Definition
A Fraud is:
- a wrongful or criminal deception intended to result in financial or personal gain
- an uncommon, well-considered, imperceptibly concealed, time-evolving and often carefully organized crime which appears in many types of forms.
- a social phenomenon
The main characteristics of fraud are as follows:
- Uncommon: Fraud cases are relatively rare compared to legitimate cases. Only a minority of cases involve fraud, and even among those, only a limited number are known to be fraudulent. This rarity makes it challenging to detect fraud, as fraudulent cases can easily blend in with legitimate ones. Furthermore, the limited number of known examples makes it difficult to learn from historical cases and develop effective fraud detection methods.
- Well-considered and imperceptibly concealed: Fraudsters are meticulous in their planning and execution of fraudulent activities. They strive to remain unnoticed and blend in with non-fraudsters, behaving in a way that does not raise suspicion. They carefully conceal their actions, making it difficult for fraud detection systems to identify their fraudulent activities. Fraud is not impulsive or unplanned; it is a calculated and deliberate act.
- Time-evolving: Fraud detection systems continuously improve and learn from past examples to enhance their effectiveness. However, fraudsters are not idle either. They constantly adapt and refine their methods to stay one step ahead of fraud detection mechanisms. This constant evolution of fraud techniques creates a cat-and-mouse game between fraudsters and those trying to detect and prevent fraud.
- Carefully organized crime: Fraud is not an isolated event carried out by individuals acting alone. It often involves complex and organized structures, with multiple individuals working together to perpetrate fraudulent activities. These organized networks make it even more challenging to detect and investigate fraud cases. To effectively detect fraud, it is crucial to consider the broader context and connections within which the fraudulent activities occur.
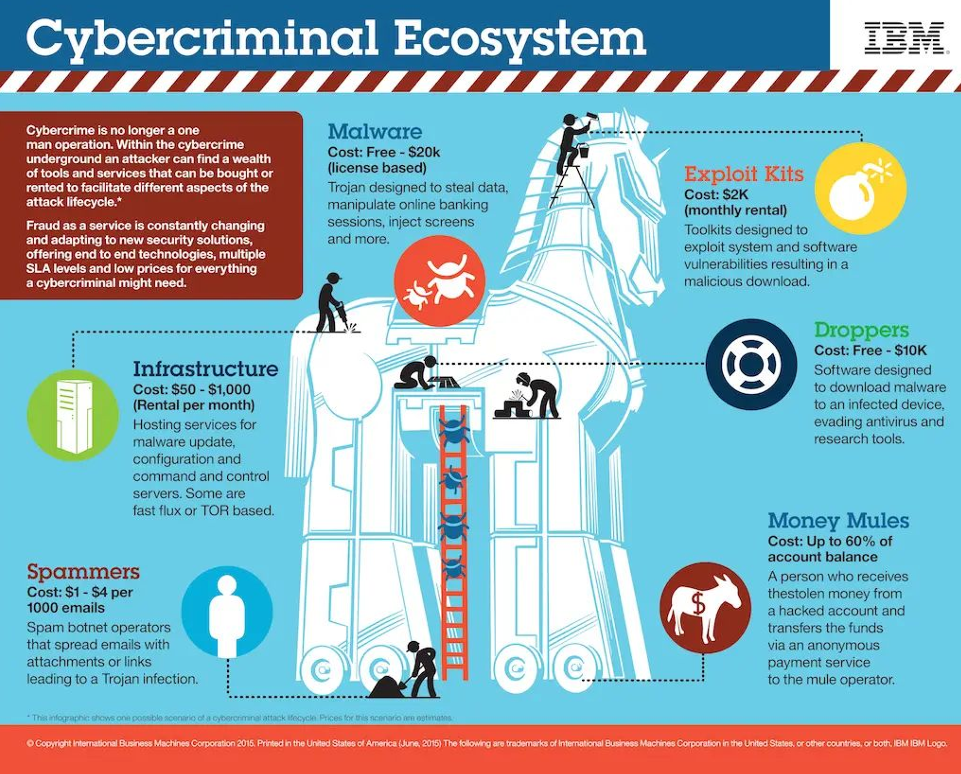
The motivation behind engaging in fraudulent activities is often driven by the potential for financial gain or other benefits. To better understand the factors that contribute to an individual’s decision to commit fraud, we can turn to the fraud triangle. The fraud triangle is a fundamental conceptual model that outlines the key elements that explain the drivers behind fraudulent behavior. By examining these factors, we can gain insights into the psychological and situational aspects that influence individuals to engage in deceptive and unlawful practices.
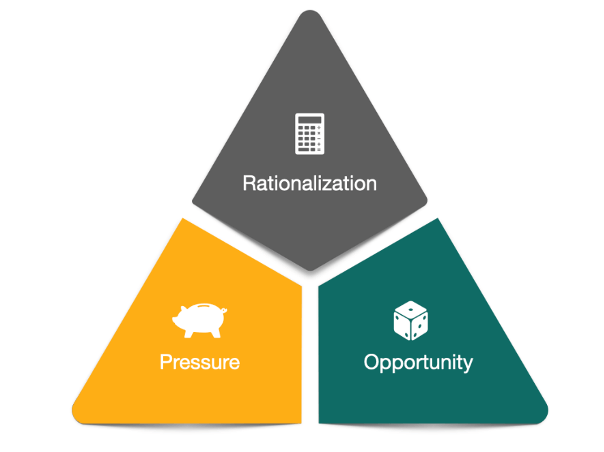
Fraud has a significant impact on organizations and economies worldwide. On average, a typical organization loses 5% of its revenues to fraud each year. In the United States, the total cost of insurance fraud is estimated to exceed $40 billion annually, while in the United Kingdom, fraud costs reach £73 billion per year. Additionally, credit card companies experience losses of approximately seven cents for every hundred dollars of transactions due to fraud. Clearly, fraud is a costly problem that demands attention and effective measures to combat it.
Fraud Categories
Fraud can be classified in various ways, depending on the context and perspective.
- Banking and Credit Card Fraud: Unauthorized use of another’s credit, including:
- Application Fraud: Using false personal information to obtain new credit cards and quickly maxing them out.
- Behavioral Fraud: Fraudulently obtaining details of legitimate cards, which does not require stealing the physical card, only its credentials.
- Insurance Fraud: Fraud related to insurance, which can involve either the seller or the buyer: Selling policies from non-existent companies, creating more commissions through policy churning, exaggerated claims (property), falsified medical history (health), postdated policies, and faked damage (automobile).
- Corruption: Misuse of entrusted power for private gain, including subtypes such as:
- Bribery: Offering or receiving any item of value to influence an individual in a public or legal duty.
- Embezzlement: Misappropriating money or property entrusted to one’s care.
- Extortion: Using coercion to obtain money, property, or services.
- Favoritism: Unfair preferential treatment to a person or group.
- Nepotism: Favoring relatives or personal friends.
- Counterfeit: Imitations passed off as genuine, often involving valuable items like credit cards, identity cards, popular products, and money.
- Product Warranty Fraud: Fraudulently claiming compensation based on a product warranty, which is a manufacturer’s guarantee of the product’s condition and terms for repair or exchange if it fails to function as described.
- Healthcare Fraud: Filing dishonest healthcare claims for profit, including:
- Fraud by Providers: Billing for services not rendered, unnecessary services, or higher-level services than provided; misrepresenting non-covered treatments as necessary; upcoding, and unbundling.
- Fraud by Consumers: Using another person’s insurance card or falsifying medical history.
- Telecommunications Fraud: Theft or misuse of telecommunication services to commit other frauds, including:
- Cloning Fraud: Cloning a phone number and call credit.
- Superimposition Fraud: Adding fraudulent usage to a legitimate account.
- Money Laundering: Converting large amounts of money from criminal activities into legitimate sources. It is a significant global issue, with the U.S. seeing an estimated $300 billion in gains from it.
- Click Fraud: Illegally increasing the number of clicks on a website’s ads to boost payable clicks to the advertiser, performed either:
- Manually: Individuals clicking on ads without intent to purchase.
- Automated: Computer programs clicking on ads without intent to purchase.
- Identity Theft: Stealing someone’s personal or financial information to assume their identity for transactions or purchases, often by sifting through trash for bank statements or accessing databases to steal customer information.
- Tax Evasion: Illegally failing to pay owed taxes, such as knowingly underreporting income.
- Plagiarism: Stealing and passing off another’s ideas or words as one’s own, using another’s work without crediting the source, and presenting it as new and original. This involves both theft of work and deception.
Social Engineering
Quote
- Social engineering uses influence and persuasion to deceive people by convincing them that the social engineer is someone he is not, or by manipulation. As a result, the social engineer is able to take advantage of people to obtain information with or without the use of technology.
- The art, or better yet, science, of skillfully maneuvering human beings to take action in some aspect of their lives.
Social engineering is a method of manipulating individuals to obtain sensitive information by posing as a trustworthy entity. It exploits human vulnerabilities, as technology vulnerabilities become more difficult to exploit. Human error cannot be fixed with patches, making social engineering a consistently successful tactic for stealing valuable information from multiple sources.
Quote
You could spend a fortune purchasing technology and services from every exhibitor, speaker, and sponsor at the RSA Conference, and your network infrastructure could still remain vulnerable to old-fashioned manipulation.
Social engineering is a deceptive tactic employed by fraudsters to manipulate individuals and exploit their vulnerabilities in order to obtain sensitive information or gain unauthorized access to systems. This method is chosen by criminals because it offers the path of least resistance. Instead of spending hours, days, or even weeks trying to crack complex passwords or bypass sophisticated security measures, they simply ask for the information they need.
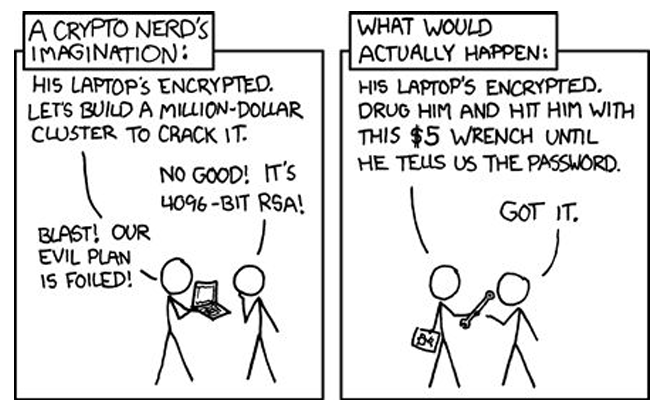
One of the main reasons social engineering is so effective is because people are the weakest link in any security chain. No matter how advanced or robust the technology may be, it cannot prevent social engineering attacks. This is because social engineering preys on human psychology and exploits our natural tendencies to trust and help others. Moreover, there is no patch or software update that can fix human stupidity. Even the most well-designed security systems can be easily bypassed if an individual falls victim to social engineering tactics. Fraudsters capitalize on this fact and use various techniques such as impersonation, manipulation, and psychological manipulation to deceive their targets.
By posing as a trustworthy entity or using persuasive tactics, fraudsters are able to convince individuals to disclose sensitive information, such as passwords, credit card details, or personal identification numbers (PINs). They may also trick people into clicking on malicious links or downloading malware, which can lead to unauthorized access to systems or the theft of valuable data.
It is important to recognize the threat posed by social engineering and take proactive measures to protect ourselves and our organizations. This includes raising awareness about common social engineering techniques, implementing strong security protocols, and educating individuals about the importance of skepticism and verifying the legitimacy of requests before sharing sensitive information.
In conclusion, social engineering is a preferred method for fraudsters due to its effectiveness and the inherent vulnerabilities of human nature. It serves as a reminder that no matter how advanced our technology becomes, we must always remain vigilant and skeptical to protect ourselves from falling victim to these deceptive tactics.
Phishing
Definition
Phishing refers to the fraudulent practice of trying to obtain sensitive information by pretending to be a reliable source in electronic communications.
The Nigerian Prince Scam
The Nigerian Prince Scam is a classic example of an advance-fee fraud scheme that has been around for decades. It typically starts with an email or letter from someone claiming to be a wealthy Nigerian prince or government official.
The scammer presents a compelling story, stating that they have a large sum of money trapped in a foreign bank account and need the victim’s help to access it. They promise to share a portion of the funds with the victim as a reward for their assistance. To gain the victim’s trust, the scammer may provide official-looking documents, such as bank statements or legal agreements. They may also use persuasive language and emotional appeals to create a sense of urgency and desperation. Once the victim expresses interest, the scammer will gradually introduce various obstacles and complications that require financial assistance to overcome. These can include legal fees, bribes, or unexpected taxes. Each time the victim pays, the scammer promises that the funds will be released soon. However, the requests for money continue indefinitely, with the scammer always finding new reasons why the funds cannot be accessed. The victim may be led to believe that they are on the verge of receiving a substantial sum of money, but in reality, they are being manipulated and deceived.
The Nigerian Prince Scam preys on the victim’s greed and desire for easy money. It exploits their willingness to believe in the possibility of a lucrative opportunity, despite the numerous red flags and warning signs. It is important to be cautious and skeptical when receiving unsolicited emails or letters promising large sums of money. Legitimate financial transactions do not require upfront payments or personal financial information from strangers.
Vishing
Vishing (or Voice-Phishing) is a criminal practice that uses social engineering techniques through the telephone system to obtain access to personal and private financial information from the public, with the goal of gaining financial profit. This type of fraud exploits the trust of individuals to obtain credit card information, passwords, and other sensitive information. Vishing perpetrators often impersonate representatives of legitimate institutions, such as banks or government entities, to deceive victims and convince them to provide their personal information.
Anti-Fraud Strategy
Implementing advanced anti-fraud mechanisms can help reduce losses caused by fraud. By preventing and detecting fraudulent activities, we can discourage fraudsters from targeting our systems. It is important to remember that fraudsters, like other criminals, are opportunistic and will seek out easier targets if they encounter strong anti-fraud measures.
Definitions
- Fraud Detection: recognize or discover fraudulent activities (Ex-post approach)
- Fraud Prevention: avoid or reduce fraud (Ex-ante approach)
The two approaches are complementary but not independent. The more effective the prevention mechanism, the less detection power is needed, and vice versa. The more effective the detection system, the less prevention power is needed.
flowchart TB A[Prevention mechanism] B[Detection System] C[Fraudsters adapt and<br>change their behavior] D[Impact detection power] E[Impact prevention power] A --> C B --> C D --> C E --> C E --> A D --> B
Banking Fraud Detection/Prevention
The detection section of the system plays a crucial role in ensuring the security and trustworthiness of financial services. It begins with the collection of raw transaction data, including user IDs, amounts, timestamps, and IBANs. This data is then aggregated to create comprehensive profiles that capture important metrics such as the number of transactions in a day or week and the total amount transacted. Using machine learning techniques, a classifier analyzes these aggregated profiles to identify patterns and anomalies that may indicate fraudulent activity. Based on the classifier’s analysis, transactions are categorized as either legitimate or fraudulent, and the results are communicated back to the financial institution for appropriate action.
On the other hand, the prevention section focuses on securing user authentication and protecting against various threats that could compromise the integrity of financial services. One key aspect of prevention is authentication, where users are required to authenticate themselves using tokens through devices like smartphones or computers. This process ensures secure access and verifies user identities before any financial transaction can be initiated. Additionally, the prevention section addresses specific fraud threats such as social engineering (phishing), credentials database theft, and malware (banking trojans). By implementing measures to mitigate these threats, the prevention section aims to safeguard user authentication and prevent unauthorized access to financial services.
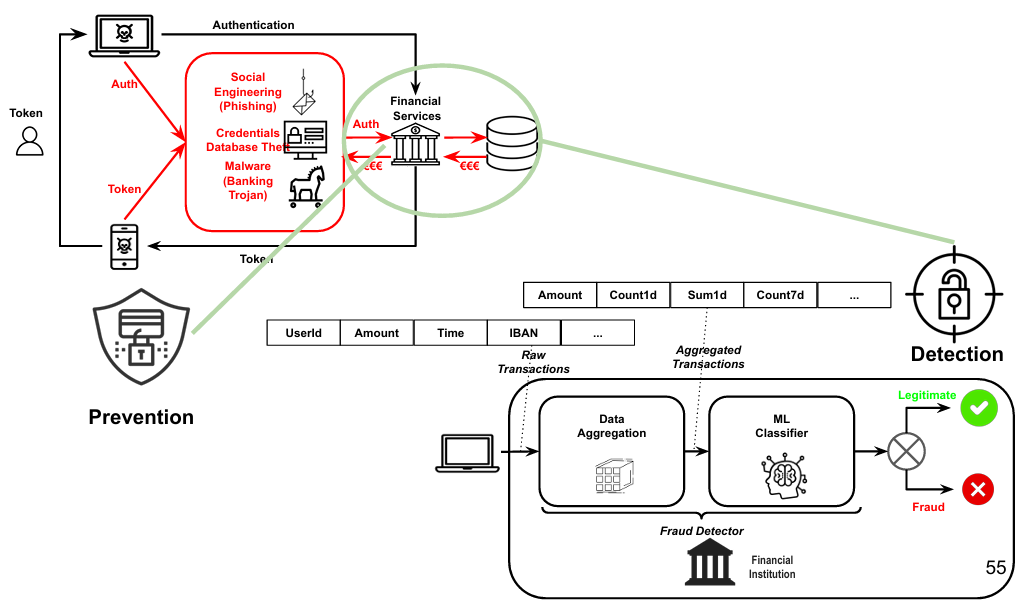
By combining effective detection and prevention strategies, financial institutions can maintain the security and trustworthiness of their services, protecting both themselves and their customers from fraudulent activities.
Fraud Detection Approach: A Three-Tiered Framework
Fraud detection can be effectively managed through a three-tiered approach, each level offering a different perspective on identifying and preventing fraudulent activities:
- Individual Profile Analysis: This method focuses on the specific spending behaviors of individual users. By examining a user’s historical transaction data, this approach establishes a baseline of what constitutes typical behavior for that particular user. New transactions are then compared against this baseline to detect anomalies. For instance, if a user who normally makes small, local purchases suddenly makes a large international transaction, this could trigger an alert for further investigation. This level of detail helps in identifying fraud that deviates from established personal spending patterns.
- Group Profile Analysis: This level extends the analysis to patterns observed across a group of users. By analyzing the common spending behaviors within a cohort of users, this approach helps mitigate issues related to insufficient training data for fraud detection models. For example, if a new transaction pattern is detected among multiple users, it may indicate a emerging fraudulent scheme that affects several accounts. Group profiles help in recognizing trends and anomalies that are not apparent when looking at individual profiles alone.
- Temporal Profile Analysis: This technique focuses on the timing and frequency of transactions. It is particularly useful for identifying sophisticated fraud attempts that involve repeating transactions that, on their own, might appear legitimate. For instance, a fraudster might perform small transactions over a long period to avoid detection. By analyzing the temporal patterns of transactions, this approach can flag suspicious activities that occur in a certain temporal sequence or frequency, indicating a potential fraudulent pattern that would be difficult to detect through individual or group profiles alone.
By employing these three levels of analysis—individual, group, and temporal profiles—fraud detection systems can offer a more comprehensive approach, improving the accuracy and effectiveness of fraud prevention measures. Each level provides a different lens through which transaction data can be scrutinized, addressing various types of fraudulent behavior and enhancing overall detection capabilities.
Fraud Prevention: What is Strong Customer Authentication?
A new regulatory requirement in Europe aims to enhance online payment security and reduce fraud. To comply with Strong Customer Authentication (SCA) standards, it is necessary to incorporate additional authentication measures into the checkout process. SCA mandates the use of at least two out of three authentication elements:
- Something the customer knows (e.g., password or PIN)
- Something the customer has (e.g., phone or hardware token)
- Something the customer is (e.g., fingerprint or face recognition)
Traditional technologies used for fraud prevention include:
- One-time password generators: These devices combine a private key and a counter synchronized with the host. The client generates a password by encrypting the counter with the private key, while the host decrypts the password using the public key. The counter is checked to ensure it matches the expected value, and it changes every 30-60 seconds.
- Smart cards (or USB keys): These devices contain a CPU and non-volatile RAM with a private key. The smart card authenticates itself to the host using a challenge-response protocol, encrypting the challenge with the private key. The private key remains within the device and should have some level of tamper-proof protection.
For payment authentication, options include 3D Secure, 3D Secure 2, Apple Pay, and Google Pay.
Expert-based Knowledge
Based on the expertise of the fraud analyst, it is crucial to gather and process the relevant information in a meticulous manner. Manual investigation of suspicious cases is necessary to identify potential new fraud mechanisms. Understanding these mechanisms allows for the enhancement of fraud detection and prevention measures. Once fraudulent activities are detected and confirmed, two types of measures are typically implemented:
- Corrective measures: These measures aim to resolve the fraud and address its consequences. Retrospective screening is conducted to identify and address similar fraud cases. Taking corrective measures as soon as possible increases their effectiveness and helps minimize losses.
- Preventive measures: These actions focus on preventing future frauds and strengthening the organization’s resilience. The typical process involves investigating the fraud case to uncover underlying mechanisms, incorporating this knowledge into the existing expertise, and adjusting the detection and prevention system accordingly.
Rule-based Engine
One approach commonly used in fraud detection is the Rule-based engine. It utilizes If-Then rules to describe previously identified fraud patterns and applies them to future transactions. When a potential fraud is detected, an alert is triggered. Red flags indicating potential fraud are translated into expert rules and incorporated into the rule engine.
Quote
Red flags refer to anomalies or deviations from normal behavior patterns. They are indicators that something is out of the ordinary.
- Grabosky and Duffield
However, the Rule-based engine has some disadvantages:
- It can be expensive to build, as it requires manual input from fraud experts.
- Maintenance and management can be challenging, including the need to regularly update the rule base to ensure its effectiveness.
- Every flagged case requires human follow-up and investigation.
- New fraud patterns are not automatically detected, as fraudsters can learn the rules and find ways to circumvent them.
To remain effective, the Rule-based engine must be continuously monitored, improved, and updated.
The Detection of Fraud Becomes More Effective Over Time
As fraudulent activities are successfully executed, fraudsters gain experience and knowledge, leading to an increase in the usage and frequency of a particular type of fraud. This pattern of repeated offenses creates a trail of evidence that can be analyzed and utilized to enhance fraud detection mechanisms. With each instance of fraud, the pattern becomes more evident and statistically easier to detect. As a result, the fraud mechanism itself is eventually discovered and identified, allowing for the detection of similar fraudulent activities committed in the past. Leveraging the power of big data, organizations can explore and exploit vast amounts of information to improve fraud detection at a lower cost. This data-driven approach to fraud detection enables more accurate identification and prevention of fraudulent activities, ultimately safeguarding businesses and individuals from financial losses and reputational damage.
Comparison between Expert-based and Automated Fraud-Detection Systems
When it comes to fraud detection, there are two main approaches: expert-based systems and automated data-driven systems. Expert-based systems rely on the expertise and input of human fraud analysts, who evaluate and monitor suspicious activities. These systems serve as a starting point and a complementary tool in developing effective fraud-detection and prevention strategies.
On the other hand, there is a growing trend towards automated data-driven fraud-detection systems. These systems leverage advanced algorithms and machine learning techniques to analyze large volumes of data and identify patterns indicative of fraudulent behavior. By reducing the reliance on human involvement, automated systems have the potential to be more efficient and effective in detecting and preventing fraud.
However, it is important to note that expert knowledge and input still play a crucial role in building and fine-tuning automated fraud-detection systems. The expertise of fraud analysts is invaluable in understanding the intricacies of fraud mechanisms and developing algorithms that can effectively detect and mitigate fraudulent activities.
Data-Driven Fraud Detection
Data-driven fraud detection systems leverage advanced algorithms and machine learning techniques to analyze large volumes of data and identify patterns indicative of fraudulent behavior. These systems are designed to automatically detect and prevent fraud by analyzing transactional data, user behavior, and other relevant information. By processing vast amounts of data, data-driven fraud detection systems can identify anomalies and patterns that may indicate fraudulent activities. These systems are continuously learning and adapting to new fraud patterns, making them more effective and efficient in detecting and preventing fraud.
- Precision: Organizations have limited capacity for investigation, so the goal of a fraud-detection system is to maximize the detection of fraudulent cases among those inspected. Higher precision means a higher fraction of inspected cases are frauds.
- Operational and Cost Efficiency: With an increasing number of cases to analyze, automated processes are necessary to meet operational requirements and time constraints. Expert-based systems can be challenging and labor-intensive, while automated data-driven approaches are more efficient.
- Growing Interest: The negative impact of frauds has raised awareness and attention, leading to increased investments and research from academia, industry, and government.
Fraud-Detection Techniques
Fraud detection approaches have undergone significant advancements in recent years, utilizing powerful statistical methodologies and analyzing vast amounts of data. However, fraud remains a challenging and complex issue to address.
Where's Wally?
Where’s Wally? is a popular children’s book series that challenges readers to find the character Wally, who is hidden among a crowd of people in intricate illustrations. The task of finding Wally is similar to detecting fraud, as both require careful observation and analysis to identify anomalies or deviations from the norm. Just as finding Wally becomes more challenging as the illustrations become more complex, detecting fraud becomes more difficult as fraudsters develop sophisticated strategies to conceal their activities.

Sequence
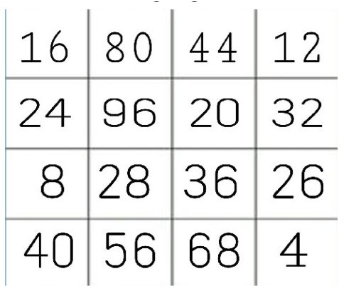
Now considere the following sequence:
This might be a simpler task than finding Wally, but… what’s the “strange” number of the sequence? It’s
, the only number that is not a multiple of . This is an example of a simple fraud detection task.
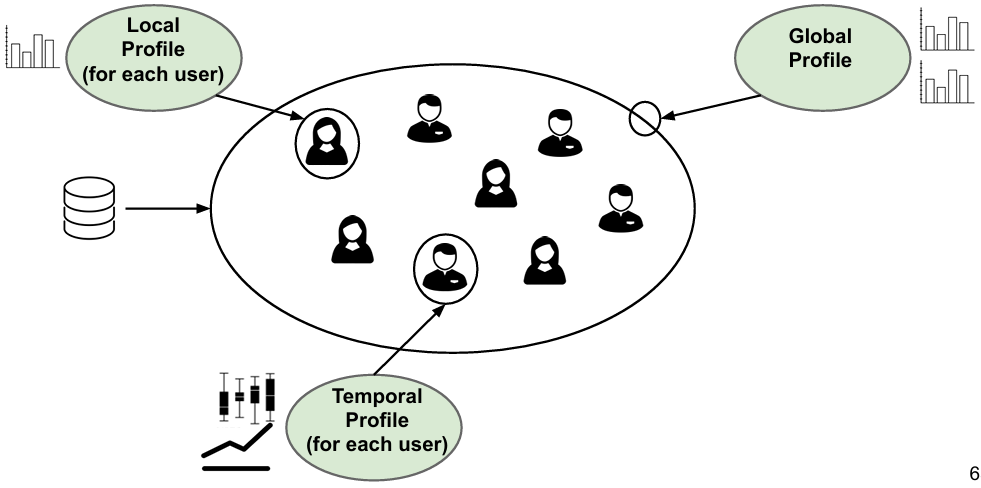
Fraudsters continuously develop sophisticated strategies to conceal their activities and avoid detection, employing techniques such as camouflage, mimicry, and adversarial machine learning. As a result, there is a need for new techniques capable of identifying and addressing these stealthy patterns.
- Unsupervised learning or descriptive analytics techniques
- Supervised learning or predictive analytics techniques
Unsupervised Learning Techniques
Definition
Unsupervised learning is a type of machine learning that involves training a model on a dataset without any supervision or labeled responses. The model learns to identify patterns and relationships within the data, allowing it to make predictions or detect anomalies.
Unsupervised learning techniques do not require labeled observations. They learn the normal behavior from historical observations and focus on detecting anomalies, which are behaviors that deviate from the norm. This allows them to detect novel fraud patterns that are different from historical fraud and make use of new, unknown mechanisms. Unsupervised learning techniques serve as a complementary tool to improve the expert rule-based fraud detection system.
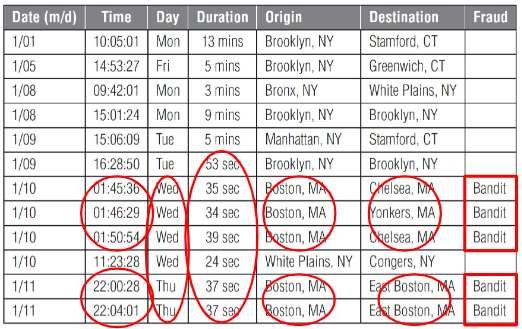
Telecommunications fraud
The marked sections (in red) of the telecommunication log could be considered possible frauds for the following reasons:
- Unusual Pattern of Calls: There is a cluster of calls originating from Boston, MA within a very short period on 1/10. Specifically, there are four calls between 01:45:30 and 01:50:54, each lasting between 24 and 39 seconds. Another set of calls originates from Boston, MA on 1/11, occurring at 22:00:28 and 22:04:01, with durations of 37 and 37 seconds, respectively.
- Short Durations: The calls identified as “Bandit” have notably short durations, typically around 30 seconds, which is often characteristic of fraudulent calls meant to test the system or carry out brief illicit activities.
- Repetitive Origin: The origin of these calls is consistently from Boston, MA, suggesting that a particular source may be attempting to commit fraud repeatedly.
- Consistent Destinations: The destinations of these calls include places like Chelsea, MA, Yonkers, MA, and East Boston, MA. The repetition of the origin and the varying destinations might indicate the use of the same fraudulent source to reach multiple targets.
- Labeled as Fraud: The log explicitly labels these calls as “Bandit,” indicating that they have already been identified as suspicious or fraudulent based on the system’s detection criteria.
These factors collectively suggest that the marked sections are flagged for possible fraud due to the abnormal calling patterns, short durations, consistent origin point, and the system’s fraud detection labeling them as “Bandit.”
Limitations: Fraud detection systems are susceptible to deception and camouflage-like fraud strategies. They can only detect new fraud if it results in detectable deviations from normal behavior. To overcome these limitations, it is necessary to complement them with other tools and techniques.
Supervised Learning Techniques in Fraud Detection
Supervised learning techniques involve training algorithms using historical data to recognize patterns that differentiate between legitimate and fraudulent activities. The primary aim is to identify “known alarms”, patterns of behavior indicative of fraud that have been observed before and are thus more easily detected. This method is instrumental in several areas including fraud prediction, detection, and quantification of fraudulent activity.
- Data Preparation: Supervised learning requires a dataset consisting of labeled examples, where each instance is tagged as either fraudulent or legitimate based on historical records. This labeled data serves as a reference for the algorithm to learn from.
- Model Training: During the training phase, the algorithm analyzes these labeled examples to identify distinguishing features and patterns that characterize fraudulent behavior. For instance, it might learn that a sudden spike in transaction size following several small purchases could indicate potential fraud.
- Prediction and Detection: Once trained, the model can classify new, unlabeled transactions as either fraudulent or legitimate based on the patterns it has learned. This enables real-time detection of fraudulent activities.
To build a comprehensive fraud detection system, both supervised and unsupervised analytics can be employed. Supervised analytics can provide a foundational model based on known patterns, while unsupervised analytics can help in identifying previously unrecognized or novel fraud patterns by examining the data for anomalies or outliers.
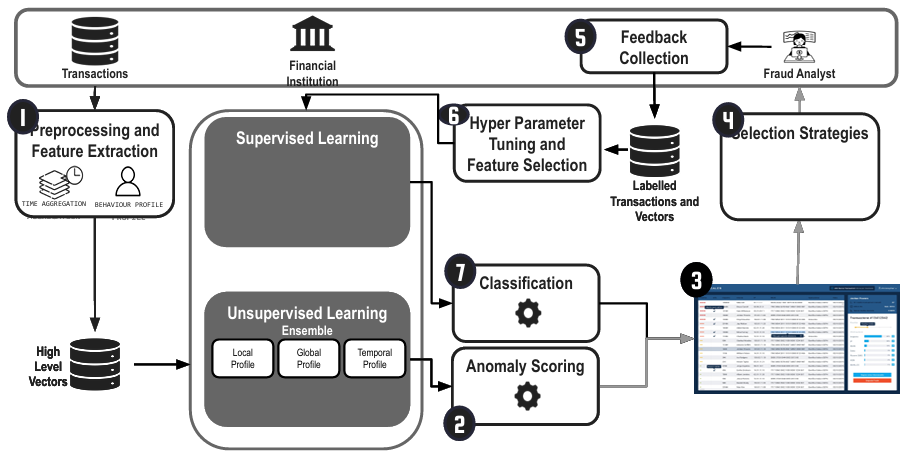
Developing a Comprehensive Fraud-Detection System
When it comes to developing a robust fraud-detection system, there are several techniques that can be employed. These techniques can be implemented in a specific order based on the characteristics of the type of fraud being targeted.
- Expert-based rule engine: One of the initial steps in developing a fraud-detection system is to establish an expert-based rule engine. This involves creating a set of predefined rules and criteria that can be used to identify potential fraudulent activities. These rules are typically based on the knowledge and expertise of fraud analysts and investigators who have a deep understanding of the patterns and indicators of fraudulent behavior.
- Unsupervised learning systems: Another important technique in fraud detection is the use of unsupervised learning systems. These systems are designed to analyze large volumes of data and identify patterns and anomalies that may indicate fraudulent activity. Unsupervised learning systems do not require labeled data and can uncover new and unknown fraud patterns. By leveraging powerful statistical methodologies, these systems can detect deviations from normal behavior and flag potential fraud cases for further investigation.
- Supervised learning systems: In addition to unsupervised learning, supervised learning systems play a crucial role in fraud detection. These systems learn from historical data that has been labeled as either fraudulent or non-fraudulent. By analyzing patterns and features in the data, supervised learning systems can classify new transactions or activities as either fraudulent or non-fraudulent. This approach is particularly effective in detecting known fraud patterns and can provide valuable insights into the characteristics and behaviors associated with fraudulent activities.
Challenges in Developing Effective Fraud-Detection Models
While developing fraud-detection models, there are several challenges that need to be addressed to ensure their effectiveness and accuracy:
- Dynamic nature of fraud: Fraudsters are constantly evolving their tactics and strategies to avoid detection. They adapt their approaches, probe fraud-detection systems, and develop advanced techniques to cover their tracks. This dynamic nature of fraud requires adaptive analytical models that can quickly detect and respond to new fraud patterns.
- Good detection power: A successful fraud-detection system should have a high detection power, meaning it can accurately identify fraudulent activities with a low false negative rate. It should be able to detect fraud cases involving large financial impacts and minimize false alarms to avoid inconveniencing legitimate customers.
- Skewness of the data: Fraudulent cases are often rare compared to non-fraudulent cases, resulting in a skewed distribution of data. This can pose challenges for analytical techniques, as they may struggle to learn accurate models due to the limited number of fraudulent cases. Addressing this needle-in-a-haystack problem requires specialized techniques and algorithms that can effectively handle imbalanced datasets.
- Operational efficiency: Fraud detection is a time-sensitive process, and decisions need to be made quickly to prevent fraudulent transactions. This places a premium on operational efficiency, requiring the analytical models to process massive volumes of data in a timely manner. The design of the IT systems supporting the fraud-detection process should be optimized to ensure efficient evaluation and decision-making.
- Big Data management: With the exponential growth of data in today’s digital landscape, managing and analyzing big data is a significant challenge in fraud detection. The ability to efficiently process and analyze large volumes of data is crucial for identifying complex fraud patterns and detecting fraudulent activities in real-time.
By addressing these challenges and leveraging a combination of expert-based rules, unsupervised learning, and supervised learning techniques, organizations can develop comprehensive fraud-detection systems that are capable of detecting and preventing fraudulent activities effectively.
Fraud Management Cycle
graph BT A[Fraud Detection] subgraph " " B[Fraud Investigation] C[Fraud Confirmation] end D[Fraud Prevention] E{{Automated Detection Algorithm}} A --> B --> C --> D C -.-> E -.-> A
The fraud management cycle involves several stages to effectively detect, investigate, confirm, and prevent fraud. It begins with fraud detection, where detection models are applied to new observations to assign a fraud risk. If a case is flagged as suspicious, it moves to the fraud investigation stage, where human experts analyze the case due to its complexity. The next stage is fraud confirmation, where the true fraud label is determined, sometimes requiring field research. Finally, the cycle includes fraud prevention, aiming to prevent future instances of fraud.
An automated detection algorithm is used to continuously update the detection model by incorporating newly detected cases into the historical fraud database. The frequency of model updates depends on factors such as fraud behavior volatility, detection power, available confirmed cases, and the effort required for retraining. Reinforcement learning is employed to continuously learn from the newest observations and improve the detection model.
Fraud Analytical Process
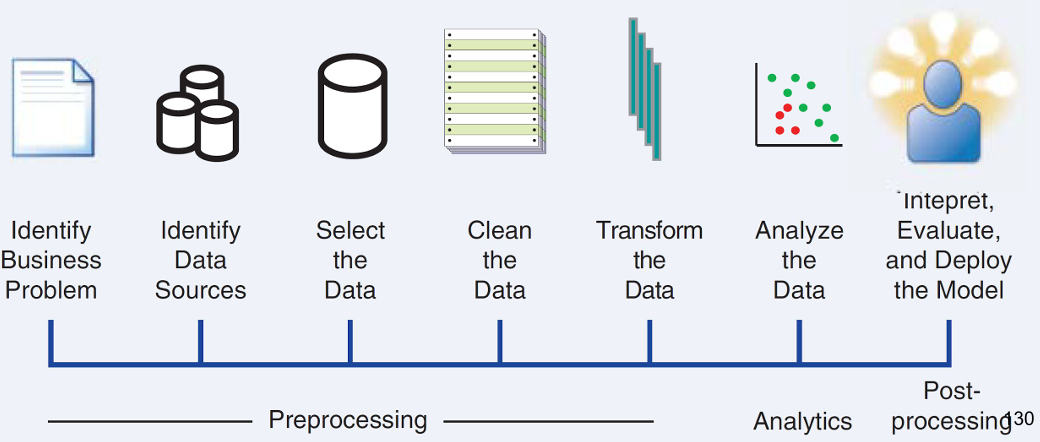
The fraud analytical process is an iterative and systematic approach to detecting fraudulent activities within a business environment. This process involves multiple stages, each crucial for building an effective fraud detection model.
- Identify the Business Problem: The first step in the fraud analytical process is to clearly define the business problem that needs to be addressed. This involves understanding the specific types of fraud that are of concern, such as credit card fraud, insurance fraud, or financial statement fraud. The business problem dictates the objectives of the fraud detection model and influences the entire analytical approach.
- Identify Data Sources: Data is the cornerstone of any analytical exercise. In this step, relevant data sources are identified. These could include transactional databases, customer records, log files, or third-party data sources. The quality and variety of data sources directly impact the effectiveness of the fraud detection model. It is essential to ensure that the data sources provide comprehensive and accurate information related to the identified business problem.
- Select the Data: Data selection involves choosing the most relevant datasets from the identified sources. This step is critical because the quality of data selection has a significant impact on the performance of the analytical models. During this phase, data is often gathered in a staging area where it undergoes basic exploratory analysis. This helps to assess the data’s suitability for modeling, identify key variables, and detect potential issues such as data sparsity or imbalance.
- Clean the Data: Data cleaning is a crucial step where inconsistencies, such as missing values, outliers, and duplicate records, are addressed. Inconsistent data can lead to inaccurate models, so it is vital to ensure that the data is as clean and accurate as possible. Techniques such as imputation, outlier detection, and normalization may be applied to prepare the data for subsequent stages.
- Transform the Data: Data transformation involves modifying the data to make it suitable for analysis. This may include converting categorical variables into numerical formats, performing binning (grouping continuous variables into discrete intervals), or aggregating data geographically. Additional transformations might involve feature engineering, where new variables are created based on existing data to capture more complex patterns. Proper data transformation can significantly enhance the predictive power of the analytical models.
- Analyze the Data: In this stage, the preprocessed and transformed data is used to build the fraud detection model. Various analytical techniques, such as machine learning algorithms, statistical models, or rule-based systems, are applied to detect patterns indicative of fraudulent behavior. The choice of model depends on the nature of the data and the business problem. The model is trained on historical data and validated to ensure its accuracy and reliability.
- Interpret, Evaluate, and Deploy the Model: After the model is built, it must be interpreted and evaluated by fraud experts. Interpretation involves understanding the model’s outputs, such as the probability scores or classifications it assigns to each transaction or entity. Evaluation involves testing the model’s performance on unseen data to assess its accuracy, precision, recall, and other relevant metrics. Once the model has been validated and fine-tuned, it is deployed into the production environment, where it can be used to monitor and detect fraudulent activities in real-time. Continuous monitoring and periodic retraining of the model may be necessary to maintain its effectiveness as new types of fraud emerge.
This process is highly technical and requires a deep understanding of both the business context and the data involved. Each step, from identifying data sources to deploying the model, involves complex decision-making and technical tasks that can significantly influence the success of the fraud detection initiative. For example, data cleaning and transformation require knowledge of advanced data processing techniques, while model building and evaluation demand expertise in machine learning and statistical analysis. By following this iterative process, organizations can develop robust fraud detection models that help mitigate financial losses and protect against fraudulent activities.
Analysis Output and Model Validation for Fraud Detection
When developing a fraud-detection model, it is crucial to validate and rigorously test its performance before deploying it into production. This process ensures that the model accurately identifies fraudulent patterns and provides actionable insights. A comprehensive understanding of the key elements that contribute to the success of a fraud-detection model is essential for effective evaluation.
Key Elements of a Successful Fraud Analytics Model
Statistical accuracy is a fundamental aspect of any fraud-detection model. The objective is to ensure the model can effectively detect fraudulent activities with high accuracy. To achieve this, various performance metrics, such as precision, recall, F1 score, and ROC-AUC, are employed to evaluate the model’s ability to generalize beyond historical data and avoid overfitting. Accurate detection minimizes the occurrence of false positives and false negatives, which is critical for maintaining trust in the fraud-detection system.
Interpretability is another crucial factor, as it enables users to understand and make sense of the fraud detection results. The chosen algorithms greatly influence the interpretability of the model. For instance, simpler models like decision trees offer greater transparency compared to more complex models, such as deep neural networks. Clear insights into why certain transactions are flagged as suspicious facilitate informed decision-making and enable further investigation when needed.
Operational efficiency focuses on optimizing the model for efficient real-time performance. This involves considering the time and resources required for data collection, preprocessing, model evaluation, monitoring, backtesting, and real-time analysis. An operationally efficient model ensures the timely detection of fraudulent activities without overwhelming the system or slowing down regular business processes, thereby maintaining overall system performance.
Economic cost is a significant consideration in the implementation of a fraud-detection model. The financial implications include both direct costs (such as management, operational, and equipment expenses), and indirect costs (such as reduced usability, slower system performance, privacy concerns, and decreased productivity). A thorough cost-benefit analysis helps determine whether the advantages of deploying the fraud-detection model outweigh the associated costs, ensuring a favorable return on investment.
The balance between security and cost is essential for creating an effective and financially sustainable fraud-detection system. High-cost systems, if poorly configured, may be less effective than more economical solutions. Additionally, complex authentication methods can hinder user efficiency, leading to insecure practices like writing down passwords. Achieving a balance between security measures and financial expenditure ensures that the system is both effective and practical.
Finally, regulatory compliance is a key factor in the success of a fraud-detection model. The model must adhere to relevant regulations and standards, such as the Payment Services Directive 2 (PSD2), to avoid legal issues and maintain industry standards. Compliance ensures that the organization remains protected from legal repercussions while aligning the model with best practices in the industry.
A well-validated fraud-detection model is essential for protecting against fraudulent activities while ensuring operational efficiency and compliance. By focusing on statistical accuracy, interpretability, operational efficiency, economic cost, security vs. cost balance, and regulatory compliance, organizations can develop effective fraud-detection systems that offer valuable insights and robust protection against fraud.