources. This adaptability is particularly valuable in environments where data sources are not uniform, as it allows for more versatile data handling and processing.
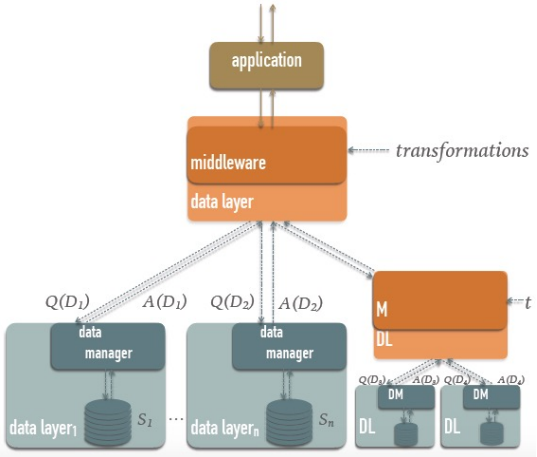
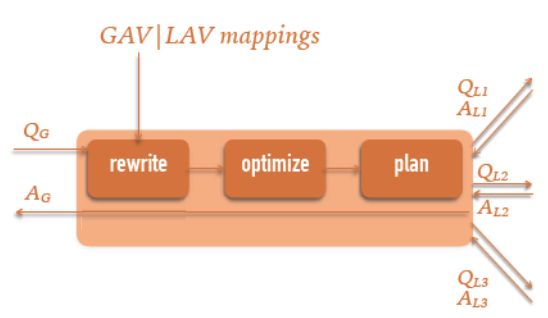
A critical aspect of effective data integration lies in the implementation of middleware, which serves as a bridge between various data sources and the applications that utilize this data. Middleware plays several vital roles in this integration process. First, it is responsible for rewriting queries through the use of LAV (Local-As-View) and GAV (Global-As-View) mappings. These mappings provide a means to translate queries from one data representation to another, ensuring that the queries are reformulated into a language that can be comprehended by the target system.
In addition to query rewriting, middleware also optimizes queries, aiming to enhance performance by reducing the time and resources required for execution. This optimization process involves analyzing the structure of the queries, identifying potential redundancies, and employing strategies to streamline execution. Finally, middleware undertakes the crucial task of planning the execution of these queries. This involves determining the most efficient order of operations, allocating resources, and ensuring that the integration process runs smoothly, even when dealing with diverse and potentially incompatible data sources.
Semistructured Data Models
Semistructured data models represent a flexible approach to organizing data, accommodating a variety of structures that may not conform to traditional relational database systems. These models can be visualized in different ways, notably through trees or graphs, which may consist of labeled nodes, labeled arcs, or both. The use of these structures allows for the representation of irregular data in a more intuitive manner, providing clarity in the relationships and hierarchies that exist within the data.
graph TD
PROF1[Professor]
PROF2[Professor]
PROF1 -- Name --> NAME -- Last Name --> KING((King))
PROF1 -- Age --> 37((37))
PROF1 -- Teaches --> COURSE -- Course Name --> DATABASES((Databases))
PROF2 -- Teaches --> COURSE
PROF2 -- Age --> YEARS --> 45((45))
PROF2 -.- ANN[AND NO NAME?]
NOTE
Semistructured data models exhibit significant variability, which can complicate efforts toward data integration.
Unlike well-defined schemas found in structured data models, the lack of uniformity in semistructured data makes it challenging to seamlessly combine or compare different datasets. This diversity requires specialized methods and tools for effective integration, as conventional integration techniques may not be applicable.
A prime example of a semistructured data model is XML. XML enables the representation of data in a hierarchical structure, where elements can have attributes and nested elements, allowing for a flexible encoding of information. This capability to express complex data structures makes XML a popular choice for data interchange between disparate systems, even though it introduces challenges related to schema validation and data compatibility.
In the realm of graph databases, Neo4j stands out as a widely used graph-based data model. It employs a graph structure where data is represented as nodes (entities) and relationships (edges) that connect these nodes. This model excels in representing interconnected data and can efficiently handle complex queries that involve relationships between various entities. Neo4j’s graph-based architecture facilitates the exploration of intricate data networks, making it particularly suitable for applications in social networks, recommendation systems, and knowledge graphs.
Information Search in Semistructured Databases
In the context of semistructured databases, the goal is to enable the integration, querying, and comparison of data from diverse structures as if they were uniformly structured. Achieving this requires a flexible approach, as the varying formats and schemas of semistructured data present significant challenges. An effective strategy involves progressively constructing an overarching data representation while systematically discovering and exploring new information sources. This iterative process allows for a more comprehensive understanding of the available data, enhancing the ability to draw insights and make informed decisions.
Mediators
Mediators play a crucial role in facilitating the integration of semistructured data. Their functions mirror those of traditional integration systems, yet the complexity of dealing with semistructured data necessitates more sophisticated approaches. The simple Global-As-View (GAV) and Local-As-View (LAV) mappings, which are often employed in structured data environments, are not sufficient on their own. Instead, mediators must incorporate additional capabilities to address the challenges presented by the inherent variability of semistructured data.
The term “mediation” encompasses several key components. First, it includes the processing required to ensure that various interfaces operate seamlessly together. This involves establishing connections and protocols that facilitate communication among different data sources, regardless of their underlying structures. Secondly, mediators rely on knowledge structures that guide the transformations necessary to convert raw data into usable information. These structures help define how data should be interpreted, processed, and represented within the context of specific applications or queries.
Additionally, intermediaries may require temporary storage solutions to hold data during the transformation and integration process. This intermediate storage is essential for managing data as it flows from disparate sources, allowing mediators to manipulate and prepare it for final use.
A significant challenge in mediation arises from the need for domain-specific mediators. Each distinct domain possesses its own semantics, requiring mediators to be specifically designed to understand and process the nuances of that domain’s data. This specificity is crucial for ensuring accurate interpretations and effective data handling, as generalized solutions may fall short in addressing the unique characteristics of various data types and sources.
TSIMM
One of the pioneering systems that embody the mediator/wrapper paradigm is the TSIMMIS (The Stanford University Integrated Media Information System), which emerged in the 1990s at Stanford University. TSIMMIS represents a significant advancement in the integration of semistructured data, providing a framework that facilitates the interaction between various data sources while allowing for the inherent flexibility of semistructured formats.
TSIMMIS operates through a mediator-based architecture that employs the Object Exchange Model (OEM) for representing data. In this system, wrappers are utilized to perform model-to-model translations, ensuring that queries posed to the mediator can be accurately interpreted and processed. The queries in TSIMMIS are expressed using the LOREL language, a lightweight object repository language specifically designed to cater to the needs of semistructured data. Importantly, the mediator possesses knowledge of the semantics related to the application domain, which is critical for understanding the context and meaning of the data it processes.
The Object Exchange Model is a graph-based data representation that diverges from traditional schema-based models. Instead of focusing on a predefined schema, OEM directly represents the data itself, allowing for a self-descriptive approach. An example of this representation is:
<temp-in-farenheit, int, 80>
This format demonstrates how the data is encapsulated in a way that conveys both the type and the value without being constrained by a rigid schema. The structure of an object in the OEM can be denoted as <(Object-id), label, type, value>, showcasing its capability to represent complex information in a flexible manner. The architecture of the TSIMMIS system can be visualized as follows:
In this diagram, various applications (APP1, APP2) interact with their respective mediators (MED1, MED2). Each mediator employs multiple wrappers to access different types of data sources, which can include traditional relational databases (RDBMS), XML documents, and web-based data. This architecture illustrates the flexibility and extensibility of the TSIMMIS system, highlighting its capability to integrate and manage diverse data sources effectively.
Integrating semistructured or unstructured data introduces several complexities, primarily due to the need for specialized mediators tailored to specific domains. Each mediator must possess an understanding of domain metadata to accurately convey the semantics of the data it handles. This includes challenges such as online duplicate recognition, reconciliation, and removal, which are essential for maintaining data integrity and consistency.
Moreover, the dynamic nature of data sources poses additional challenges. If a data source undergoes even minor changes, the corresponding wrapper must be adjusted accordingly. This highlights the necessity for automatic wrapper generation to minimize the manual effort required for adaptation. Such automation would enhance the system’s responsiveness to changes in data sources and improve overall efficiency.
LOREL Language
The query language employed by TSIMMIS is LOREL, which is characterized as a lightweight object repository language. LOREL is object-based and draws similarities to object-oriented query languages while incorporating modifications suitable for semistructured data environments. For instance, a query seeking books authored by “Aho” can be articulated in LOREL as follows:
However, a notable challenge arises when this query needs to be generated at runtime, particularly in the absence of a predefined schema. The question then becomes how the user or the system can ascertain the existence of specific nodes, such as “library,” which contains nodes like “book,” with fields such as “author” and “title.” To address this challenge, the authors of TSIMMIS introduced the concept of the Dataguide, an a posteriori schema that is progressively constructed by the mediator as it explores available data sources. This approach allows for a dynamic understanding of the data landscape, enabling users to query effectively even in the absence of a fixed schema.
Wrapper
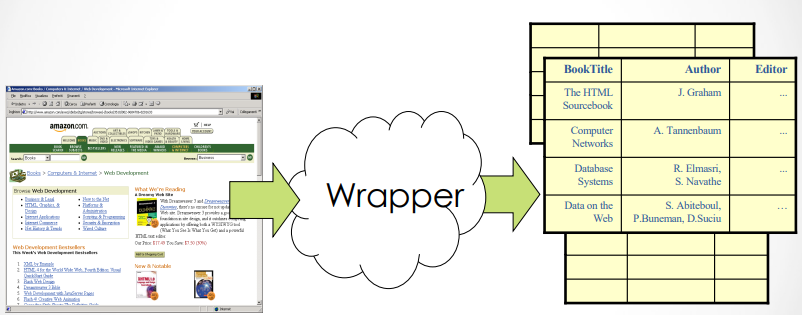
A wrapper is a critical software module designed to facilitate the extraction and transformation of data from various sources. Its primary function is to convert incoming queries into a format that is comprehensible to specific data sources, enabling effective communication between disparate systems. Additionally, wrappers extend the querying capabilities of data sources, allowing for more sophisticated interactions. Once the data has been retrieved, wrappers also play a pivotal role in transforming the query results from the source’s format into a structure that is understandable and usable by the application, whether that be a relational table, XML, or JSON.
When it comes to extracting information from web pages, wrappers are particularly valuable. The process of information extraction from HTML documents involves several key considerations. The source format typically consists of plain text interspersed with HTML tags, which lack inherent semantics. This makes it challenging to extract meaningful data directly from the raw HTML.
The goal is to convert this unstructured or semi-structured data into a more structured format, such as a relational table (which may be nested in accordance with the rules of the Second Normal Form, NF²), XML, or JSON.
By doing so, we effectively add structure and semantics to the data, allowing for easier analysis and manipulation.
The extraction process becomes significantly more manageable if the underlying page structure is derived from a database. When web pages are dynamically generated from a database, the layout is more consistent, making it easier for wrappers to define extraction rules that can be applied uniformly across similar pages.
However, a significant challenge in this context is the frequent changes that occur on websites. Web pages can be updated or redesigned at any time, and even minor layout changes can disrupt existing extraction rules, rendering them ineffective. The human-based maintenance of ad-hoc wrappers can be prohibitively expensive and time-consuming. Consequently, there is a pressing need for automatic wrapper generation, which can alleviate some of the burdens associated with maintaining these wrappers manually.
Automatic wrapper generation is feasible only when the web pages exhibit a certain degree of regularity. For instance, if multiple pages share the same structural characteristics (often the case when they are generated dynamically from a database) it becomes significantly easier to create wrappers that can adapt to these patterns. This regularity is especially common in data-intensive websites, where large volumes of data are presented in a consistent format across different pages.
In scenarios where such structure is prevalent, automatic wrapper generation can streamline the extraction process, significantly reducing the manual effort required to maintain wrappers as website layouts change. This not only improves efficiency but also enhances the robustness of data extraction processes, allowing applications to reliably access and utilize the data they need from a variety of web sources.
Ontology
Ontologies are fundamental in the domain of data management, providing a structured framework that formalizes knowledge representation. Essentially, an ontology acts as a detailed model defining the concepts, relationships, and constraints within a specific area of interest. This formalization captures the semantics of the domain, which in turn enhances the integration, querying, and analysis of data. By establishing a common understanding of the domain’s structure and meaning, ontologies facilitate effective communication and interoperability across different systems and applications.
Definition
The ontology itself can be represented as , where:
denotes the ontology as a whole,
encompasses the concepts defined within the ontology,
represents the relationships that connect these concepts,
signifies the instances or individuals within the ontology.
denotes the axioms that specify the logical constraints and rules governing the ontology.
In more technical terms, an ontology consists of two primary components:
T-Box (Theory Box): This part includes the definitions of concepts and roles within the domain. It also encompasses all the axioms that form the logical theory, specifying how concepts relate to each other (e.g., “A father is a man with a child”).
A-Box: The A-Box contains the basic assertions or ground facts of the logical theory. It describes the instances of concepts and their specific relationships (e.g., stating “Tom is a father” as Father(Tom)). This component is crucial for populating the ontology with real-world data and instances.
The structured nature of ontologies not only organizes information but also supports reasoning and inference tasks within the domain. By formally defining concepts and relationships, ontologies enable automated systems to interpret and process data more effectively. They play a pivotal role in various fields including artificial intelligence, semantic web technologies, and information retrieval, where precise knowledge representation is essential for accurate analysis and decision-making.
OpenCyc
OpenCyc is the open-source iteration of the Cyc project, which was initiated in July 1984 by Douglas Lenat at the Microelectronics and Computer Technology Corporation (MCC), a research consortium established by two American corporations. The primary goal of this initiative was to create a comprehensive ontology and knowledge base that could empower AI systems to emulate human-like reasoning and understanding.
For many years, OpenCyc was available under an open-source (Apache) license, providing access to a subset of the Cyc knowledge base. This allowed developers and researchers to use its extensive ontology for various AI applications, fostering innovation and experimentation in the field.
In addition to OpenCyc, the Cyc project introduced ResearchCyc, which offered a more comprehensive version of the Cyc knowledge base under a research-purpose license. This version supported academic and scientific research, enabling deeper exploration of AI concepts and methodologies in knowledge representation and reasoning.
The Cyc ontology is vast, containing hundreds of thousands of terms and millions of assertions. This extensive network covers all aspects of human consensus reality, making it a valuable resource for AI systems aiming to achieve human-like understanding and reasoning. Cyc’s comprehensive framework provides a foundational knowledge base for building sophisticated AI applications capable of complex reasoning tasks.
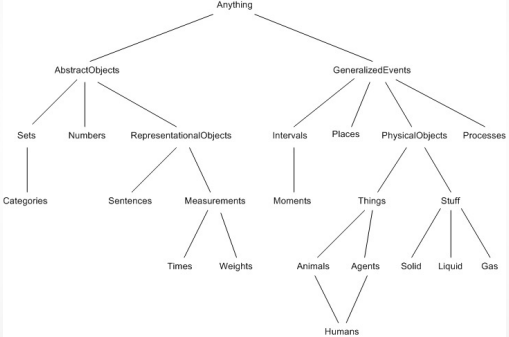
Russel and Norvig’s ontology is a comprehensive knowledge base that covers a wide range of topics in artificial intelligence. At the top level, the ontology is organized into several key categories, each representing a distinct domain of knowledge. These categories serve as high-level concepts that encapsulate various subdomains and topics within the field of AI. By structuring the ontology in this hierarchical manner, Russel and Norvig provide a systematic framework for organizing and navigating the vast array of knowledge encompassed by the ontology.
Semantic Interoperability and the Semantic Web
The concept of semantic interoperability and the Semantic Web envisions a future where the Web’s information has explicit, machine-understandable meaning. This would enable the automatic processing and seamless integration of data by machines, allowing for more efficient communication and collaboration between platforms, systems, and applications.
The goal is to create a highly interconnected and intelligent web in which data flows freely, enhancing both human and machine interaction with information.
At the core of this vision are technologies like XML and RDF (Resource Description Framework). XML allows for the definition of customized tagging schemes, providing a structured way to encode documents, while RDF represents a flexible framework to describe complex relationships between pieces of data. Together, they enable a “web of data” where relationships are as important as the data itself, allowing for richer interconnection and interpretation of information.
RDF operates by organizing data into triples, where each triple consists of a , , and . This framework supports the representation of relationships between data points in a way that is both simple and powerful, laying the foundation for further enhancements in data modeling and machine reasoning.
OWL (Web Ontology Language) builds on RDF to offer more advanced capabilities for describing and reasoning about data. While RDF Schema provides basic semantics for defining simple relationships, OWL enables more sophisticated data modeling by allowing developers to specify constraints, hierarchies, and rules within the data. This added expressiveness makes OWL particularly useful for creating complex ontologies that support reasoning tasks such as classification, inference, and consistency checking, allowing machines to derive new insights from existing information.
Moreover, various implementations of RDF, such as Turtle, provide alternative syntaxes for working with RDF data, offering users flexibility in how they choose to represent and manipulate their datasets. This flexibility helps ensure that different communities and applications can adopt semantic web technologies in a manner that suits their specific needs.
Linked Data: Expanding Connectivity
Linked Data is a significant subset of the Semantic Web movement, designed to connect datasets across the web, making data more accessible and interrelated. It describes a method for publishing structured data in such a way that different datasets can be linked to one another, creating an interconnected and integrated web of information. Linked Data uses established Web standards like HTTP, RDF, and URIs (Uniform Resource Identifiers) to enable data from different sources to be connected and queried automatically by machines.
The vision of Linked Data, promoted by Tim Berners-Lee, is to add deeper meaning to the Web by making the relationships between data more explicit. By allowing machines to interpret these connections, Linked Data makes web-based information more useful for a range of applications, including artificial intelligence, data integration, and knowledge discovery.
Open Data refers to data published on the Web that is freely available to anyone. This initiative promotes transparency and accessibility, allowing anyone to use and build upon the data without restrictions, thus fostering innovation and collaboration across industries. Open Data drives a culture of sharing that not only benefits the academic and research communities but also contributes to societal advancements in areas like governance, education, and environmental sustainability.
Linked Open Data extends this concept further by linking open datasets in a manner consistent with Linked Data principles. By publishing datasets as RDF on the Web and establishing RDF links among them, Linked Open Data creates a rich “data commons.” This interconnected web of open datasets provides a wealth of information that is both freely accessible and highly usable, unlocking new opportunities for research, development, and the creation of intelligent applications.
The Linked Open Data Cloud Diagram visualizes the connections between various datasets published as Linked Open Data. These interconnected datasets span multiple domains, including geographic information, cultural heritage, scientific research, and government data. The power of the Linked Open Data Cloud lies in its ability to provide structured, interconnected information that can be used by both machines and humans for a wide range of purposes.
Notable Datasets
CKAN – A registry of open data and content packages maintained by the Open Knowledge Foundation. CKAN helps organizations manage and publish data, making it easier to discover and share datasets.
DBpedia – A dataset containing data extracted from Wikipedia. It provides structured information about more than 5 million concepts described by billions of RDF triples, including abstracts in multiple languages, making it a valuable resource for querying and research.
GeoNames – This dataset offers RDF descriptions of over 8 million geographical features worldwide, serving as a rich resource for geographic and spatial data integration.
YAGO – A large, open-source knowledge base developed at the Max Planck Institute for Computer Science. YAGO automatically extracts information from Wikipedia and other sources, creating a growing ontology that connects millions of entities.
UMBEL – A lightweight reference structure composed of 20,000 subject concept classes and their relationships. Derived from OpenCyc, UMBEL connects to over 1.5 million named entities from DBpedia and YAGO, enabling cross-domain data integration.
FOAF (Friend of a Friend) – A dataset describing people, their properties, and relationships, which is used to build social networks and connect personal data across the web.
RDF and the Semantic Web
The Resource Description Framework (RDF) is at the heart of the Semantic Web, providing a structured way to describe resources and their relationships. At its core, RDF represents information using a triple structure composed of a , , and . These triples form a graph, where:
: Represents a resource or node in the graph.
: Denotes the relationship (edge) between two nodes.
: Can either be another resource or a literal value (such as a string, number, or date).
An RDF file encodes these relationships, typically using a variety of syntaxes like RDF/XML or Turtle. For instance, the following RDF sample encodes information about John, Mary, and their child:
:John a :Man ; :name "John" ; :hasSpouse :Mary .:Mary a :Woman ; :name "Mary" ; :hasSpouse :John .:John_jr a :Man ; :name "John Jr." ; :hasParent :John, :Mary .:Time_Span a owl:Class .:event a :Activity ; :has_time_span [ a :Time_Span ; :at_some_time_within "2018-01-12"^^xsd:date ].:u129u-klejkajo-2309124u-sajfl a :Person ; :name "John Doe" .
This structure reveals the ability of RDF to represent complex relationships between individuals and concepts, such as family relationships and temporal events, as well as literal values like names and dates.
RDF serves as a foundational data model for representing knowledge. It describes the relationships between resources using a flexible format that can be serialized in XML or Turtle, among others. RDF is used to build a network of interconnected data, which can be queried and analyzed by machines. However, RDF by itself has limited expressiveness for specifying more intricate relationships, constraints, or rules about the data. This is where OWL (Web Ontology Language) comes into play.
OWL extends RDF by introducing additional expressive capabilities. While RDF Schema allows for the definition of basic relationships and hierarchies, OWL provides richer semantics that enable more complex reasoning about data. For instance, OWL supports:
Disjointness: Allows for specifying that certain classes cannot have any members in common (e.g., “a car is not a bicycle”).
Cardinality constraints: Restrict the number of instances that can participate in a particular relationship (e.g., “a person can have exactly two biological parents”).
Symmetry and transitivity: Define specific properties of relationships, such as making a relationship symmetrical (if is related to , then is related to ).
OWL provides three sublanguages, each with increasing levels of expressiveness:
OWL Lite: A simpler version, suitable for lightweight applications that require basic classification and hierarchy creation.
OWL DL: Offers more expressiveness while retaining computational completeness and decidability. It is designed for use cases requiring reasoning and consistency checking.
OWL Full: The most expressive version, allowing full use of RDF and OWL constructs, though it sacrifices computational guarantees like decidability.
RDF and OWL in Practice
Consider an RDF/XML document that uses OWL to describe an ontology for a tourism domain:
<?xml version="1.0"?><rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns:dc="http://purl.org/dc/elements/1.1/" xml:base="http://eng.it/ontology/tourism"> <owl:Ontology rdf:about=""/> <owl:Class rdf:ID="Church"> <rdfs:comment rdf:datatype="http://www.w3.org/2001/XMLSchema#string"> Definition: Edificio sacro in cui si svolgono pubblicamente gli atti di culto delle religioni cristiane. </rdfs:comment> </owl:Class> <owl:Class rdf:ID="Theatre"> <rdfs:comment rdf:datatype="http://www.w3.org/2001/XMLSchema#string"> Definition: A building where theatrical performances or motion-picture shows can be presented. </rdfs:comment> </owl:Class> <owl:Class rdf:ID="DailyCityTransportationTicket"> <rdfs:subClassOf rdf:resource="#CityTransportationTicket"/> <rdfs:comment rdf:datatype="http://www.w3.org/2001/XMLSchema#string"> Definition: A ticket allowing unlimited travel on public transportation within a city for 24 hours. </rdfs:comment> </owl:Class></rdf:RDF>
This RDF document demonstrates how OWL can be used to define complex relationships and constraints within an ontology. For instance, it defines classes like Church and Theatre, each with associated comments providing definitions. The class DailyCityTransportationTicket is also defined as a subclass of CityTransportationTicket, illustrating how OWL allows for rich hierarchical relationships.
Reasoning is a core feature of OWL ontologies, providing the ability to infer new knowledge from existing data. OWL supports various reasoning services through TBox and ABox operations:
Service
Description
Tbox Services
Subsumption
Verifies if a concept subsumes (is a subconcept of) another concept
Consistency
Verifies that there exists at least one interpretation I which satisfies the given Tbox
Local Satisfiability
Verifies, for a given concept , that there exists at least one interpretation in which is true
Abox Services
Consistency
Verifies that an Abox is consistent with respect to a given Tbox
Instance Checking
Verifies if a given individual belongs to a particular concept
Instance Retrieval
Returns the extension of a given concept , that is, the set of individuals belonging to
Comparison: Ontologies vs. Relational Databases
Descriptive ontologies and relational databases have distinct strengths and limitations, primarily due to the different goals they are designed to achieve. Below is a detailed comparison of their features and differences:
Feature
Ontologies
Relational Databases (DBs)
Flexibility and Expressiveness
Highly expressive, representing complex relationships, constraints, and concepts beyond simple data storage. Supports the Open World Assumption (OWA), meaning that if something is not explicitly stated, it is assumed to be unknown rather than false.
Structured data with predefined schemas (tables, columns) ensuring data integrity and consistency. Operates under the Closed World Assumption (CWA), where any data not explicitly stored is assumed to be false.
Generalization and Specialization
Allows for complex hierarchical relationships, such as subclassing (generalization/specialization), where one concept can inherit properties from another.
Can represent hierarchical data through techniques like foreign keys, but lacks the depth and flexibility of ontological generalization/specialization.
Reasoning Capabilities
Comes with built-in reasoning mechanisms, such as inferencing, consistency checking, and instance classification, allowing for rich semantic interpretation of data.
Lacks built-in reasoning services and requires additional layers or rules engines to perform logic-based inference.
Handling Incomplete Data
Manages and reasons with incomplete information under the OWA, essential in dynamic domains where all data may not be available.
Handling missing or incomplete data often requires explicit NULL values or the use of outer joins, making it less flexible than ontologies in representing evolving information.
Complex Structures
Supports intricate data structures, allowing relationships and properties to be described in detail.
Efficiently handles large volumes of structured data and supports powerful query languages like SQL for fast data retrieval.
Instance Management
Efficiently manages instances with built-in reasoning capabilities.
Offers efficient mechanisms for handling millions of instances (rows) of data.
ER Diagrams vs. Ontologies
Entity-Relationship (ER) diagrams, which form the basis for database schema design, are more restricted in the kinds of relationships they can model compared to ontologies:
Feature
Ontology
ER Diagram/DB
Complex Data Structures
Yes
Limited (Tables)
Generalization/Specialization
Yes
Yes (but less flexible)
Defined Concepts
Yes
No (attributes only)
Reasoning Mechanisms
Yes
No
Closed/Open World Assumptions
OWA
CWA
Inference Capabilities
Yes
No
An ER schema, which maps entities and relationships, does not explicitly manage values or the semantic meaning of the relationships it defines, unlike ontologies, which have mechanisms to handle these concepts.
Key Differences
Ontology
Database (DB)
Data Representation
Uses triples (subject-predicate-object) to represent relationships and facts, allowing for flexible, web-like structures.
Uses tables and columns to represent data, optimized for querying through SQL but less flexible in representing relationships.
Reasoning and Inference
Supports reasoning services like subsumption, instance checking, and automatic classification of data based on logic and rules.
Lacks built-in reasoning services and requires additional layers or rules engines to perform logic-based inference.
Handling Missing Data
Works under the Open World Assumption (OWA), allowing for reasoning over incomplete data.
Operates under the Closed World Assumption (CWA), where missing data is considered as false, limiting flexibility in dynamic and evolving data environments.
DBs vs. Ontologies: Bridging the Gap
To align databases more closely with ontologies:
Incorporating Defined Concepts: Databases need support for defined concepts and relationships similar to those in ontologies, which would involve adding semantics to the data.
Reasoning Mechanisms: Databases should integrate reasoning capabilities for automatic inference and validation of complex relationships, which can enable more sophisticated querying and decision-making.
Adapting to Open World Assumption: To align with ontology-based reasoning, databases must move beyond the CWA, allowing for the representation and processing of incomplete or evolving information. This would enable more flexibility in scenarios where data is uncertain or growing over time.
Ontologies and Integration Challenges
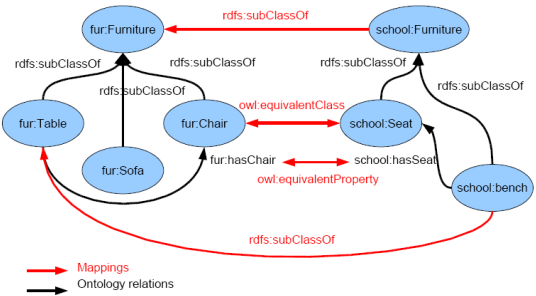
When integrating data across multiple ontologies, one of the most significant issues is resolving equivalent concepts. This process, known as ontology mapping, involves aligning concepts from different ontologies that may refer to the same or similar entities in different domains or systems. The following steps are critical in this process:
Identifying Equivalent Concepts (Ontology Mapping):
The first challenge is discovering concepts from different ontologies that are equivalent or similar in meaning. This could involve identifying two concepts that represent the same real-world entity but are named or structured differently. For instance, one ontology might describe a “Person” entity, while another refers to it as an “Individual.” These concepts might need to be mapped based on semantic similarity.
Representing Mappings:
Once equivalent concepts are identified, the next step is to represent these mappings in a structured, machine-readable format. This formal representation often uses a specialized language, such as OWL or RDF Schema. These mappings could be expressed through specific alignment relations, such as:
Equivalent class (e.g., Person ≡ Individual)
Subclass relations (e.g., Student ⊑ Person)
Property equivalence (e.g., hasName ≡ fullName)
These mappings are essential for enabling systems to interpret data from different ontologies as being equivalent or related, facilitating data integration.
Reasoning on Mappings:
Once mappings are in place, systems need to reason over these mappings to support query answering and knowledge discovery. This means that if one ontology describes a “Person” and another describes an “Individual,” a query about “Persons” should also return information about “Individuals” based on the established mapping. Reasoning tasks may include:
Query Rewriting: Adapting a query to take into account equivalent concepts from different ontologies.
Inference: Drawing new conclusions based on the mapped concepts, such as inferring that all “Students” are “Persons” if the appropriate subclass relationship is defined.
Ontology Matching
Ontology matching is the process of determining correspondences between entities (e.g., concepts, properties) from different ontologies. This process is crucial for integrating data from multiple sources and involves several steps:
Matching Operators:
Ontology matching uses various matching operators to evaluate the potential equivalence of resources between ontologies. These operators consider factors such as labels, structure, data types, and other attributes.
Similarity Measures:
A core aspect of ontology matching is the use of similarity measures to evaluate the degree of similarity between two resources. This measure is often a numerical value between 0 (no similarity) and 1 (the concepts are fully equivalent).
These measures may be based on various factors, such as lexical similarity (similarity of terms or labels), structural similarity (how concepts are organized within the ontologies), and semantic similarity (meaning and context).
Semantic Similarity:
Ontology matching goes beyond lexical matching (i.e., comparing the names or labels of concepts). It incorporates the semantic context of the entities being matched. This is crucial because two concepts might have different labels but refer to the same underlying entity or class.
Example
For example, in one ontology, the concept of “Car” may be labeled as “Automobile” in another. A semantic similarity measure considers that, despite the lexical differences, these terms refer to the same entity in the real world.
The typical workflow for ontology matching involves:
Preprocessing: This stage involves preparing the ontologies, which might include normalizing labels, handling synonyms, and aligning structures to ease comparison.
Similarity Computation: Using a combination of lexical, structural, and semantic methods, the system computes the similarity between entities.
Matching Selection: Based on the computed similarity scores, the system identifies which pairs of entities from different ontologies should be mapped as equivalent or related.
Post-processing and Validation: Human or automated checks are applied to validate the accuracy of the matching results, and adjustments are made if needed.
More on Similarity
Similarity is a fundamental concept in human cognition, playing a crucial role in taxonomy, recognition, case-based reasoning, and many other fields. Despite its importance, many aspects of similarity have proven difficult to formalize. According to Zadeh, the “inventor” of fuzzy sets and fuzzy logic,
Quote
“Formulation of a valid, general-purpose definition of similarity is a challenging problem.”
Nevertheless, numerous special-purpose definitions have been successfully employed in cluster analysis, search, classification, recognition, and diagnostics. Self-identity is the property which says that the distance between identical objects is zero.
Axiom
This translates to the following self-identity axiom:
For all in , .
For all and in , if , then : Positivity is the property which says that distinct objects have a nonzero distance
For all and in , : Symmetry says that the order of two elements does not matter for the distance between them
For all , , and in , : The triangle inequality says that the distance between and does not exceed the sum of the distance between and and the distance between and
While dealing with distance-based similarity measures, examples have been constructed where every distance axiom is clearly violated by dissimilarity measures, and particularly the triangle inequality, consequently the corresponding similarity measure disobeys transitivity. For these cases, a different attitude has been taken, and more general concepts of distance have been proposed: a distinction is made between perceived dissimilarity and judged dissimilarity.
Ontology Mapping and Integration Challenges
Ontology mapping is essential for integrating multiple information sources with distinct ontological structures. By relating concepts from different sources through equivalence or order relations, ontology mapping enables meaningful data integration and advanced reasoning capabilities across disparate datasets. However, integrating ontologies is complex due to mismatches at various levels.
Definition Language Level Mismatches:
Syntax: Different ontology languages may have varying syntax, complicating the direct integration of data or concepts.
Construct Availability: Some languages may provide constructs like part-of or synonym relationships, while others may not, leading to inconsistencies.
Semantics of Linguistic Primitives: The meaning of key terms, such as the union or intersection of multiple intervals, can vary between languages, causing mismatches.
Normalization, where ontologies are translated into a common language or paradigm, can help address these inconsistencies.
Ontology-Level Mismatches:
Scope: Classes in different ontologies might represent the same concept but have varying instances.
Model Coverage and Granularity: The level of detail in how different ontologies cover the same domain may vary.
Paradigm: Different ontologies may use different models to represent concepts like time (e.g., continuous intervals versus discrete sets of points).
Encoding: Information might be encoded differently across ontologies.
Concept Description: Variations in how classes are distinguished, such as whether to use a qualifying attribute or introduce a separate class.
Homonymies and Synonymies: Ontologies may use the same term for different concepts (homonymy) or different terms for the same concept (synonymy).
To overcome these issues, ontologies can support schema integration by serving as a unifying semantic layer. They provide insights into similarities between elements of different schemas or datasets, both at the schema and instance levels.
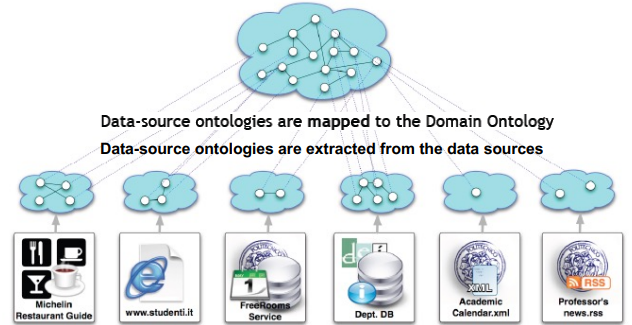
How Ontologies Support Integration
Ontologies play a crucial role in data integration by providing a semantic framework that enhances the interoperability of disparate data sources. Here’s how they achieve this:
Schema Integration Support: Ontologies can function as tools for schema integration by:
Representing Semantics: They capture the meaning of schema elements, which is vital for understanding the context and relationships among data entities.
Conflict Resolution: By identifying similarities between source ontologies at both the schema and instance levels, ontologies assist in resolving conflicts that arise when integrating different data sources. This includes:
Schema Level: Mapping similar concepts across different schemas.
Instance Level: Implementing record linkage to connect data entities that represent the same real-world object.
Replacing Global Schema: Instead of relying on traditional schema integration techniques, ontologies can be utilized to completely replace a global schema. In this approach:
Ontology Mapping and Merging: Rather than combining schemas directly, the focus is on mapping and merging different ontologies. This process involves aligning concepts and relations from various ontologies into a coherent integrated ontology.
Integrated Ontology as Schema: The resulting integrated ontology serves as the schema for querying. This allows for more dynamic and flexible data integration, as the ontology can adapt to changes in underlying data sources without needing significant structural changes.
Addressing Data-Source Heterogeneity: Ontologies are particularly effective in handling data-source heterogeneity through:
Semantic Extraction: By extracting the semantics of data into an ontological format (potentially at runtime), ontologies facilitate a common understanding of diverse data sources. This extraction can occur dynamically, accommodating changes in data structure or content.
Automatic Wrapping and Query Transition: The integration process often involves the use of automatic wrapper generators that translate data between different models. This is a challenging task due to:
Impedance Mismatch: This occurs when the data model of the database differs from that of the programming language being used (e.g., object-oriented vs. relational models). Ontologies help bridge this gap by providing a shared semantic framework that both models can reference.
Unstructured Data Sources: Integrating unstructured data (e.g., text, images) into a structured framework can be particularly complex. Ontologies can assist in wrapping this content, making it accessible for queries and analysis.
Content Interpretation and Mediation
Content Interpretation and Wrapping: Ontologies can support the interpretation of diverse content types, such as HTML pages, by wrapping this content in a structured format that reflects its semantics. This enables better retrieval and manipulation of data.
Mediation Support: They can also act as mediation tools for detecting and resolving content inconsistencies, aiding in processes such as record linkage and data fusion. By providing a unified view of the data, ontologies help ensure that integrated information is accurate and reliable.
Ontology Query Processing
Once ontologies are integrated, they require efficient query languages to retrieve and reason about the data they contain. Query languages for ontologies support:
Schema Exploration: Allowing users to explore the structure of the ontology.
Reasoning on the Schema: Enabling inference over the ontology, such as deriving new knowledge based on the relationships within the schema.
Instance Querying: Facilitating queries on instances (e.g., individuals, projects) contained within the ontology.
SPARQL (SPARQL Protocol and RDF Query Language) is a widely-used query language for ontologies, designed to query data stored in RDF format.
Example
A simple SPARQL query example that retrieves all projects involving PhD students:
A more complex query that retrieves both PhD students and professors, along with their projects:
SELECT ?X ?YWHERE { { ?X rdf:type PhDStudent. UNION ?X rdf:type Professor. } AND ?X inProject ?Y. }
Differences Between Ontology Query Processing and Database Query Processing
Query Transformation: Queries written for ontologies need to be translated into the language used by underlying data sources (e.g., SQL for relational databases) and vice versa.
Handling of Semantics: Traditional databases operate under the Closed World Assumption (CWA), where missing information is assumed false. Ontologies, however, use the Open World Assumption (OWA), allowing for incomplete information. Query processing must account for these differing assumptions.
Location of Processing: Deciding whether to push the query processing to the relational database or to perform it within the ontology layer. For performance reasons, relational operators can be processed within the relational engine, while ontology-specific reasoning might take place within the ontology layer.